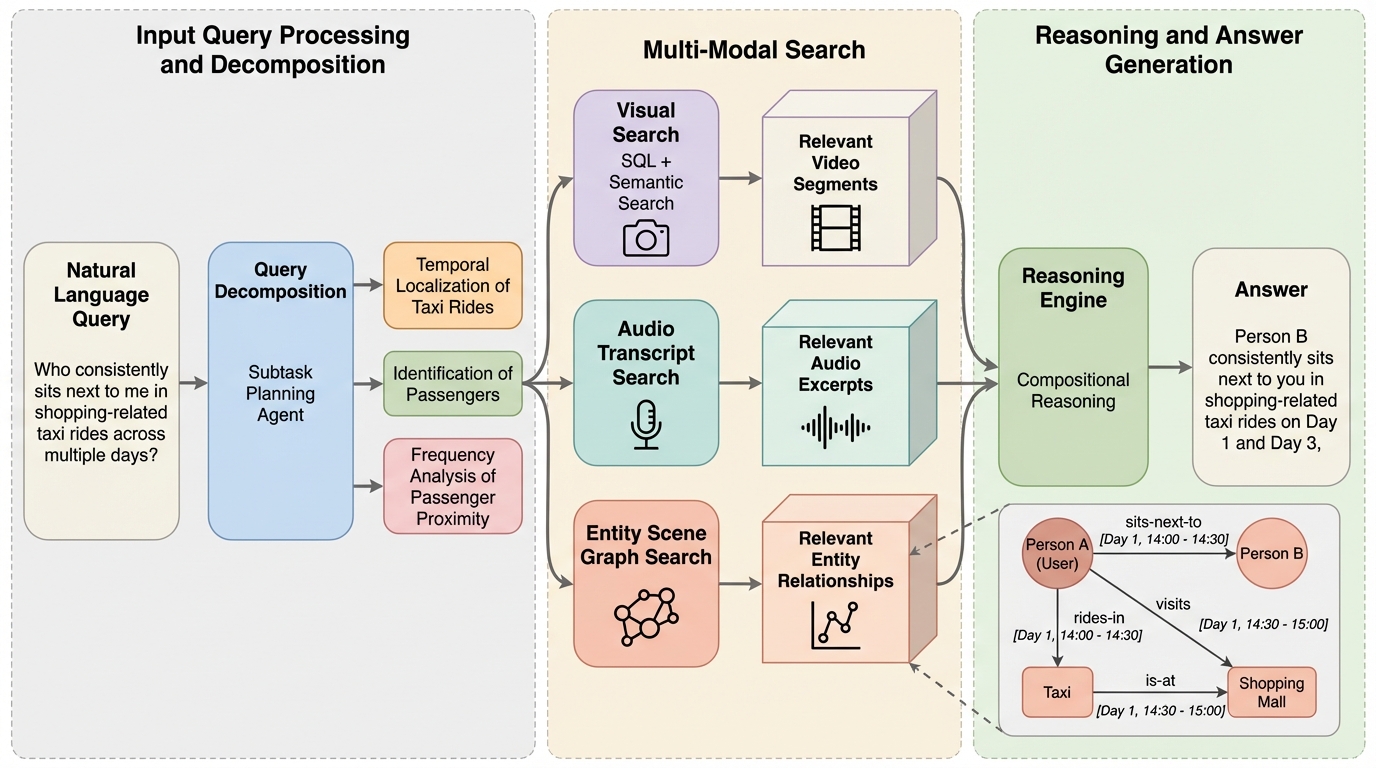
エージェントによる超長時間動画理解
スマートグラス等のウェアラブルデバイスが記録する数日間にわたる膨大な一人称視点動画を理解するため、人物・物体・場所とその関係性を時間情報と共に構造化した「エンティティ・シーングラフ(ESG)」を活用する新フレームワーク「EGAgent」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
スマートグラス等のウェアラブルデバイスが記録する数日間にわたる膨大な一人称視点動画を理解するため、人物・物体・場所とその関係性を時間情報と共に構造化した「エンティティ・シーングラフ(ESG)」を活用する新フレームワーク「EGAgent」が提案されました。
