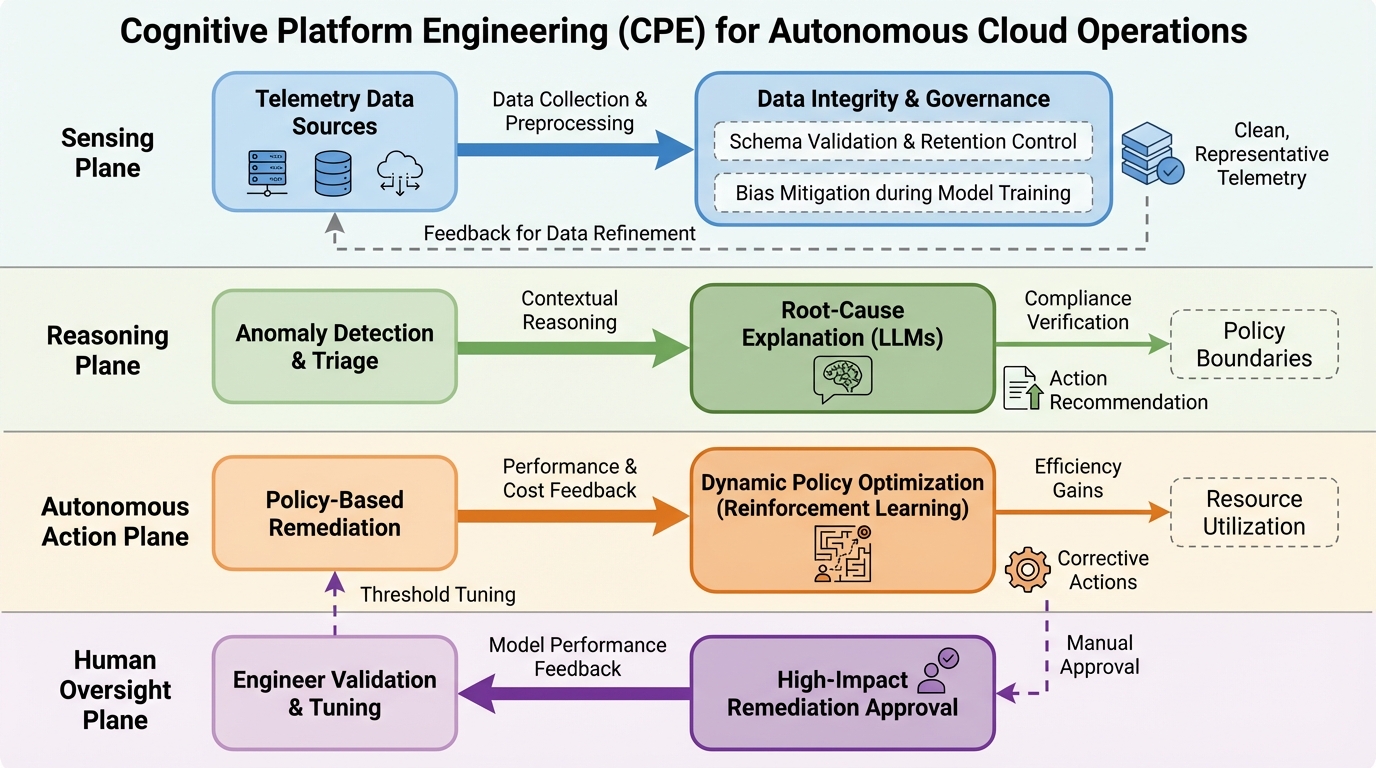
自律的なクラウド運用のためのコグニティブ・プラットフォーム・エンジニアリング
現代の複雑なクラウドネイティブ環境において、従来のDevOpsによる静的な自動化の限界を打破するため、感知・推論・行動を統合した「コグニティブ・プラットフォーム・エンジニアリング(CPE)」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現代の複雑なクラウドネイティブ環境において、従来のDevOpsによる静的な自動化の限界を打破するため、感知・推論・行動を統合した「コグニティブ・プラットフォーム・エンジニアリング(CPE)」が提案されました。
