レガシーな有限差分法コードをリバースエンジニアリングしてDevitoへ翻訳するAIエージェント
科学計算の基盤である膨大なレガシーFortranコードを現代的なGPU対応のDevito環境へ移行させるため、GraphRAGと多層的なAIエージェントを組み合わせた統合フレームワークが開発されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
科学計算の基盤である膨大なレガシーFortranコードを現代的なGPU対応のDevito環境へ移行させるため、GraphRAGと多層的なAIエージェントを組み合わせた統合フレームワークが開発されました。
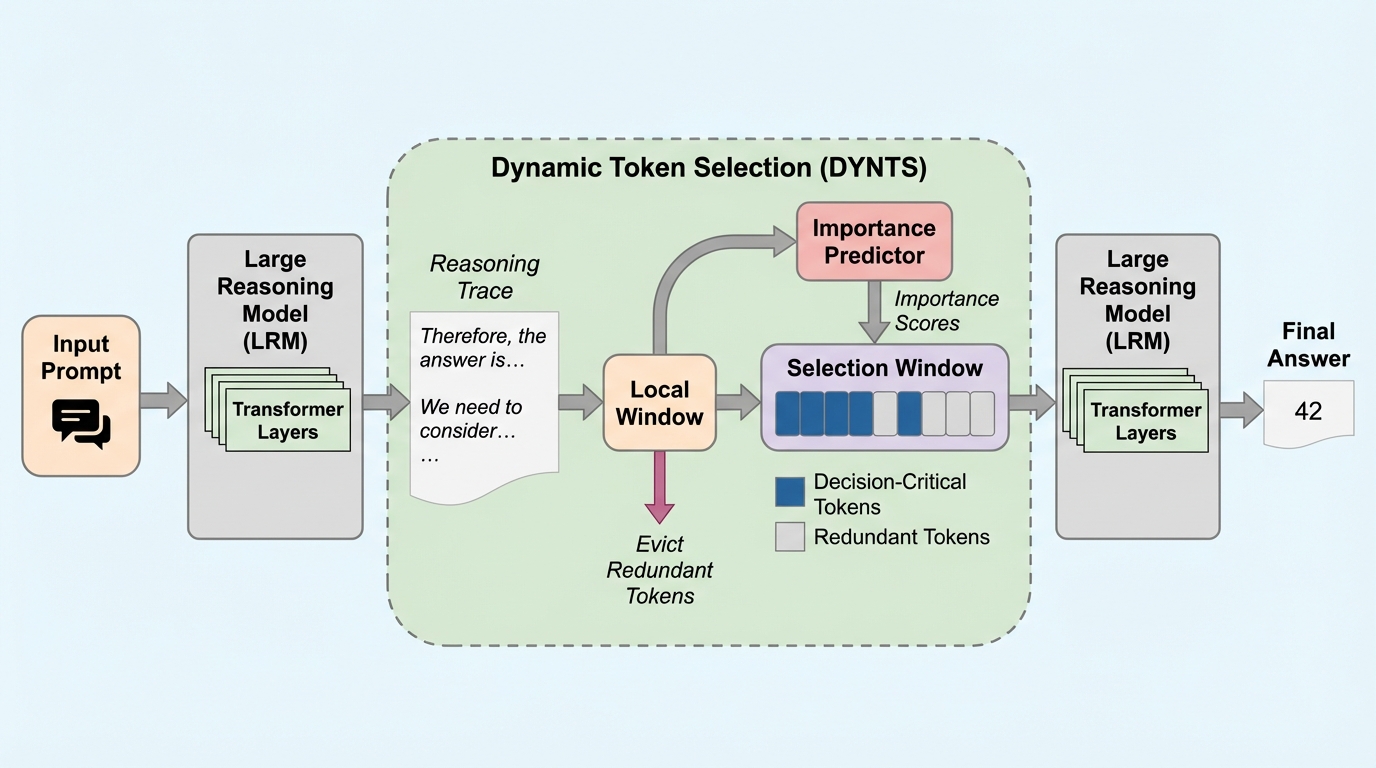