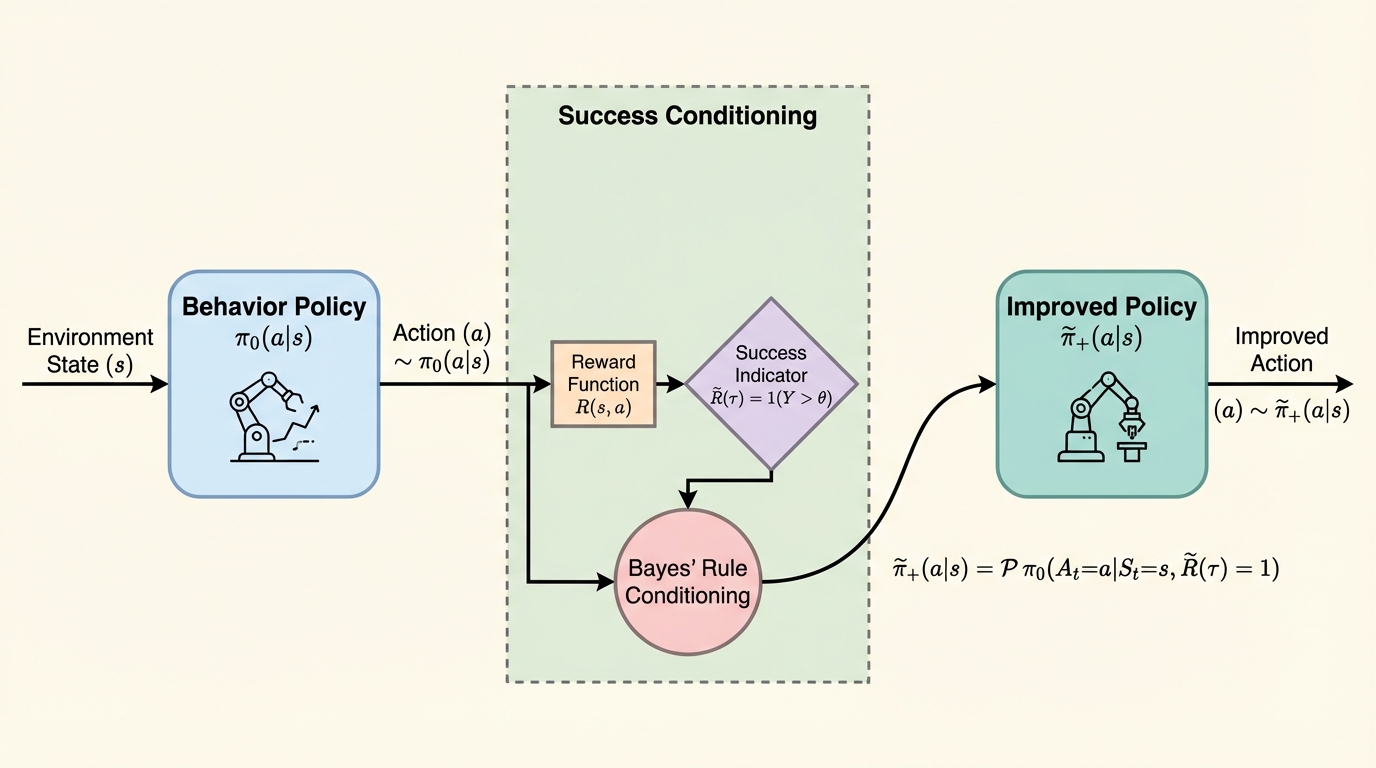
成功条件付け(成功した軌跡を模倣する手法)は、LLMの調整や強化学習で広く使われていますが、その理論的な最適化対象は不明でした。本論文は、この手法が$\chi^2$ダイバージェンスを制約とした信頼領域最適化問題を正確に解いていることを証明しました。
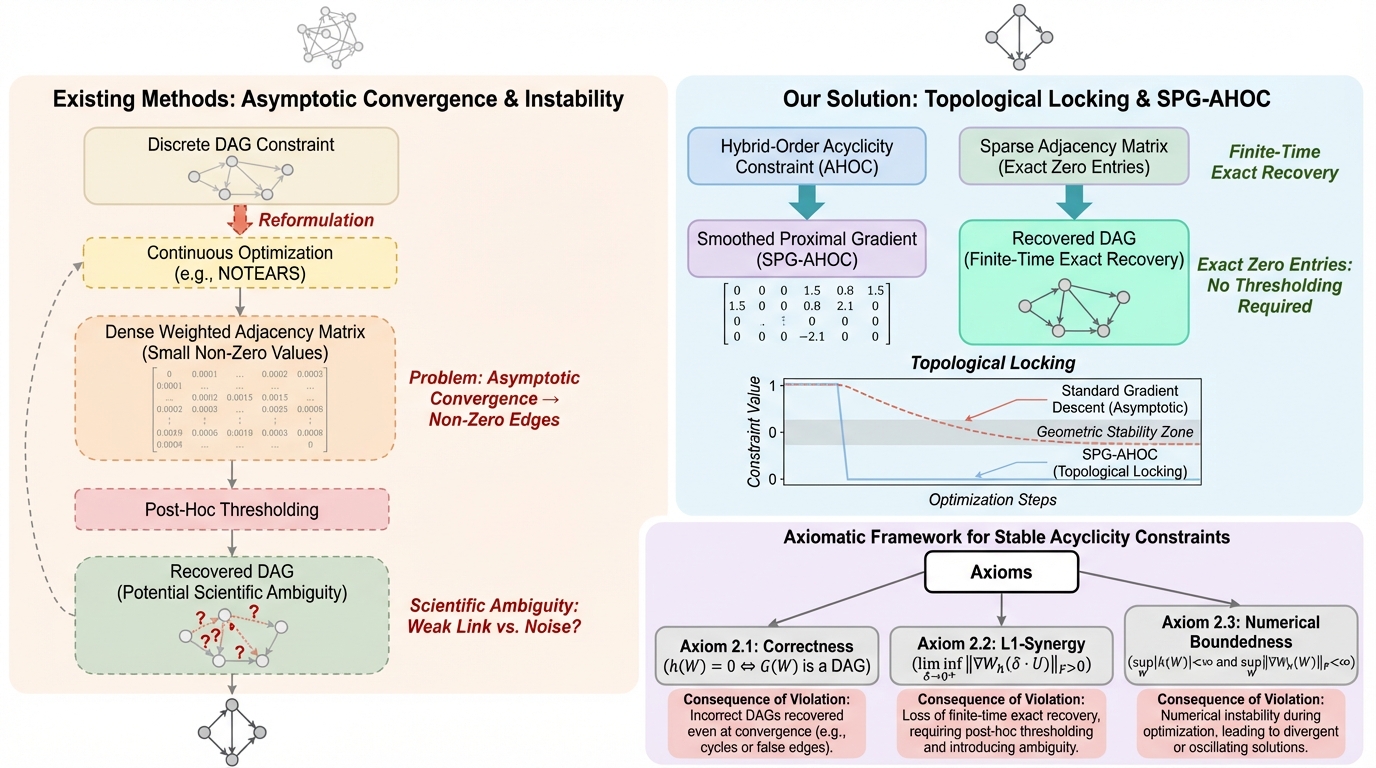
因果探索における連続最適化手法は、漸近的な収束に留まるため離散的なグラフ構造の復元に恣意的な閾値処理を必要とするという根本的な課題を抱えていた。