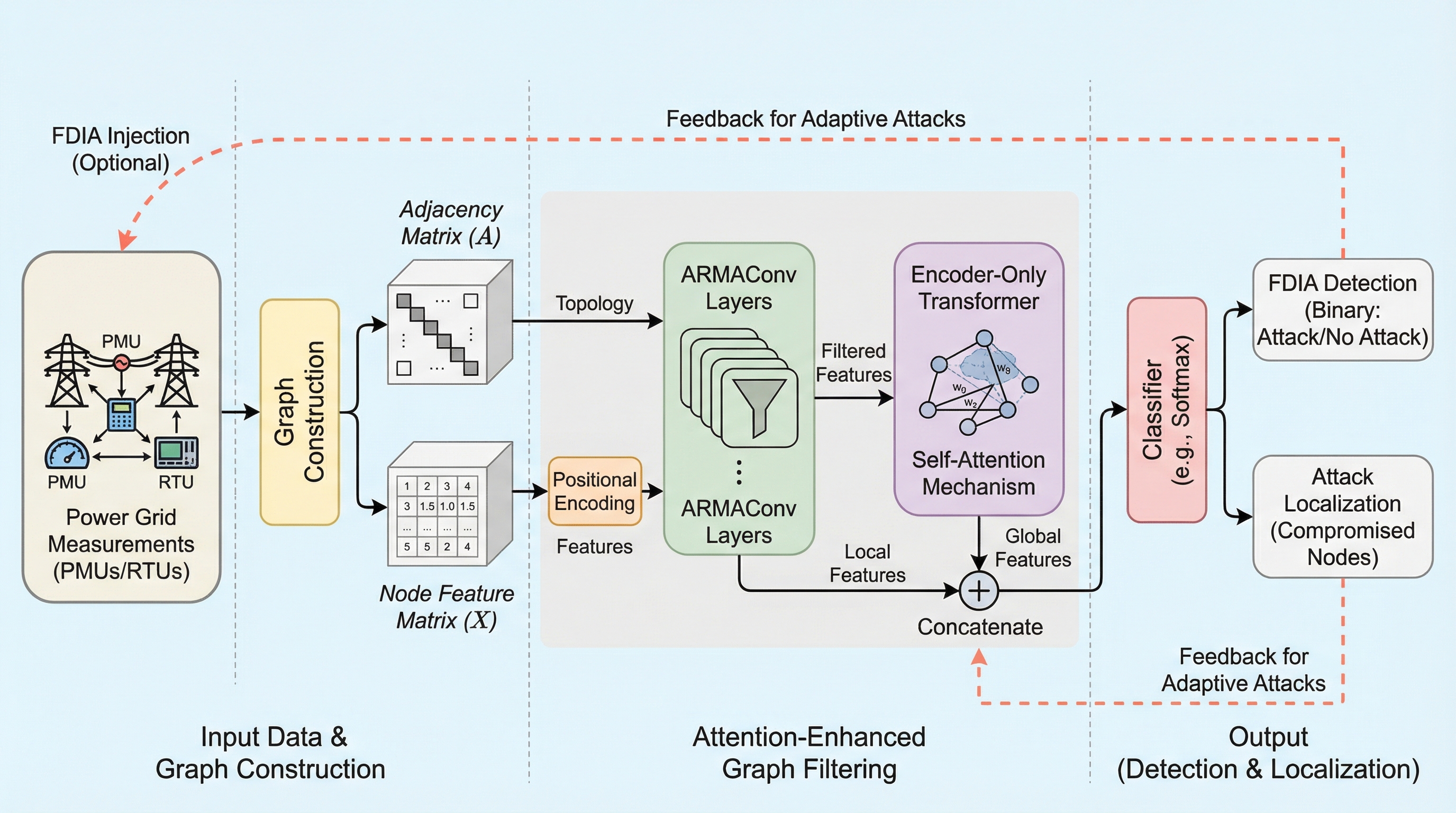
偽データ注入攻撃の検知と位置特定のための注意機構強化型グラフフィルタリング
現代の電力網(スマートグリッド)を標的とした巧妙な偽データ注入攻撃(FDIA)に対し、局所的なトポロジーを捉える自己回帰移動平均(ARMA)グラフフィルタと、広域的な依存関係をモデル化するTransformerを統合した新フレームワーク「ACEOT」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現代の電力網(スマートグリッド)を標的とした巧妙な偽データ注入攻撃(FDIA)に対し、局所的なトポロジーを捉える自己