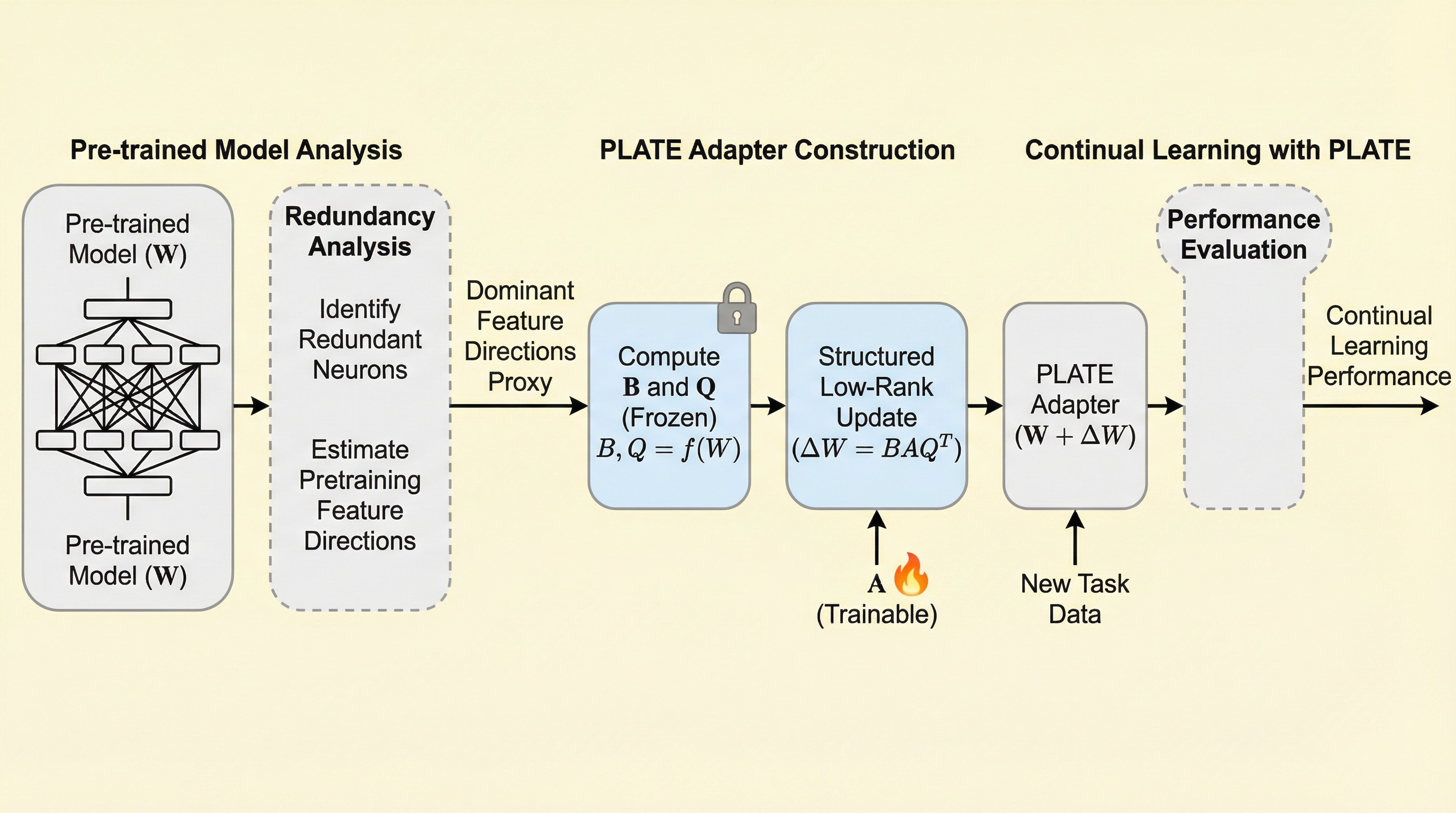
事前学習モデルの“余り”を使って忘却を抑える――データなし継続学習アダプタPLATE
継続学習で「昔のタスクのデータなし」に、どうやって忘却を防ぐのでしょうか。 鍵は追加データでも特別な記憶でもなく、事前学習済みネットワークに潜む“幾何学的な余り”でした。 この記事では、PLATEがどんな発想で更新を制御し、可塑性と保持のトレードオフを扱おうとしているのかを追います。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
