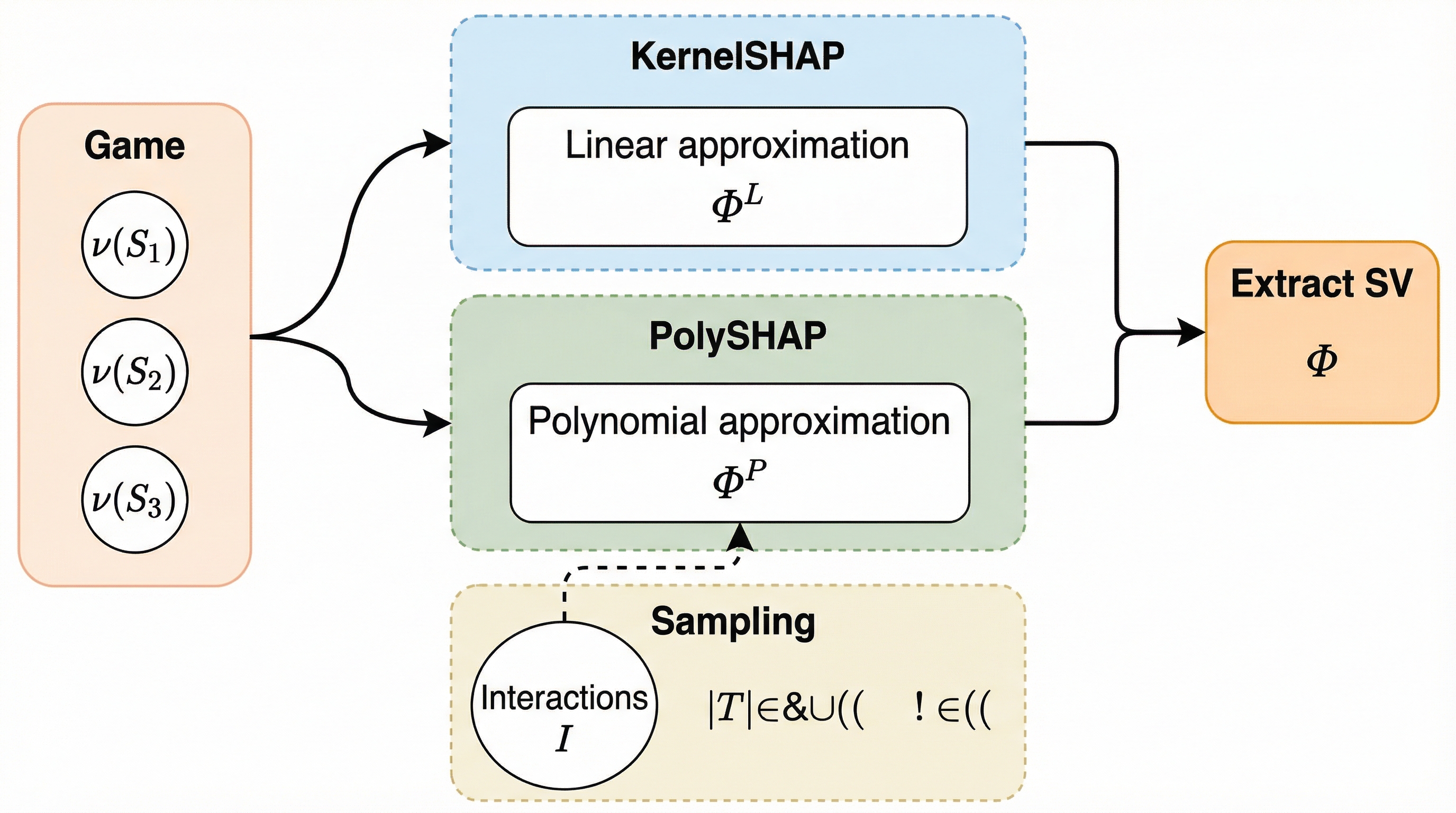
PolySHAP:交互作用を考慮した多項式回帰によるKernelSHAPの拡張
PolySHAPは、機械学習モデルの説明手法であるKernelSHAPを拡張し、特徴量間の複雑な交互作用を多項式回帰によってモデル化することで、シャプレイ値の推定精度を大幅に向上させる新しいアルゴリズムである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
PolySHAPは、機械学習モデルの説明手法であるKernelSHAPを拡張し、特徴量間の複雑な交互作用を多項式回帰によってモデル化することで、シャプレイ値の推定精度を大幅に向上させる新しいアルゴリズムである。