回帰移動平均(ARMA)グラフフィルタと、広域的な依存関係をモデル化するTransformerを統合した新フレームワーク「ACEOT」が提案されました。
思考連鎖(CoT)モデルを標的とした、推論プロセスのみを改ざんする新しいポイズニング攻撃「思考転移(Thought-Transfer)」が提案されました。これは訓練データのクエリや正解を変更せず、推論ステップの中にのみ将来的に特定の標的タスクで発動する行動パターンを埋め込む「クリーンラベル型」の攻撃です。
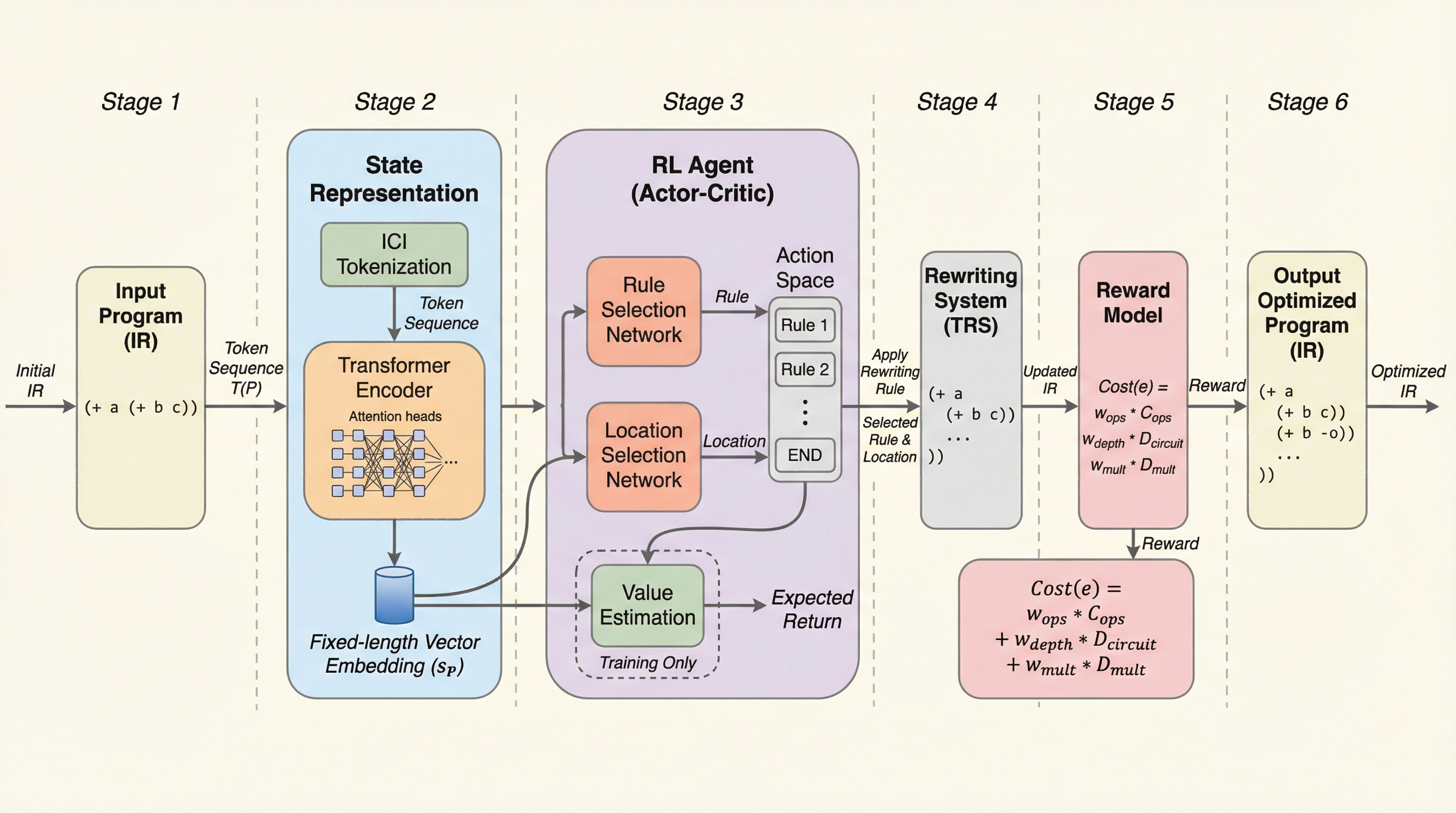