継続学習で「昔のタスクのデータなし」に、どうやって忘却を防ぐのでしょうか。 鍵は追加データでも特別な記憶でもなく、事前学習済みネットワークに潜む“幾何学的な余り”でした。 この記事では、PLATEがどんな発想で更新を制御し、可塑性と保持のトレードオフを扱おうとしているのかを追います。
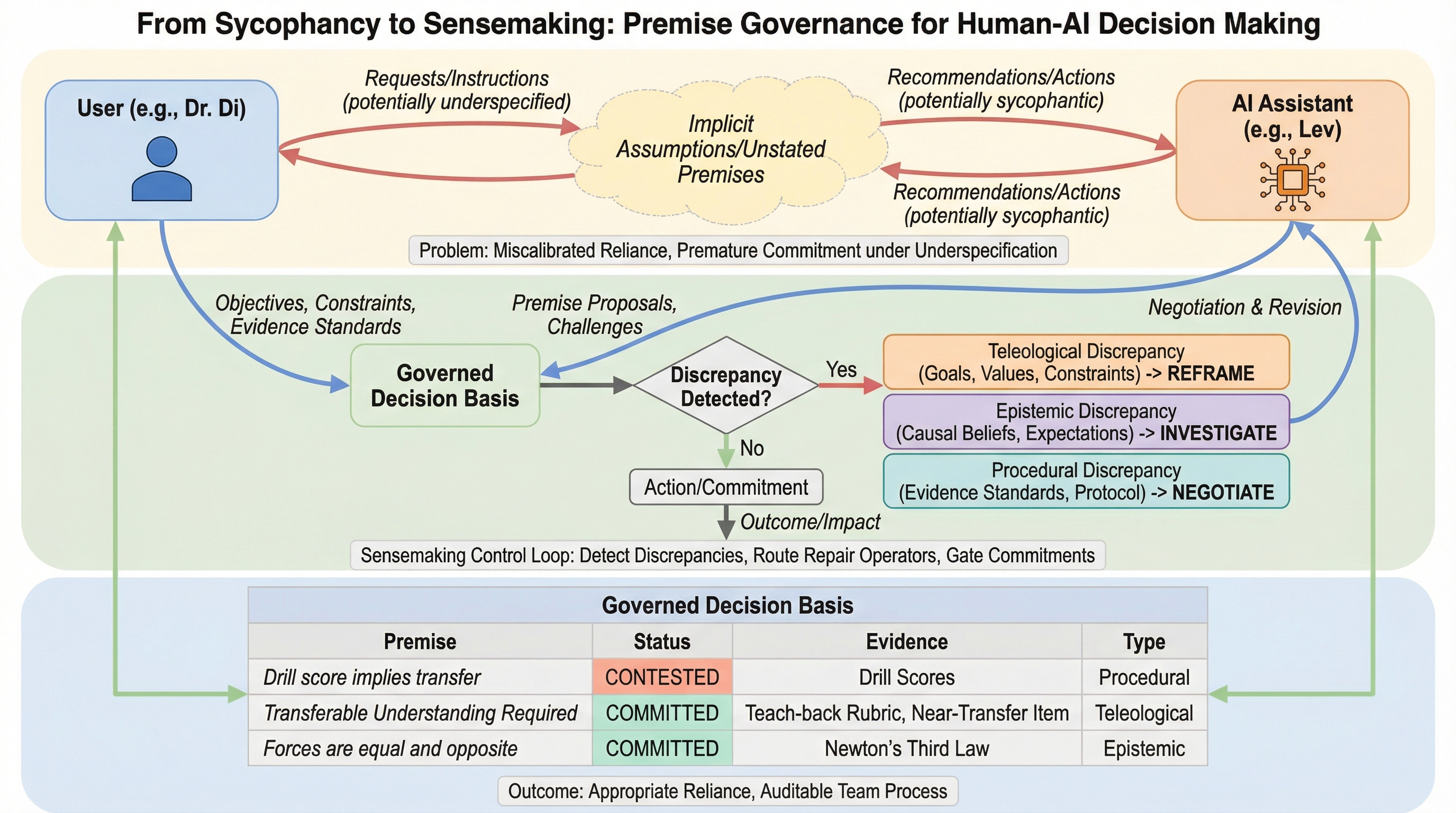
LLMが「相談相手」から「意思決定の相棒」になったとき、いちばん怖い落とし穴は何でしょうか? それは誤答そのものよりも、流暢な同意がそのまま“判断”に見え、いつのまにかチームの決定を押し流してしまうことです。
