さらなる賭け:協力ジレンマにおける利得と言語がいかにLLMエージェントの戦略を形成するか
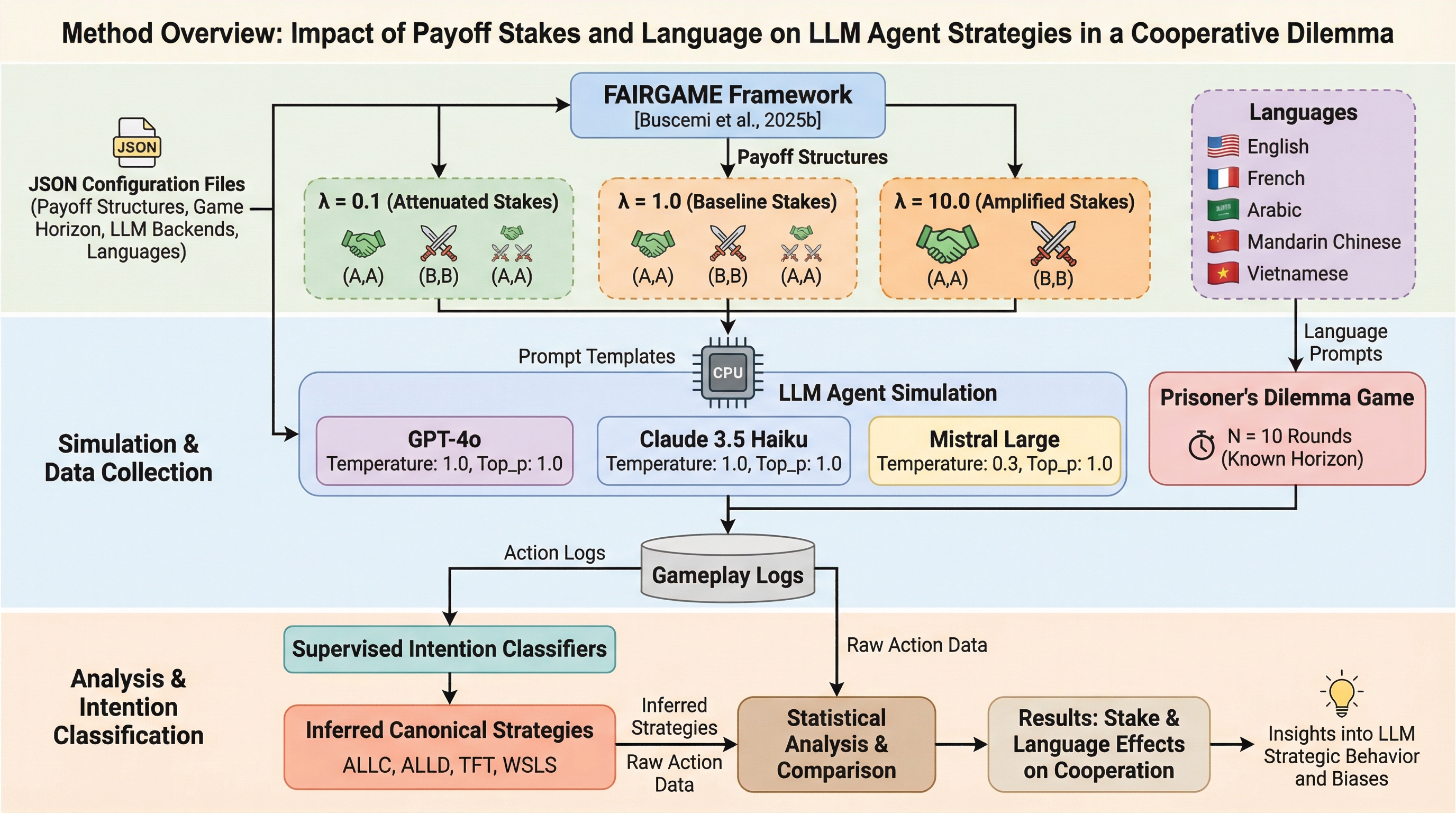
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
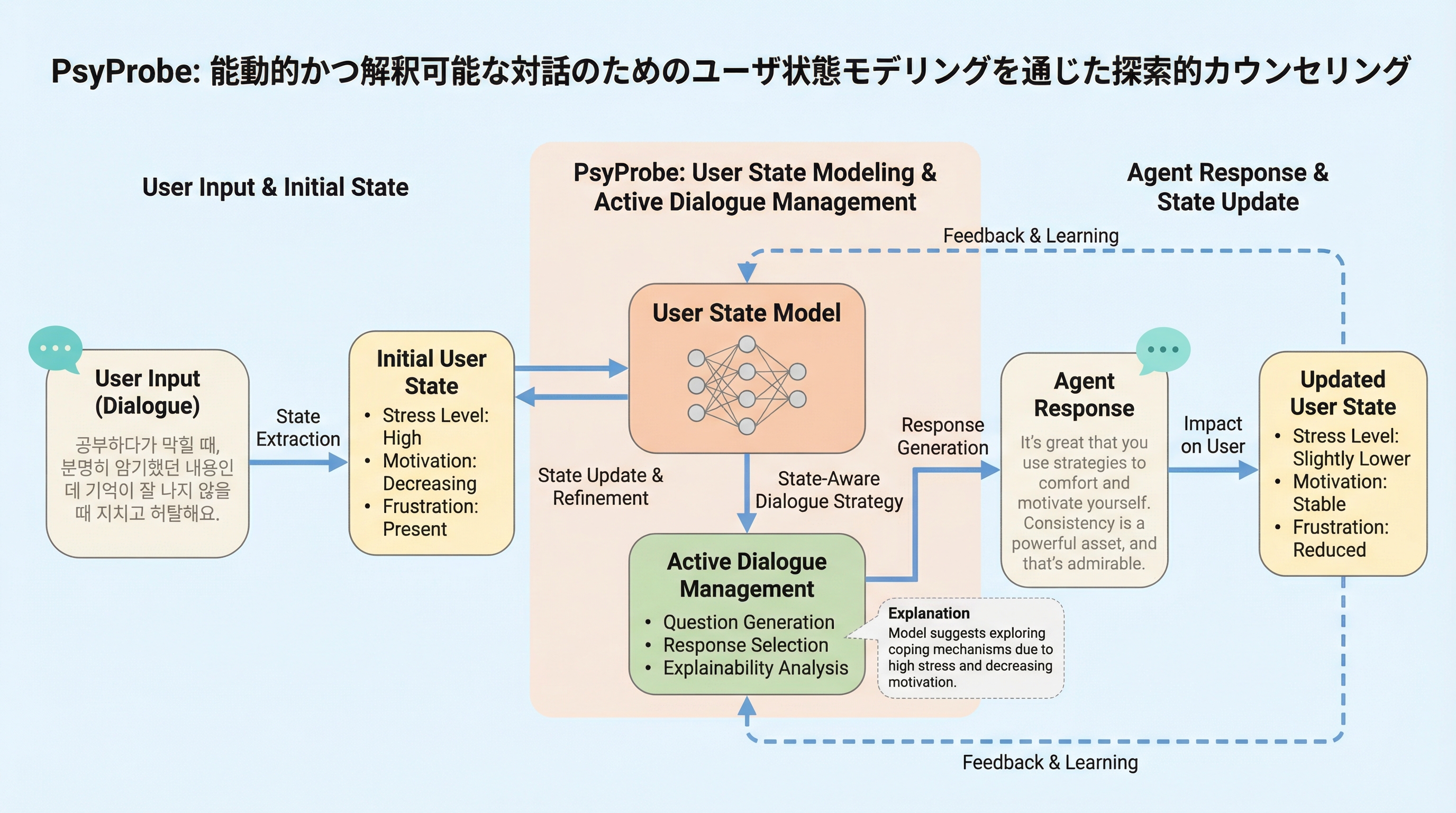
PsyProbeは、カウンセリングの初期段階である「探索」に特化し、大規模言語モデルが陥りがちな受動的な応答を克服するために開発された、能動的かつ解釈可能な対話システムである。