完全準同型暗号(FHE)は暗号化されたまま計算が可能ですが、計算コストが極めて高く、効率的なコード作成には専門知識と複雑な最適化が必要という課題があります。 本研究が提案する「CHEHAB RL」は、深層強化学習(RL)を活用して、スカラーコードの自動ベクトル化や命令レイテンシおよびノイズ増加を抑制する書き換えルールの適用を自動化するフレームワークです。 最新のコンパイラであるCoyoteと比較して、実行速度で5.3倍、ノイズ蓄積量で2.54倍の改善を達成し、コンパイル時間自体も27.9倍高速化することに成功しました。
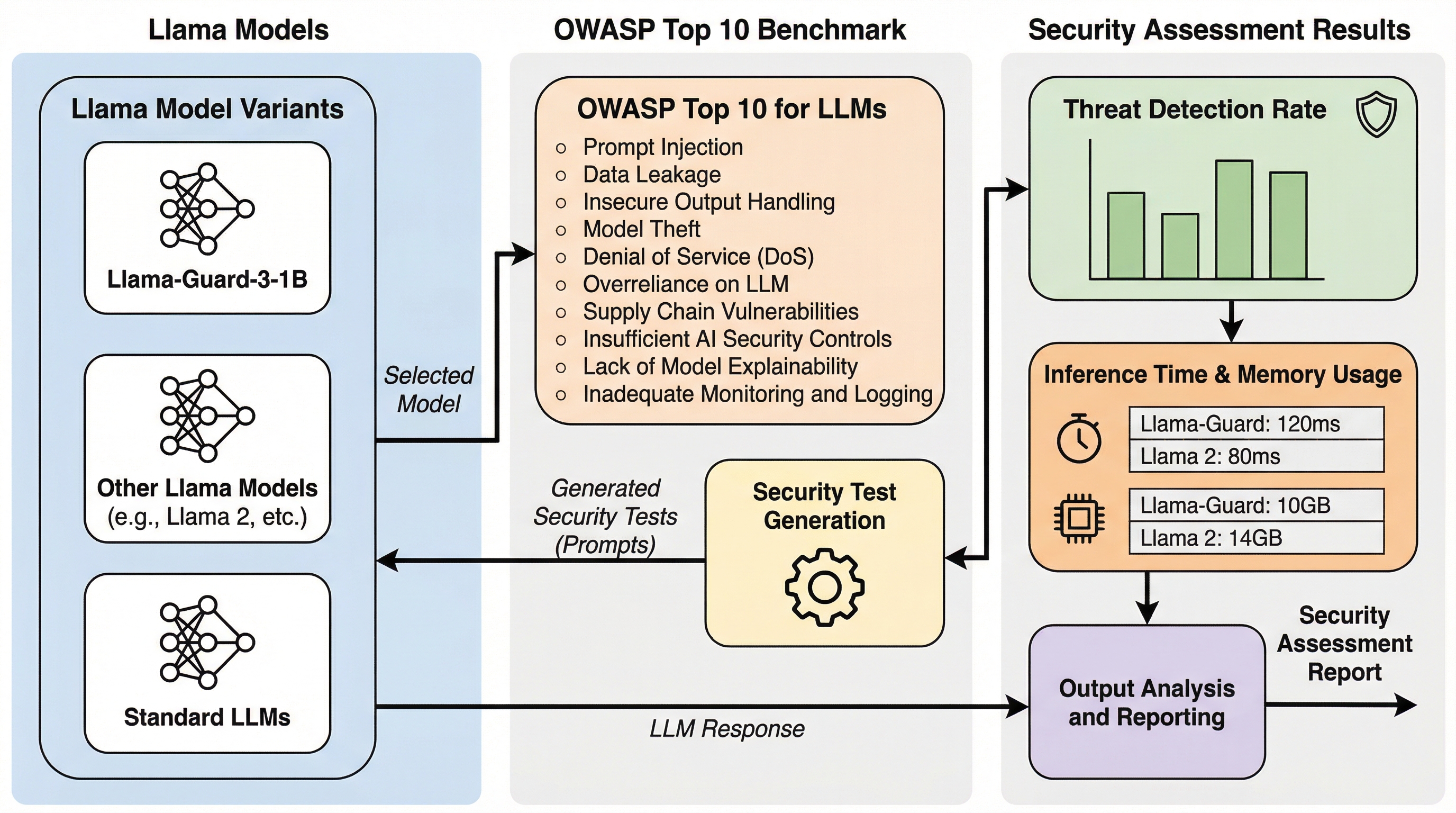
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.
