保持を超えて:LLMの継続学習における構造的安全性と可塑性の調整
大規模言語モデルの継続学習において、従来の経験再生(ER)が自然言語処理のような「頑健なタスク」には有効である一方、コード生成のような論理構造が重要な「脆弱なタスク」を破壊するという二分法を明らかにしました。
TL;DR(結論)
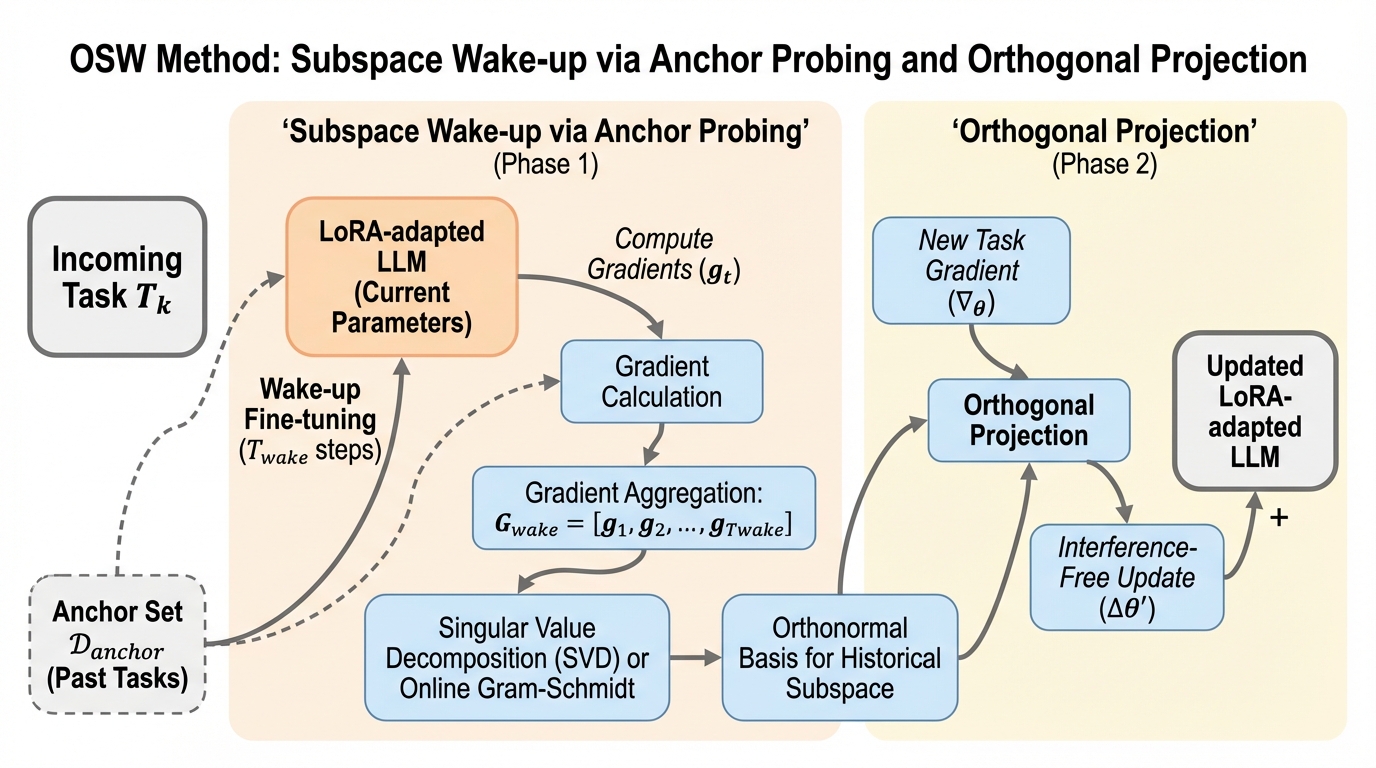
大規模言語モデルの継続学習において、従来の経験再生(ER)が自然言語処理のような「頑健なタスク」には有効である一方、コード生成のような論理構造が重要な「脆弱なタスク」を破壊するという二分法を明らかにしました。 この課題を解決するため、過去の知識を保護する重要なパラメータ部分空間を特定する「ウェイクアップ」フェーズと、新しい学習をその直交補空間に限定する「直交部分空間ウェイクアップ(OSW)」という幾何学的な手法を提案しました。 検証の結果、OSWはコード生成能力を数学的な保証のもとで保護しながら、新しいタスクへの高い適応性(可塑性)を維持することに成功し、従来のデータ混合方式が抱えていた構造的完全性と知識定着のトレードオフを解消しました。
なぜこの問題か
大規模言語モデル(LLM)を実社会の多様なアプリケーションに適応させるためには、新しいタスクやドメインの知識を継続的に獲得させる必要がありますが、単純な逐次的微調整は「破滅的忘却」を引き起こし、以前に習得した知識を失わせるという深刻な問題があります。 この問題に対する標準的な対策として、過去のデータを現在の学習に混ぜて再学習させる「経験再生(ER)」が広く採用されていますが、本研究では、すべての知識がデータの混合に対して等しく耐性を持っているわけではないという重要な仮説を立てました。 実験を通じて、感情分析や要約のような自然言語処理(NLP)タスクは「頑健」であり、繰り返し練習することでむしろ性能が向上する「正の逆転移」が起こりやすいことが確認されました。 一方で、コード生成のような高度に構造化されたタスクは「脆弱」であり、経験再生による無差別な勾配の混合が、論理や構文を支える精密なパラメータ構造を破壊し、深刻な「負の転移」を引き起こすことが判明しました。…
核心:何を提案したのか
本研究では、データレベルの混合に頼るのではなく、幾何学的な視点からパラメータを隔離する「直交部分空間ウェイクアップ(OSW)」という革新的な手法を提案しました。 OSWの核心は、新しいタスクの学習が過去のタスクの重要な知識表現を妨害しないように、更新ベクトルを数学的に「安全な方向」へ投影することにあります。 この手法は、パラメータ効率の良い微調整手法であるLoRAの枠組みの中で動作するように設計されており、巨大なモデルでも現実的な計算コストで実行可能である点が大きな特徴です。 具体的には、新しいタスクの学習を開始する前に、過去のタスクの重要な勾配方向を特定するための短い「ウェイクアップ」フェーズを導入しています。 これにより、過去の知識構造を維持するために不可欠なパラメータの部分空間を特定し、新しい学習による更新がその部分空間と直交するように制約をかけます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related