本研究は、ハイブリッド次数非巡回制約(AHOC)と平滑化近接勾配法(SPG-AHOC)を提案し、近接演算子の「トポロジカル・ロッキング」機構によって有限時間内に正確な構造を特定する理論的保証を与えた。実験では、合成データおよび実世界のSachsデータセットにおいて、構造的制約の不安定性を解消しながら、既存手法を上回る最先端の精度と正確なゼロエントリの復元を達成している。
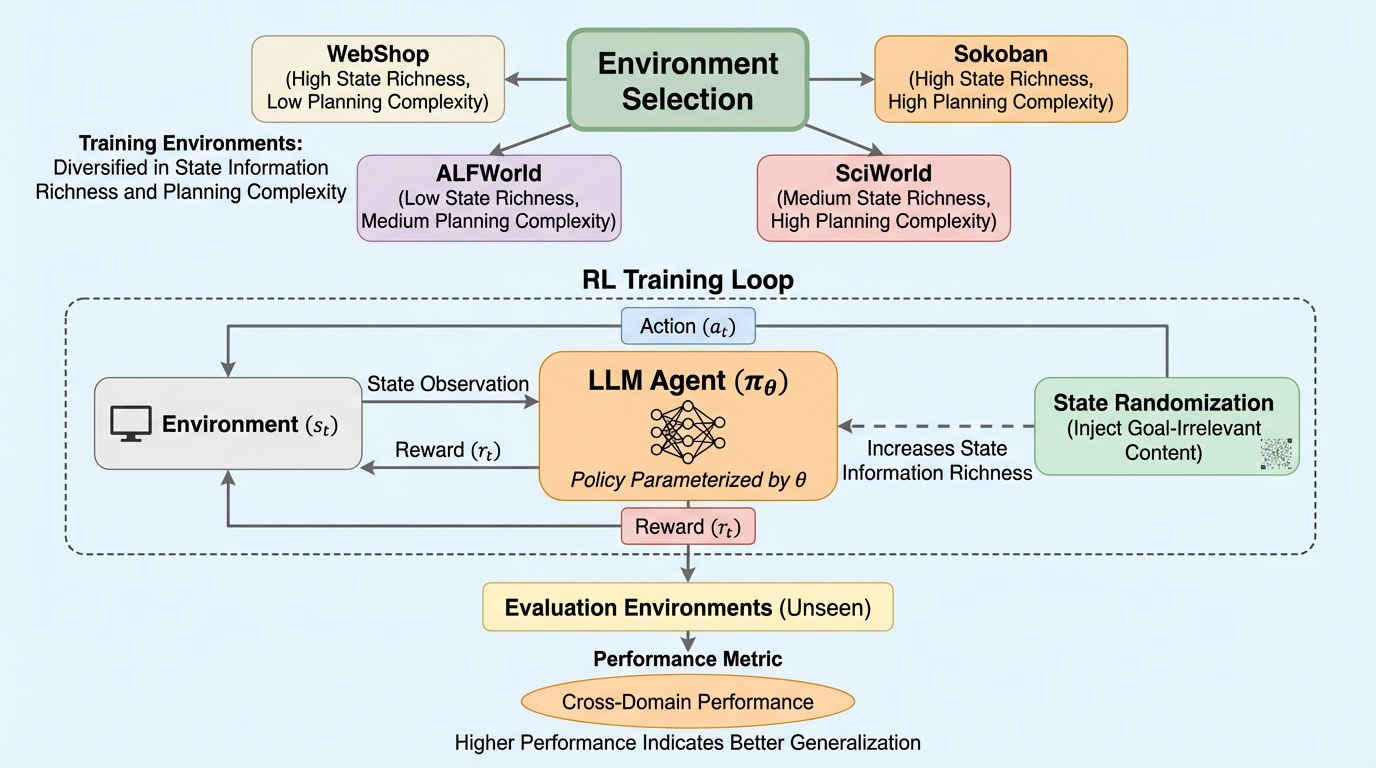
LLMエージェントを強化学習で訓練する際、学習した特定の環境には適応する一方で未知の環境での性能が低下する「汎化税」が大きな課題となっている。