深層強化学習における自然方策勾配法(NPG)は、学習の収束が早く幾何学的に適切な更新が可能である一方、フィッシャー情報行列(FIM)の逆行列計算にパラメータ数の3乗という膨大な計算コストがかかる点が実用上の大きな障壁となっていました。
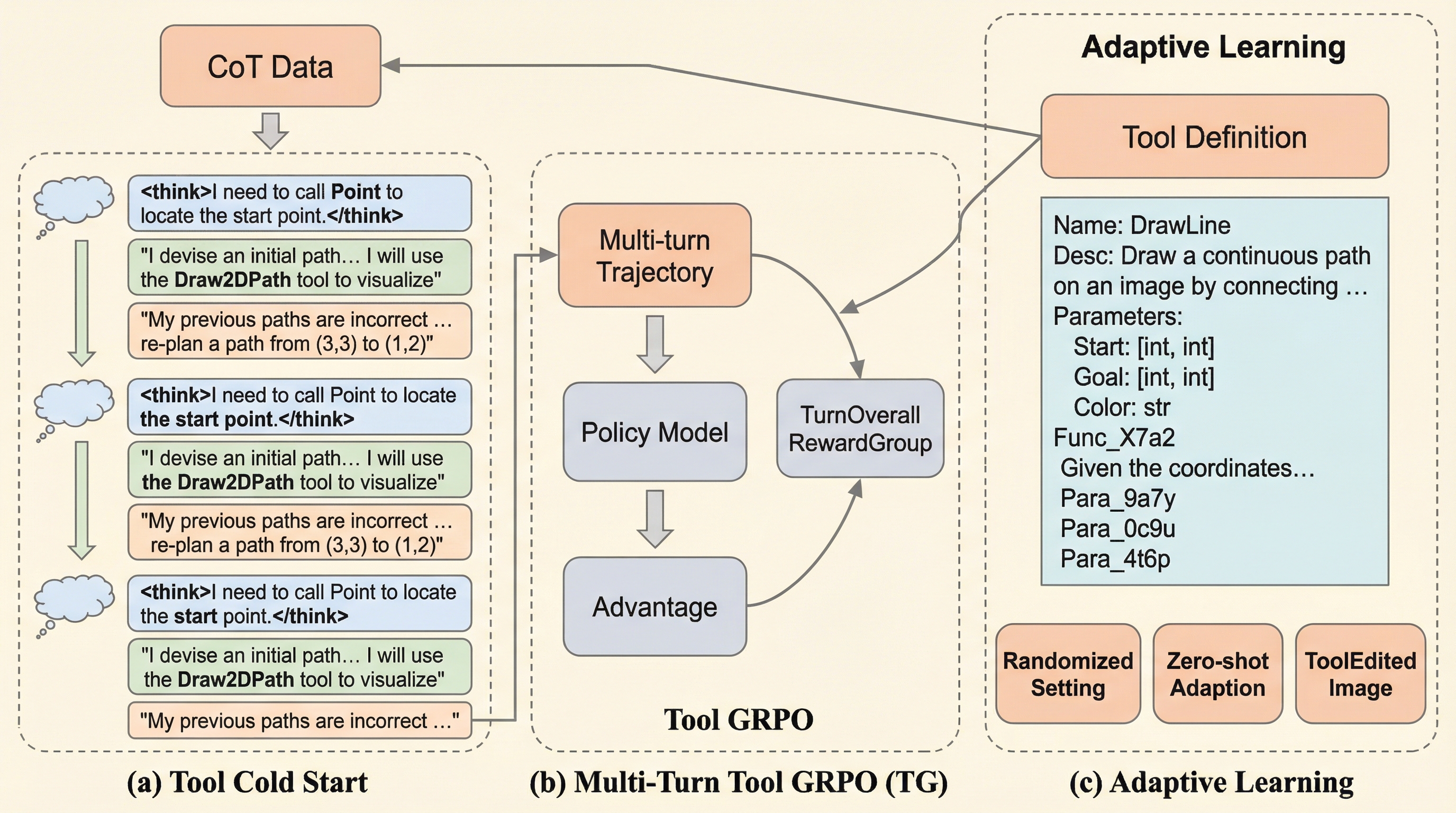
AdaReasonerは、マルチモーダル大規模言語モデル(MLLM)において、ツール利用を特定のタスクの手順としてではなく、文脈に応じて「いつ、何を、どう使うか」を判断する汎用的な推論スキルとして習得させる新しいモデルファミリーである。
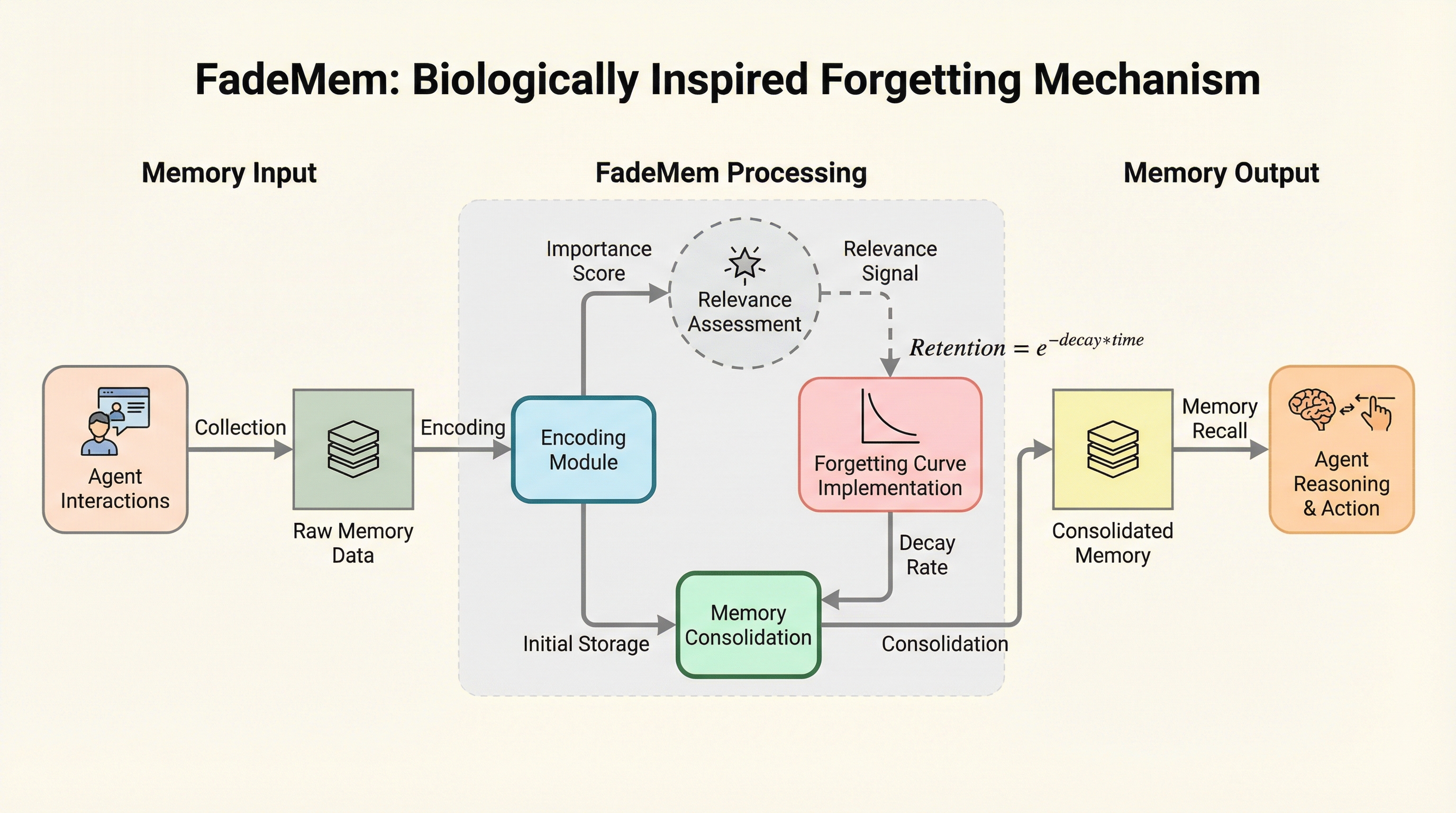
