daVinci-Dev:ソフトウェア工学のためのエージェントネイティブな中間トレーニング
従来のコード生成モデルは単発の関数作成から、自律的にリポジトリを操作し編集やテストを行うエージェント型ソフトウェア工学へと進化していますが、学習データが静的なコードの断片に偏っているため、実際の開発現場で求められる動的なフィードバックへの対応や試行錯誤のプロセスを十分に学習できていないという深刻な分布の不一致が課題となっています。 本研究では、GitHubのプルリクエストから開発の文脈と編集の流れを再構成した「文脈ネイティブな軌跡」と、実際のDocker環境での実行結果やテストのフィードバックを記録した「環境ネイティブな軌跡」の二種類からなる「エージェントネイティブ・データ」を提案し、大規模な中間トレーニング(ミッドトレーニング)を実施することで、モデルに基礎的なエージェント能力を植え付ける手法を確立しました。 この手法を用いたdaVinci-Devモデルは、SWE-Bench Verifiedにおいて既存のオープンな手法であるKIMI-DEVを半分以下のトークン数で上回り、32Bモデルで56.1%、72Bモデルで58.5%という高い解決率を達成し、非コード特化型のベースモデルから出発しながらも、エージェント型ソフトウェア工学における新たな状態最高(SOTA)を記録するとともに、科学的推論や一般的なコード生成能力の向上も確認されました。
TL;DR(結論)
従来のコード生成モデルは単発の関数作成から、自律的にリポジトリを操作し編集やテストを行うエージェント型ソフトウェア工学へと進化していますが、学習データが静的なコードの断片に偏っているため、実際の開発現場で求められる動的なフィードバックへの対応や試行錯誤のプロセスを十分に学習できていないという深刻な分布の不一致が課題となっています。 本研究では、GitHubのプルリクエストから開発の文脈と編集の流れを再構成した「文脈ネイティブな軌跡」と、実際のDocker環境での実行結果やテストのフィードバックを記録した「環境ネイティブな軌跡」の二種類からなる「エージェントネイティブ・データ」を提案し、大規模な中間トレーニング(ミッドトレーニング)を実施することで、モデルに基礎的なエージェント能力を植え付ける手法を確立しました。 この手法を用いたdaVinci-Devモデルは、SWE-Bench Verifiedにおいて既存のオープンな手法であるKIMI-DEVを半分以下のトークン数で上回り、32Bモデルで56.1%、72Bモデルで58.5%という高い解決率を達成し、非コード特化型のベースモデルから出発しながらも、エージェント型ソフトウェア工学における新たな状態最高(SOTA)を記録するとともに、科学的推論や一般的なコード生成能力の向上も確認されました。
なぜこの問題か
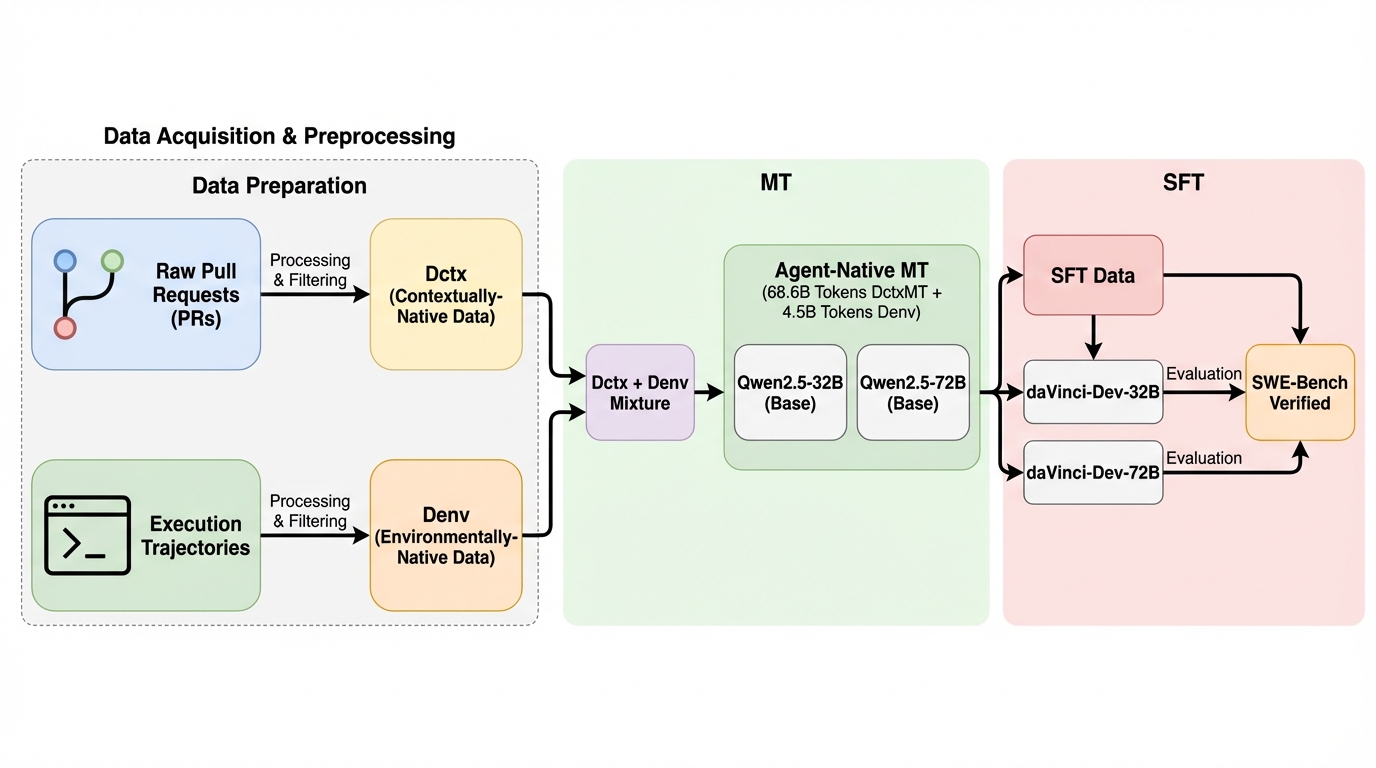
大規模言語モデル(LLM)によるコード生成の能力は、単一の関数を合成する段階から、リポジトリ全体を対象とした複雑なソフトウェア工学タスクを解決する段階へと急速に拡大しています。現実の開発環境では、バグの修正や新機能の実装において、モデルが自律的にコードベースを探索し、ファイル間の依存関係を理解し、編集を適用した上でテストを実行して変更を検証するという、反復的なエージェントとしての振る舞いが求められます。しかし、現在主流となっている事後学習(ポストトレーニング)の手法、すなわち少数のデータを用いた教師あり微調整(SFT)や実行フィードバックからの強化学習(RL)には、データの量と多様性の両面で限界があります。 特に、実行可能な環境を構築できるリポジトリの数は、READMEの記述の不透明さや計算リソースの制約により限られており、高品質なエージェントの軌跡を人間が作成するには膨大なコストがかかります。さらに、事後学習だけではベースモデルが本来持っていないエージェントとしての推論能力を十分に引き出せない可能性が指摘されています。…
核心:何を提案したのか
本研究では、ソフトウェア工学におけるエージェント能力を大規模に開発するための「エージェントネイティブな中間トレーニング」という新しいパラダイムを提案しました。その中心となるのは、エージェントが実際の運用中に経験する情報の流れと環境の動態を保存した「エージェントネイティブ・データ」の構築です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related