心理学的なPPPPPIフレームワーク(提示された問題、素因、誘因、持続要因、保護要因、影響)と認知の歪みの検出を統合し、ユーザーの心理状態を構造的に把握するState Builderや、情報の欠落を数値化して追跡するMemory Constructionなどの4つの高度なモジュールで構成されている。韓国での実証実験において、27名の参加者と専門家による評価の結果、人間のカウンセラーに匹敵する質問率を達成し、ユーザーのエンゲージメント向上と問題の本質に対する深い理解を促進することが確認された。
ベトナムの少数民族であるバナ族の言語を保護し、デジタル化を促進するため、限られた学習データでも高精度な翻訳を可能にするニューラル機械翻訳(NMT)技術が開発されました。 本研究では、既存の並列コーパスのみを活用し、複雑な前処理や追加データを必要としない「マルチタスク学習データ拡張(MTL DA)」と「文境界拡張」という2つの柔軟な手法を提案しています。 これらの手法は、バナ語特有の複雑な語彙構造やベトナム語との文法的な差異に起因する誤訳を大幅に改善し、文化遺産の継承と世代間コミュニケーションの活性化に大きく貢献する実用的な成果を示しました。
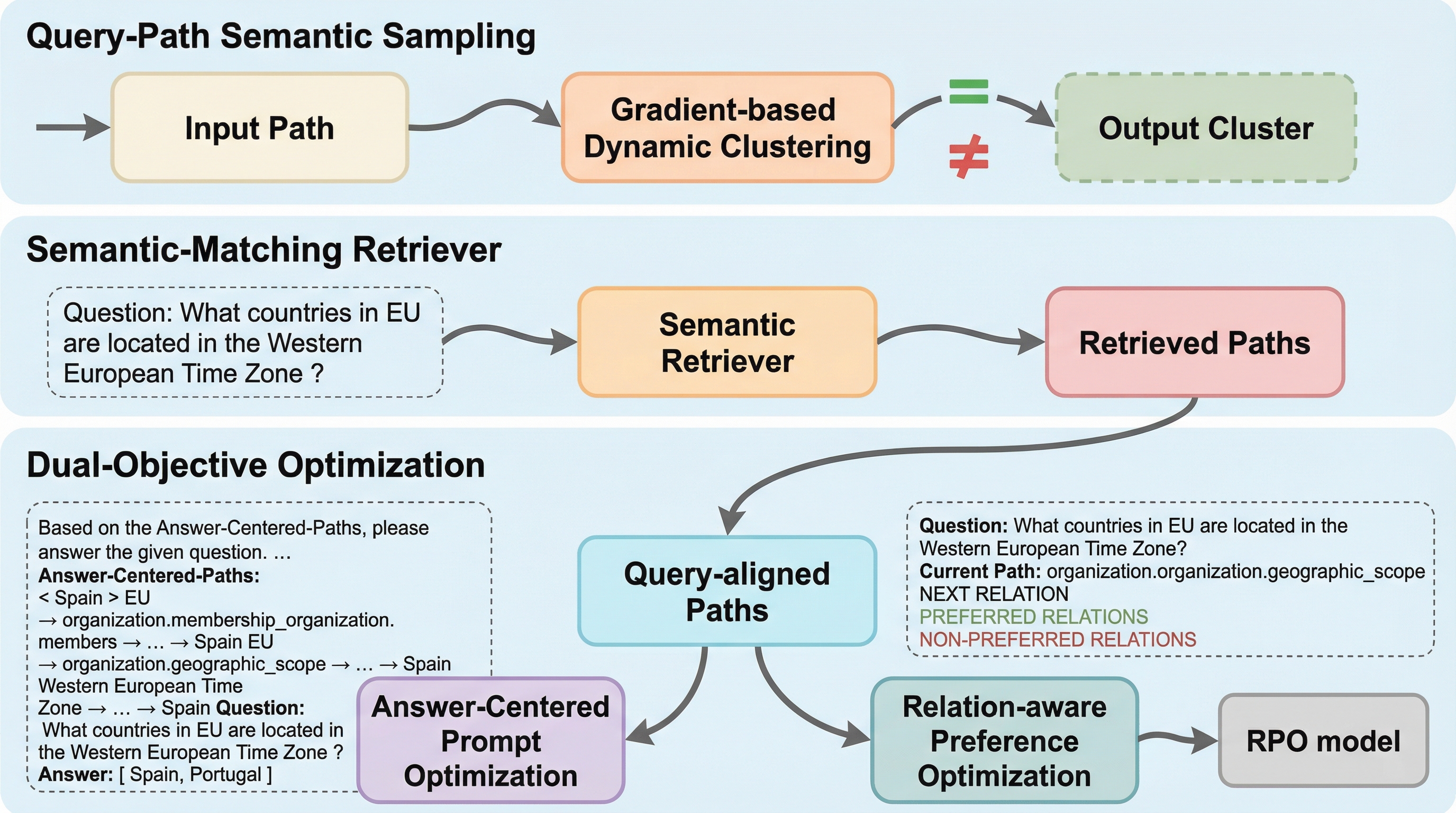