大規模言語モデル(LLM)エージェントの長期運用における課題である情報の過負荷と破滅的忘却を解決するため、人間の「忘却」プロセスを模倣した二層構造のメモリ管理アーキテクチャ「FadeMem」が提案されました。
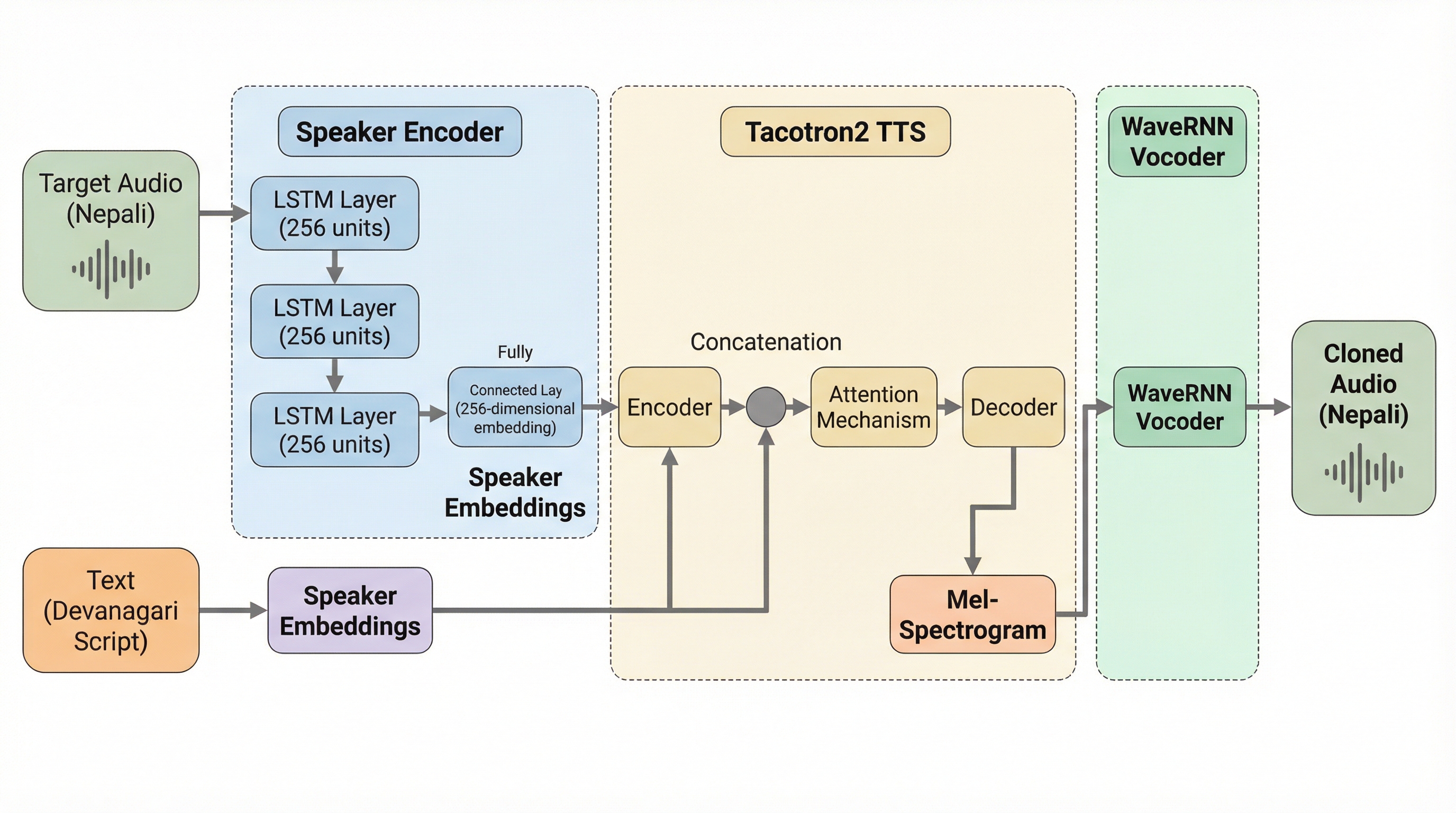
本研究は、データ資源が極めて乏しいネパール語において、わずかな音声サンプルから特定の個人の声を再現する「フューショット音声クローニング」システムを開発しました。 システムは、話者の特徴を抽出するエンコーダ、デバナガリ文字からメルスペクトログラムを生成するTacotron2、そして高品質な音声を合成するWaveRNNの3つの主要なニューラルネットワークを統合して構成されています。 