大規模推論モデル(LRM)が生成する膨大な思考プロセスは、メモリ消費と計算コストを増大させ、効率的な展開を妨げる深刻なボトルネックとなっています。本研究では、アテンションマップの解析により、思考トークンのうち最終的な回答に寄与するのはわずか約20%から30%の重要なトークンのみであり、残りの大部分は冗長であるという「推論におけるパレートの法則」を発見しました。この知見に基づき、重要な思考トークンを動的に予測・選択して保持し、不要なキャッシュを破棄する手法「DYNTS」を提案し、推論速度を最大2.62倍向上させ、メモリ使用量を最大5.73倍削減しつつ、フルキャッシュと同等の高い精度を維持することに成功しました。
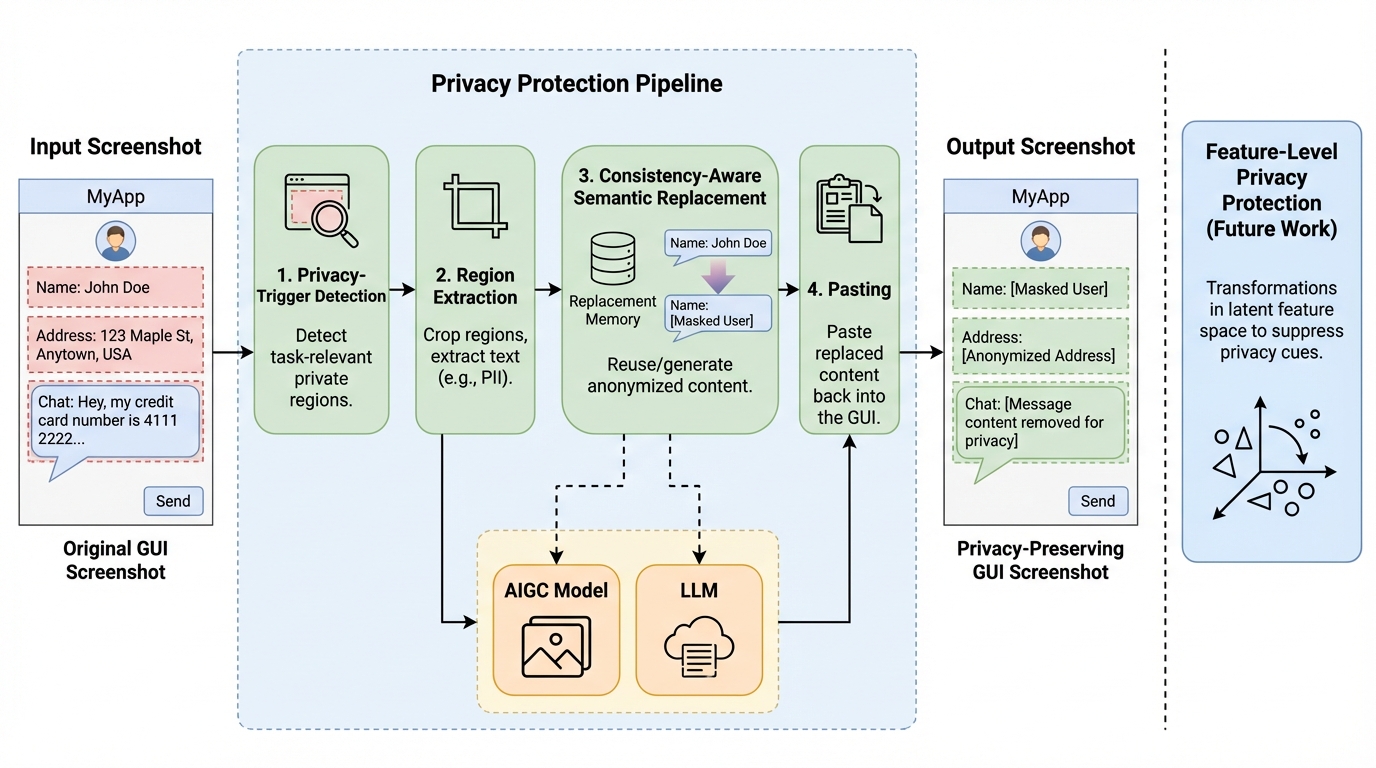
GUIエージェントが画面情報を外部サーバーへ送信する際の深刻なプライバシー漏洩リスクを解決するため、認識・保護・実行の3段階で構成される汎用フレームワーク「GUIGuard」を提案した。