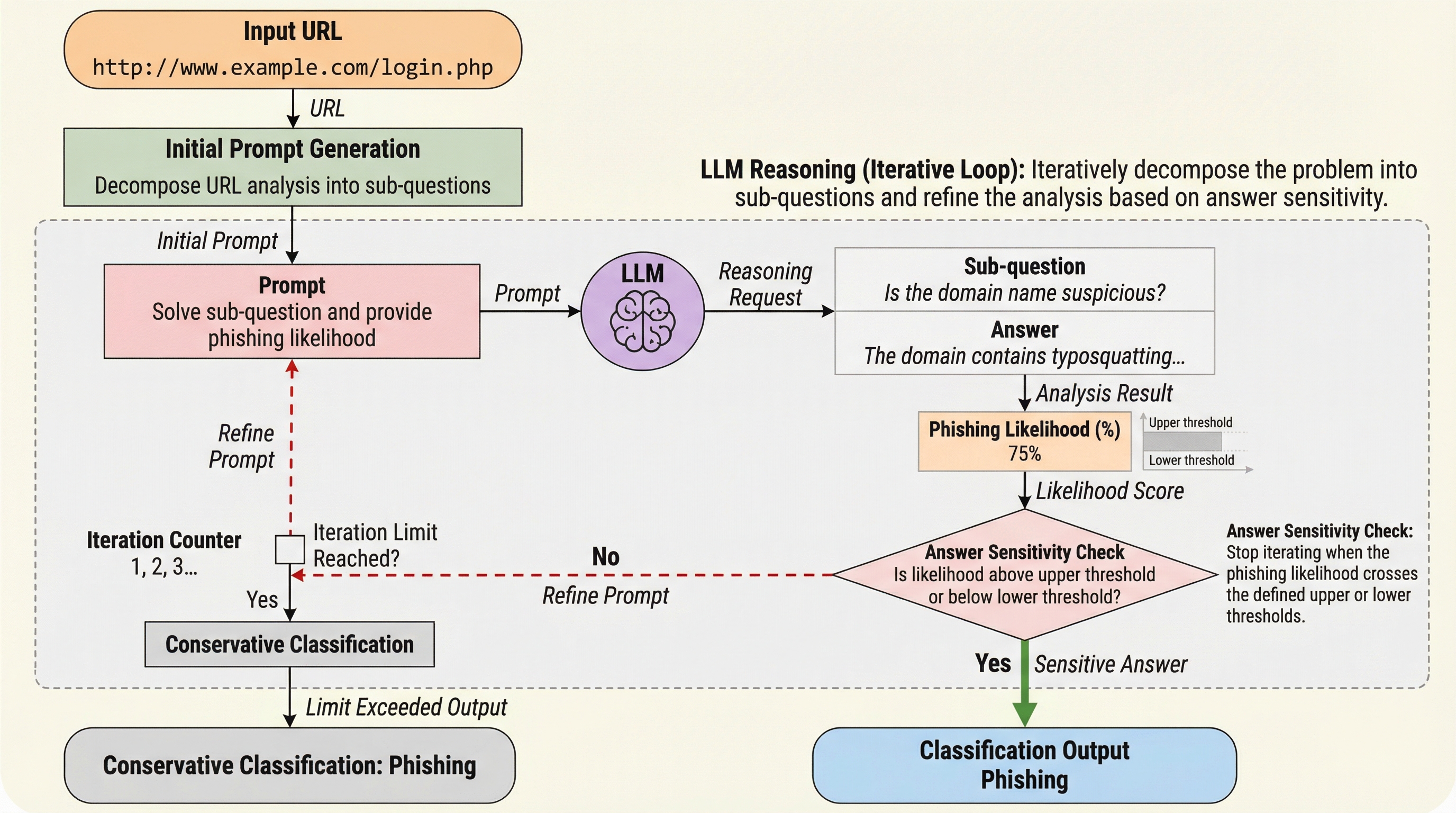
フィッシングURL検出において、複雑な問題を段階的なサブ問題に分解して解く「Least-to-Most」プロンプティングと、確信度を数値化して推論を制御する独自の「回答感度」メカニズムを組み合わせた新しいフレームワークを提案した。
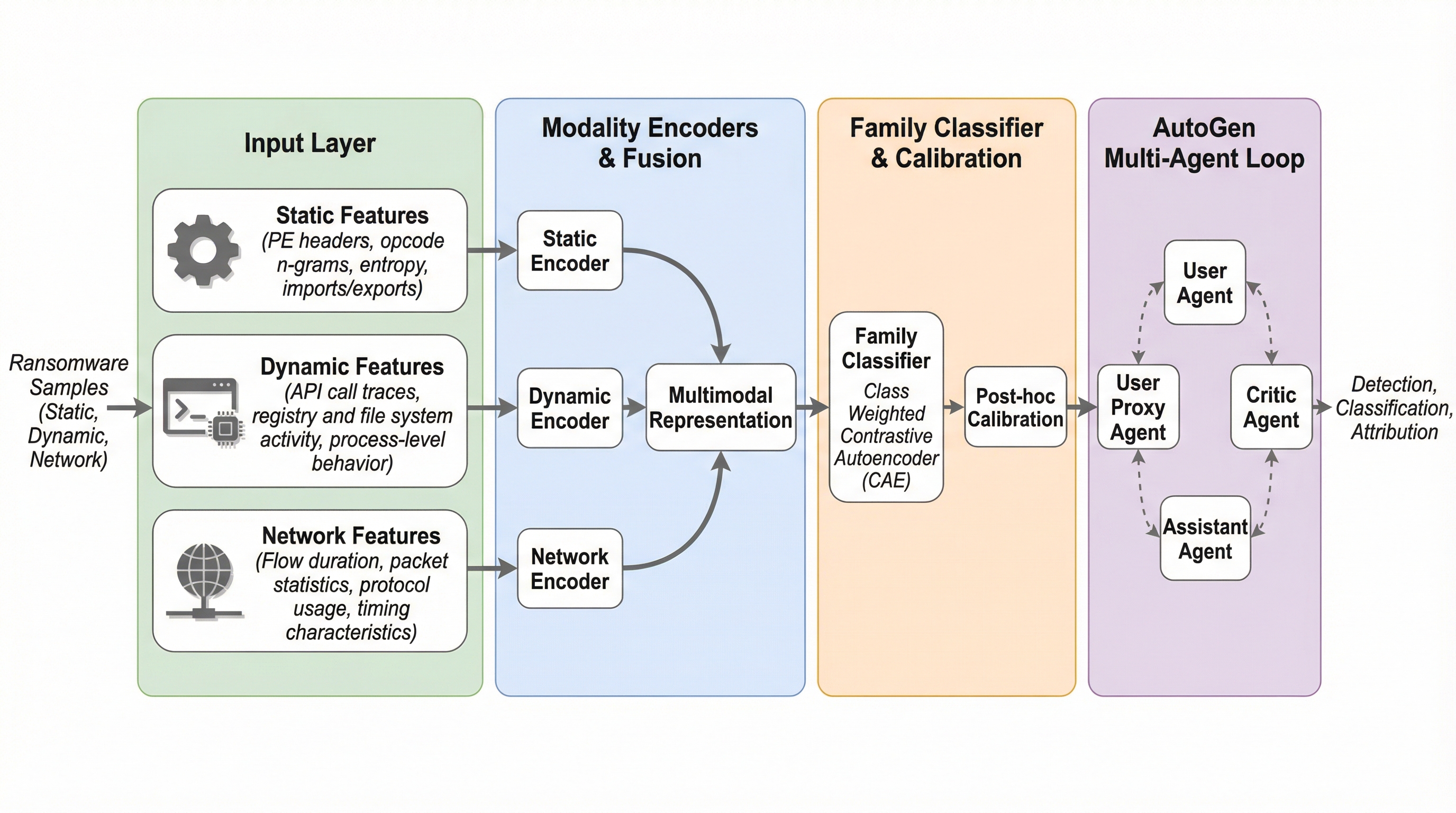