833名の話者による235時間の広範なデータセットを用いた検証の結果、未知の話者に対しても高い類似性と自然な音声品質を実現し、低リソース言語におけるパーソナライズされた音声合成の基盤を確立しました。
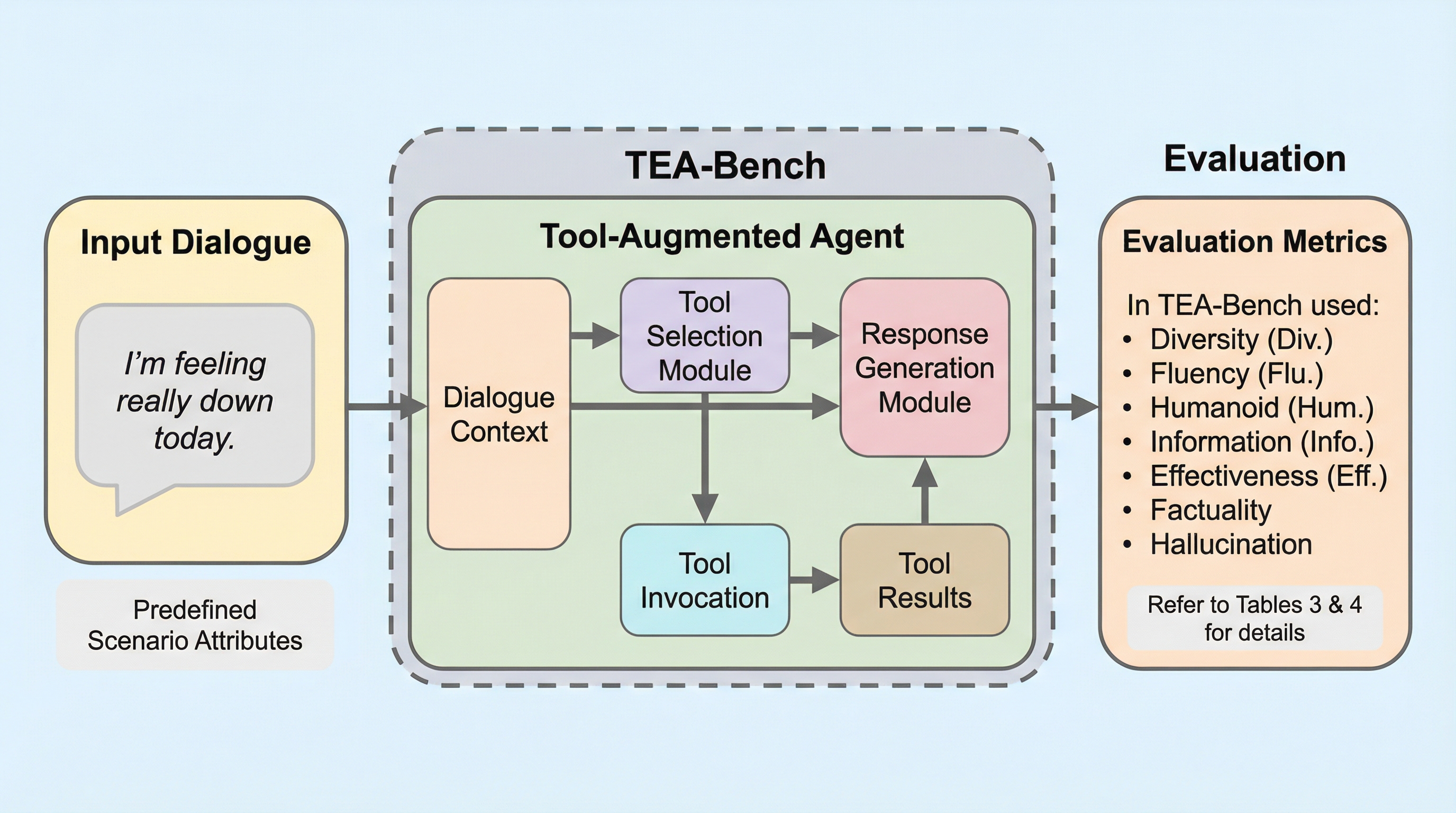
従来の感情支援対話(ESC)は共感的な発話に偏り、現実の状況に基づいた具体的な助言が不足することで、AIが事実を捏造し信頼を損なうハルシネーションの問題を抱えていました。本研究は、外部ツールを活用して事実に基づいた「道具的支援」を行う能力を評価する初の対話型ベンチマーク「TEA-Bench」を提案し、31種のツールを備えた環境で9種の大規模言語モデルの性能を体系的に検証しました。