本研究では、4つの異なるエージェント環境を用いた詳細な分析を通じて、「状態情報の豊かさ」と「計画の複雑さ」という二つの環境特性が、未知のドメインへの汎化性能と強く相関することを突き止めた。 この知見に基づき、タスクの本質を変えずに状態情報へ少量の無関係なノイズを加える「状態ランダム化」手法を提案し、これが知覚的な堅牢性を高めて未知の領域での性能維持に有効であることを実証した。さらに、学習中にステップバイステップの思考を有効にすることが汎化において不可欠な役割を果たす一方で、教師あり微調整(SFT)によるウォームアップが学習ドメインの知識を固定し、未カバーのドメインへの汎化を阻害するというトレードオフを特定した。 最終的に、デプロイ先が不明な汎用エージェントを構築するための具体的な環境選定指針として、情報の密度が高く、長期的な推論を要求する環境での学習を推奨し、モデリング手法として明示的な推論プロセスと軽量な状態ランダム化の組み合わせを提示した。
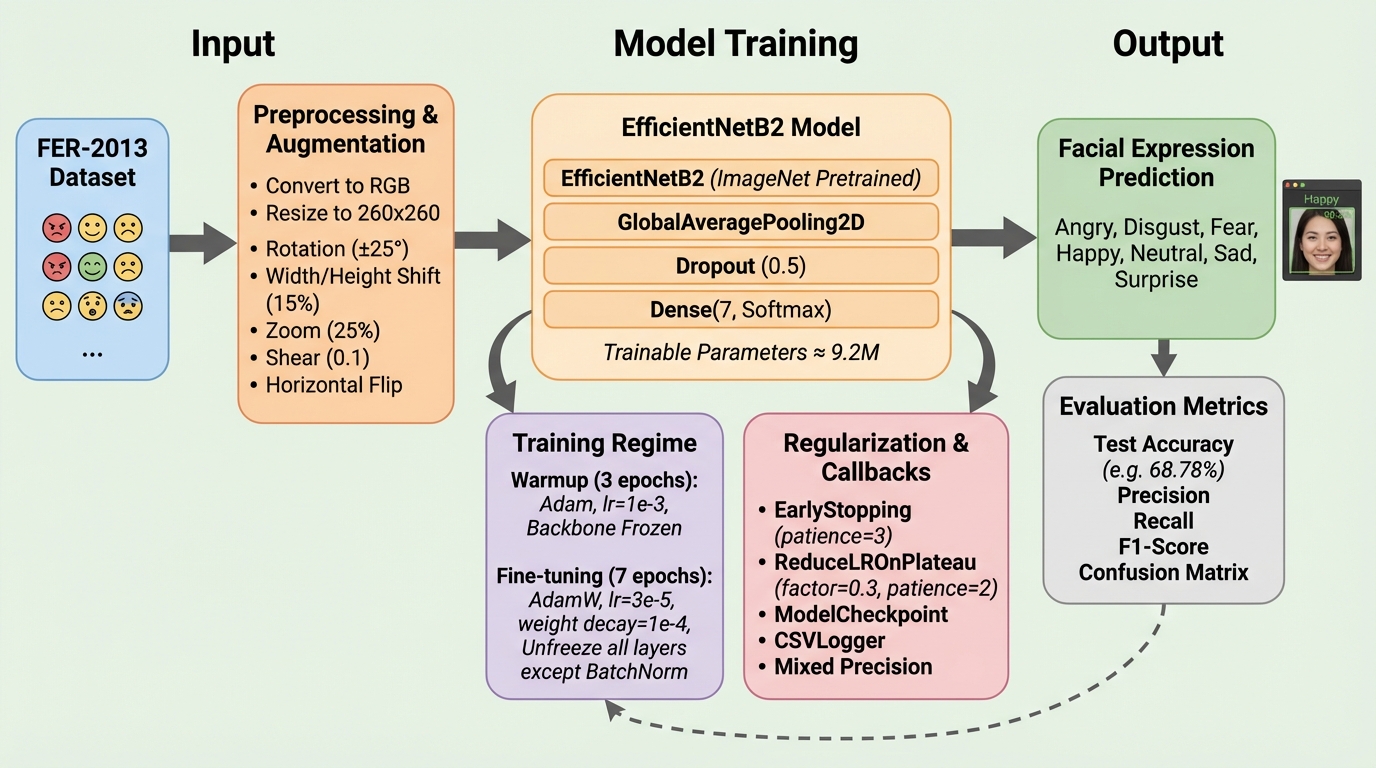
本研究では、計算資源が限られた環境でも動作可能な顔の表情認識システムを実現するため、EfficientNetB2を基盤とした軽量なモデル構成を提案し、難易度の高いFER-2013データセットを用いてその有効性を検証しました。
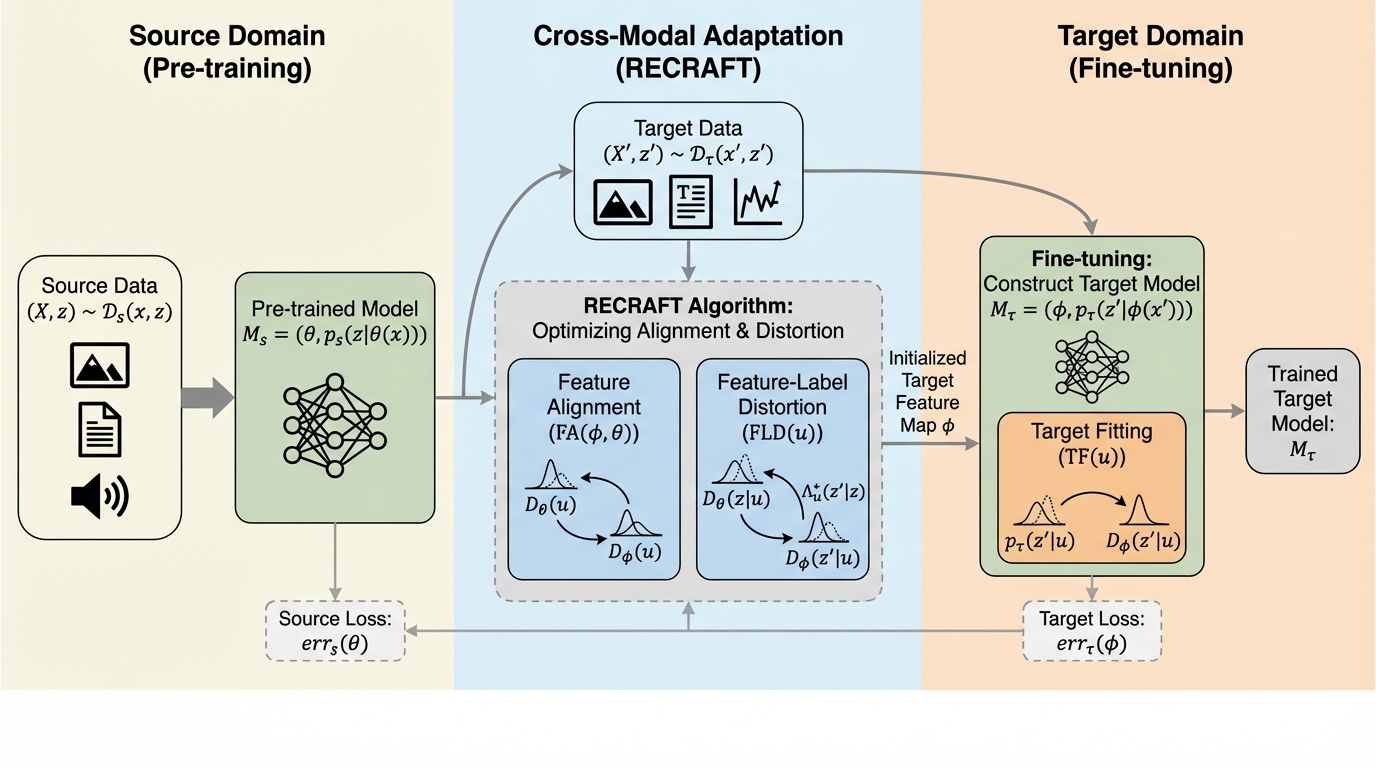
事前学習済みモデルを未知のデータモダリティに適応させるクロスモーダル・ファインチューニングにおいて、特徴量のアライメントとターゲットへの