確かなヘッド、不確かなテイル:細粒度MoEにおけるテスト時スケーリングのためのエキスパート・サンプル
細粒度MoEのルーティングにおいて、推論の核を担う少数の高確信度エキスパート(確かなヘッド)と、多様性に寄与する多数の低確信度エキスパート(不確かなテイル)が存在することを発見しました。 この構造を利用し、ヘッドを固定して安定性を保ちつつ、テールの範囲から確率的にエキスパートを選択する手法「Expert-Sample」を提案し、追加学習なしで推論時の多様性と品質の両立を実現しました。 数学や専門知識を問う難関タスクにおいて、従来のトークン単位のサンプリングを上回る正解発見率(pass@n)と検証精度を達成し、Qwen3やDeepSeek-V2などの最新モデルでその有効性を実証しました。
TL;DR(結論)
細粒度MoEのルーティングにおいて、推論の核を担う少数の高確信度エキスパート(確かなヘッド)と、多様性に寄与する多数の低確信度エキスパート(不確かなテイル)が存在することを発見しました。 この構造を利用し、ヘッドを固定して安定性を保ちつつ、テールの範囲から確率的にエキスパートを選択する手法「Expert-Sample」を提案し、追加学習なしで推論時の多様性と品質の両立を実現しました。 数学や専門知識を問う難関タスクにおいて、従来のトークン単位のサンプリングを上回る正解発見率(pass@n)と検証精度を達成し、Qwen3やDeepSeek-V2などの最新モデルでその有効性を実証しました。
なぜこの問題か
大規模言語モデル(LLM)の性能を最大限に引き出すためのアプローチとして、推論時に複数の回答候補を生成し、その中から最適なものを選択する「テスト時スケーリング」が注目を集めています。通常、回答の多様性を生み出すためには、各トークンの出力確率分布に対して温度パラメータ(Temperature)を調整するサンプリング手法が用いられます。しかし、この従来手法には深刻なトレードオフが存在します。温度を高く設定すると回答のバリエーションは増えますが、個々の回答の論理的な一貫性が失われ、モデルが本来持っている推論能力が低下してしまいます。逆に温度を低くすると、生成される回答が似通ってしまい、困難な問題を解くための新しい視点や解法を見つけ出すことができなくなります。特に、数学的推論や高度な専門知識を必要とするタスクでは、単なる言葉の言い換えではなく、根本的な思考プロセスの多様性が求められます。 一方で、近年のモデル設計では、1層あたり数百のエキスパートを備え、1トークンごとに複数のエキスパートを活性化させる「細粒度Mixture-of-Experts(MoE)」アーキテクチャが主流となっています。…
核心:何を提案したのか
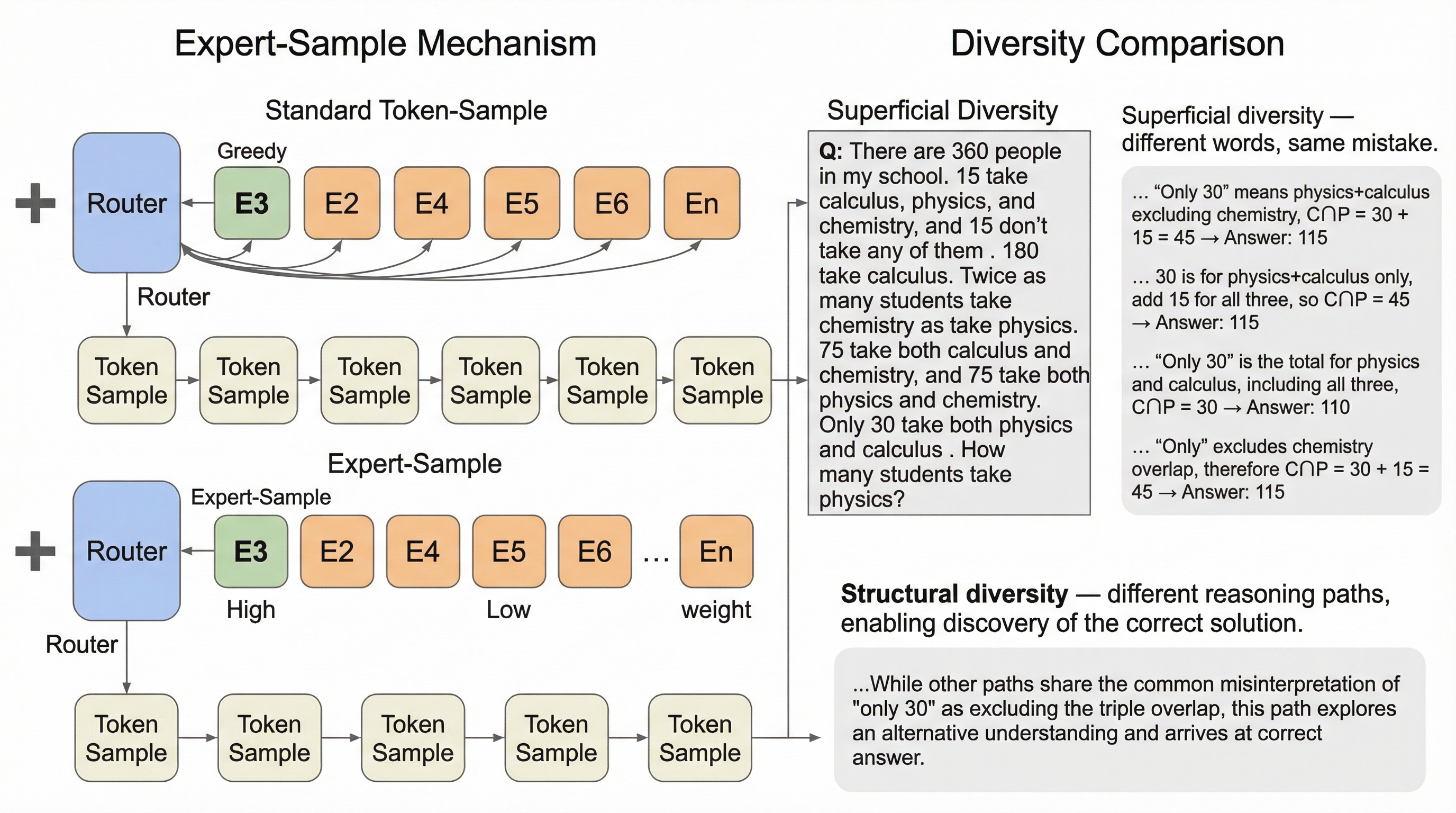
本研究の核心は、細粒度MoEのルーティング挙動に関する重要な発見と、それに基づいた新しいサンプリング手法「Expert-Sample」の提案にあります。著者らはまず、モデルが各トークンに対してエキスパートを選択する際のスコア分布を詳細に分析しました。その結果、非常に興味深いパターンが明らかになりました。ルーターが出力するスコアの上位には、極めて高い確信度で選ばれる少数のエキスパート(Certain Head)が存在し、それに続いて、スコアが低くかつ互いに僅差で並んでいる膨大な数のエキスパート(Uncertain Tail)が控えているという構造です。実験により、上位の確信度が高いエキスパートのみを使用しても、決定論的な生成(Greedy Decoding)の精度はほとんど低下しないことが判明しました。しかし、複数のサンプルを生成した際の正解発見率(pass@n)は大幅に低下しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related