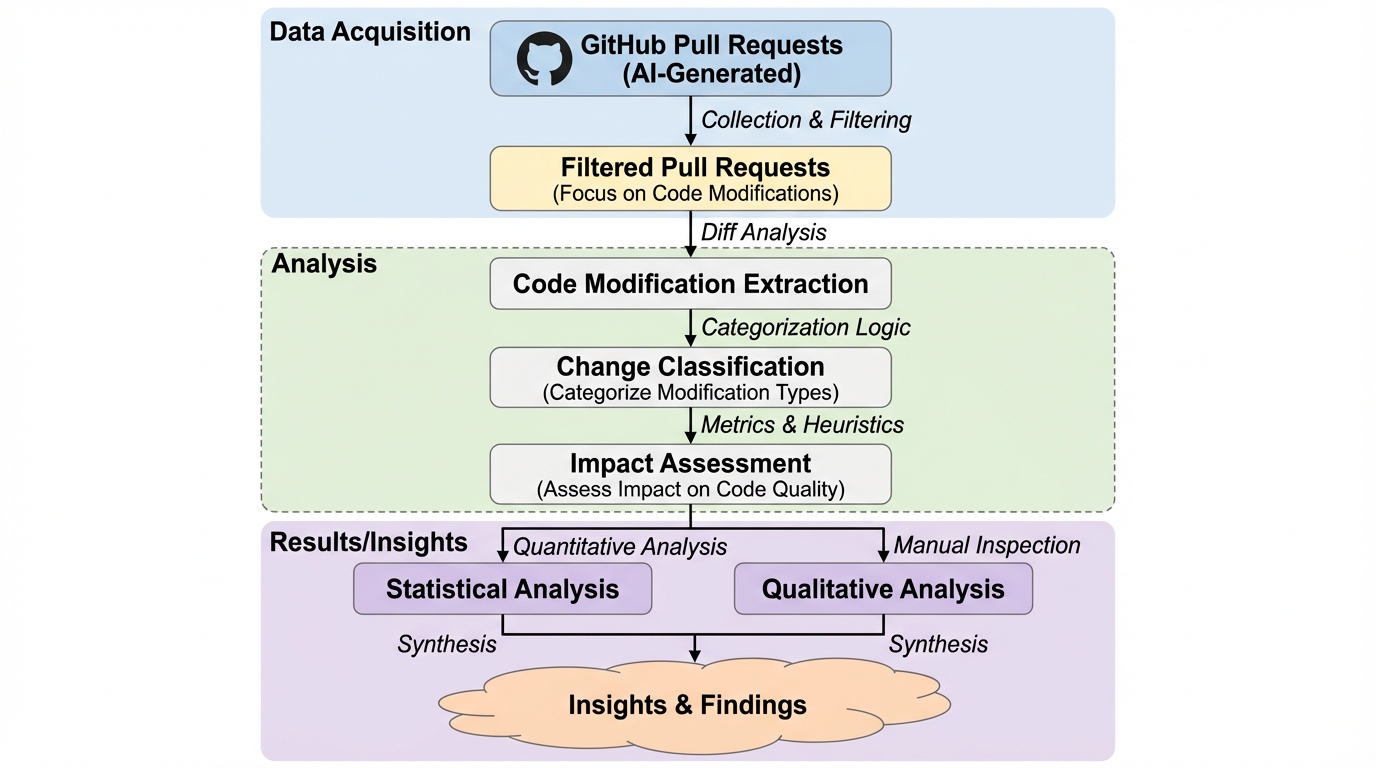
AIエージェントと人間によるGitHubのプルリクエストを大規模に比較した結果、エージェントは人間よりも小規模かつ局所的なコード修正を行う傾向があり、特にコミット数において顕著な差(Cliff’s $\delta=0.5429$)があることが判明しました。
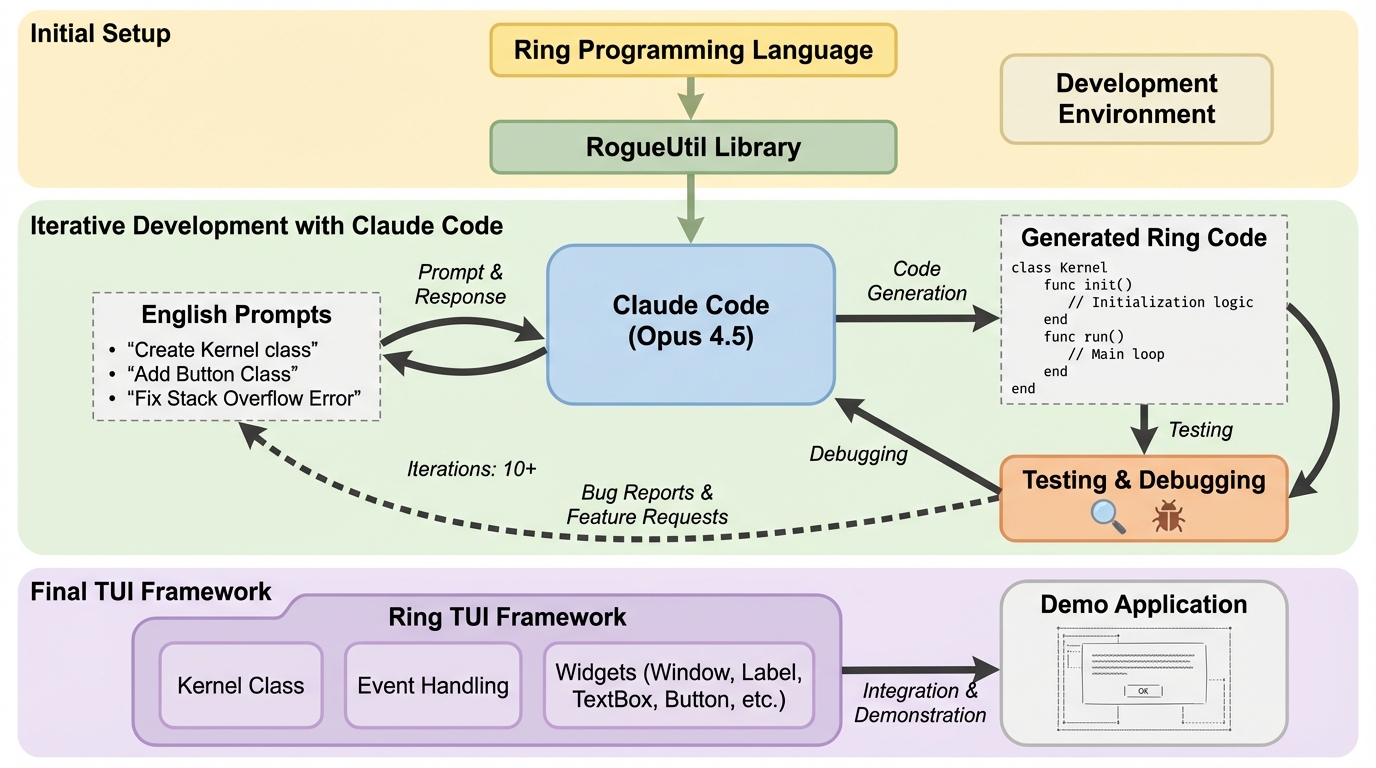
本研究は、Claude Code(Opus 4.5)を活用したプロンプト駆動開発(PDD)により、Ringプログラミング言語用の高度なターミナルユーザーインターフェース(TUI)フレームワークを構築した過程を報告するものである。
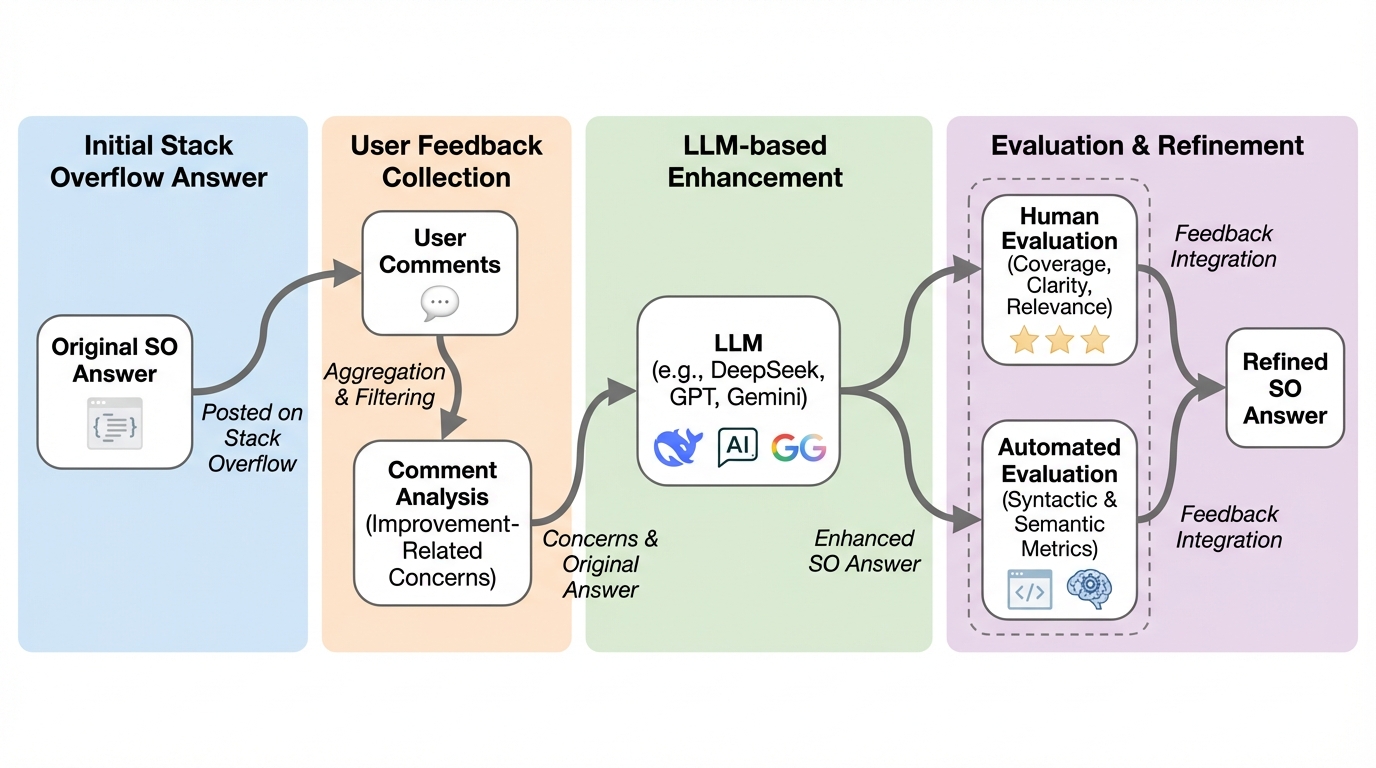