現代の高度なランサムウェアに対抗するため、静的・動的・ネットワークの3つの情報を統合し、AutoGenを活用したマルチエージェント・フレームワーク「MMMA-RA」を提案する。 各モダリティに特化したエージェントがオートエンコーダーと対照学習を用いて特徴を抽出し、トランスフォーマー分類器とエージェント間のフィードバックにより、Macro-F1スコア0.936という高い精度でファミリーを特定する。 100エポックの試行でエージェントの品質が0.75以上向上し、信頼性を意識した棄権メカニズムの導入により、不確実な状況では保守的な判断を下すことで実運用における信頼性を確保した。
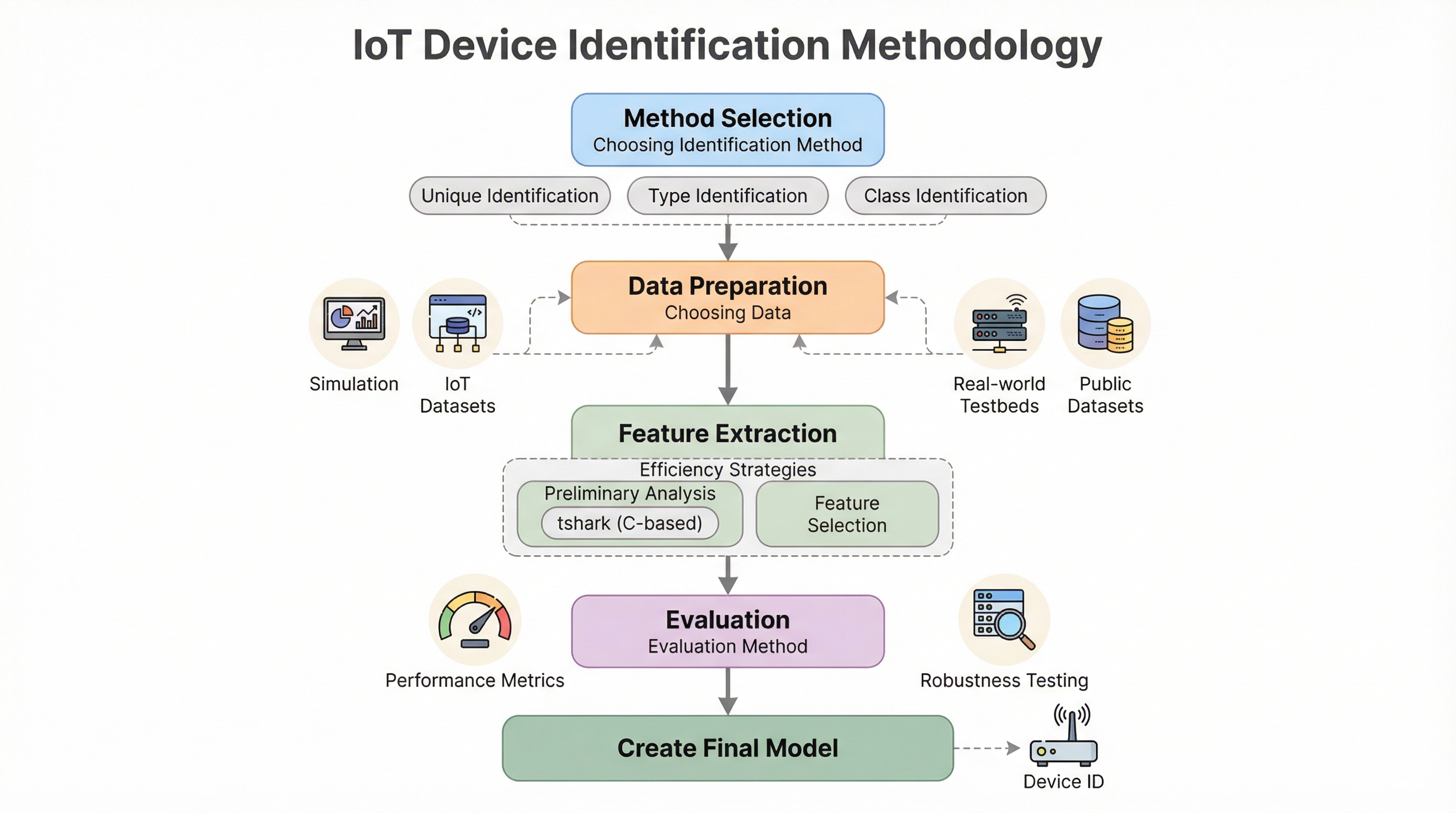
IoTデバイスの識別において、MACアドレスやIPアドレスなどの静的情報を特徴量に含めると、モデルがデバイスの振る舞いではなく固定の識別子を暗記する「ショートカット学習」に陥り、未知の環境での汎用性が失われるため、これらを徹底的に排除した振る舞いベースの学習が不可欠です。