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、知識グラフ(KG)を活用したRAGにおいて、30億パラメータ未満の小規模モデルでも高精度な推論を可能にする新フレームワーク「RPO-RAG」が提案されました。

大規模言語モデル(LLM)を活用した多言語音声認識において、単一のプロジェクターが抱える音響と意味のマッピングの限界を打破するため、複数の専門家(エキスパート)を動的に統合する「SMEAR-MoE」を提案しました。
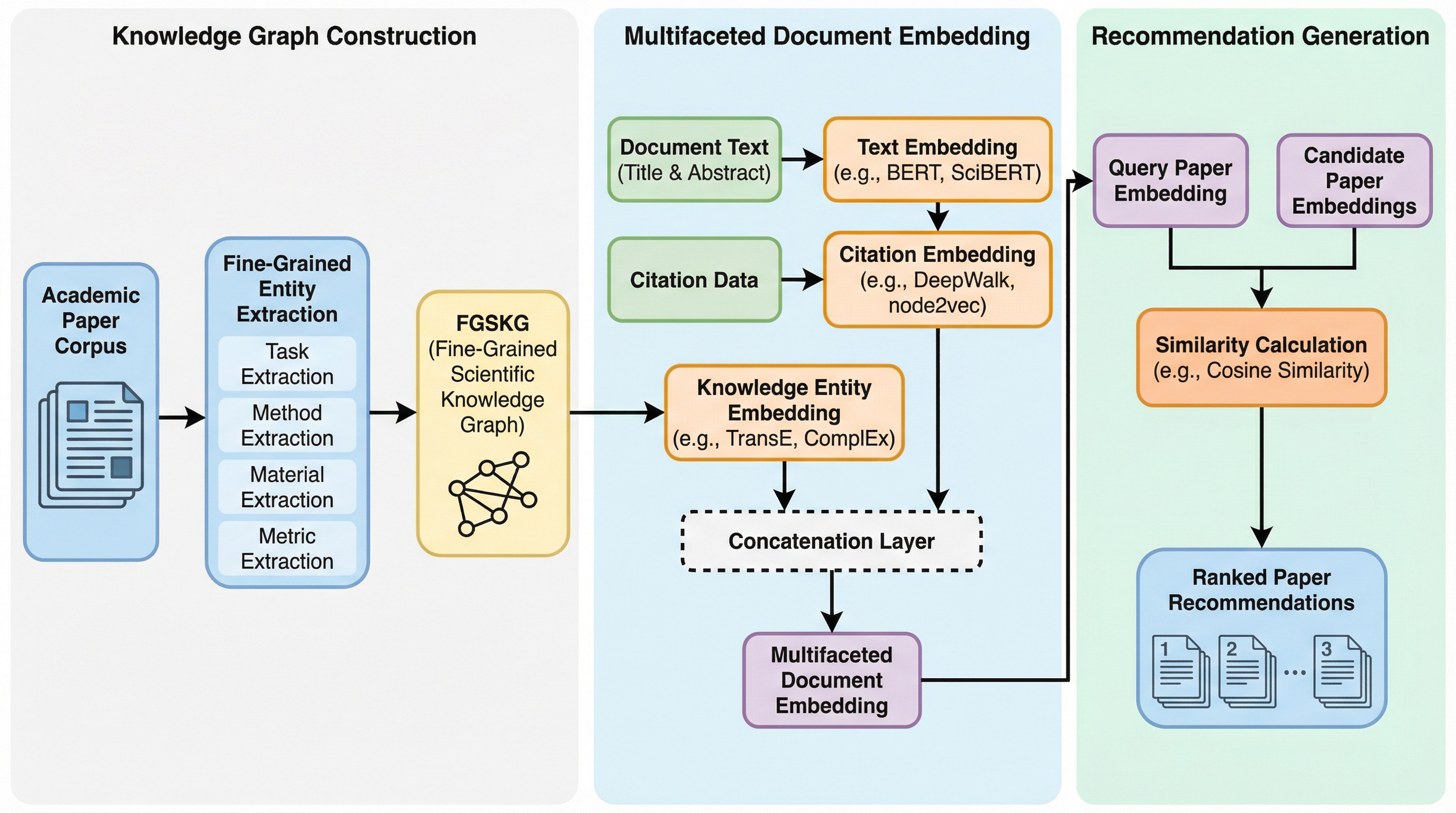
