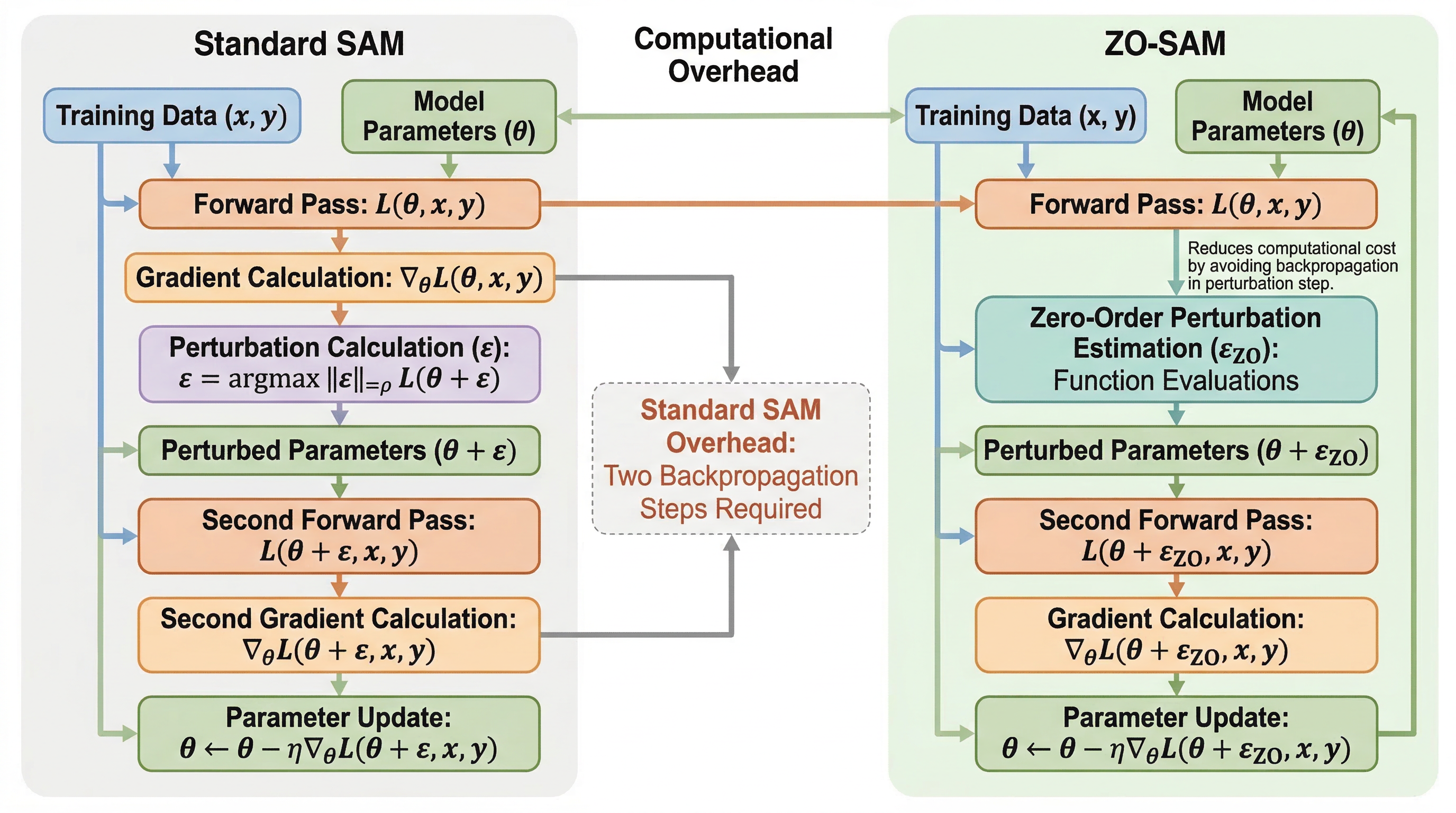
ZO-SAM:スパース学習で SAM の効き目を残したまま計算負荷を抑える
高い疎性では勾配が荒れやすく、スパース学習は収束も汎化も不安定になりがちです。ZO-SAM は SAM の摂動生成だけをゼロ次最適化に置き換え、平坦な解を探す利点を残しながら計算負荷を抑えることで、精度・収束・頑健性の三つを同時に改善しようとします。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
高い疎性では勾配が荒れやすく、スパース学習は収束も汎化も不安定になりがちです。ZO-SAM は SAM の摂動生成だけをゼロ次最適化に置き換え、平坦な解を探す利点を残しながら計算負荷を抑えることで、精度・収束・頑健性の三つを同時に改善しようとします。
PsyCogMetrics AI Lab は、心理測定学と認知科学の方法論を取り込みつつ、クラウド上で使える統合評価プラットフォームとして設計された IT アーティファクトです。論文の核心は、評価結果そのものよりも、three-cycle Action Design Science によって LLM 評価基盤をどう設計すべきかを具体化した点にあります。
GRPO はグループ平均との差で学習を進めますが、同じグループ内に自然に生まれる正解トレースと誤答トレースの対比を、そのままでは十分に使えていません。BICC と RCC はこの比較情報を直接学習に取り込み、追加サンプリングや補助モデルなしで推論精度と学習安定性を底上げする提案です。
ESG レポートは長く複雑で、しかも規制や投資判断に直結するため、LLM がもっとも苦手な「長文から事実だけを抜く」課題がそのまま表面化します。 ESG-Bench は、実在の ESG レポートに基づく human-annotated QA と hallucination ラベルを備えたベンチマークで、LLM が答えるべき場面と「答えないべき」場面の両方を評価できるようにした点が特徴です。 さらに 4-step CoT を使った fine-tuning は、通常の prompting や単純な SFT より hallucination を強く抑え、しかもその改善が HaluEval や BioASQ のような他ベンチにも波及することが示されました。