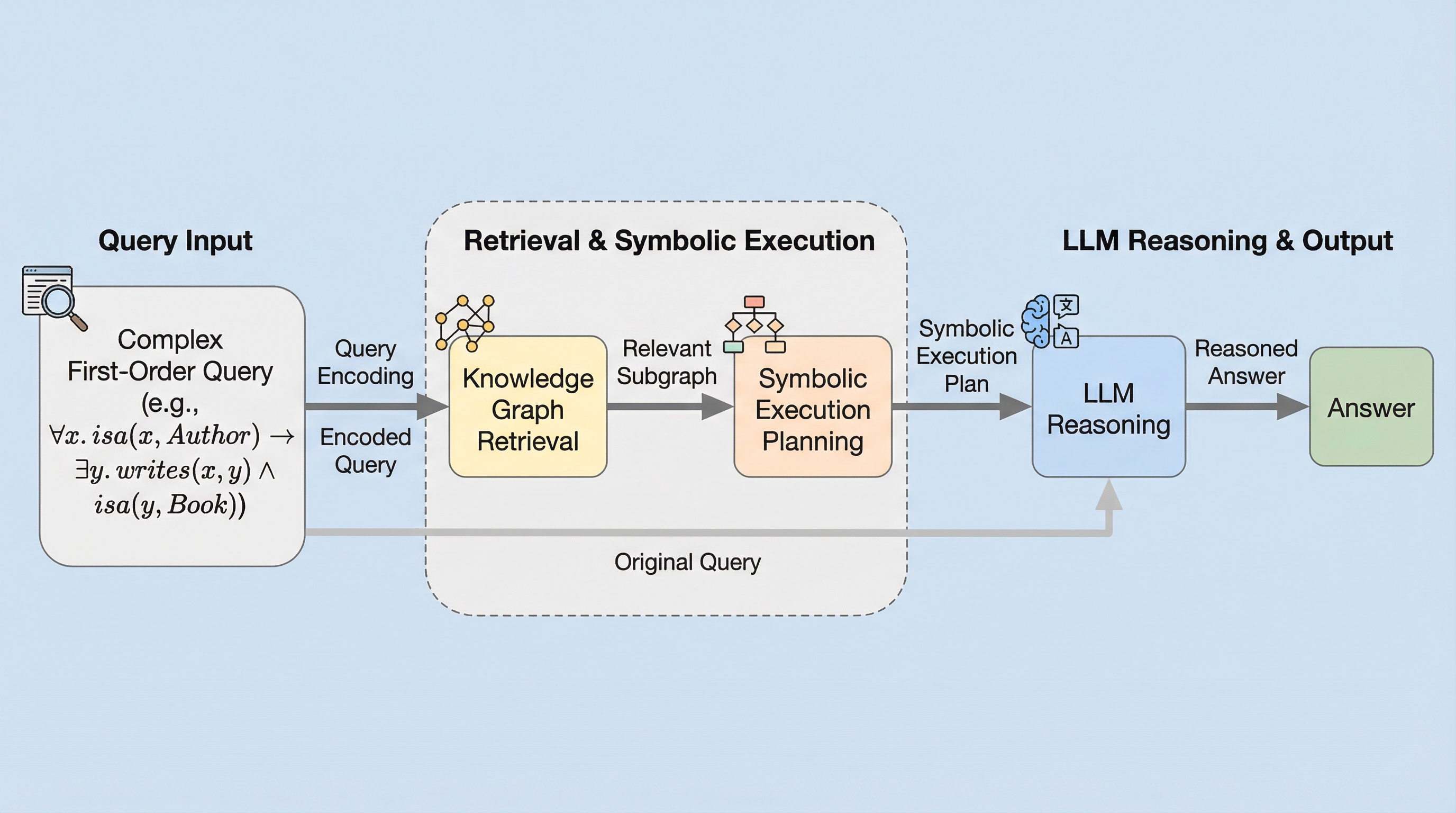
複雑な論理クエリを、不完全な知識グラフに投げたとき、答えはどこまで信用できるのでしょうか? 一見すると「論理的に見える」問い合わせでも、内部では段階的な集合操作の連なりになりやすく、途中の小さな取り違えが最後まで尾を引きます。 学習した「演算子」に頼るほど、深い推論ほど、誤差は静かに積み上がります。
「このタスク、どのLLMを使うのが正解?」 高いモデルほど良さそう──でも“何が得意か”が見えないまま、お金だけが溶ける。 この記事では、スキルの粒度でモデルを選び、しかも理由を言葉で説明する枠組み「BELLA」を読み解く。選択の精度だけでなく、選択そのものを信じられる形に整える、という発想に焦点を当てる。