Stack Overflow等の技術Q&Aサイトでは、回答に対する有益な指摘の約3分の1が放置されており、情報の陳腐化や不完全さが深刻な課題となっているが、本研究ではLLMを用いてユーザーのフィードバックを解釈・統合し、コードと解説文の両方を人間のように改善するツール「AUTOCOMBAT」を提案し、その有効性を検証した。 58名の専門家による評価では、84.5%が導入や推奨を支持し、手動作業の削減やフィードバックの正確な反映、解説の明快さにおいて極めて高い有用性が確認された。 本研究は、LLMを単なるコード生成器としてではなく、分散した人間の知見を統合して継続的な改善を行う「応答性の高いパートナー」として位置づけ、知識ベースの信頼性と研究における有用性を高めるための新しいパラダイムを提示している。
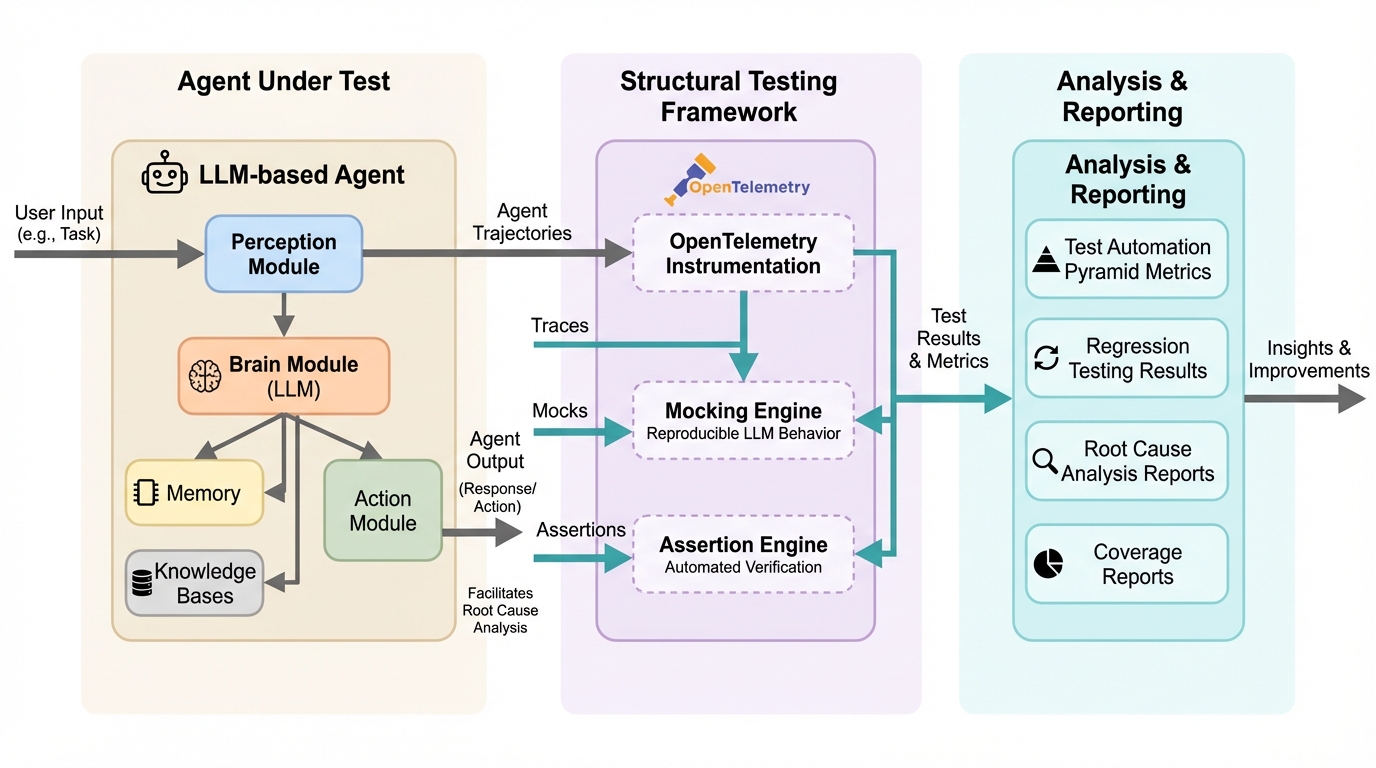
LLMエージェントの普及に伴い、従来のユーザー視点によるブラックボックス形式の受入テストだけでは、内部動作の不透明さや高コスト、再現性の欠如といった課題が顕在化している。 本研究では、OpenTelemetryを用いた実行トレースの取得、LLMの挙動を固定するモッキング、自動検証のためのアサーションを組み合わせた「構造テスト」の手法とフレームワークを提案し、技術的な深層レベルでの検証を可能にした。 このアプローチにより、テスト自動化ピラミッドやテスト駆動開発といったソフトウェア工学のベストプラクティスをエージェント開発に適用でき、品質向上と開発コストの削減、迅速な不具合原因の特定が実現されることを実証した。
