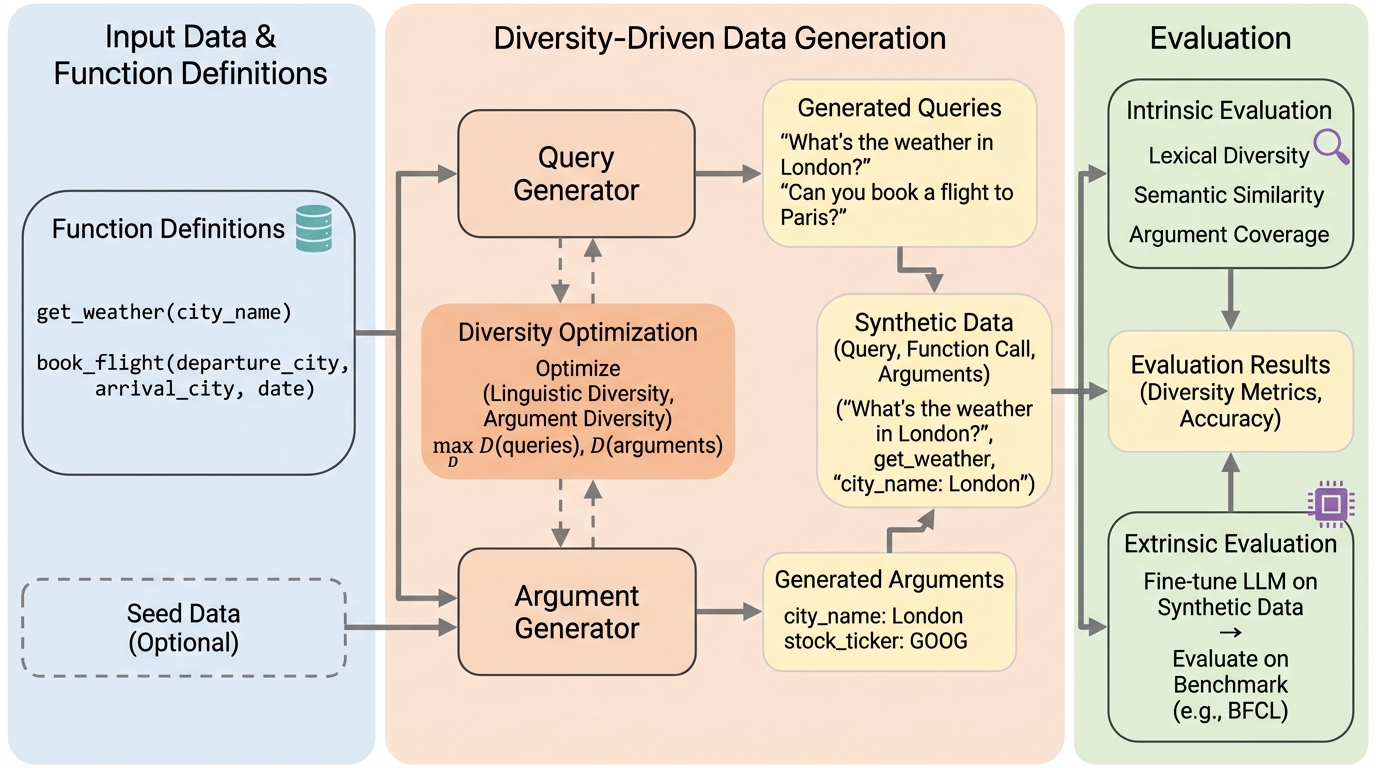
関数呼び出しエージェントのための合成データにおける言語的および引数の多様性
関数呼び出しエージェントの学習には多様なデータが不可欠ですが、既存手法は関数の種類や呼び出しパターンに偏り、ユーザーの言い回しの多様性(言語的多様性)や引数の値の網羅性(引数の多様性)が不足しているという課題がありました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