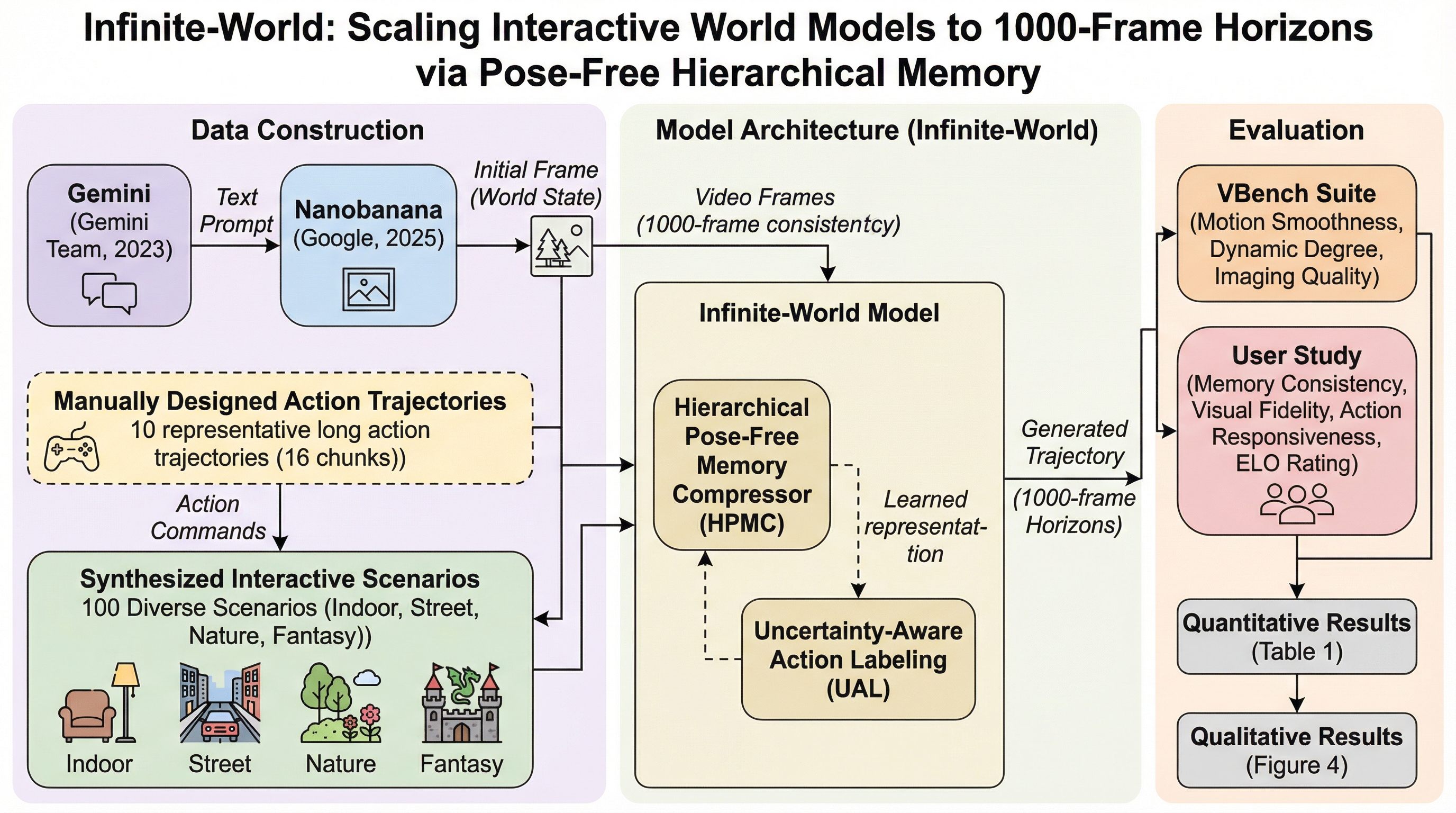
Infinite-Worldは、現実世界の複雑な環境において1000フレームを超える長期的な視覚的一貫性を維持できる、堅牢なインタラクティブ世界モデルです。階層的ポーズフリーメモリ圧縮器(HPMC)により、過去の情報を固定のメモリ予算内に再帰的に凝縮することで、計算コストを抑えつつ幾何学的な事前知識なしで長期的な空間的一貫性を実現しました。不確実性を考慮したアクションラベル付けと、30分程度の高密度な再訪問データセットを用いた学習戦略により