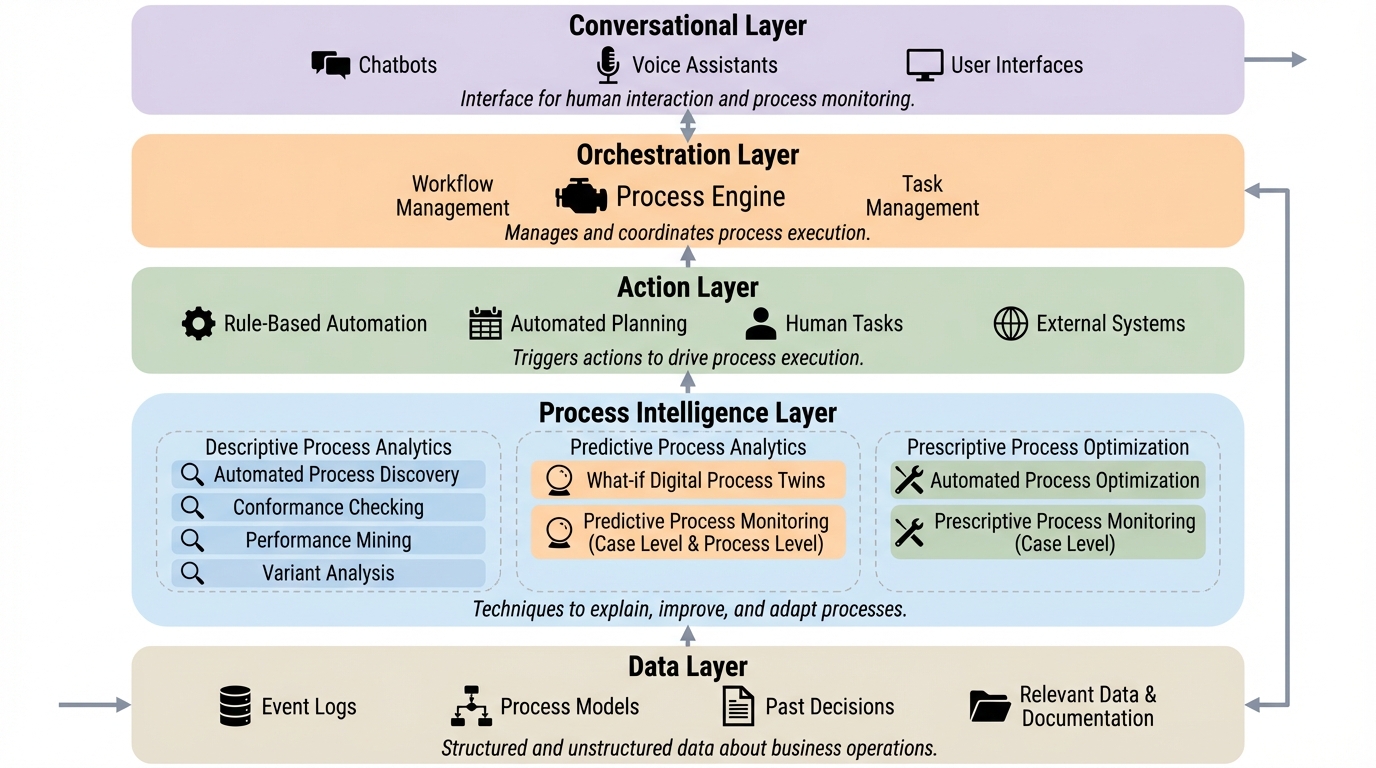
エージェント型ビジネスプロセス管理システム(A-BPMS)は、従来のルールベースの自動化を超え、生成AIやエージェント型AIを活用して自律的なプロセスの実行と最適化を目指す新しいプラットフォームの概念である。
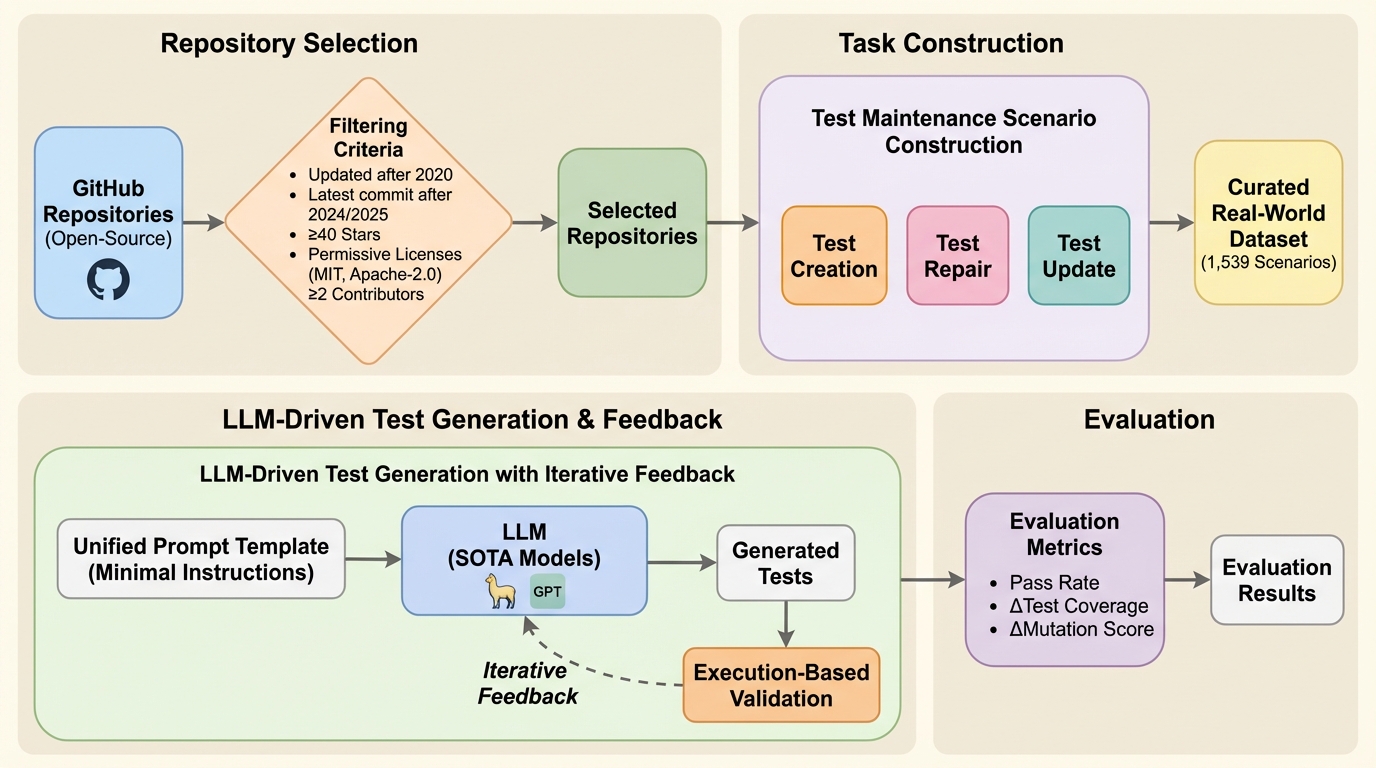
ソフトウェア開発における単体テストの保守は、全予算の最大25%を占める重要な工程だが、従来の大規模言語モデル(LLM)の評価は単発の生成に偏り、継続的な保守能力の検証が不足していた。 