LLM-VA:ベクトルアライメントによる脱獄と過剰拒否のトレードオフの解消
安全性が調整された大規模言語モデル(LLM)において、有害な入力に回答してしまう「脱獄」と、無害な質問を拒否する「過剰拒否」がトレードオフの関係にあるのは、モデル内部で回答の意思決定と安全性評価が独立したプロセスとして処理されていることが原因です。
TL;DR(結論)
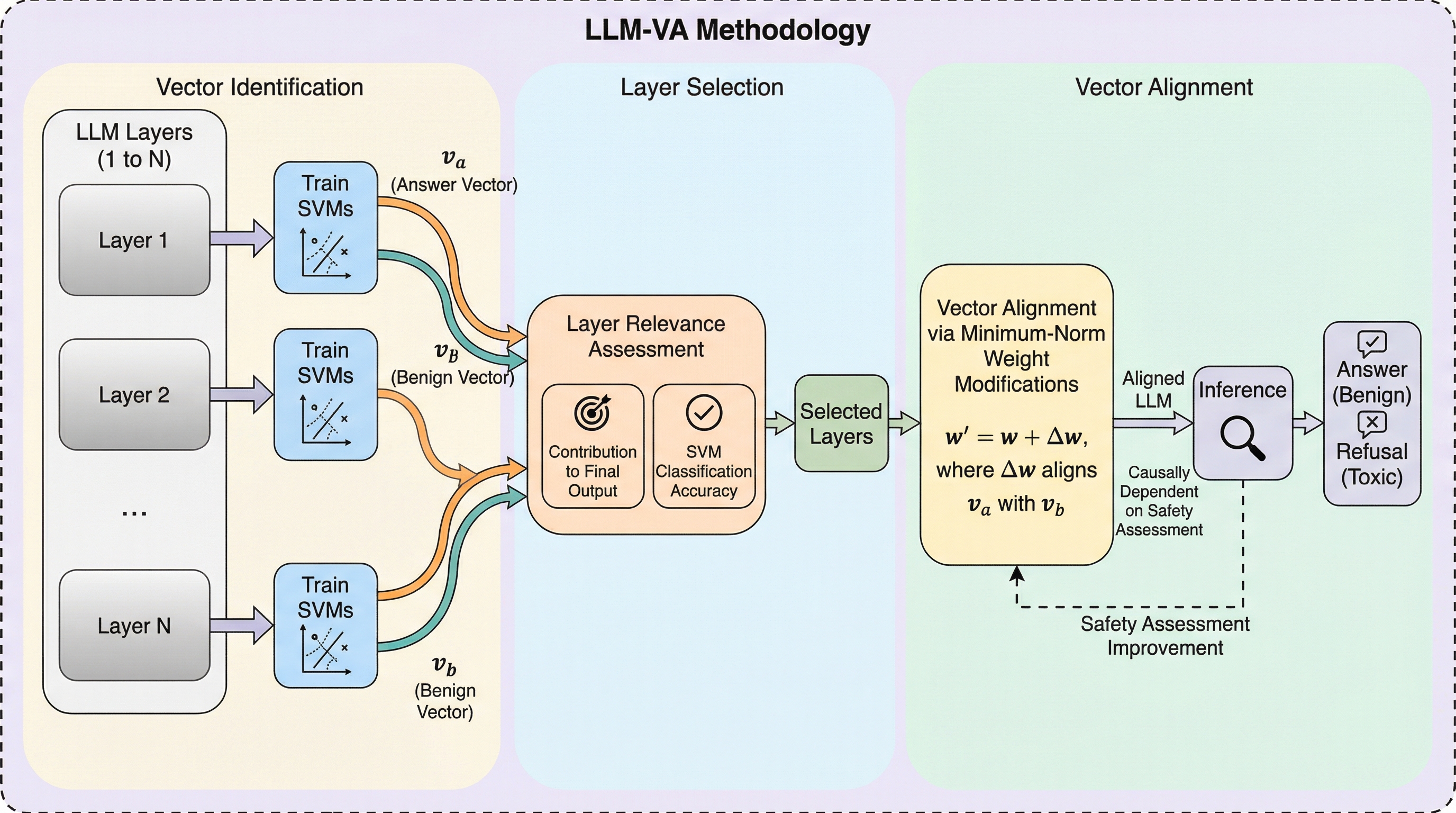
安全性が調整された大規模言語モデル(LLM)において、有害な入力に回答してしまう「脱獄」と、無害な質問を拒否する「過剰拒否」がトレードオフの関係にあるのは、モデル内部で回答の意思決定と安全性評価が独立したプロセスとして処理されていることが原因です。本研究が提案する「LLM-VA」は、モデルの微調整や構造変更を行わず、閉形式の重み更新のみを用いて回答ベクトルを安全性ベクトルに整列させることで、回答の判断を安全性評価に因果的に依存させることに成功しました。12種類の主要なLLMを用いた実験では、既存の最良手法と比較してF1スコアを11.45%向上させつつ、モデル本来の汎用能力を95.92%という高い水準で維持できることが実証されており、各モデルの安全性の偏りに自動適応する実用的な解決策となっています。
なぜこの問題か
大規模言語モデル(LLM)の安全性調整において、信頼性とユーザビリティを両立させることは極めて困難な課題であり、現在のモデルは二つの主要な失敗モードに直面しています。一つは「脱獄(Jailbreak)」であり、これは有害、非倫理的、あるいは安全でない応答を引き出すために設計された毒性のある入力に対して、モデルが直接的に回答してしまう現象を指します。もう一つは「過剰拒否(Over-refusal)」であり、これはモデルが過度に保守的になり、本来は安全で無害な質問に対しても不必要に応答を拒否してしまう現象です。これら二つの問題は、一方を改善しようとするともう一方が悪化するという、根本的なトレードオフの関係にあることが知られています。 既存の対策として注目されている「ベクトルステアリング」は、モデルの潜在空間における特定の方向を操作する手法であり、高コストな再学習を必要としない効率的なアプローチです。しかし、これまでのベクトルステアリング手法は、主に「回答ベクトル」の大きさを調整することに終始していました。回答ベクトルの大きさを抑制すれば脱獄は減少しますが、同時に無害な質問に対する回答意欲も削がれるため過剰拒否が増加します。…
核心:何を提案したのか
本研究は、LLMが「回答するかどうかの決定」と「入力が安全かどうかの判断」を、内部的にほぼ直交する(約90度の角度を持つ)独立したプロセスとして処理しているという発見に基づき、新しい手法「LLM-VA(Large Language Model Vector Alignment)」を提案しました。この手法の核心は、回答ベクトル(va)を安全性を示すベニグン(無害)ベクトル(vb)に整列(アライメント)させることにあります。これにより、モデルが回答しようとする意思を、その入力が安全であるという判断に因果的に依存させることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related