勾配正則化された自然勾配
深層学習の訓練において、初期段階の収束を劇的に加速させる自然勾配法(NGD)と、損失景観の平坦な領域を探索して汎化性能を高める勾配正則化(GR)を統合した新しい最適化フレームワーク「GRNG」を提案した。
TL;DR(結論)
深層学習の訓練において、初期段階の収束を劇的に加速させる自然勾配法(NGD)と、損失景観の平坦な領域を探索して汎化性能を高める勾配正則化(GR)を統合した新しい最適化フレームワーク「GRNG」を提案した。 計算コストの課題を解決するため、フィッシャー情報行列を構造的に近似し再利用する頻度主義的な手法(RING/RENG)と、カルマンフィルタの原理を応用して行列の反転計算を完全に排除するベイズ主義的な手法(R-Kalman)の二つのスケーラブルなアルゴリズムを開発した。 画像分類や自然言語処理の広範なベンチマークにおいて、AdamWやSophiaといった既存の有力な手法を上回る収束速度と高い精度を実証し、さらに二層ニューラルネットワークにおける大域的最小解への収束を理論的に保証することに成功した。
なぜこの問題か
深層ニューラルネットワーク(DNN)の規模が拡大し続ける中で、大規模なモデルを効率的に訓練し、かつ未知のデータに対して高い精度を発揮させる「高速な収束」と「高い汎化性能」の両立は、依然として機械学習における根本的な課題である。 自然勾配法(NGD)は、損失関数の曲率情報を考慮することで、特定の条件下において極めて少ない反復回数で最適解に到達できるという優れた理論的特性を持っており、複雑な損失景観においても訓練を安定させ、収束を加速させることができるため注目されている。 しかし、自然勾配法を数億から数千億のパラメータを持つトランスフォーマーのような大規模モデルに適用しようとすると、フィッシャー情報行列(FIM)の計算と、その巨大な行列の反転計算に膨大な計算リソースと時間が必要となり、実用上の大きな障壁となっていた。 一方で、勾配正則化(GR)は、損失関数の勾配ノルムを正則化項として加えることで、最適化の軌跡を損失景観のより平坦な領域へと導き、訓練済みモデルの汎化性能や堅牢性を向上させることが知られている。…
核心:何を提案したのか
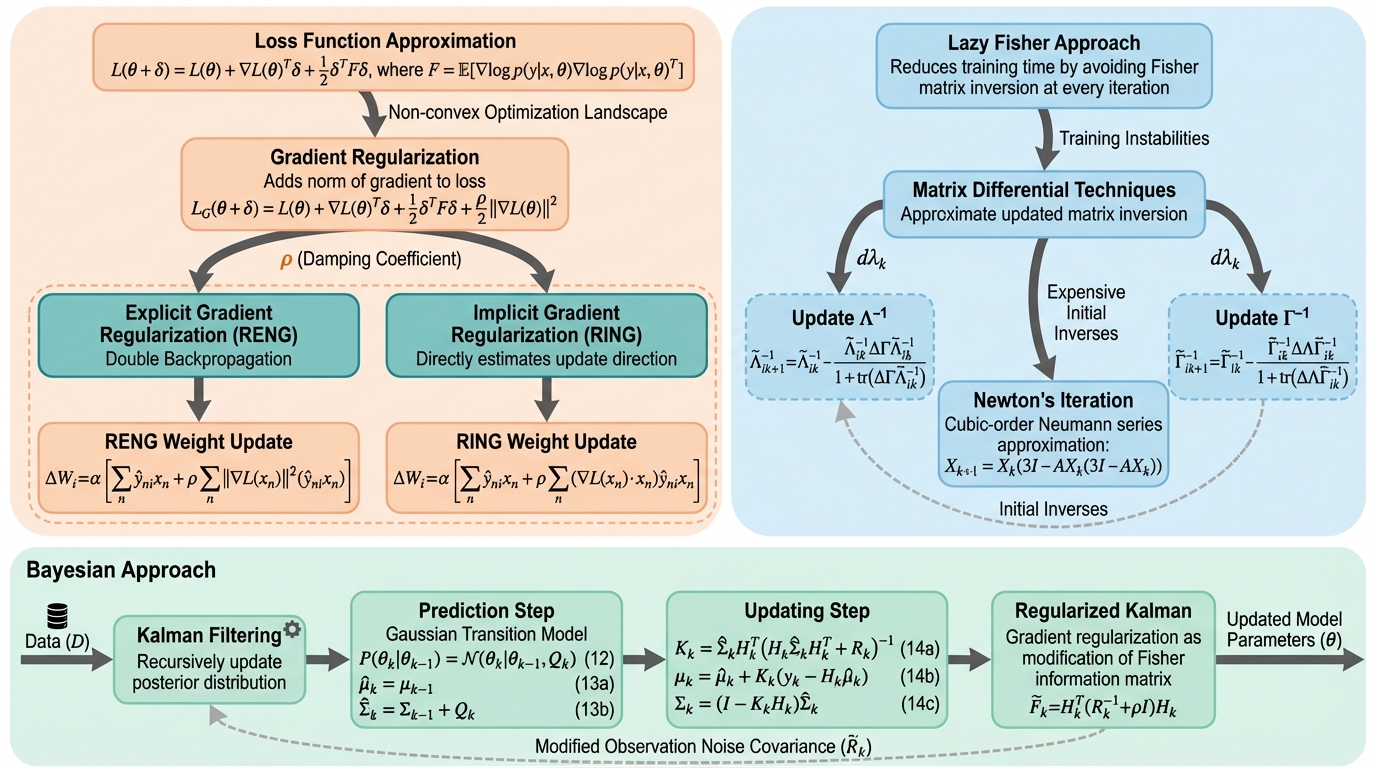
本研究では、明示的な勾配正則化と自然勾配の更新を一つの枠組みで統合した、スケーラブルな二次最適化手法のファミリーである「Gradient-Regularized Natural Gradients(GRNG)」を提案した。 このフレームワークは、計算上の課題を解決するために、統計学的な背景が異なる二つの相補的なアプローチを提供している。 一つは頻度主義的な観点から設計されたアルゴリズムで、フィッシャー情報行列の構造的近似とニュートン反復法を組み合わせることで、計算効率を劇的に向上させている。 この頻度主義的アプローチには、更新方向に正則化の効果を直接反映させる暗黙的な手法(RING)と、勾配ノルムの二乗を直接計算して逆伝播を行う明示的な手法(RENG)の二種類が含まれている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related