関数呼び出しエージェントの学習には多様なデータが不可欠ですが、既存手法は関数の種類や呼び出しパターンに偏り、ユーザーの言い回しの多様性(言語的多様性)や引数の値の網羅性(引数の多様性)が不足しているという課題がありました。
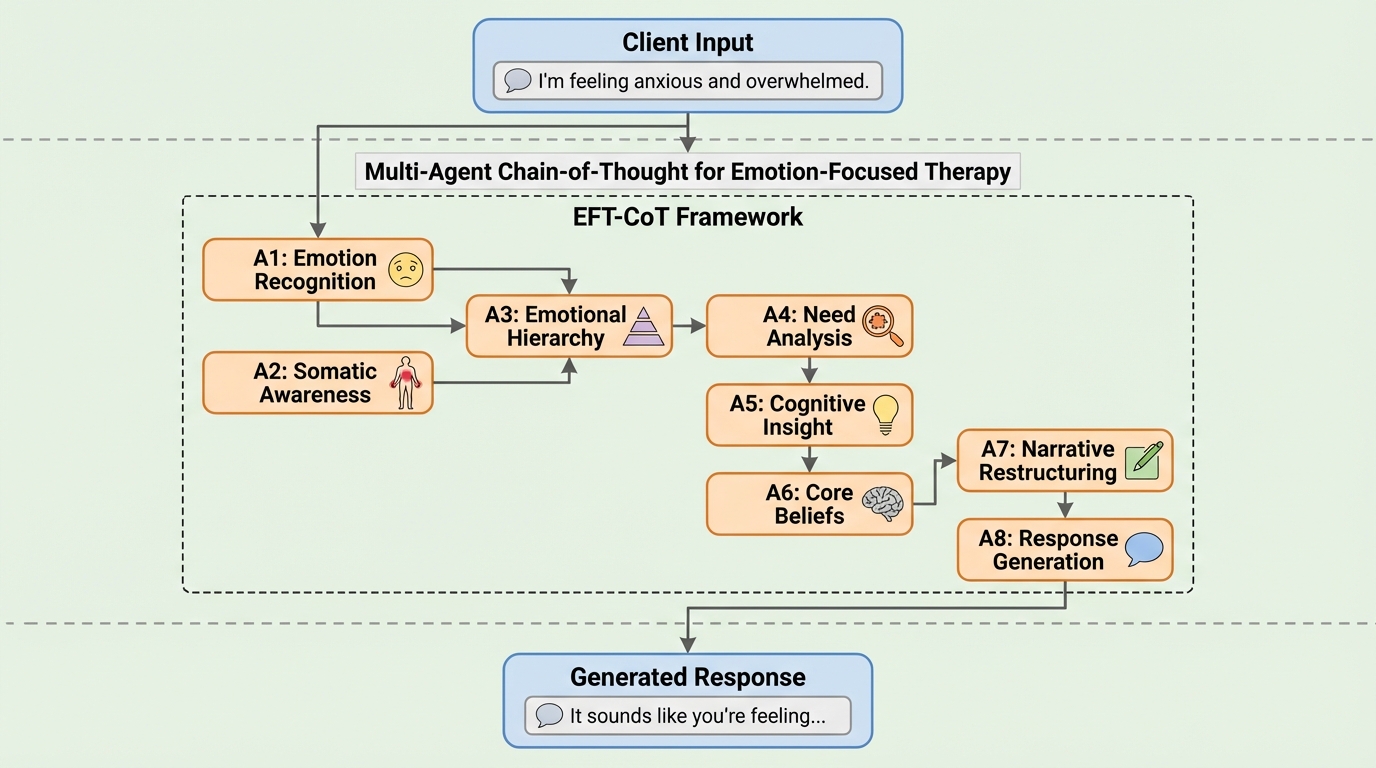
従来の認知行動療法(CBT)に基づくAI心理支援は論理的な書き換えを重視する「トップダウン」型であり、利用者の深い感情や身体的感覚への配慮が不足していたため、本研究では感