検証の結果、ツールの導入は感情支援の質を向上させハルシネーションを劇的に抑制しますが、その効果はモデルの基礎能力に強く依存しており、強力なモデルほどツールを適切に選択して活用できる一方で、能力の低いモデルはツールの情報を統合できず混乱する傾向が判明しました。
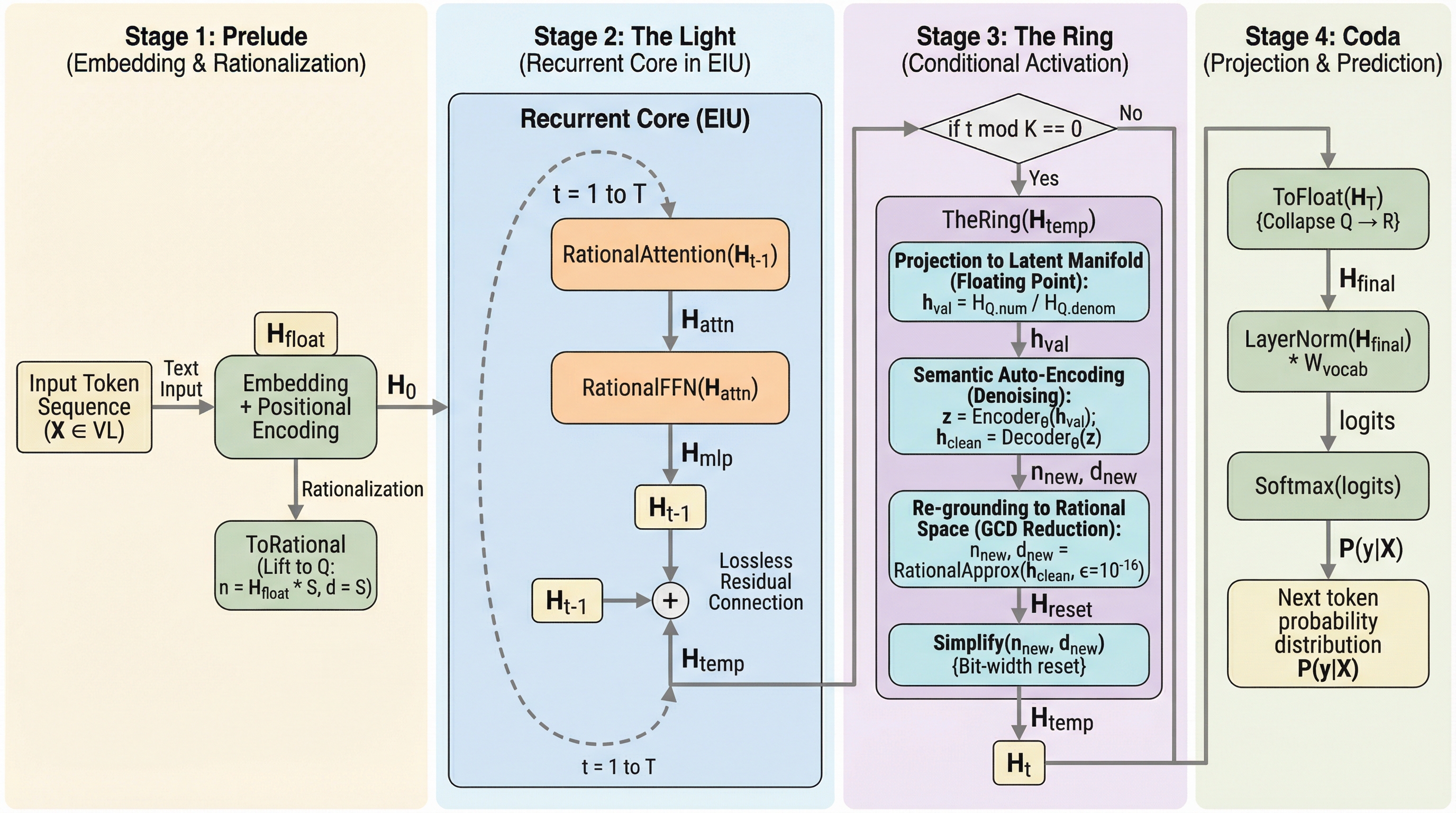
現在の深層学習が依存する浮動小数点演算の近似誤差が、深い推論における「論理的な幻覚」や「セマンティック・ドリフト」の根本原因であると特定し、これを排除するための新しい計算パラダイムを提案した。 有理数演算(Q)を基盤とする「Haloアーキテクチャ」と専用ハードウェア「Exact Inference Unit(EIU)」を導入することで、誤差の蓄積をゼロに抑え、理論上無限の深さを持つ論理推論を可能にする。 