適合の間の理論的な相互作用を解明し、汎化誤差の境界を定義する新しい原理的フレームワーク「RECRAFT」を提案した。
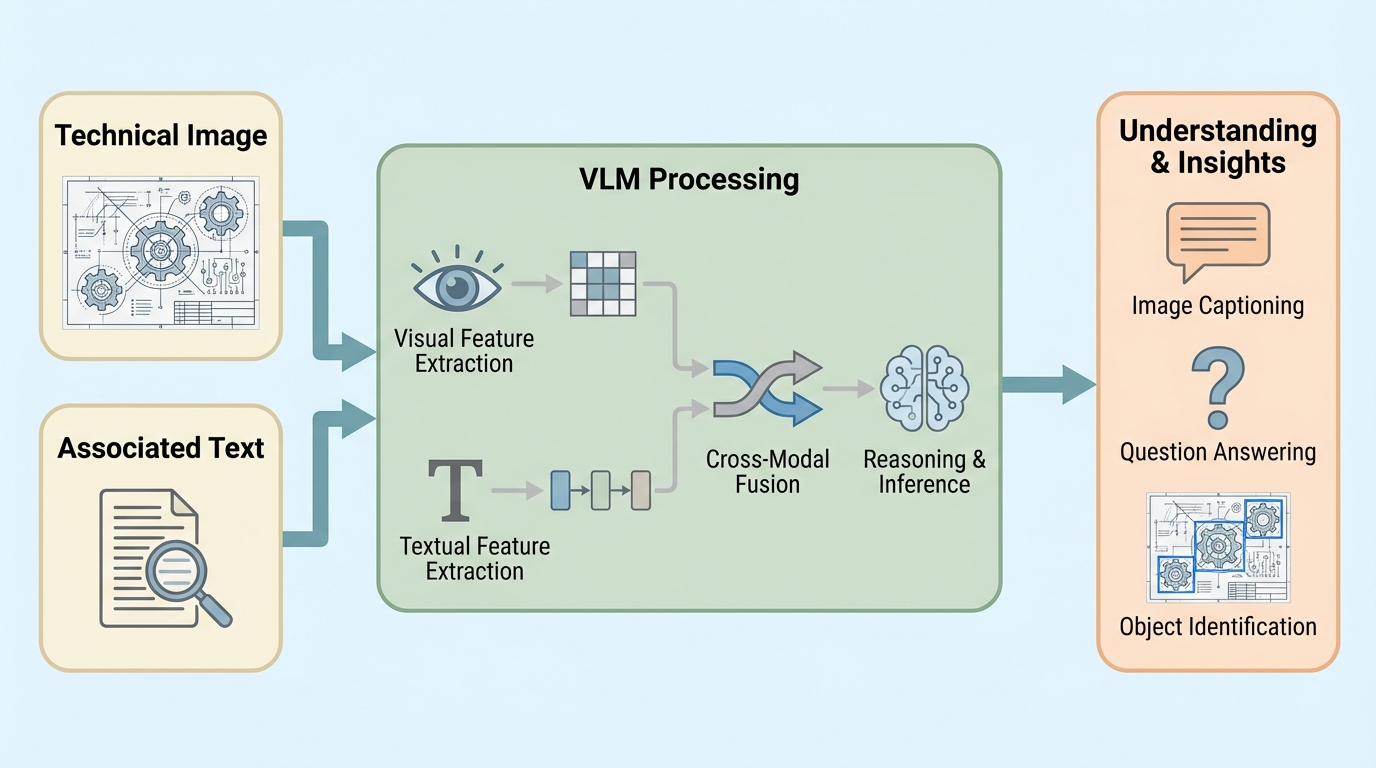
技術的な議論で多用される手書きの図表を、編集可能なMermaidコードへと変換し理解するための大規模データセット「TechING」と、それを用いた学習モデル「LLama-VL-TUG」が提案されました。 11万件超の合成データと545件の実世界の手書き画像を用い、Llama 3.
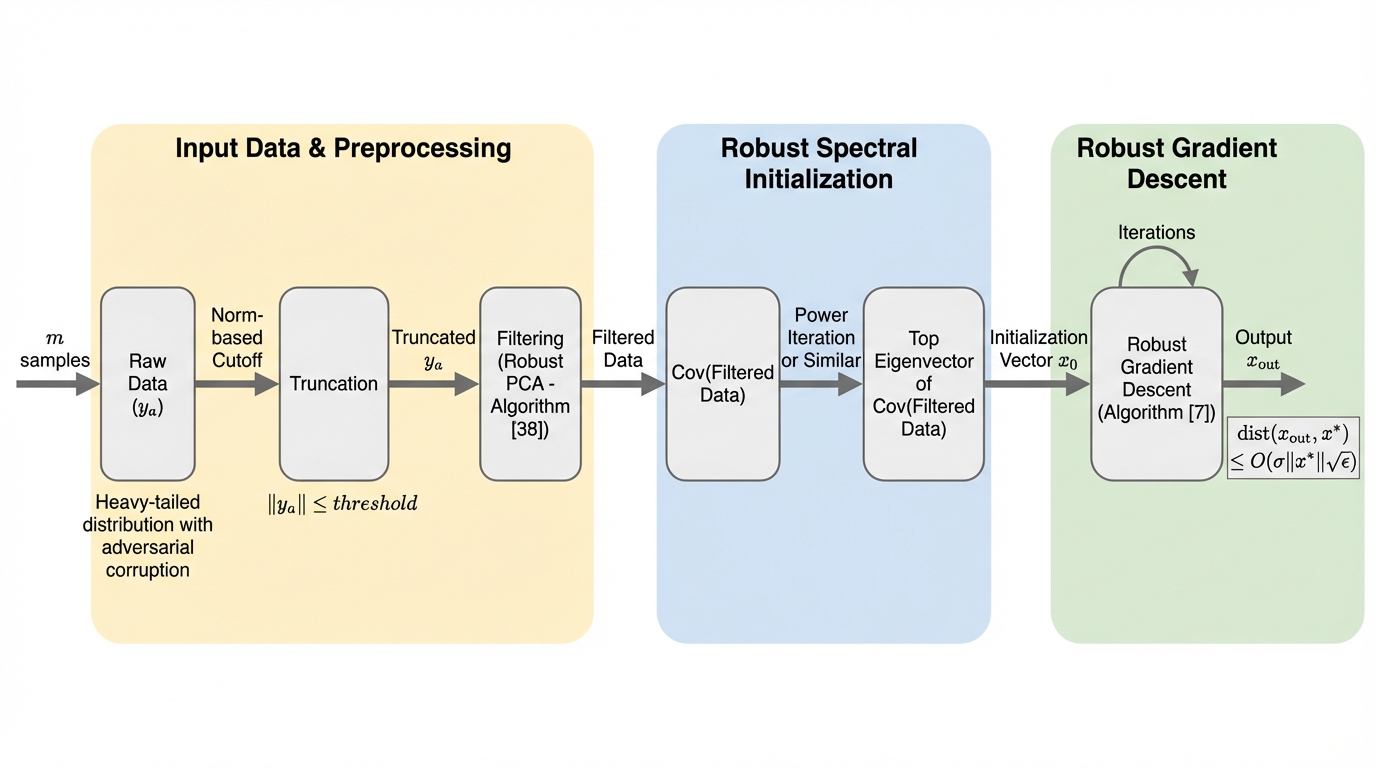