意味が同じ入力変形に対して推論がどれだけ安定するかを「意味不変性」として捉え、エージェント型AIの信頼性を測る独立した評価軸として提示しました。 / 8種類の意味保存変換を用いた変成的テストにより、7つの基盤モデルを19問・8科学領域で比較し、固定ベンチマークの正答率だけでは見えない脆さを可視化しました。
メンバーシップ推論攻撃の脆弱性はモデル全体ではなく、ごく少数の重みに集中しており、その多くは精度にも重要でした。論文は、危険な重みを削除する代わりに初期値へ巻き戻して固定し、残りだけを微調整する CWRF を提案し、LiRA や RMIA に対する耐性と精度の両立を示します。
LLM が集団の協力行動を高める影響戦略を作れてしまう一方で、その協力が自律性や公正性を壊した「操作された協力」になり得る点を問題にしています。 / 著者らは Constitutional Multi-Agent Governance(CMAG)という二段階の統治枠組みを提案し、禁止テーマや誇張表現を弾く hard constraints と、協力・自律性・整合性・公平性の釣り合いで選ぶ soft optimization を組み合わせます。 / 80エージェントのスケールフリーネットワーク実験では、無制約最適化が生の協力率では最高でも倫理協力スコアでは最悪になり、CMAG は協力率を少し落とす代わりに自律性・整合性・公平性を大きく守る結果になりました。
命令チューニング用データを表面的な品質指標ではなく、モデル内部のニューロン活性パターンで選ぶ枠組み NAIT を提案しています。狙いは、特定能力を伸ばすのに本当に効くデータだけを、小さく安く選び抜くことです。
chart・table・SVG などの vision-to-code タスクでは、出力コードが文字列として近いだけでは足りず、最終的に描画された見た目がどれだけ元画像に忠実かを見なければ本当の品質は測れません。 Visual-ERM は、生成コードをレンダリングした画像と元画像を直接比較し、差分の種類・位置・重要度まで含むきめ細かい報酬を返すことで、強化学習の報酬信号を視覚空間で整合させます。 その結果、Qwen3-VL-8B-Instruct の chart-to-code は +8.4、table/SVG でも平均 +2.7 / +4.1 改善し、VC-RewardBench では 8B でありながら 235B 級のモデルを上回る評価性能を示しました。
ToMBench-Hardで社会的推論のショートカットを露出させ、SIPに沿う多次元報酬で推論過程全体を監督するSocial-R1を提案した論文です。