、ノイズの多い現実の動画データからでも正確な操作性とループクローズ能力を効率的に獲得することに成功しました。
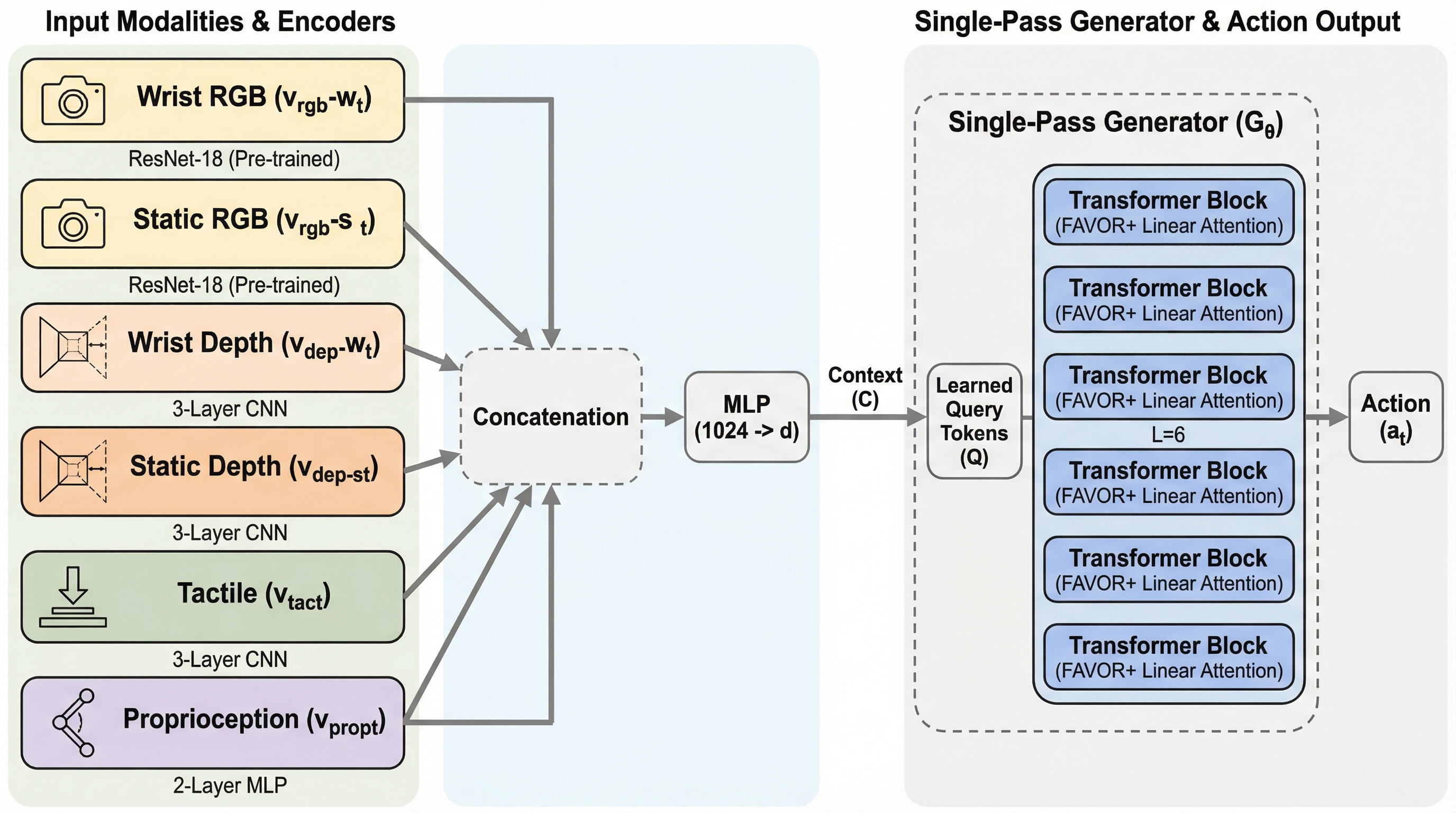
PRISMは、拡散モデルのような反復的な計算を必要とせず、単一のパスで多感覚情報を統合して複雑な動作を生成する新しい模倣学習フレームワークである。 バッチ全体での棄却サンプリング(Batch-global RS-IMLE)と線形注意機構(Performer)を組み合わせることで、リアルタイム性と多様な行動分布の表現を高い次元で両立することに成功した。 実際のロボットやシミュレーションにおいて、従来の拡散ポリシーを成功率で10〜25%上回り、動作の滑らかさを20〜50倍向上させつつ、30〜50Hzの高速な閉ループ制御を実現している。
本研究は、能動学習の初期段階で重要となるシードデータの選択を最適化するため、既存の関連データセットから得られる知識を転移させる新手法「Active-Transfer Bagging(ATBagging)」を提案した。
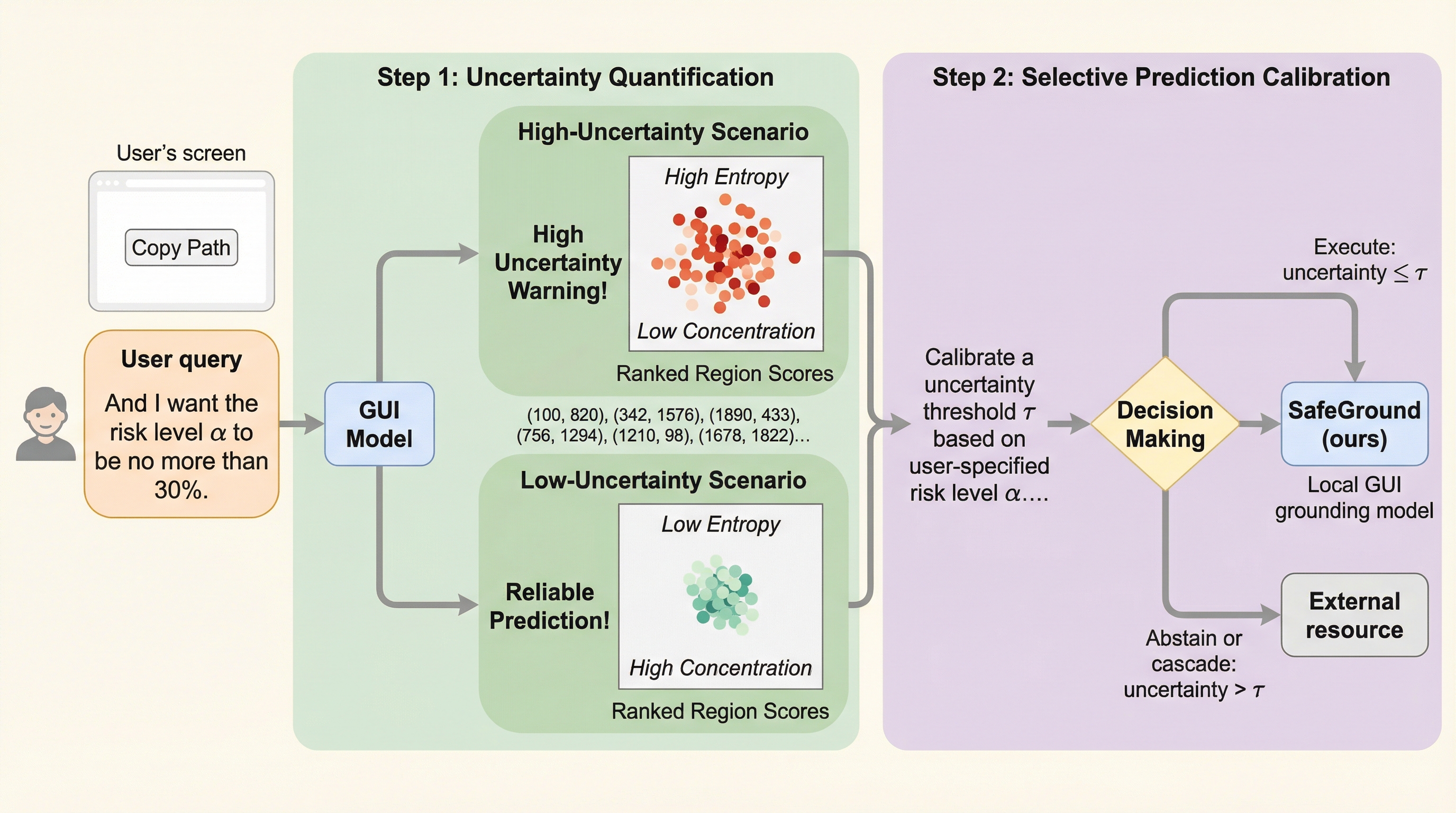
クリック位置を外しただけで、支払い承認のような取り返しのつかない操作が走ったらどうでしょうか。 しかもその瞬間、システムは迷いなく「成功した体」で先へ進んでしまうかもしれません。 