この手法は、機密情報の特定と加工をユーザーのローカルデバイスで行い、加工済みの安全な情報のみを強力なリモートモデルへ送信することで、高度な推論能力とプライバシー保護を両立させるものである。 1万枚以上のスクリーンショットを含む大規模ベンチマーク「GUIGuard-Bench」を構築し、既存の最新モデルでもプライバシー情報の認識精度が極めて低いという深刻な現状を明らかにした。Android環境で13.3%、PC環境で1.4%という結果は、現在のAIが何を守るべきかを正しく判断できていないことを示しており、実用化に向けた最大の障壁が認識精度にあることを浮き彫りにした。 機密情報を隠蔽しつつタスクの実行に必要な意味情報を維持する保護戦略を導入することで、ユーザーのプライバシー保護と自動化タスクの成功を高い次元で両立できることを実証した。本研究は、プライバシー認識の精度向上こそが実用的なGUIエージェント構築における最大のボトルネックであることを示し、信頼できるハイブリッド型サービスの実現に向けた具体的な技術的指針と評価基盤を提供している。
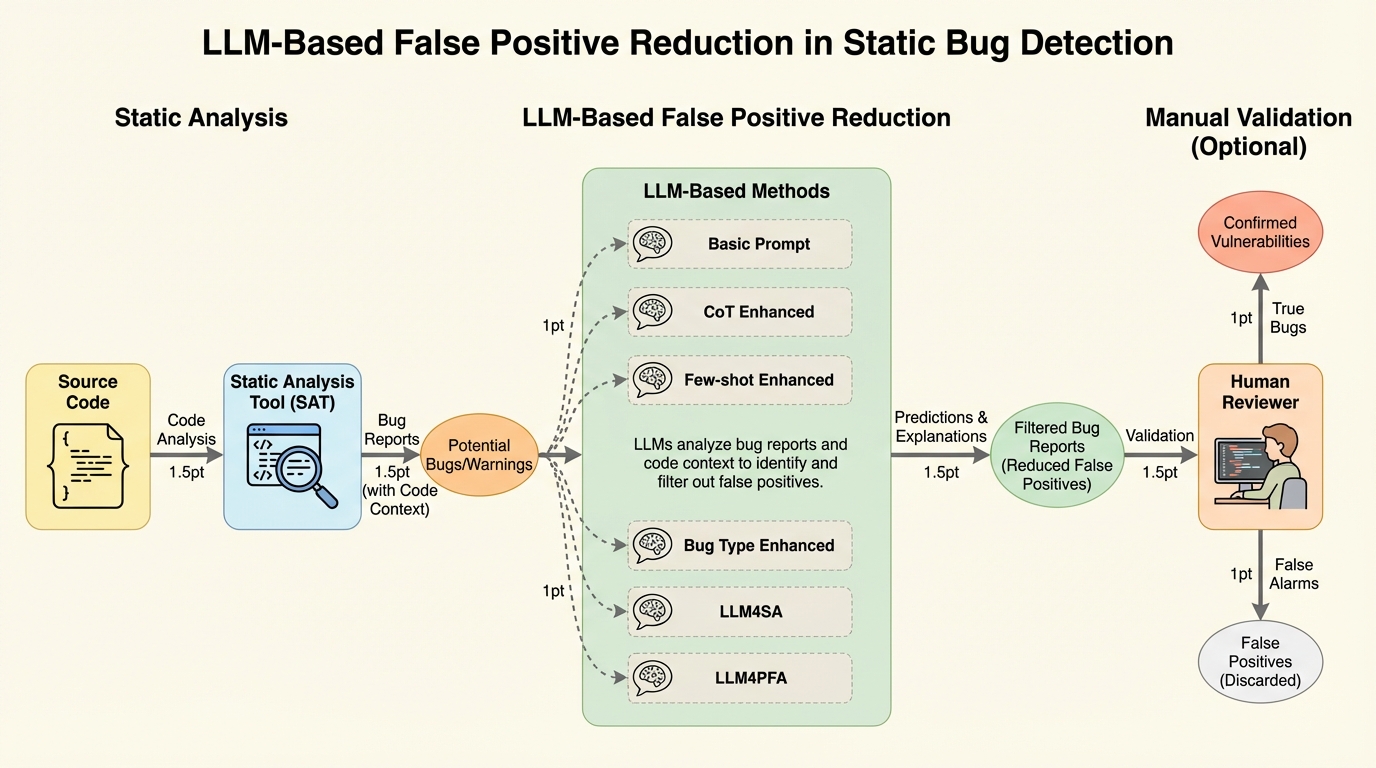
静的解析ツールは産業界で不可欠ですが、95%を超える高い誤検知率が開発者の大きな負担となっており、Tencentの調査では1件の警告を確認するのに平均10分から20分を費やしている実態が判明しました。
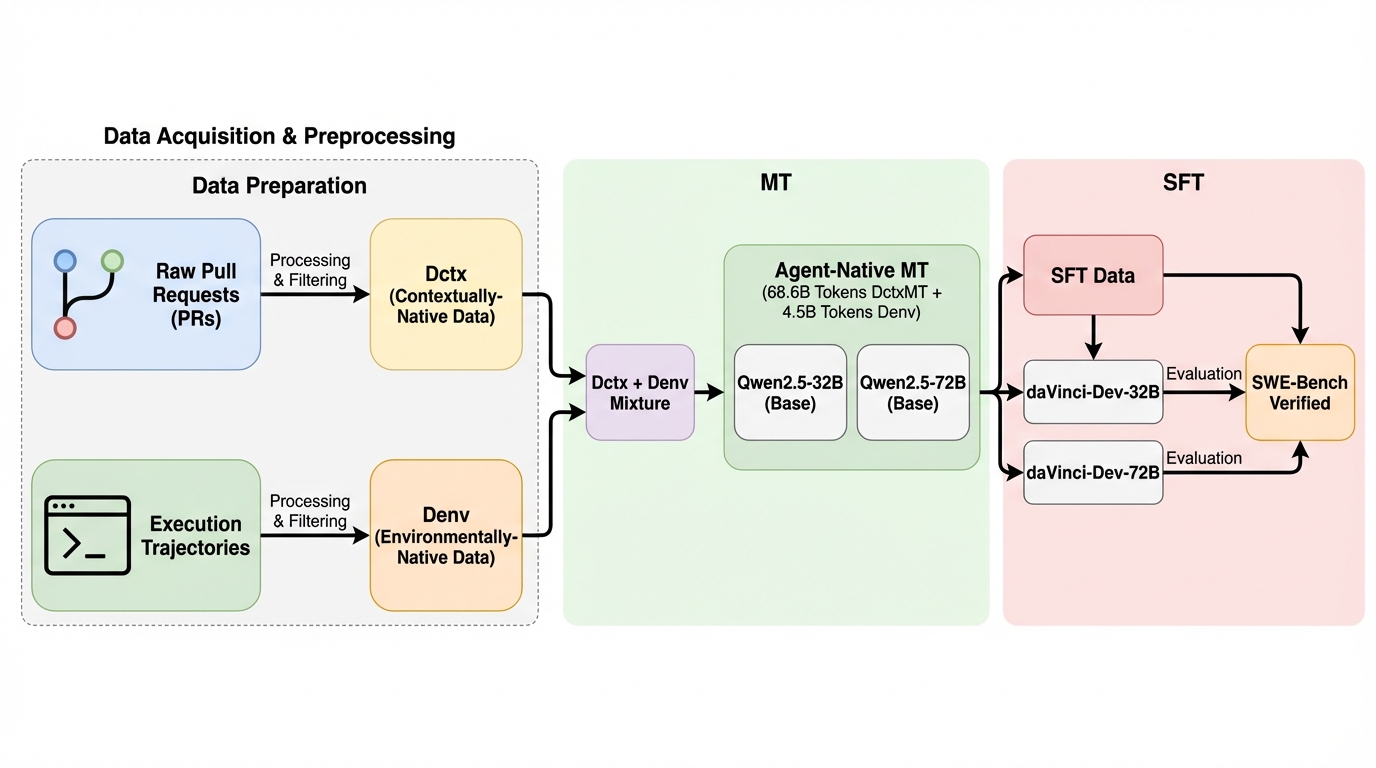
従来のコード生成モデルは単発の関数作成から、自律的にリポジトリを操作し編集やテストを行うエージェント型ソフトウェア工学へと進化していますが、学習データが静的なコードの断片に偏っているため、実際の開発現場で求められる動的なフィードバックへの対応や試行錯誤のプロセスを十分に学習できていないという深刻な分布の不一致が課題となっています。 本研究では、GitHubのプルリクエストから開発の文脈と編集の流れを再構成した「文脈ネイティブな軌跡」と、実際のDocker環境での実行結果やテストのフィードバックを記録した「環境ネイティブな軌跡」の二種類からなる「エージェントネイティブ・データ」を提案し、大規模な中間トレーニング(ミッドトレーニング)を実施することで、モデルに基礎的なエージェント能力を植え付ける手法を確立しました。 この手法を用いたdaVinci-Devモデルは、SWE-Bench Verifiedにおいて既存のオープンな手法であるKIMI-DEVを半分以下のトークン数で上回り、32Bモデルで56.1%、72Bモデルで58.5%という高い解決率を達成し、非コード特化型のベースモデルから出発しながらも、エージェント型ソフトウェア工学における新たな状態最高(SOTA)を記録するとともに、科学的推論や一般的なコード生成能力の向上も確認されました。
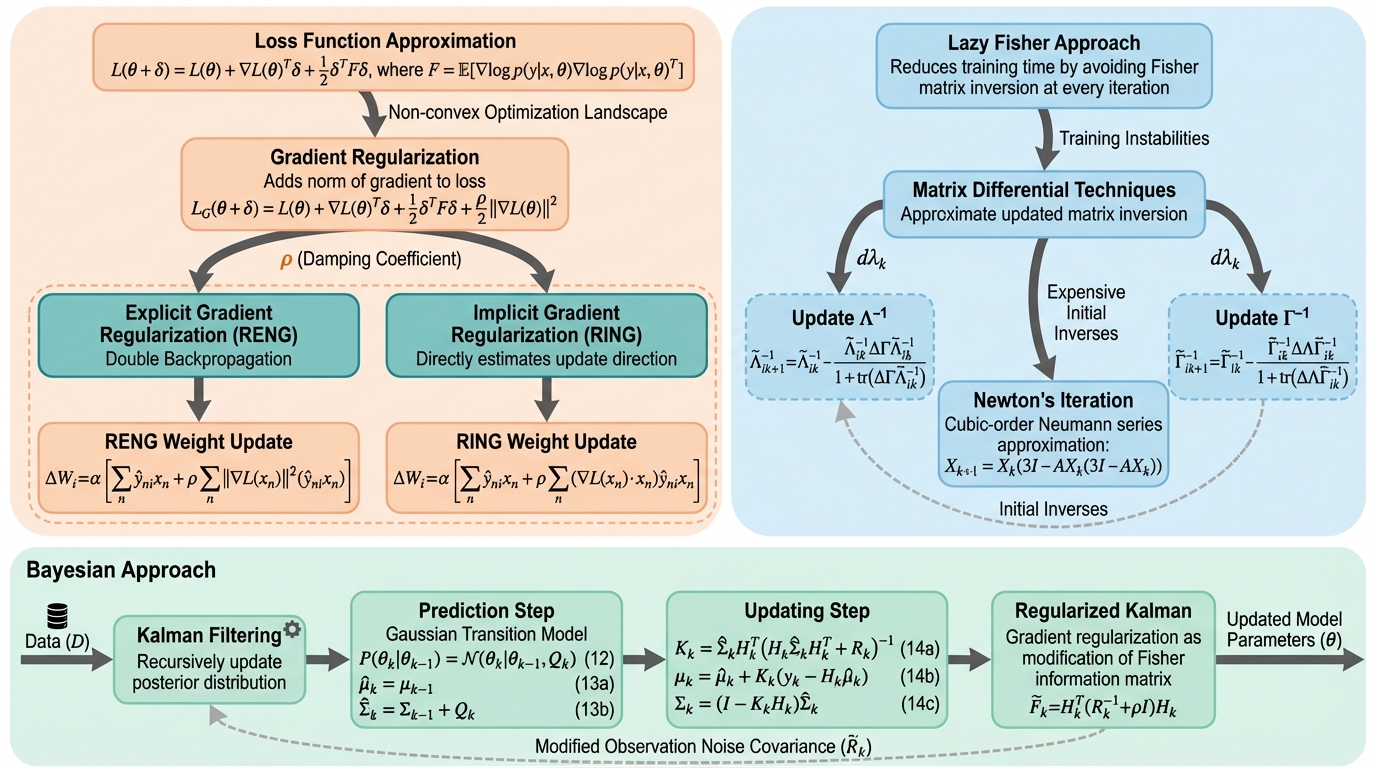
深層学習の訓練において、初期段階の収束を劇的に加速させる自然勾配法(NGD)と、損失景観の平坦な領域を探索して汎化性能を高める勾配正則化(GR)を統合した新しい最適化フレームワーク「GRNG」を提案した。
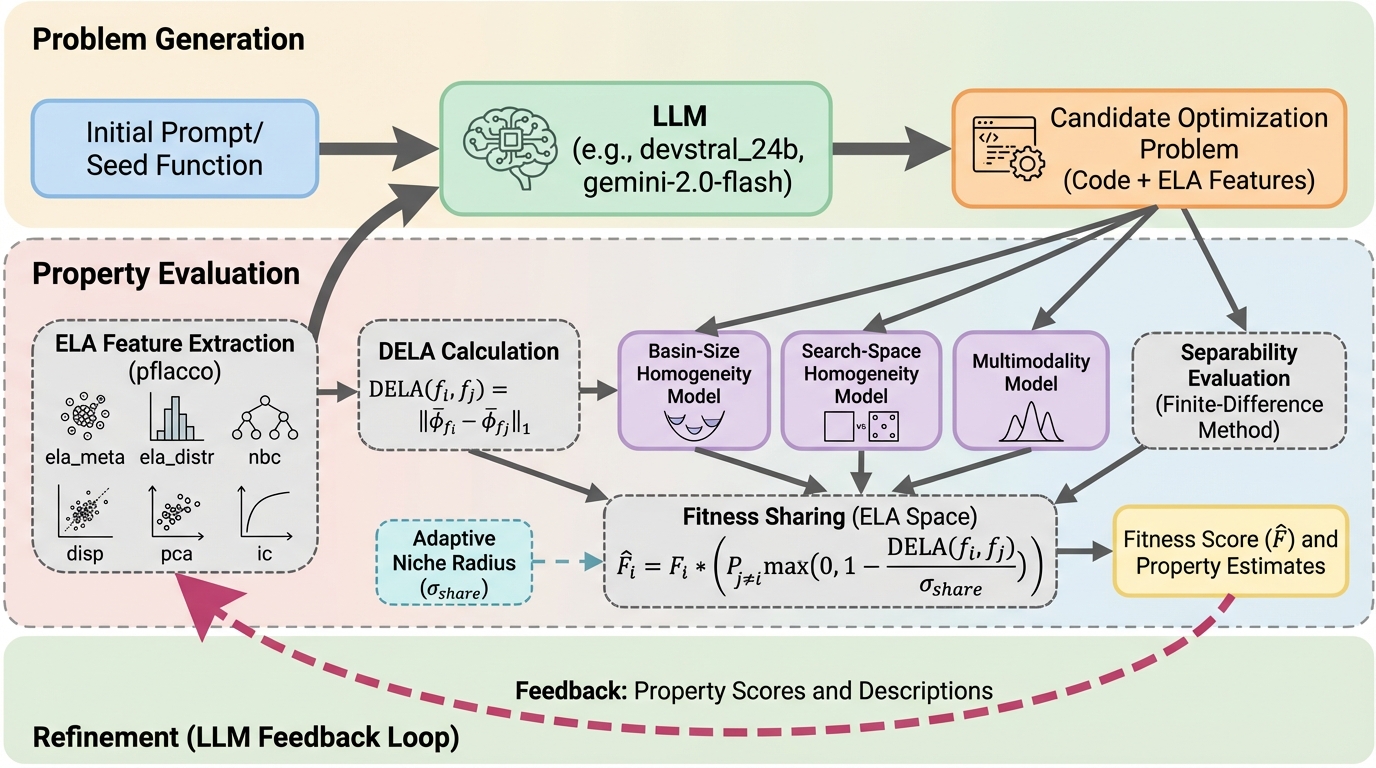
本研究では、大規模言語モデル(LLM)と進化計算を組み合わせたLLaMEAフレームワークを活用し、多峰性や分離可能性、探索空間の均一性といった特定の高レベルな構造的特性を備えた連続最適化問題を自動的に設計する新しい手法を提案した。