情焦点化療法(EFT)の理論を取り入れた「ボトムアップ」型の新しいフレームワークであるEFT-CoTを提案した。
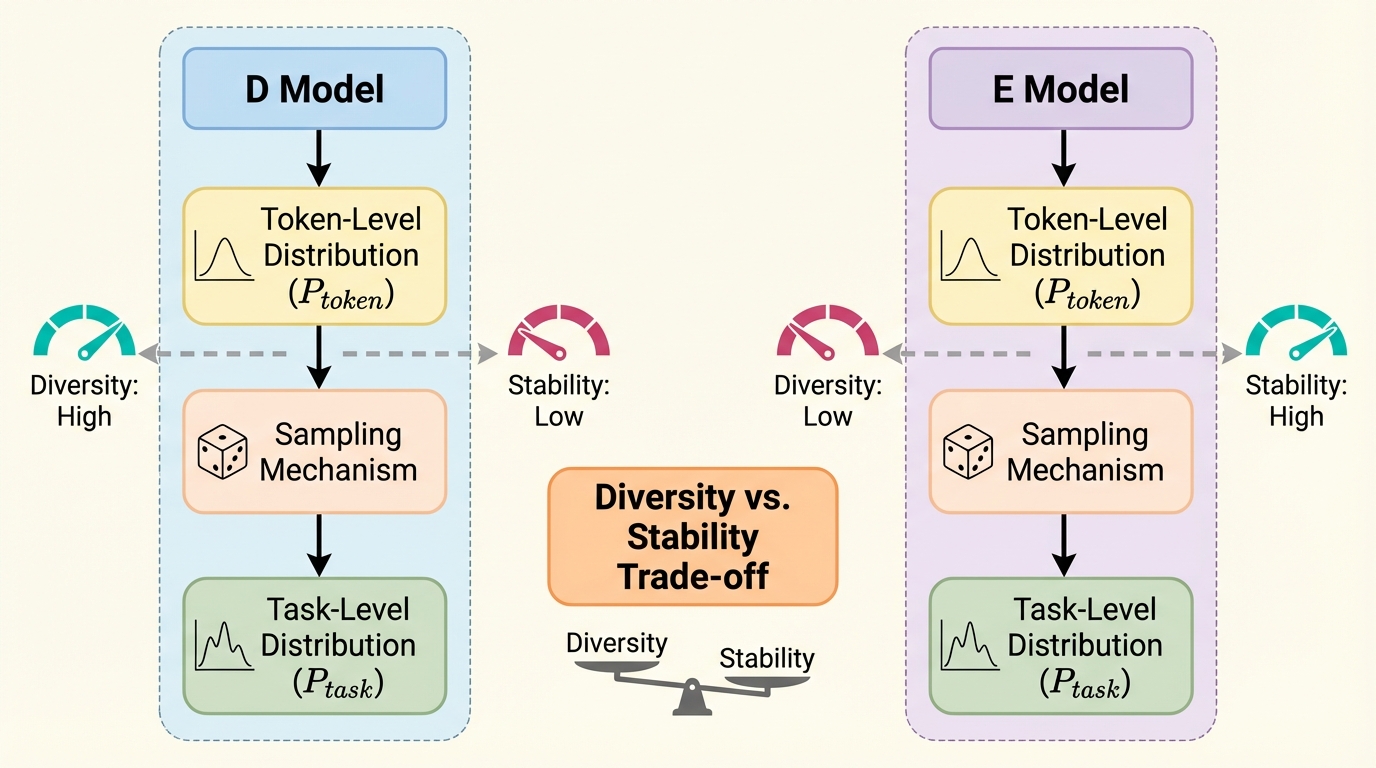
大規模言語モデル(LLM)の次トークン予測確率は、情報の関連性や商品の購入確率といったタスクレベルの目標分布($P_{task}$)と密接に関連していますが、そのサンプリング挙動には「Dモデル」と「Eモデル」という二極化された特性が存在することが明らかになりました。 Qwen-2.