学術文献の爆発的な増加に伴い、研究者が自身のニーズに合致する論文を正確に見つける負担が増大している。従来の推薦システムは広範なトピックの類似性に依存しており、特定の研究手法やタスクといった詳細なニーズに応えることが困難であった。
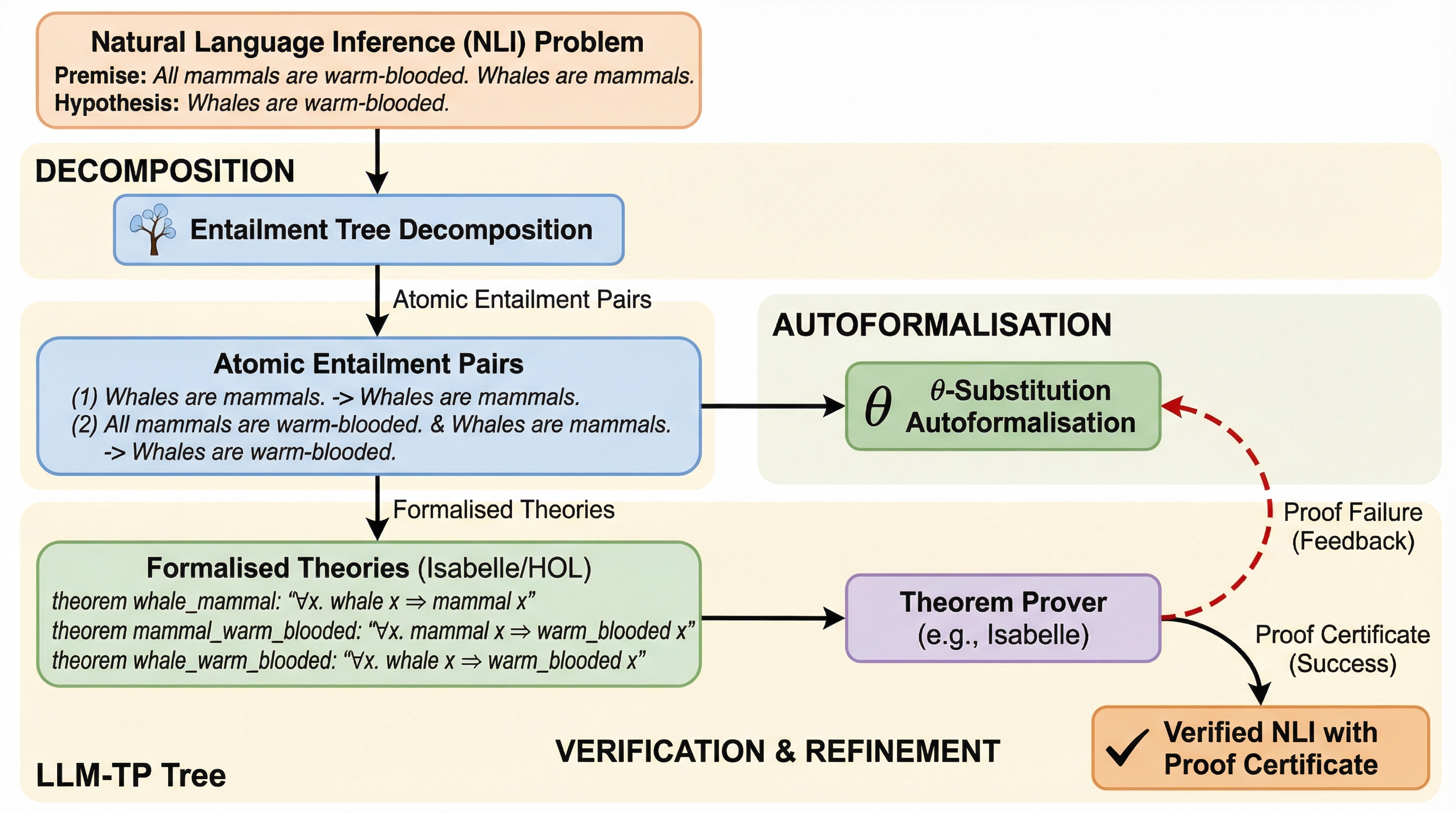
自然言語推論において、大規模言語モデルと定理証明器を統合する際の課題であった、長文や複雑な構文に起因する形式化エラーと、それによる推論チェーン全体の破綻を解決するため、推論過程を「含意ツリー」として