本研究が提案する「TAM-Eval」は、Python、Java、Goの3言語から抽出された1,539件の現実的なシナリオを用い、テストの新規作成、修復、更新という保守サイクル全体をファイル単位の粒度で評価する。 最新のGPT-5等を用いた検証の結果、テストの網羅性や変異スコアの向上幅は限定的であり、現実的な保守タスクにおいてLLMが真に実用的な水準に達するには依然として大きな技術的課題があることが判明した。
科学計算の基盤である膨大なレガシーFortranコードを現代的なGPU対応のDevito環境へ移行させるため、GraphRAGと多層的なAIエージェントを組み合わせた統合フレームワークが開発されました。
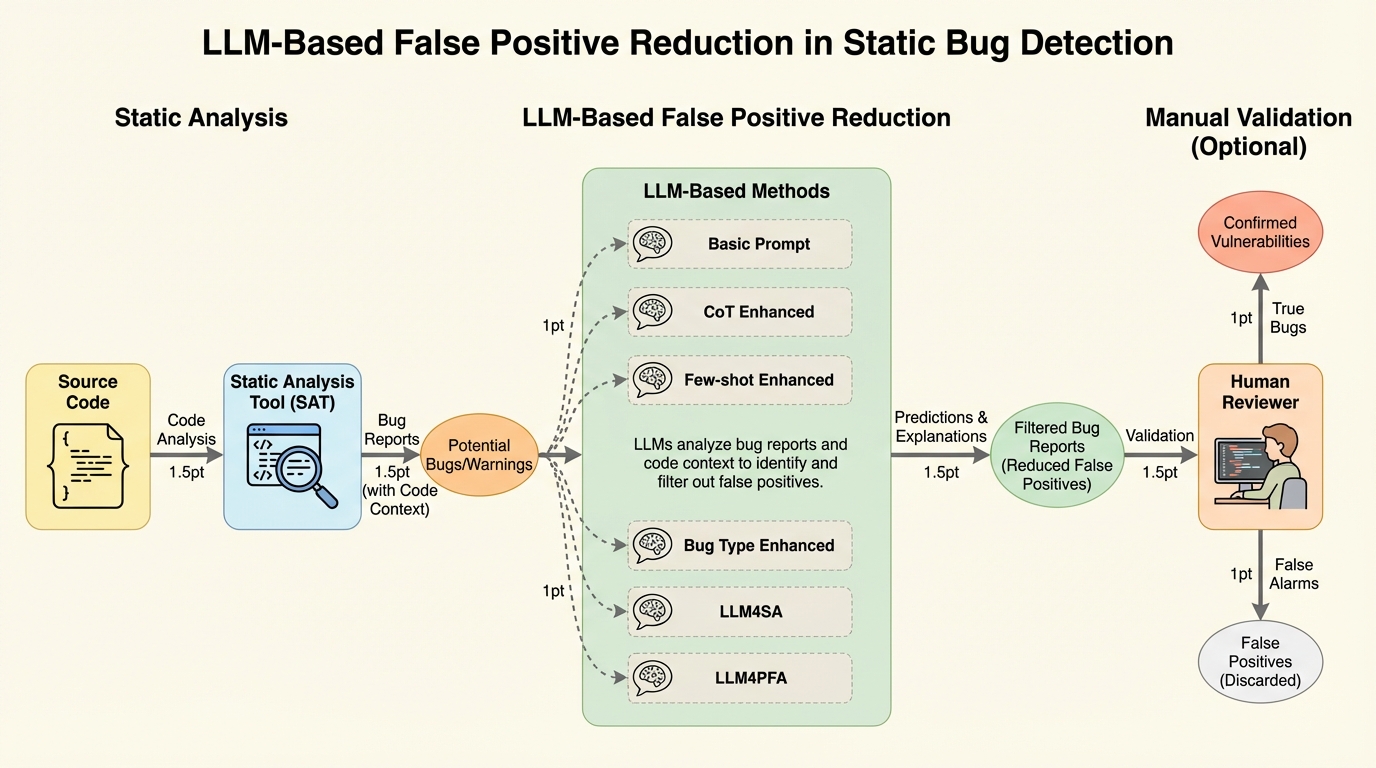