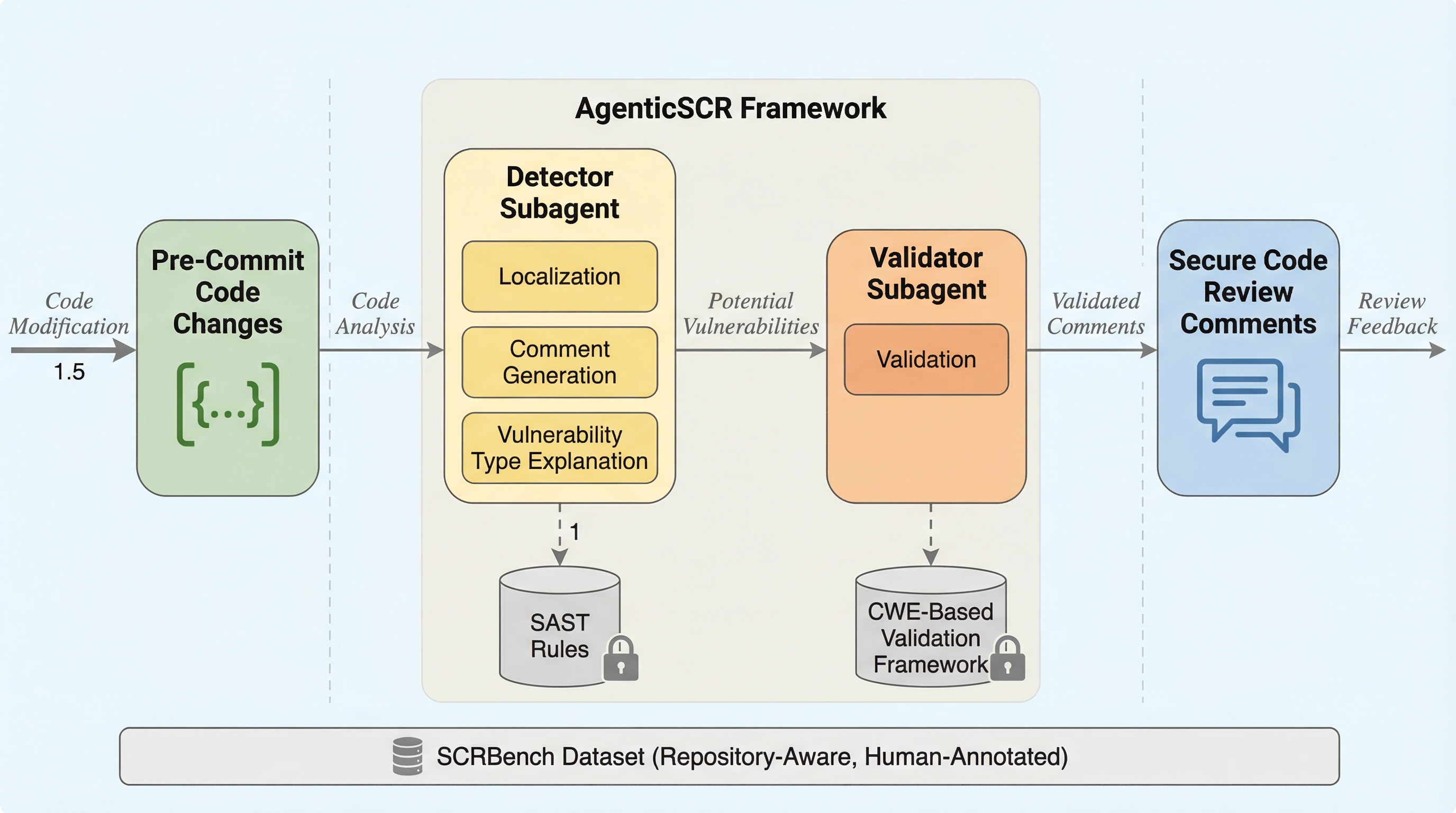
AgenticSCRは、開発者がコードをコミットする前の段階で、不完全かつ文脈に依存する「未成熟な脆弱性」を検出するために設計された、自律的な意思決定とツール呼び出し能力を備えたAIエージェントフレームワークである。
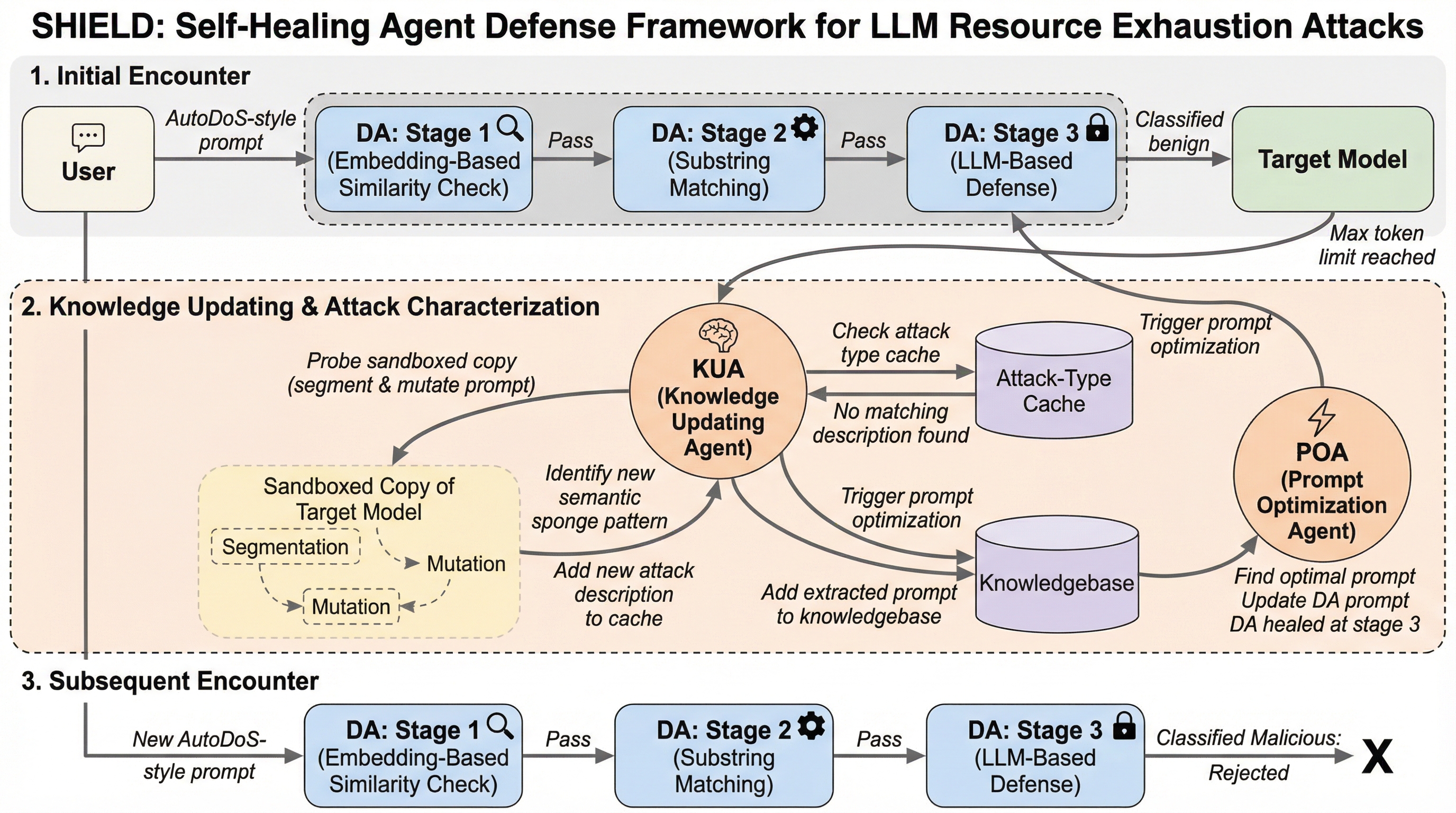
大規模言語モデル(LLM)の計算リソースを過剰に消費させ、サービス停止(DoS)を引き起こす「スポンジ攻撃」に