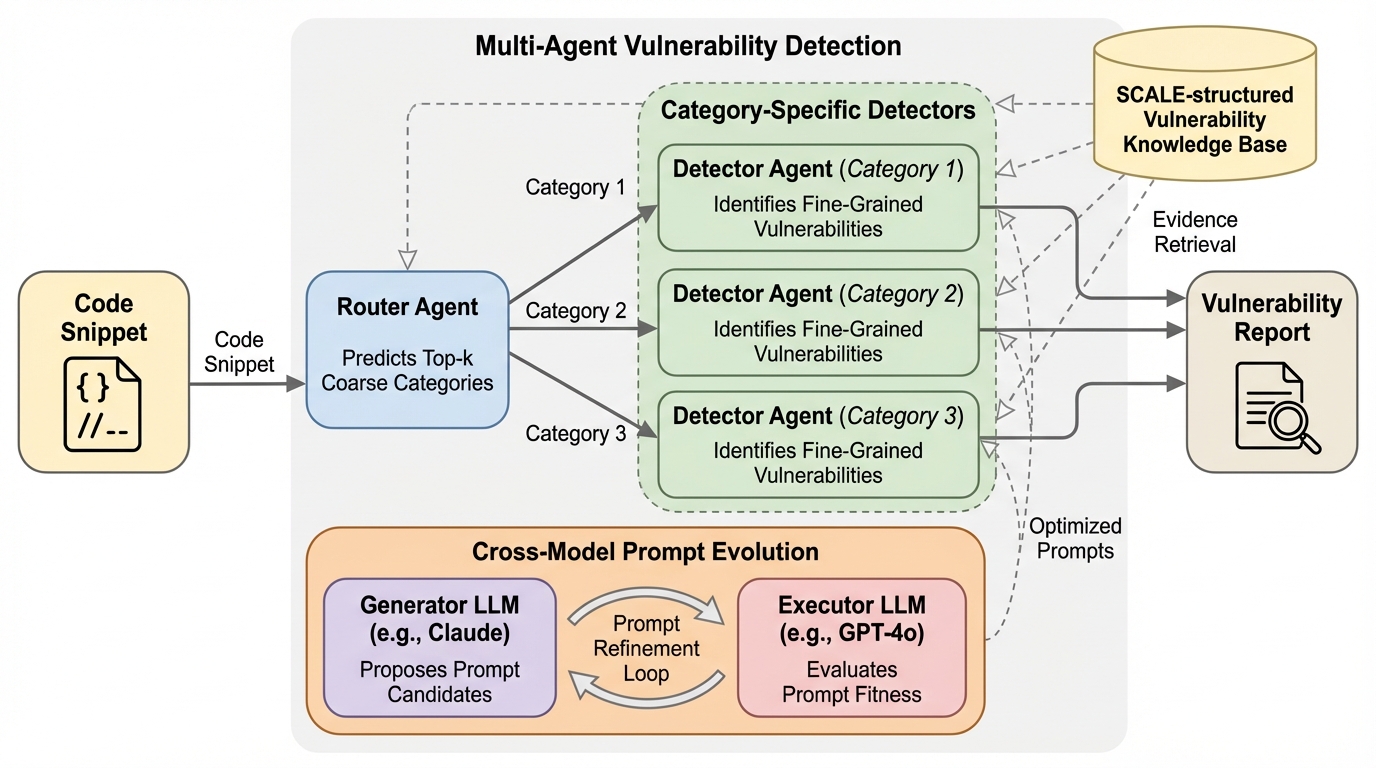
大規模言語モデルを用いた脆弱性検知において、多様な脆弱性パターンへの対応とプロンプト最適化の自動化を両立するため、ルーターと専門デテクターで構成されるマルチエージェント枠組み「MulVul」が提案されました。
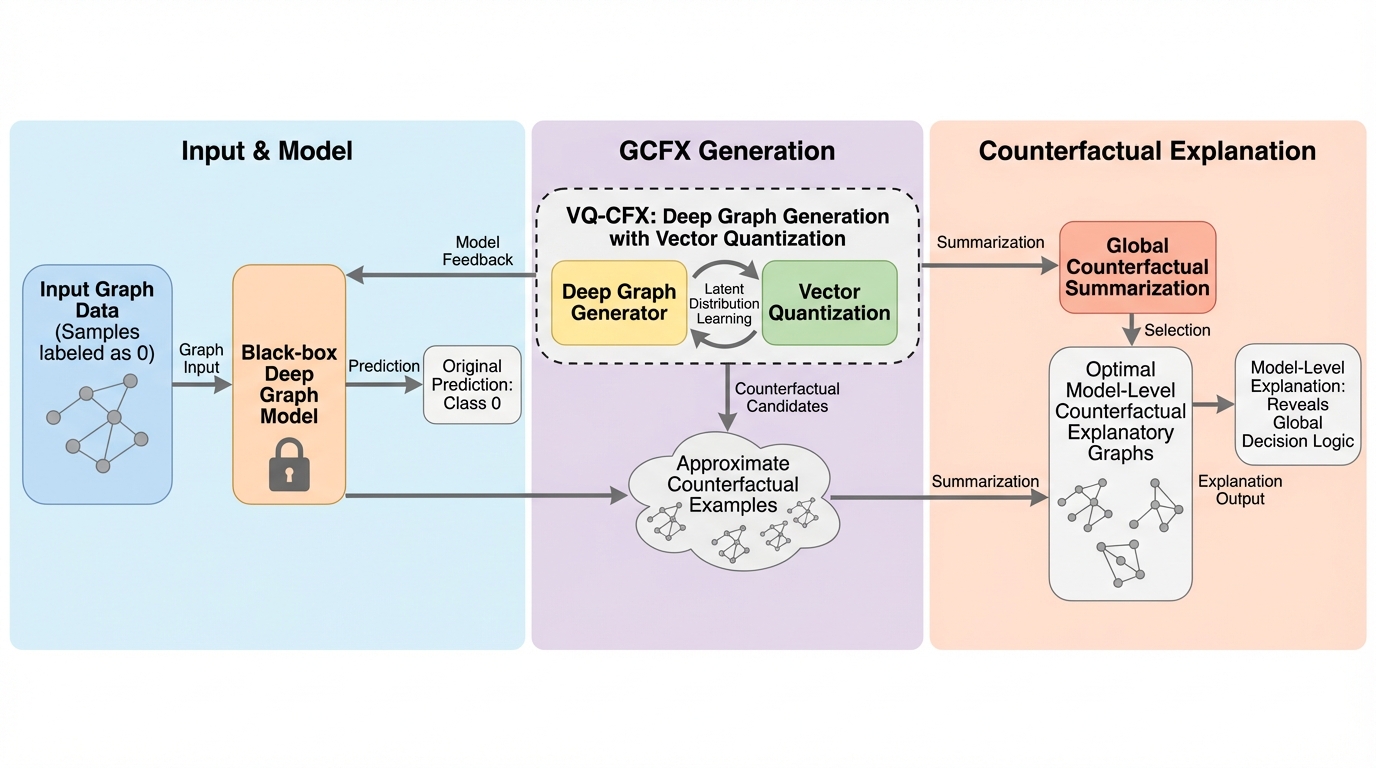
深層グラフ学習モデルの意思決定プロセスを全体的に把握するため、モデルレベルの反事実説明手法であるGCFXが提案されました。この手法は、ベクトル量子化を用いた生成モデルVQ-CFXによって高品質な反事実候補を生成し、要約アルゴリズムGCFSによって代表的かつ多様な説明セットを選択する二段構えの構成をとっています。