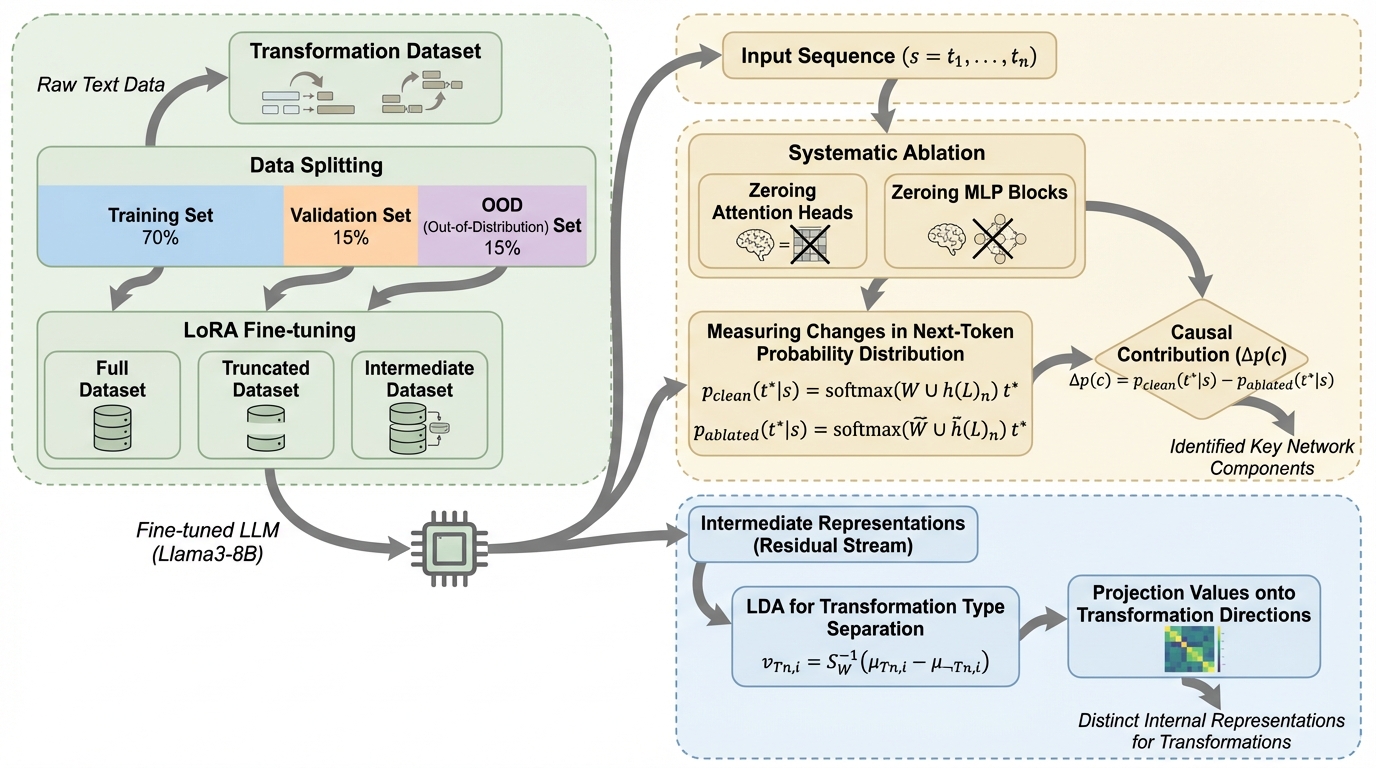
大規模言語モデルが学習データから抽象的な構造情報をどのように獲得し、それを未知の組み合わせの生成(構成的汎用化)に利用できるかを、変形文法に基づく独自の自然言語データセットを用いて検証した。 実験の結果、モデル内部で構造情報の表現が明確になる時期は、単純な次単語予測の精度向上よりも、複雑な推論タスクの性能向上と強く相関しており、学習の進展に伴い構造の区別が急激に明確化する相転移現象が確認された。 しかし、学習時に見たことのない複数の構造を組み合わせる能力は依然として限定的であり、中間的な生