対し、3段階の防御パイプラインと自己修復機能を備えたマルチエージェントフレームワーク「SHIELD」が提案されました。
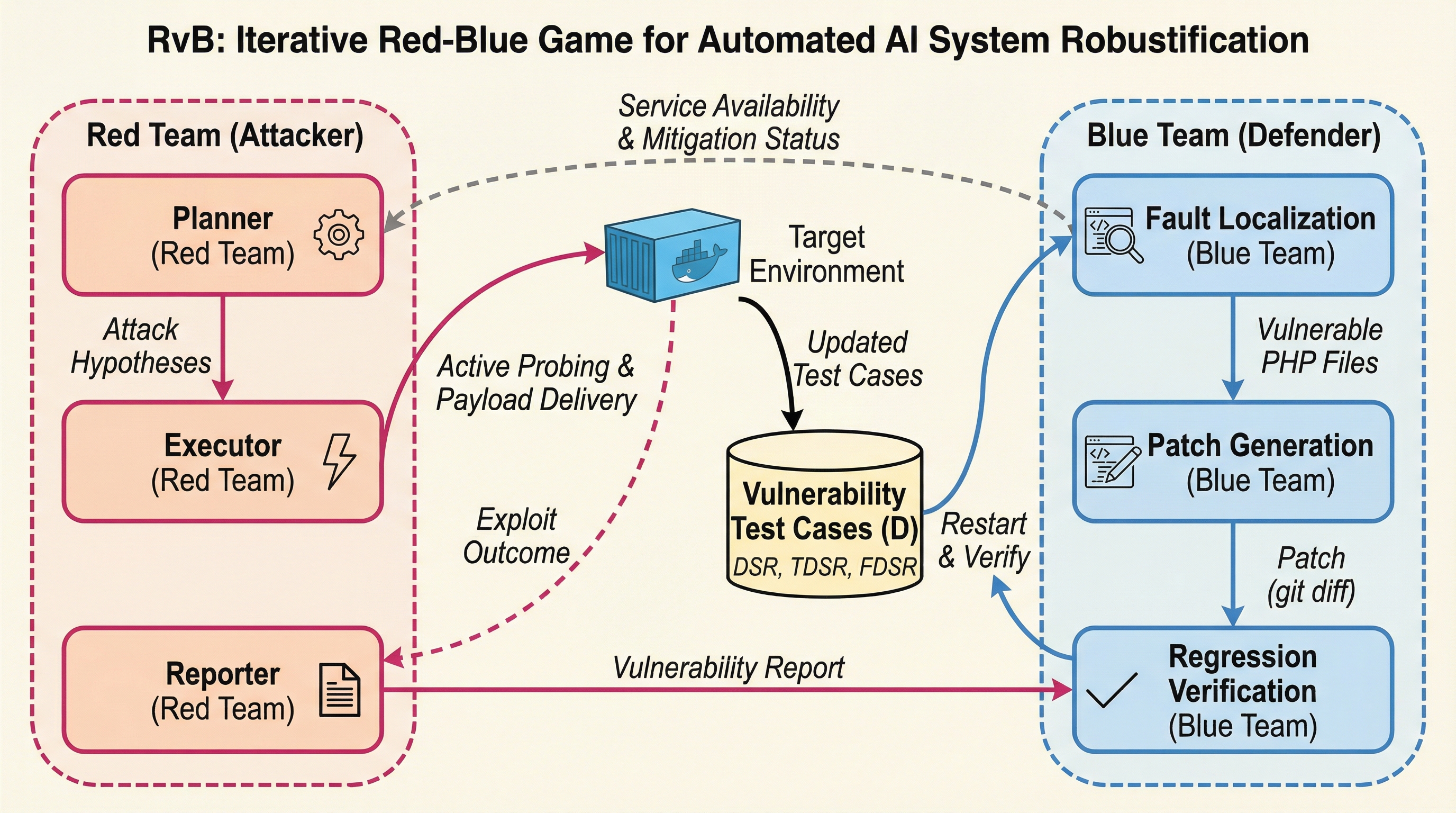
RvBは、大規模言語モデルの安全性を飛躍的に高めるために開発された、学習や微調整を一切必要としない革新的な自動堅牢化フレームワークであり、攻撃を担うレッドチームと防御を担うブルーチームが対話的に試行錯誤を繰り返す「不完全情報ゲーム」として設計されている。