構造化し、各ステップを最小単位の命題に分解して再帰的に検証・修正するフレームワーク「LLM-TP Tree」を提案しました。 この手法では、文を最小単位に切り分ける「原子的分解」と、イベントベースの論理形式で意味的な役割結合を厳密に管理する「$\theta$置換」を導入することで、定理証明器との互換性と元の文章への忠実性を両立させ、失敗した箇所のみを特定して局所的に修正する効率的なプロセスを実現しています。 5つの最新の大規模言語モデルを用いた評価の結果、従来手法と比較して検証成功率を最大48.9%向上させ、修正のための反復回数や実行時間を大幅に削減しながら、高い推論精度を維持することに成功し、複雑な多段階推論を論理的に厳密な形で検証できる実用的な可能性を示しました。
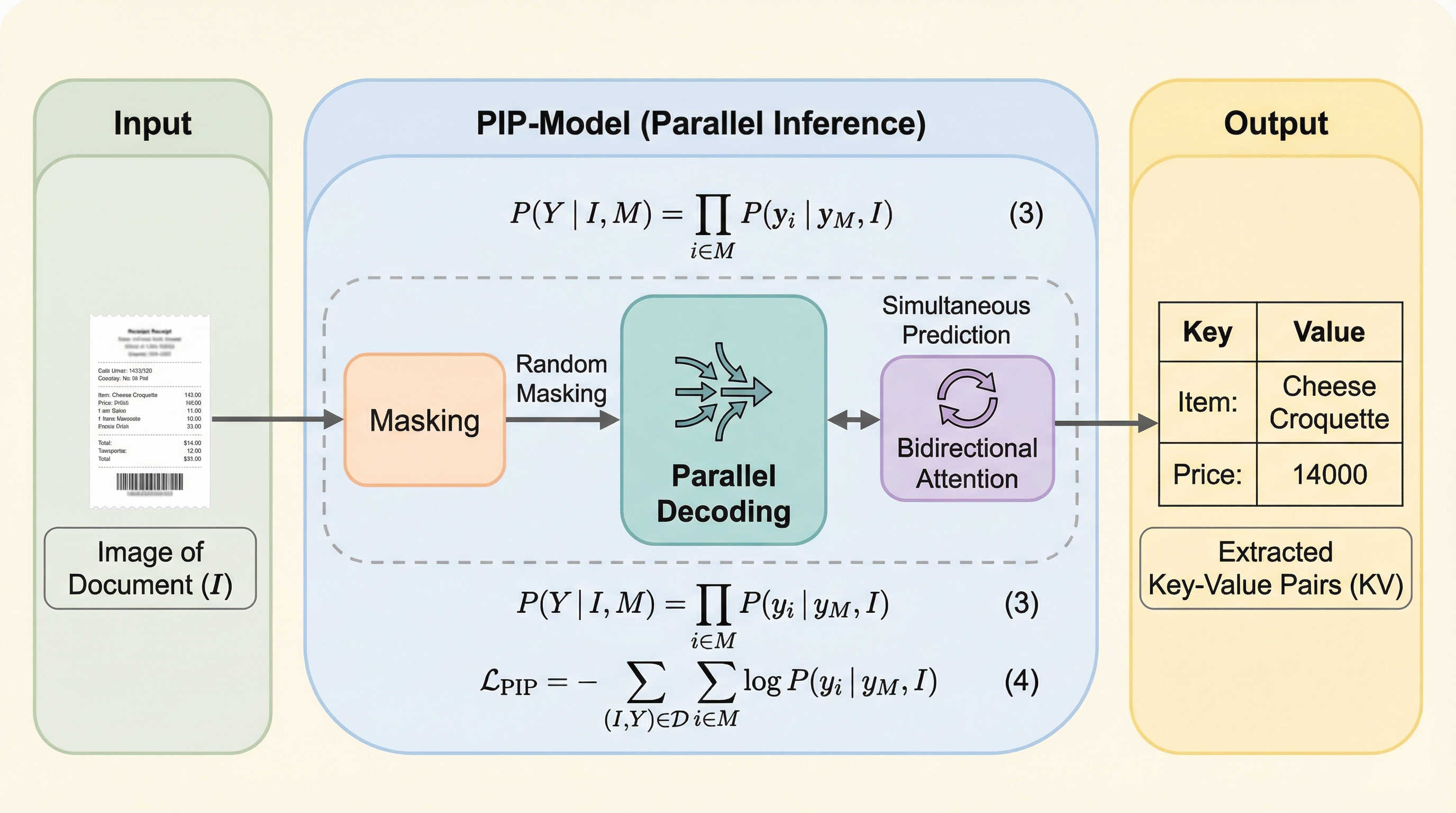
視覚的に豊かな文書(VrD)からのキー情報抽出(KIE)において、従来のマルチモーダル大規模言語モデル(MLLM)が抱えていた自己回帰的な逐次トークン生成による推論速度のボトルネックを解消するため、ターゲットとなる値を「[mask]」トークンで置き換えて一括生成する並列推論パラダイム「PIP」が提案されました。