成ステップを明示しない限り正確な出力を得ることが困難であることから、現在の学習手法における構成的な知識生成の限界が浮き彫りになった。
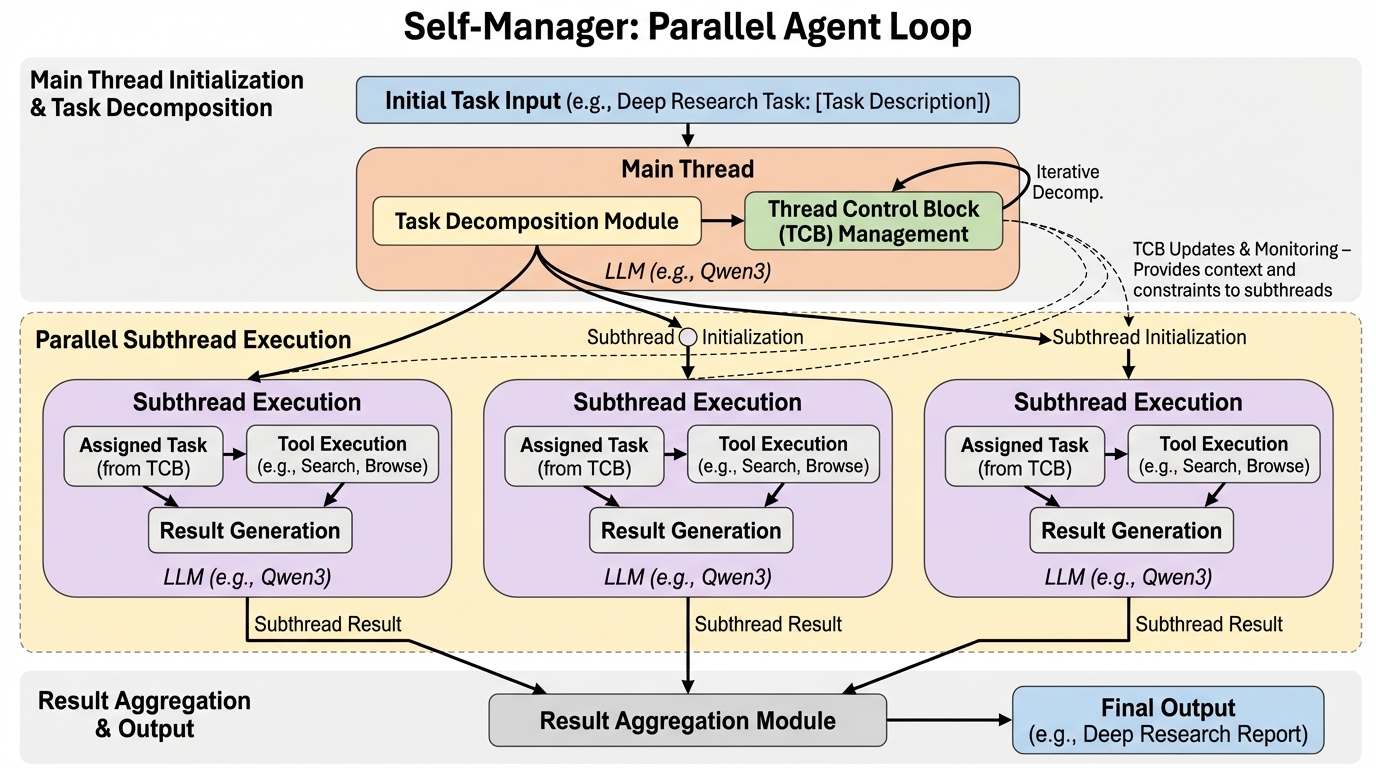
長文の深掘り調査において、従来のエージェントが抱えていた文脈の線形な蓄積による情報の希釈や、逐次実行による処理の停滞という課題を解決するため、非同期かつ並列な実行を可能にする新しいアーキテクチャ「Self-Manager」が提案されました。
人工知能(AI)の急速な普及に伴い、インド、米国、英国、欧州連合における知的財産権(IPR)の現状を比較分析し、インドの既存法制度におけるAI特有の規定の欠如や、特許法第3条(k)がAI生成発明の特許化を阻害している現状、営業秘密保護の脆弱性などの法的な不整合を明らかにしている。
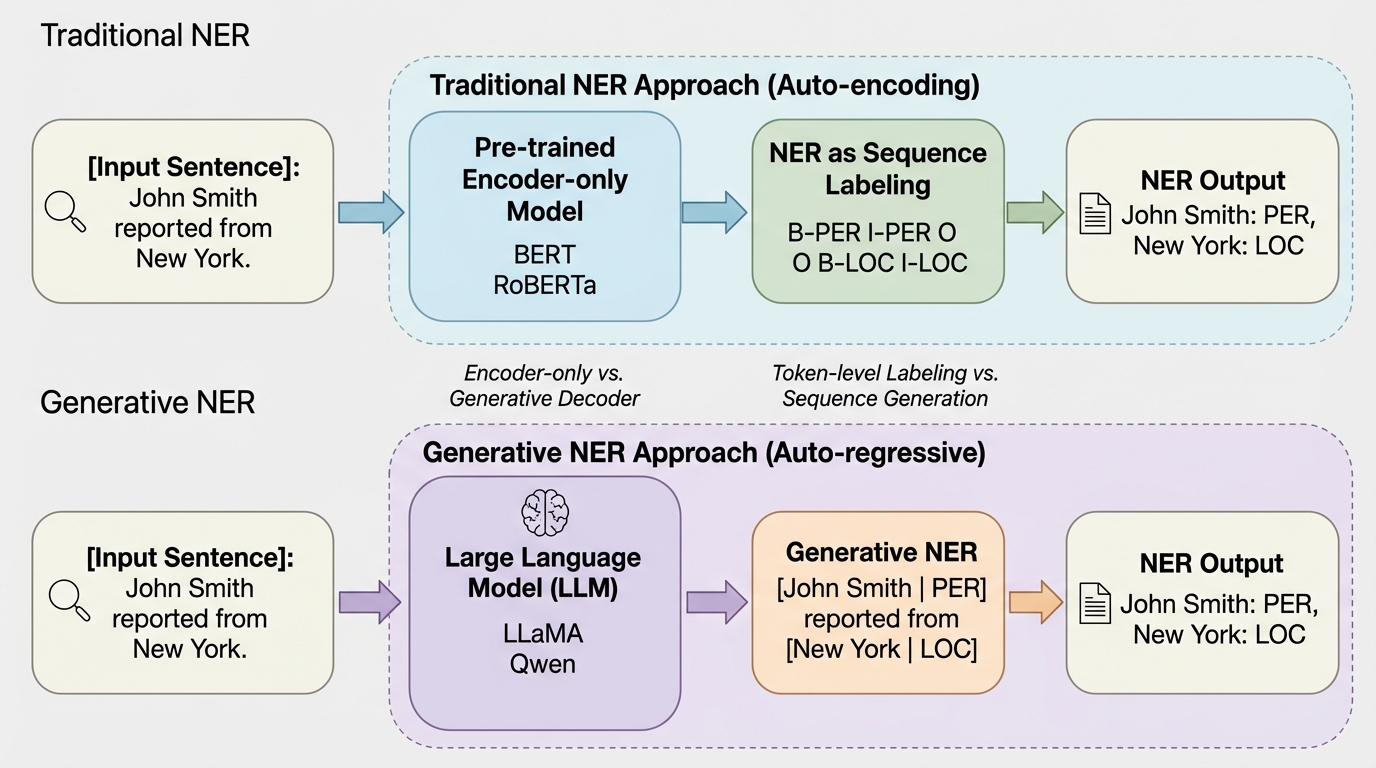
本研究は、LLaMAやQwenといった8つのオープンソース大規模言語モデル(LLM)を用い、生成的固有表現認識(NER)の性能を4つの標準データセットで系統的に評価しました。 検証の結果、LoRAによる効率的な微調整と、文章内に直接ラベルを埋め込む「Inline