ドメイン内検知を超えて:クロスドメインのハルシネーション検知のためのSpikeScore
大規模言語モデル(LLM)のハルシネーション検知において、訓練データと異なる領域で精度が低下する「クロスドメイン汎用性」の欠如を解決するため、単一ドメインの学習のみで多様な未知の領域に対応できる汎用的検知(GHD)の枠組みを確立しました。
TL;DR(結論)
大規模言語モデル(LLM)のハルシネーション検知において、訓練データと異なる領域で精度が低下する「クロスドメイン汎用性」の欠如を解決するため、単一ドメインの学習のみで多様な未知の領域に対応できる汎用的検知(GHD)の枠組みを確立しました。 ハルシネーションから始まる多ターン対話では、事実に基づく対話よりもモデル内部の不確実性の変動が激しくなる現象に着目し、対話の過程で生じる不確実性スコアの急激な変化を二階差分によって定量化する新指標「SpikeScore」を開発しました。 複数のモデルとベンチマークを用いた実験により、SpikeScoreは既存の汎用性重視の手法を上回る精度を示し、理論的な分離可能性の証明とともに、教育や医療などの安全性が重視される実社会の多様な応用におけるLLMの信頼性を高める有効性を実証しました。
なぜこの問題か
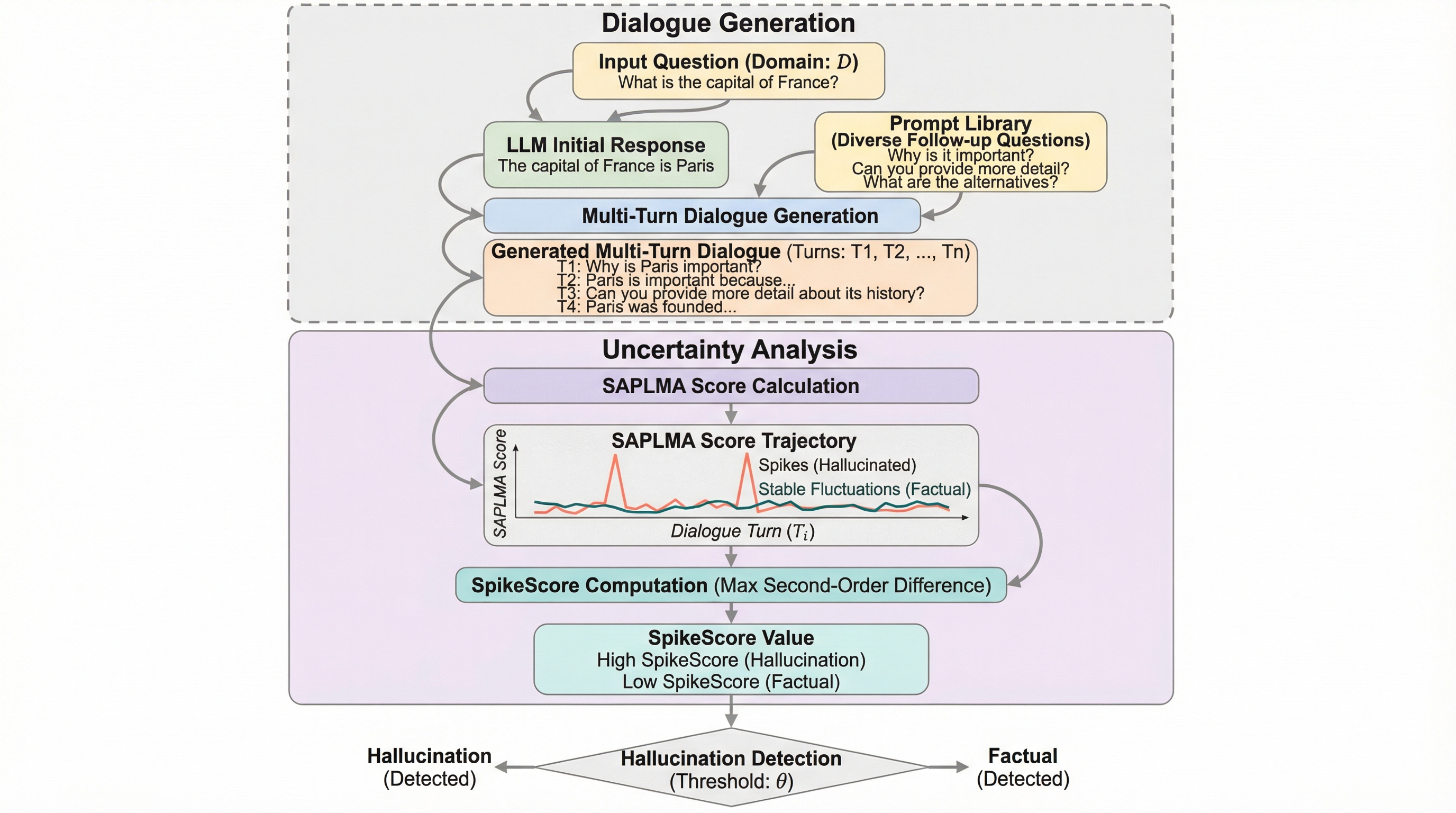
大規模言語モデル(LLM)を実社会のアプリケーション、特に教育、医療、金融といった安全性が極めて重視される領域にデプロイする際、ハルシネーションの検知は避けて通れない重要な課題となっています。LLMは事実として誤った内容や、論理的に矛盾した出力を生成することがあり、これがユーザーの信頼を損なうだけでなく、重大な場面で有害な結果を招く可能性があるからです。現在、ハルシネーション検知の研究は、モデルの内部信号を利用する訓練不要な手法と、特定の層の活性化情報を用いて分類器を学習させる訓練ベースの手法の二つに大別されます。訓練ベースの手法は、訓練データと同じドメインのテストセットに対しては非常に高い性能を発揮するため、現在の研究の主流となっています。しかし、これらの手法には「クロスドメイン汎用性の欠如」という深刻な限界が存在することが明らかになっています。 既存の訓練ベースの手法であるSAPLMAやSEPなどは、テストドメインが訓練ドメインと異なる場合に検知性能が急激に低下することが報告されています。このドメイン感度は、学習過程で特定のドメインに固有の特徴に過度に依存してしまうことに起因しており、分布のシフトに対して非常に脆弱です。…
核心:何を提案したのか
本研究の核心は、多ターン対話においてLLMが示す「自己矛盾」という振る舞いを、ドメインに依存しないハルシネーションの普遍的な指標として利用することにあります。先行研究では、ユーザーがモデルの回答に対して繰り返し問いかけたり立場を変えたりすると、モデルが自身の初期の立場を容易に放棄し、自己矛盾を引き起こす現象が報告されています。研究チームは、この振る舞いがモデル内部の不確実性や確信度の不安定さを明示的に表しているという仮説を立てました。特に、初期の回答がハルシネーションである場合、モデルの自己修正メカニズムが誘発されやすいため、事実に基づく回答から始まる対話よりも、確信度の変動が劇的かつ急激に起こると考えたのです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related