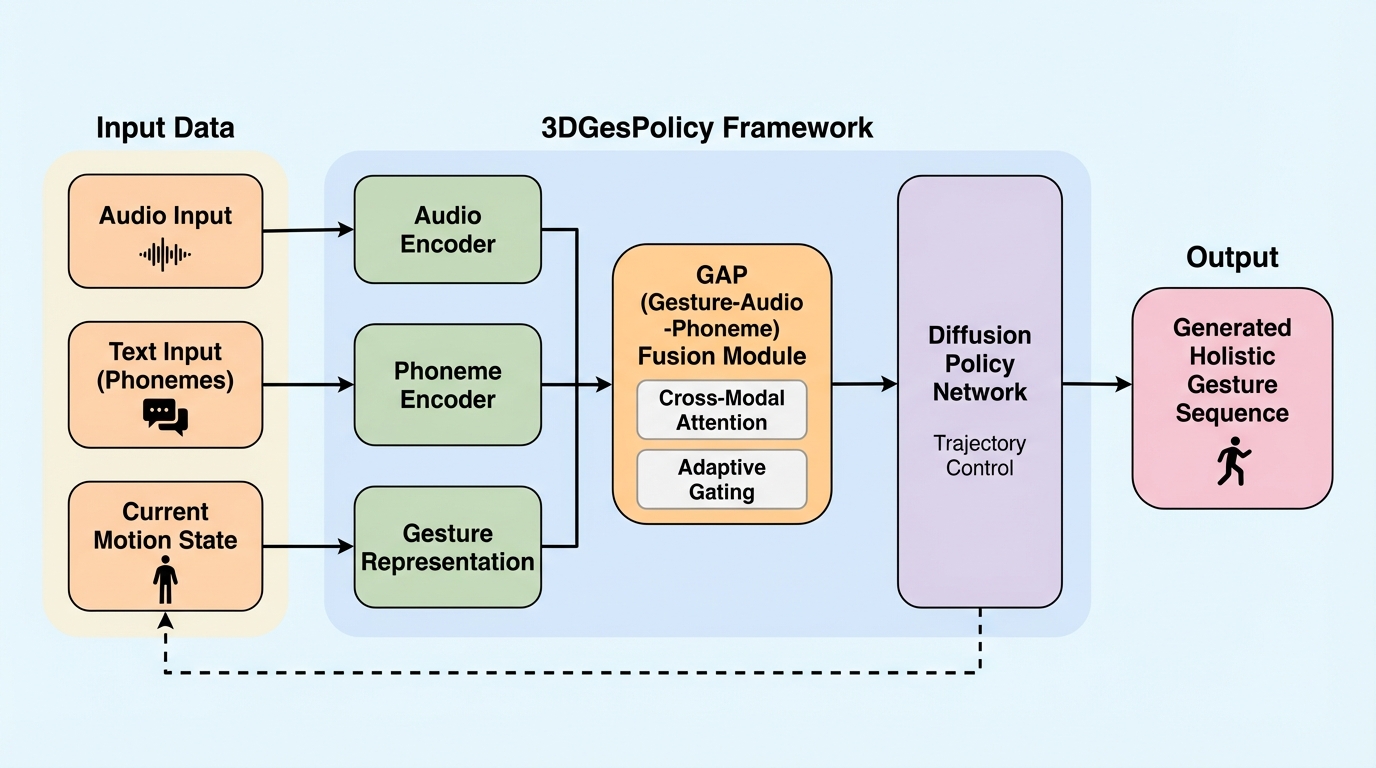
本研究は、ロボット工学の拡散ポリシー(Diffusion Policy)を応用し、全身の動きと顔の表情を統合的に生成する新しいフレームワーク「3DGesPolicy」を提案した。従来のフレーム単位の回帰や部位分解手法が抱えていた、空間的な不安定さや意味的な不整合という課題を解決するため、ジェスチャー生成を「連続的な軌道制御問題」として再定義し、フレーム間の変化を統一された「アクション」としてモデル化している。さらに、音素レベルの言語情報と音響特徴を高度に融合させるGAP(Gesture-Audio-Phoneme)モジュールを導入することで、発話内容と身体動作、唇の動きが精密に同期した、自然で表現力豊かなデジタルヒューマンの挙動を実現し、BEAT2データセットにおいて既存の最先端手法を上回る性能を実証した。