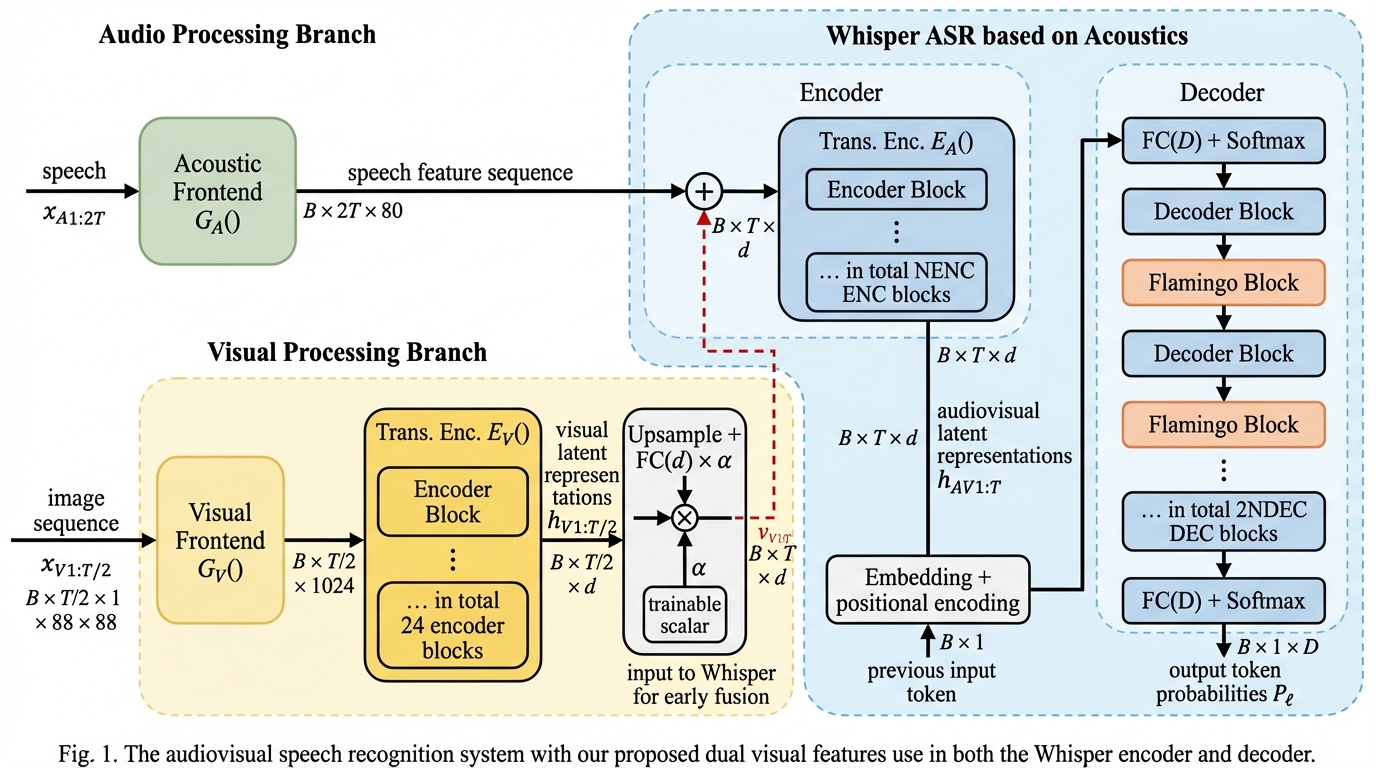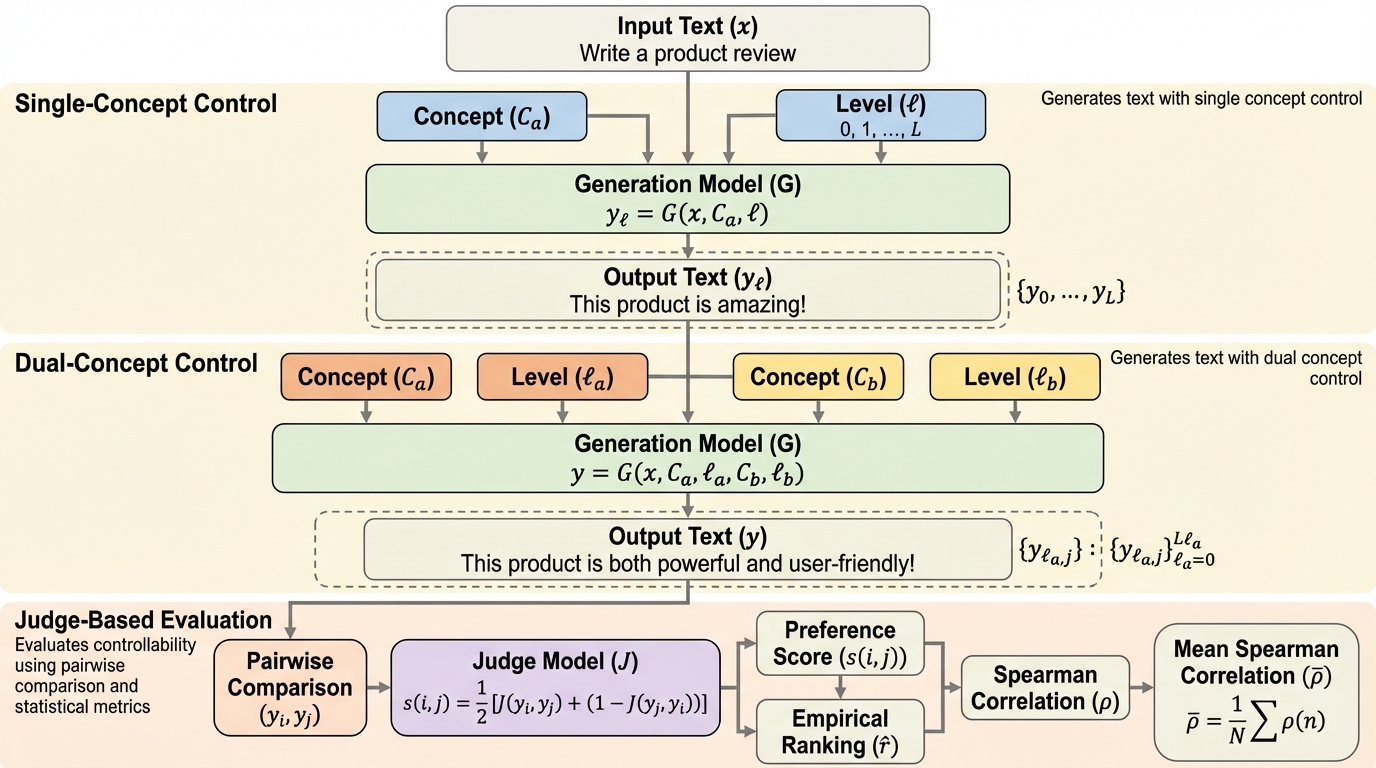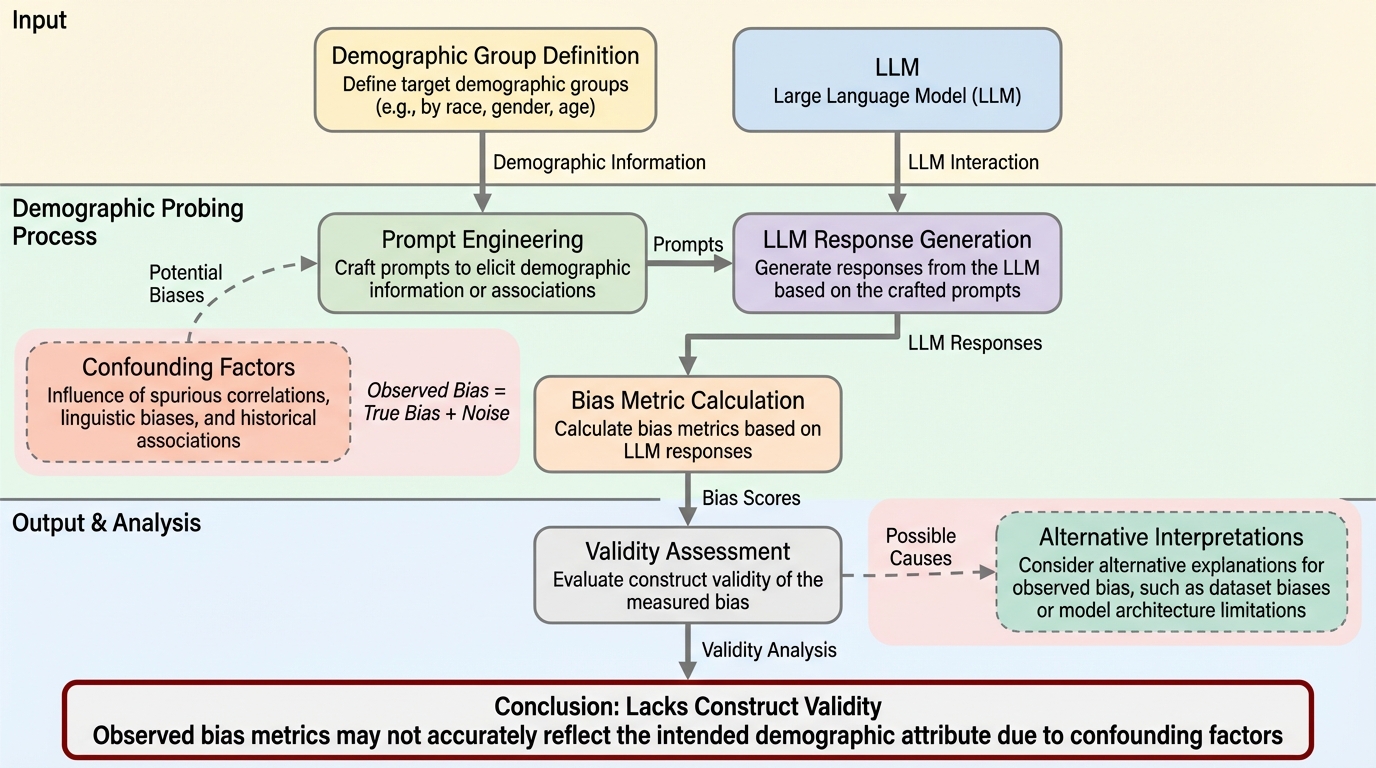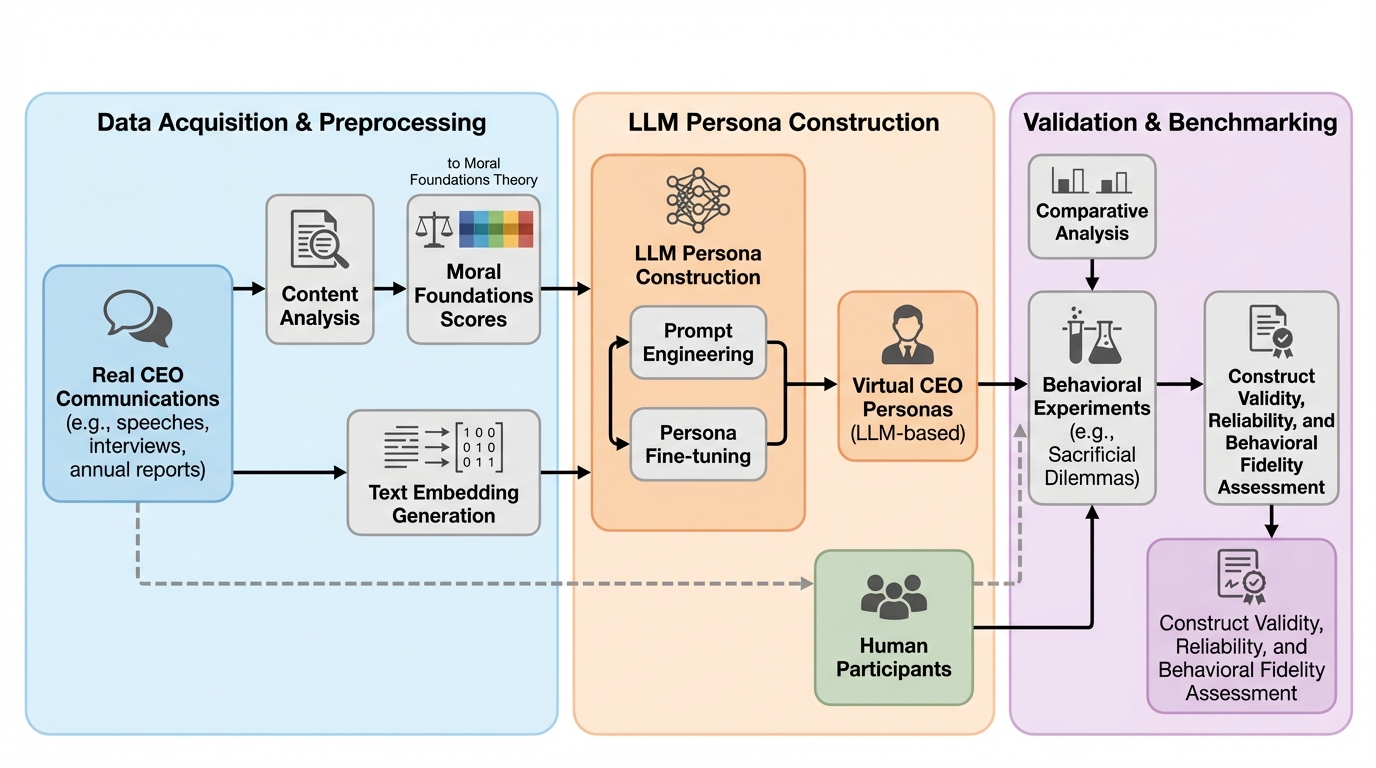
LLMによって洗練されたタクソノミーを用いた階層的テキスト分類
階層的テキスト分類(HTC)において、人間が作成した従来のタクソノミー(分類体系)には曖昧さや不整合が含まれており、言語モデルの学習を妨げているという課題がある。 本研究が提案する「TAXMORPH」は、大規模言語モデル(LLM)をタクソノミストとして活用し、リネームや統合、再配置を通じて分類体系全体をモデルの内部表現に適した構造へと自動的に洗練させるフレームワークである。 実験の結果、LLMで洗練されたタクソノミーは人間による元の体系を最大で2.9ポイント上回るF1スコアを記録し、モデルの推論バイアスとより密接に一致することで分類精度を向上させることが確認された。