Bracketed」や「XML」形式を組み合わせることで、オープンソースLLMは従来のBERT系専門モデルに匹敵し、GPT-3などの巨大なクローズドモデルを上回る性能を達成できることが明らかになりました。 また、LLMのNER能力は単なるエンティティの記憶ではなく指示に従う生成能力に由来しており、特定のNERタスクに特化した微調整を行ってもモデルの汎用的な知識や推論能力は損なわれず、むしろ読解タスクなどで性能が向上する場合があることも確認されました。
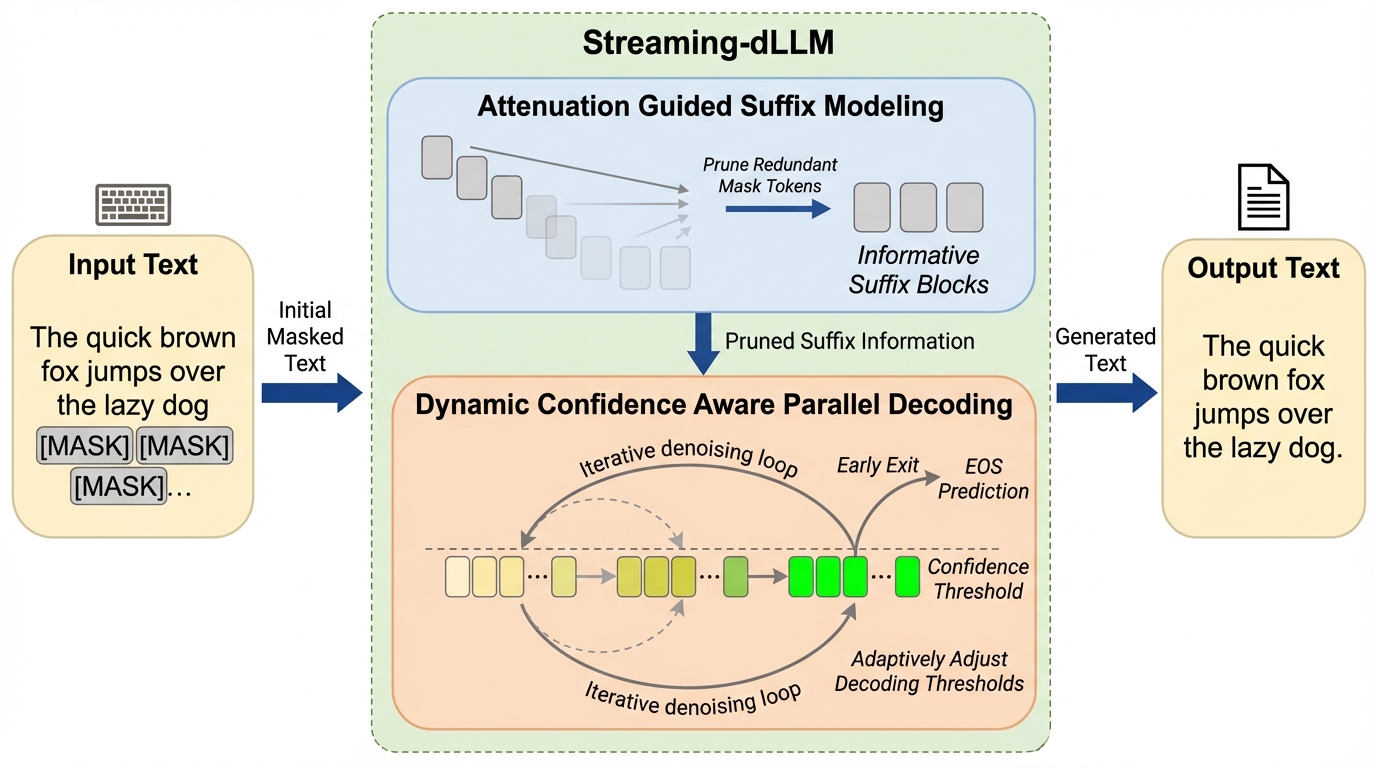
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。