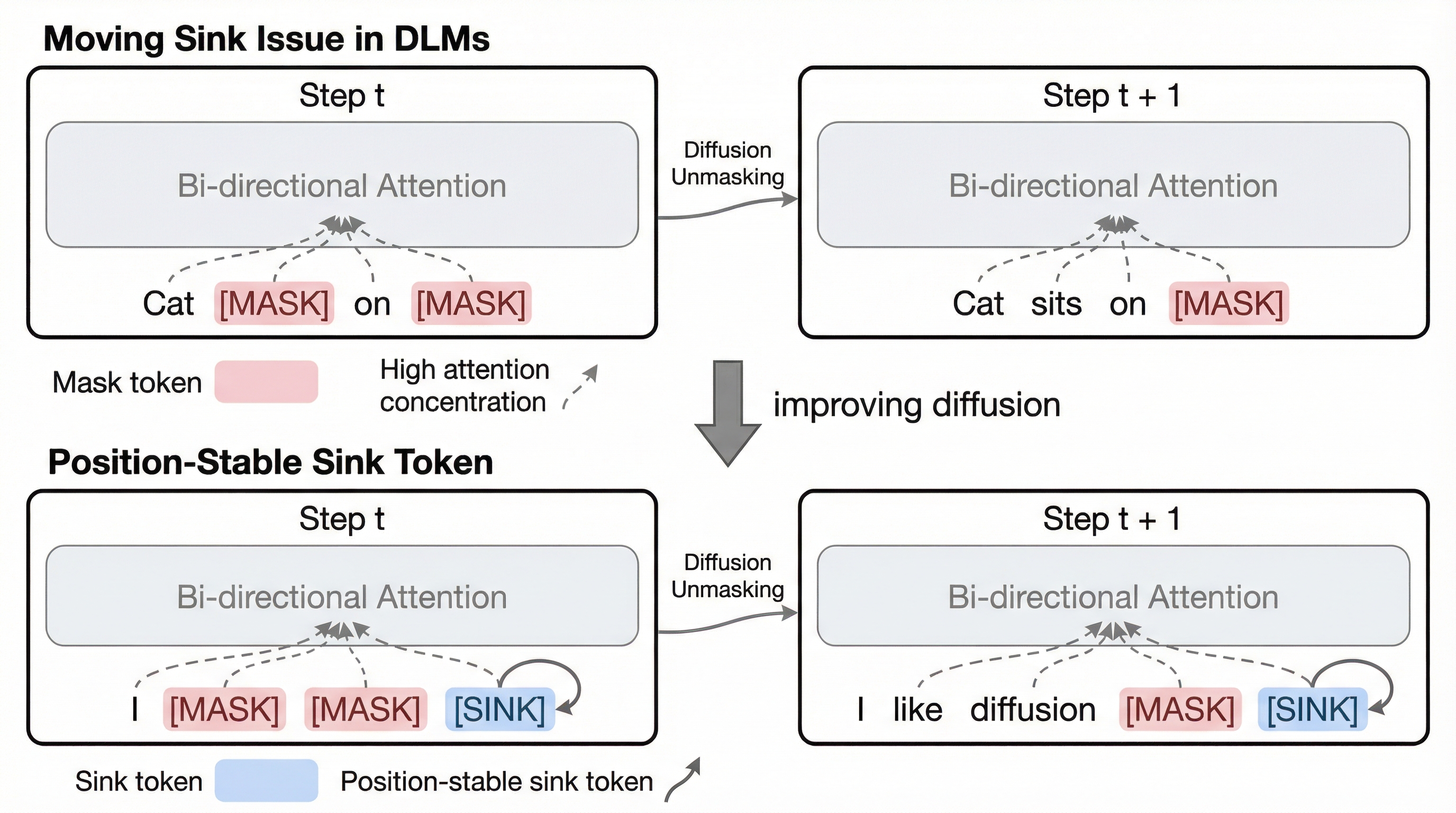
拡散言語モデル(DLM)において、注意が特定のトークンに過度に集中する「シンク現象」が、推論ステップごとに予測不能に移動する「移動シンク現象」を特定し、これがモデルの不安定性を引き起こす課題を明らかにした。
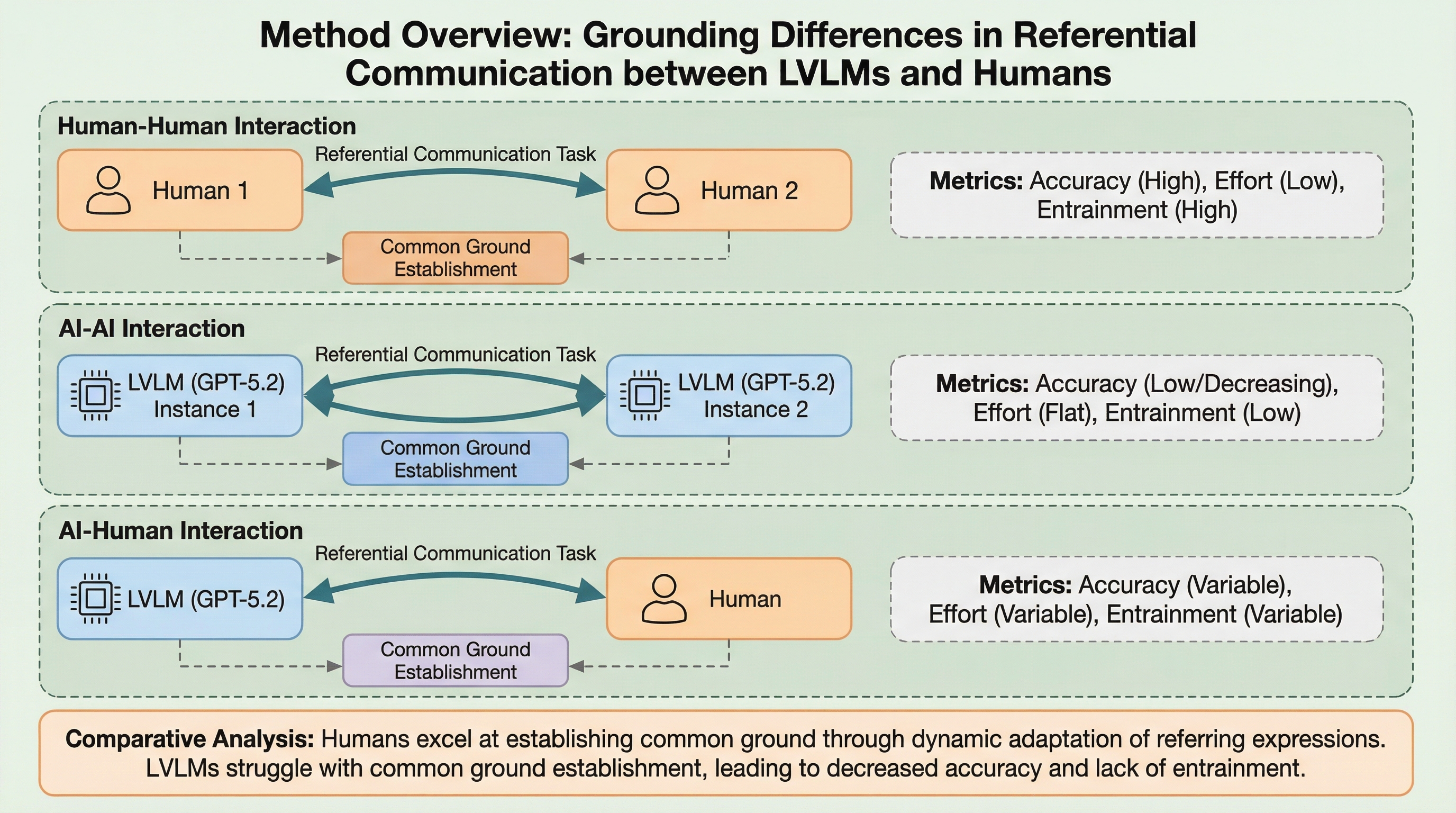
生成AIエージェントが人間と効果的に協力するには意図の予測が不可欠ですが、現在の大型視覚言語モデル(LVLM)は「共通基盤(コモングラウンド)」を構築する能力が欠如していることが明らかになりました。