600Bパラメータ規模のモデルを用いた検証では、従来の浮動小数点形式がカオス的な系で崩壊する一方で、本提案手法は無限に精度を維持し、大規模モデルほど数値的に不安定になるという「次元の呪い」を克服した。
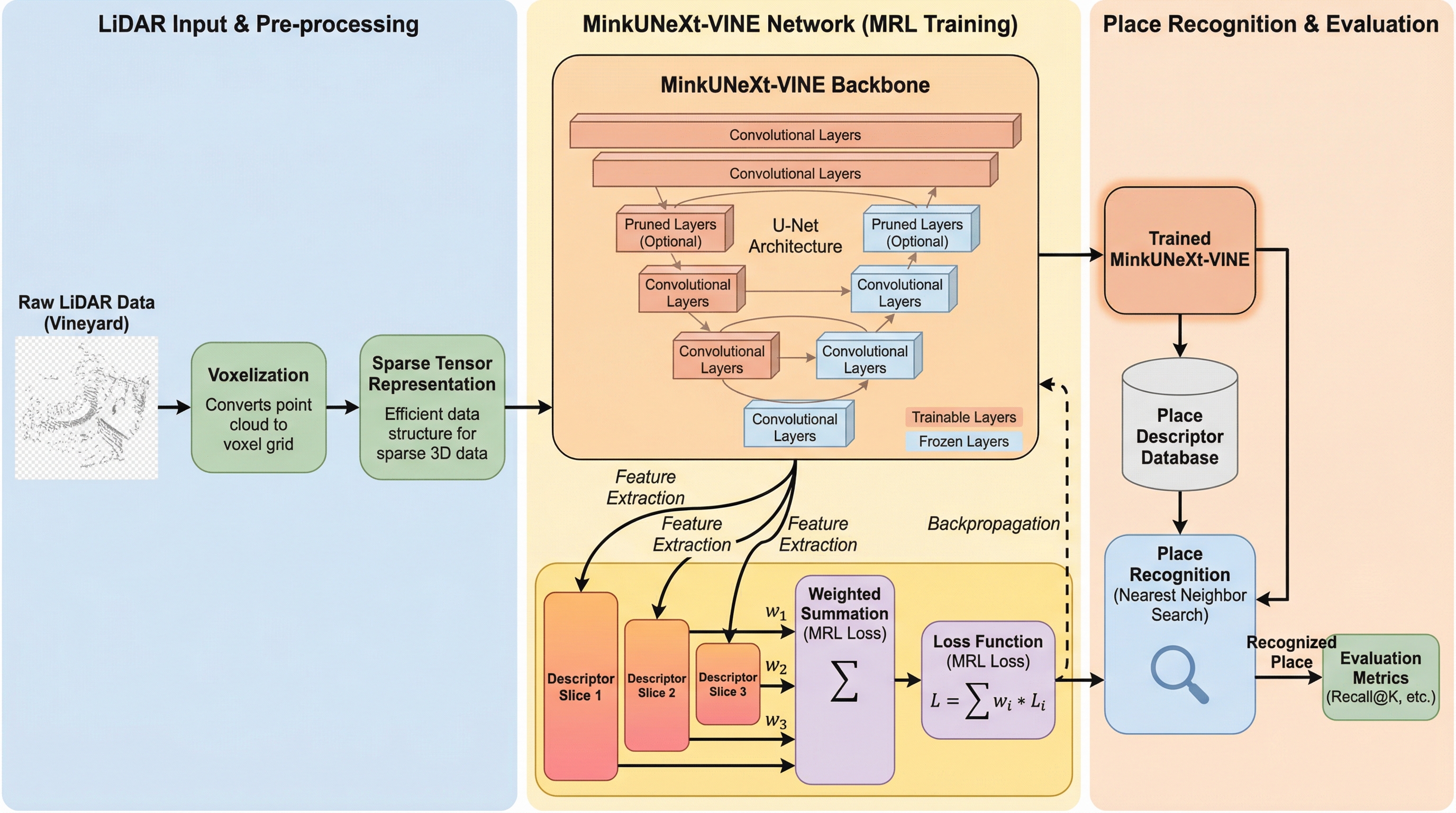
ブドウ園のような非構造的で特徴的な目印が乏しい農業環境において、ロボットが正確に自己位置を特定するための軽量な深層学習手法「MinkUNeXt-VINE」が提案されました。 既存のネットワーク構造を剪定して計算負荷を下げつつ、マトリョーシカ表現学習(MRL)を導入することで、低次元から高次元まで柔軟かつ頑健な記述子を生成し、リアルタイムでの高い処理効率を実現しています。 