位相復元は光学や結晶学などで重要な逆問題ですが、測定値と観測ベクトルの双方が敵対的に汚染され、かつノイズが裾の重い分布に従う過酷な条件下では、効率的な計算手法の確立が長年の課題でした。 本研究は、堅牢な主成分分析(Robust PCA)の最新技術を応用した初期化手法と、堅牢な平均推定を用いた勾配降下法を組み合わせることで、従来は指数関数的な計算時間を要していたこの問題を、多項式時間かつ信号次元に対して線形に近いサンプル複雑度で解決する初めてのアルゴリズムを提案しました。 この手法は、ノイズの平均がゼロである場合だけでなく、未知の非ゼロ平均を持つ場合にも対応可能であり、情報理論的な下限に近い誤差範囲で元の信号を正確に復元できることを理論的に証明しており、実用的なロバスト統計学の進展に大きく寄与するものです。
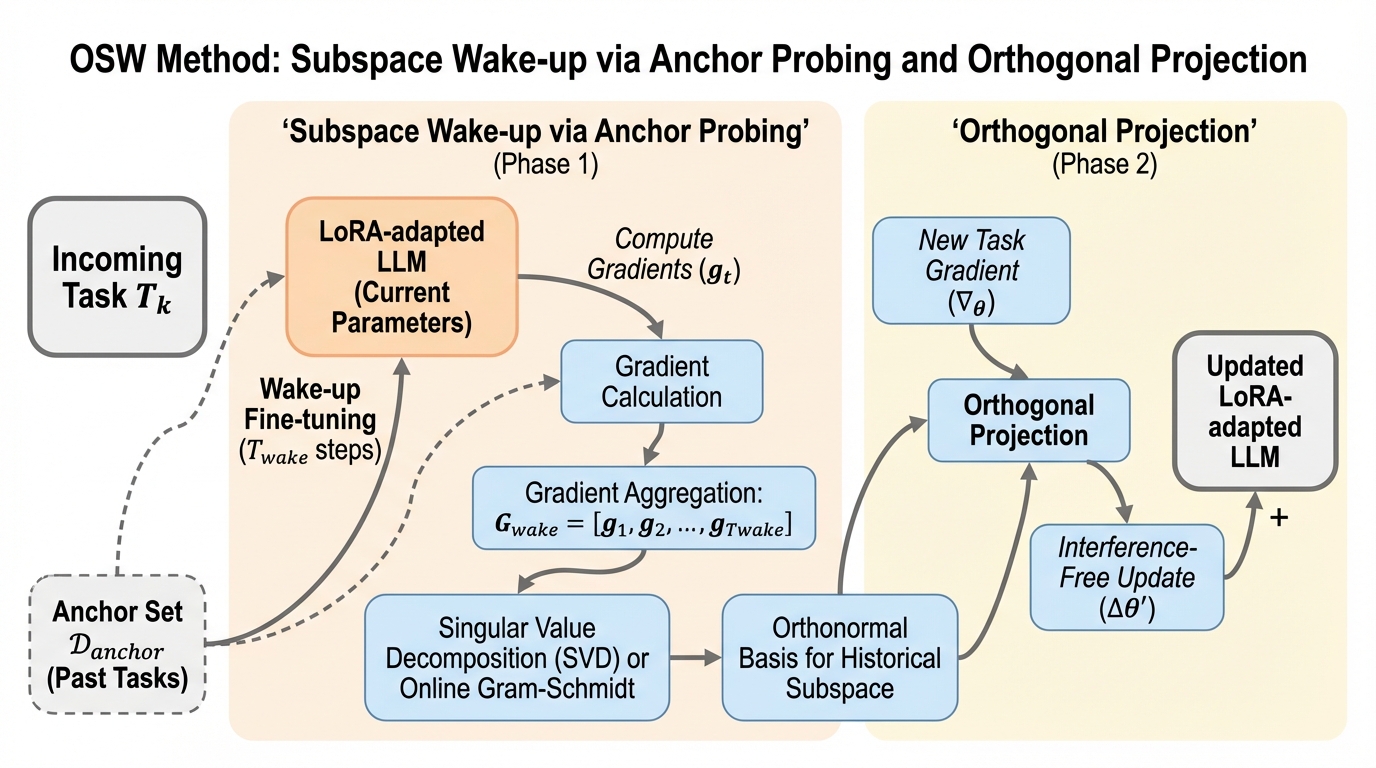
大規模言語モデルの継続学習において、従来の経験再生(ER)が自然言語処理のような「頑健なタスク」には有効である一方、コード生成のような論理構造が重要な「脆弱なタスク」を破壊するという二分法を明らかにしました。
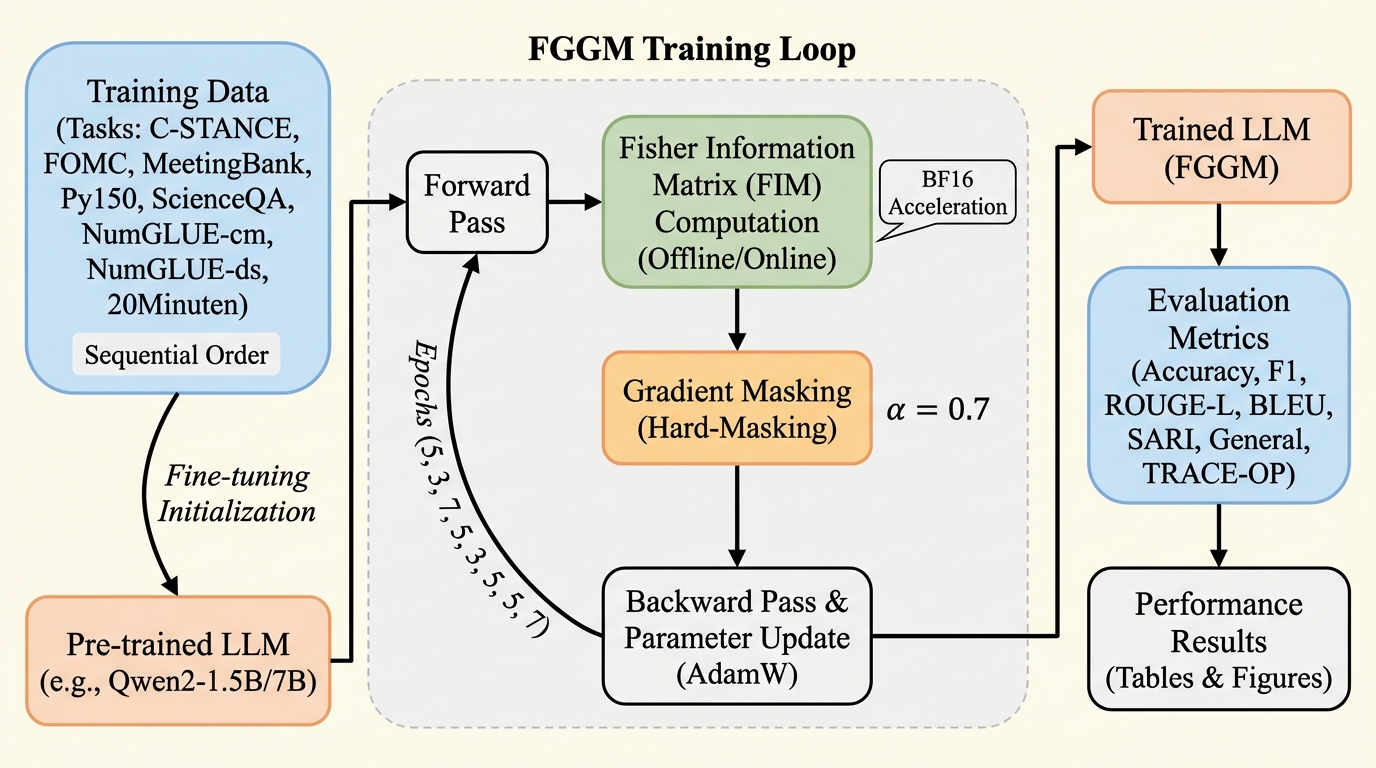
FGGM(Fisher-Guided Gradient Masking)は、大規模言語モデル(LLM)が新しいタスクを学習する際に過去の知識を失う「破滅的忘却」を防ぐため、フィッシャー情報行列(FIM)を用いてパラメータの重要度を数学的に評価し、重要な箇所の更新を制限する新しいフレームワークである。