大規模言語モデル(LLM)の微調整において、従来のLoRAは全ての層に一律のランクを割り当てていたが、本研究では各ランクの重要度をゲーム理論の「シャープレイ値」に着想を得た「Shapley sensitivity」で測定し、最適なランク割り当てを行うShapLoRAを提案した。
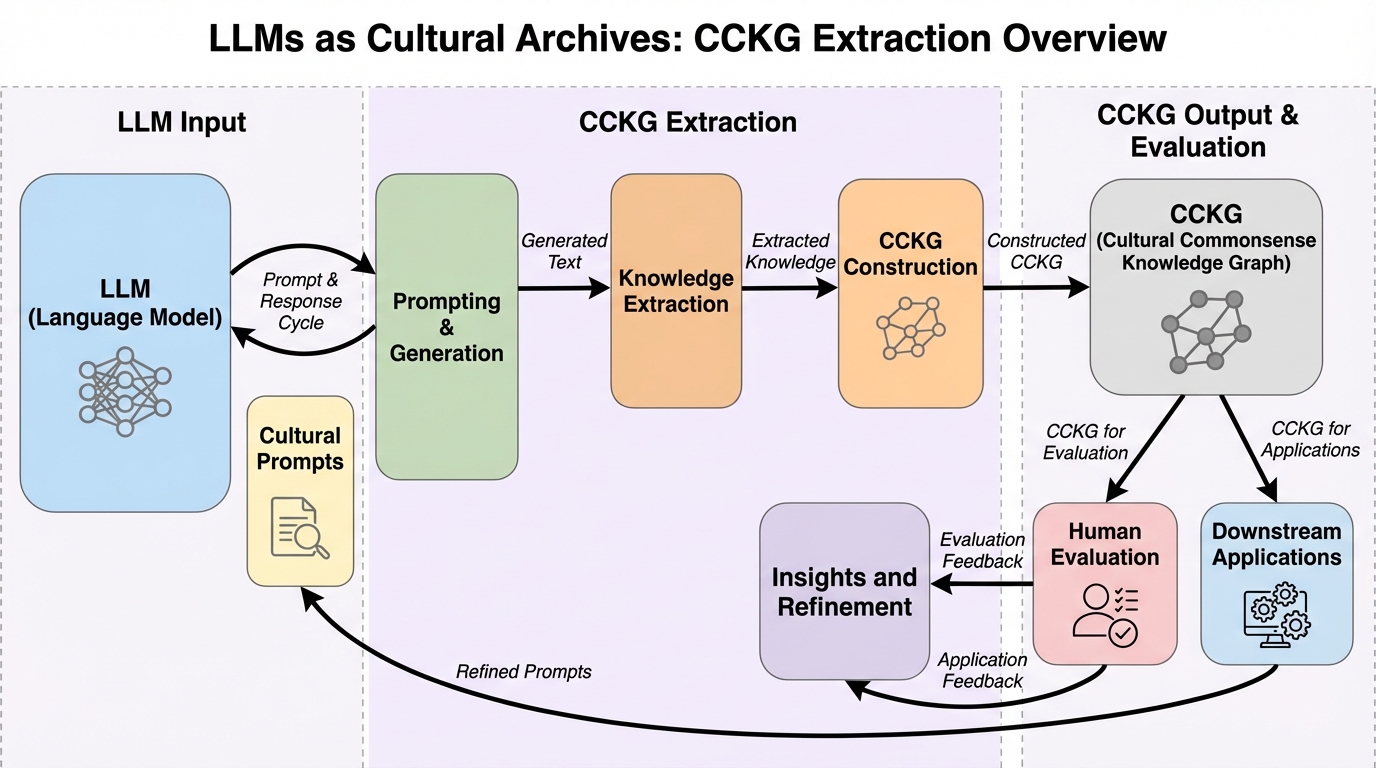
大規模言語モデル(LLM)が学習データの中に保持している、特定の文化に固有の常識や慣習を「もし〜ならば、次に〜する」という形式の推論チェーンとして体系的に抽出する新しいフレームワーク「CCKG」を開発した。