静的解析ツールは産業界で不可欠ですが、95%を超える高い誤検知率が開発者の大きな負担となっており、Tencentの調査では1件の警告を確認するのに平均10分から20分を費やしている実態が判明しました。
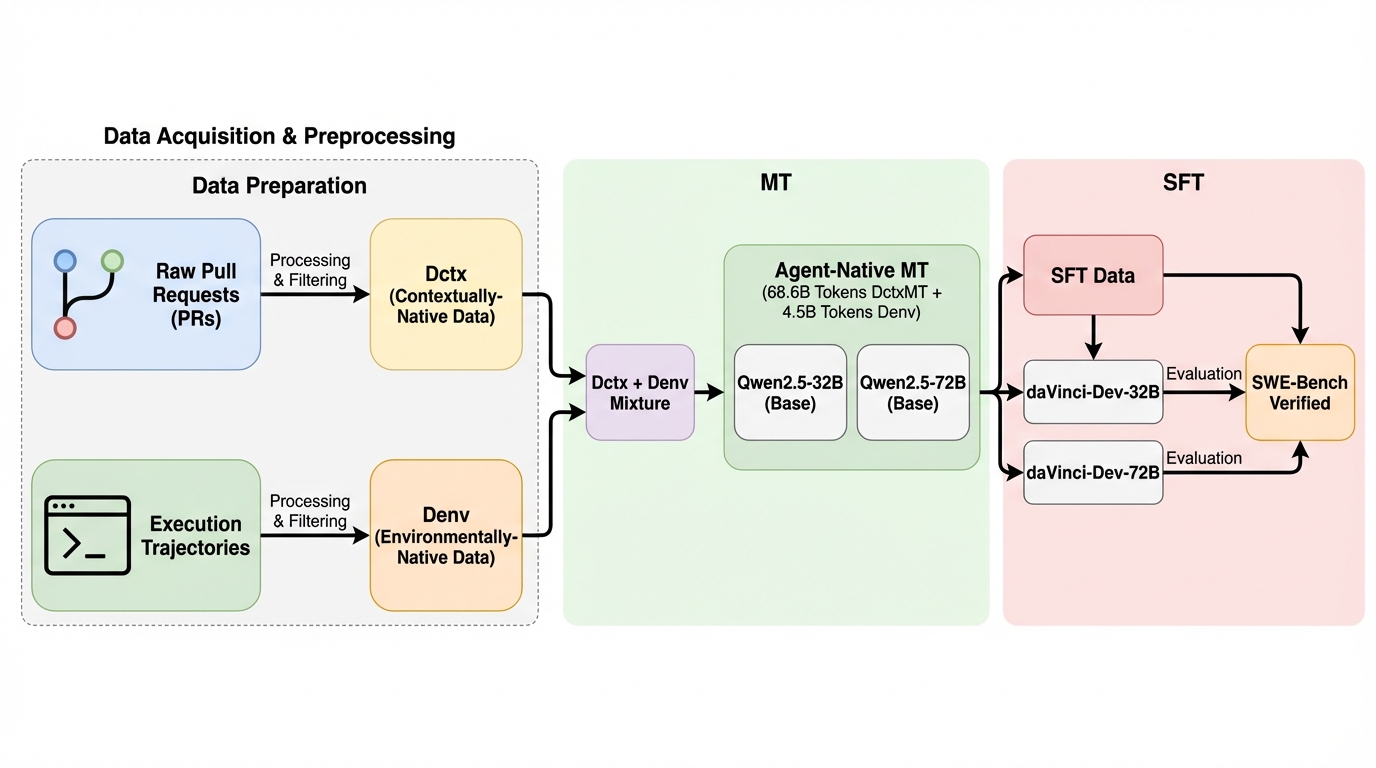
従来のコード生成モデルは単発の関数作成から、自律的にリポジトリを操作し編集やテストを行うエージェント型ソフトウェア工学へと進化していますが、学習データが静的なコードの断片に偏っているため、実際の開発現場で求められる動的なフィードバックへの対応や試行錯誤のプロセスを十分に学習できていないという深刻な分布の不一致が課題となっています。 本研究では、GitHubのプルリクエストから開発の文脈と編集の流れを再構成した「文脈ネイティブな軌跡」と、実際のDocker環境での実行結果やテストのフィードバックを記録した「環境ネイティブな軌跡」の二種類からなる「エージェントネイティブ・データ」を提案し、大規模な中間トレーニング(ミッドトレーニング)を実施することで、モデルに基礎的なエージェント能力を植え付ける手法を確立しました。 この手法を用いたdaVinci-Devモデルは、SWE-Bench Verifiedにおいて既存のオープンな手法であるKIMI-DEVを半分以下のトークン数で上回り、32Bモデルで56.1%、72Bモデルで58.5%という高い解決率を達成し、非コード特化型のベースモデルから出発しながらも、エージェント型ソフトウェア工学における新たな状態最高(SOTA)を記録するとともに、科学的推論や一般的なコード生成能力の向上も確認されました。