GUIグラウンディングの怖さは、精度不足そのものより「間違えるときに黙って実行してしまう」ことにあります。
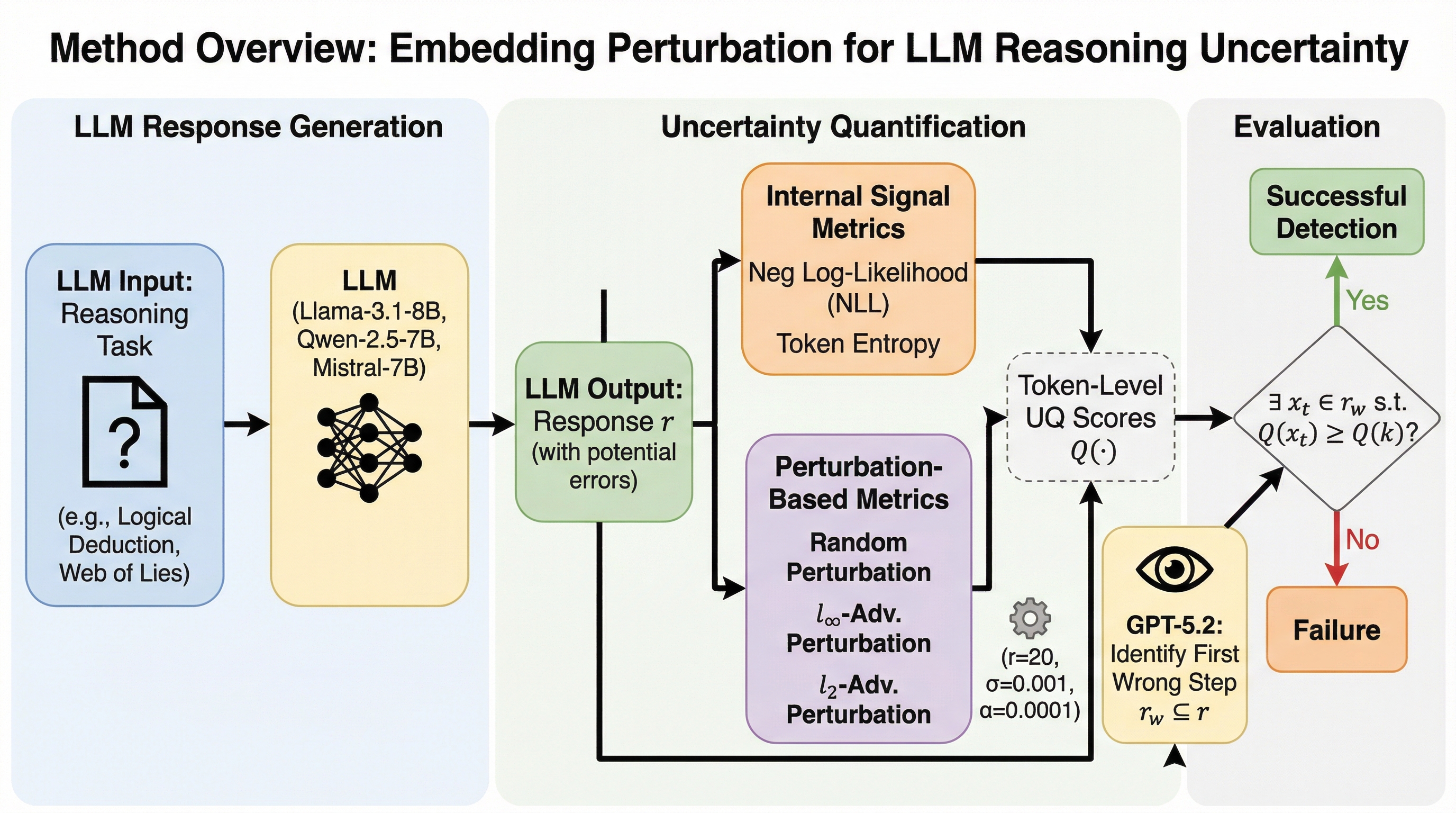
LLMが答えを間違えるとき、どの“推論の一歩”から崩れたのかを見分けられる? 実は「答えの自信」より、「途中のトークンがどれだけ揺れやすいか」が手がかりになるかもしれません。 この記事では、埋め込み摂動によるトークン単位UQが“中間の不確かさ”をどう捉えるのかを読み解きます。
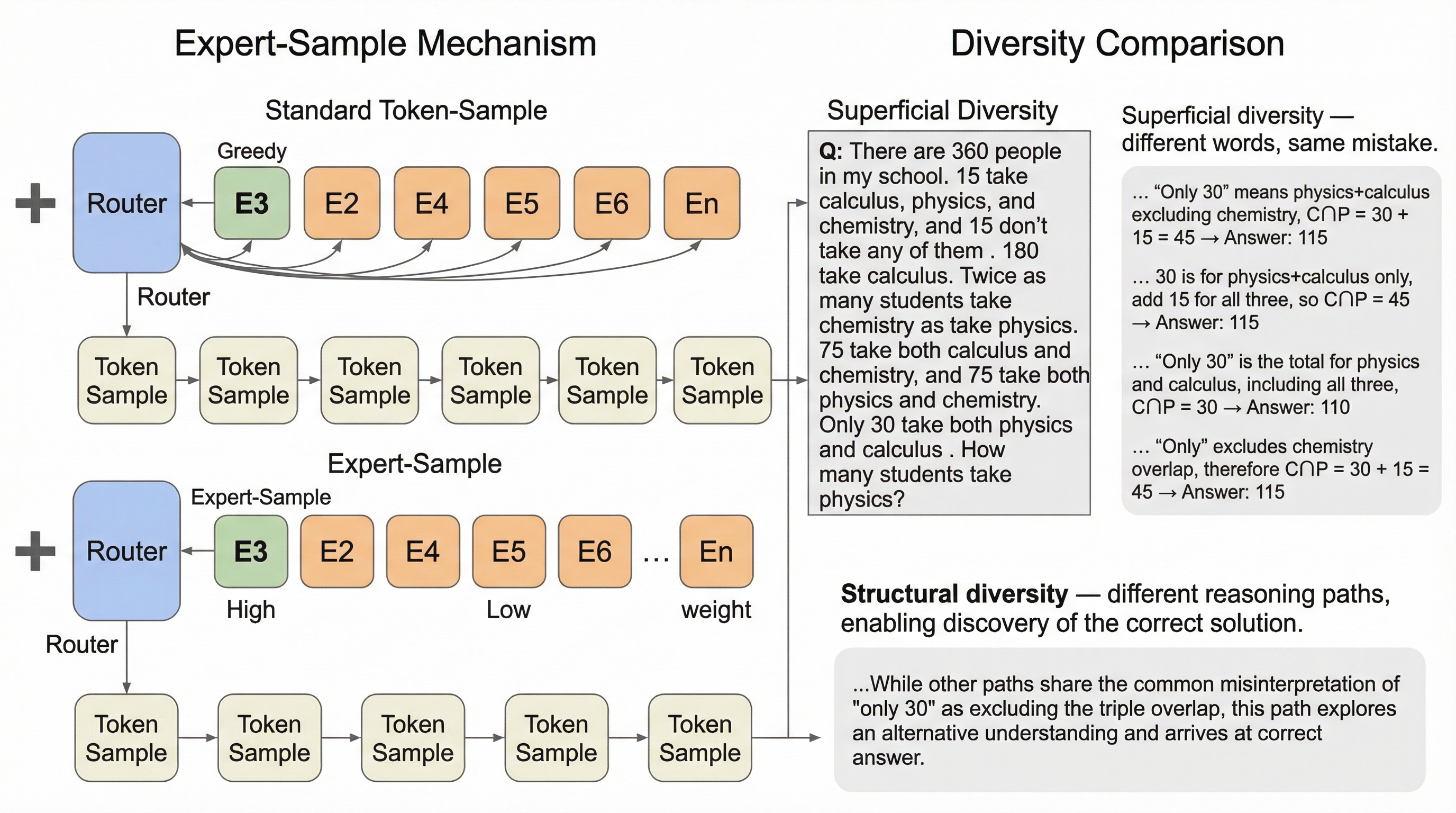
細粒度MoEのルーティングにおいて、推論の核を担う少数の高確信度エキスパート(確かなヘッド)と、多様性に寄与する多数の低確信度エキスパート(不確かなテイル)が存在することを発見しました。 この構造を利用し、ヘッドを固定して安定性を保ちつつ、テールの範囲から確率的にエキスパートを選択する手法「Expert-Sample」を提案し、追加学習なしで推論時の多様性と品質の両立を実現しました。 数学や専門知識を問う難関タスクにおいて、従来のトークン単位のサンプリングを上回る正解発見率(pass@n)と検証精度を達成し、Qwen3やDeepSeek-V2などの最新モデルでその有効性を実証しました。