複数のブドウ園で収集された長期的なデータセットを用いた検証により、季節による外観の変化や低コスト・低解像度なLiDAR入力に対しても、従来の最先端手法を上回る優れた認識精度と汎用性が実証されました。
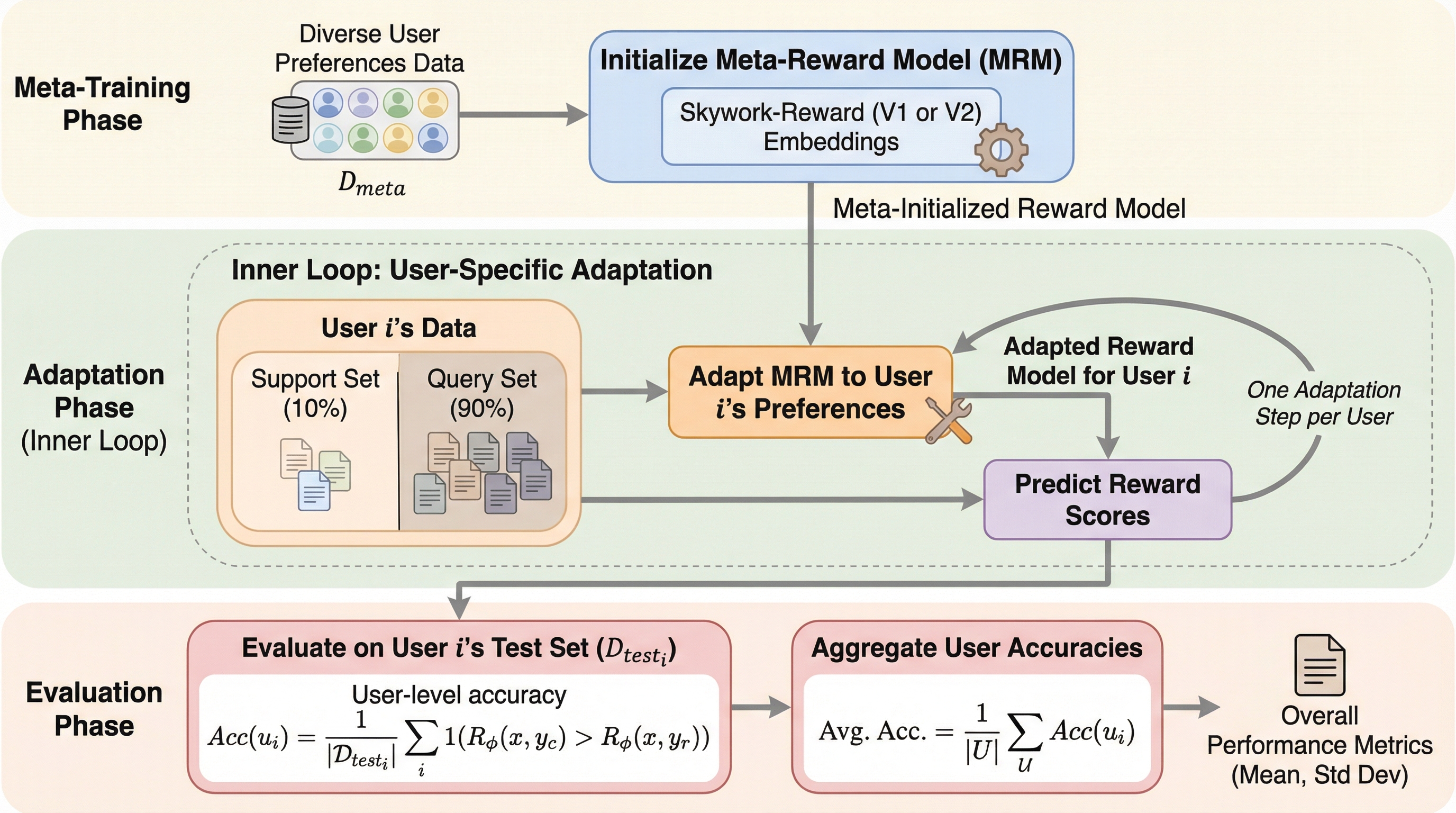
大規模言語モデル(LLM)を個々のユーザーの多様な好みに適応させるため、メタ学習の枠組みを用いた新しい報酬モデリング手法「Meta Reward Modeling(MRM)」が提案されました。この手法は、少数のフィードバックから未知のユーザーの意図を迅速に学習する「学習のプロセス」そのものを最適化することで、従来の個別化手法が抱えていたデータの希少性や過学習、未知のユーザーへの対応といった課題を根本から解決します。