感情をMEGで拡大する:注釈付き脳データからの感情分析
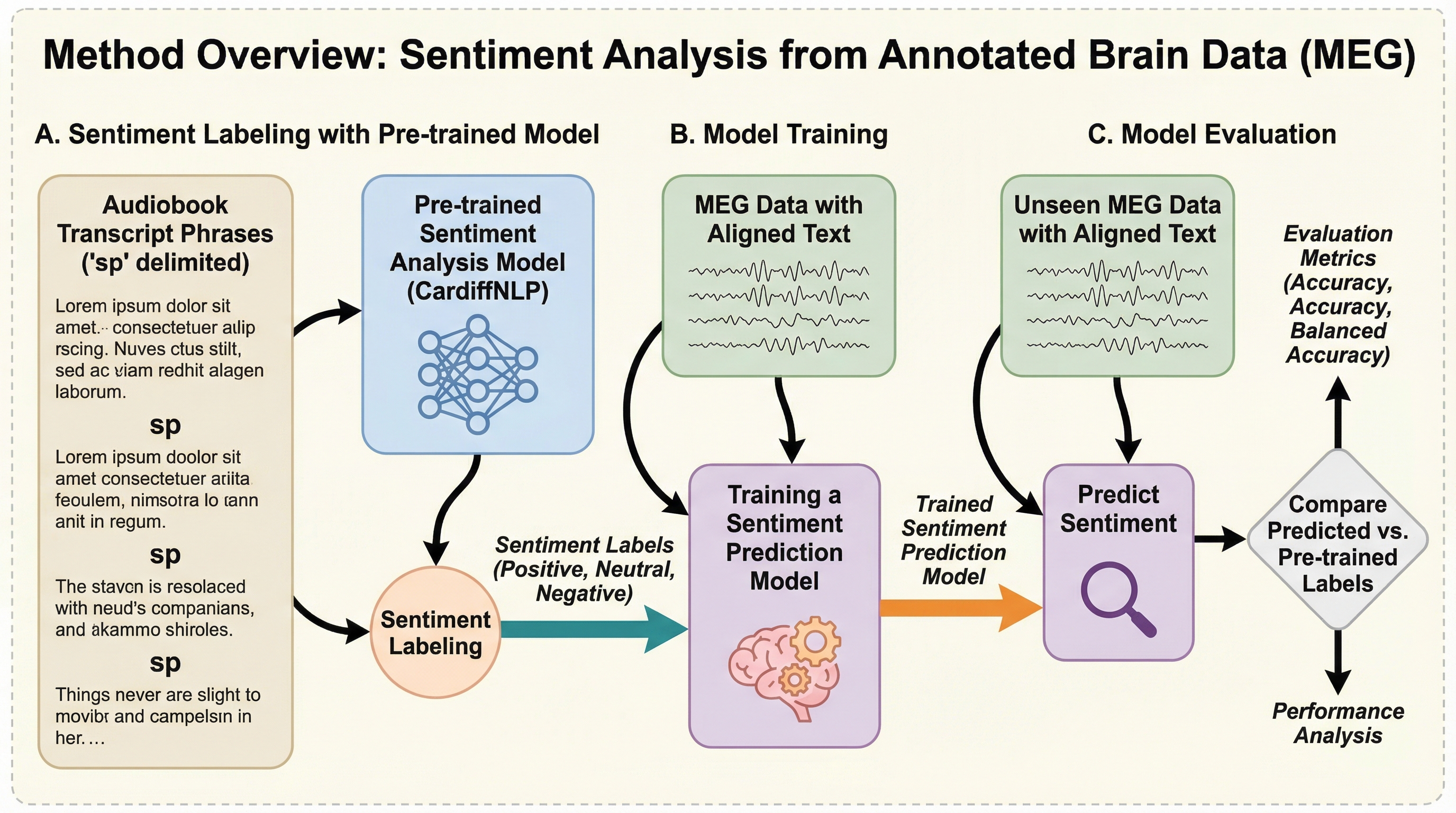
本研究は、感情ラベルが欠如している既存の脳磁図(MEG)データセットに対し、事前学習済みのテキスト感情分析モデルを用いて自動的に注釈を付与する革新的なパイプラインを提案しました。 シャーロック・ホームズの物語を聴取中の脳活動データと、テキストから抽出した感情スコアを時間軸で精密に統合することで、大規模な訓練データを構築し、脳信号から直接感情を解読するモデルの構築に成功しました。 実験の結果、多層パーセプトロン(MLP)や長短期記憶(LSTM)を用いた予測モデルは、統計的に有意な精度で感情状態を識別でき、非侵襲的な脳計測データから複雑な心理状態を読み取るための概念実証を提示しました。