さらに、学習が困難なユーザーを優先的に扱う「Robust Personalization Objective(RPO)」を導入することで、特異な価値観を持つユーザーに対しても一貫して高い精度と堅牢なパフォーマンスを保証し、公平で精緻なパーソナライズを実現しました。
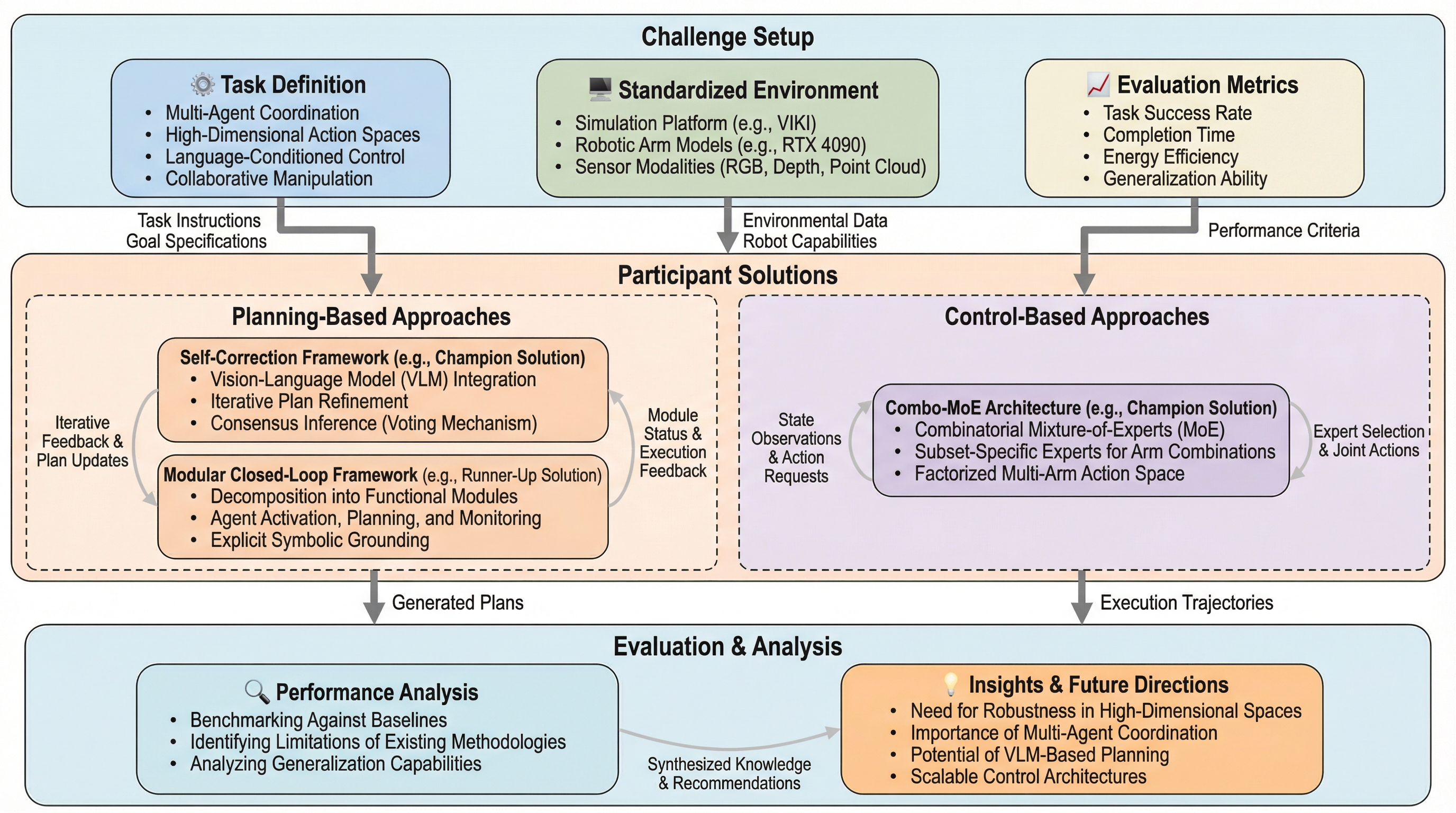
複雑なタスクを解決するため、複数のロボットが協力するマルチエージェント・ロボットシステム(MARS)チャレンジが提案された。この競技会は、視覚言語モデル(VLM)を用いた高レベルな「プランニング」と、物理シミュレーション環境での低レベルな「制御」の2つのトラックで構成されている。