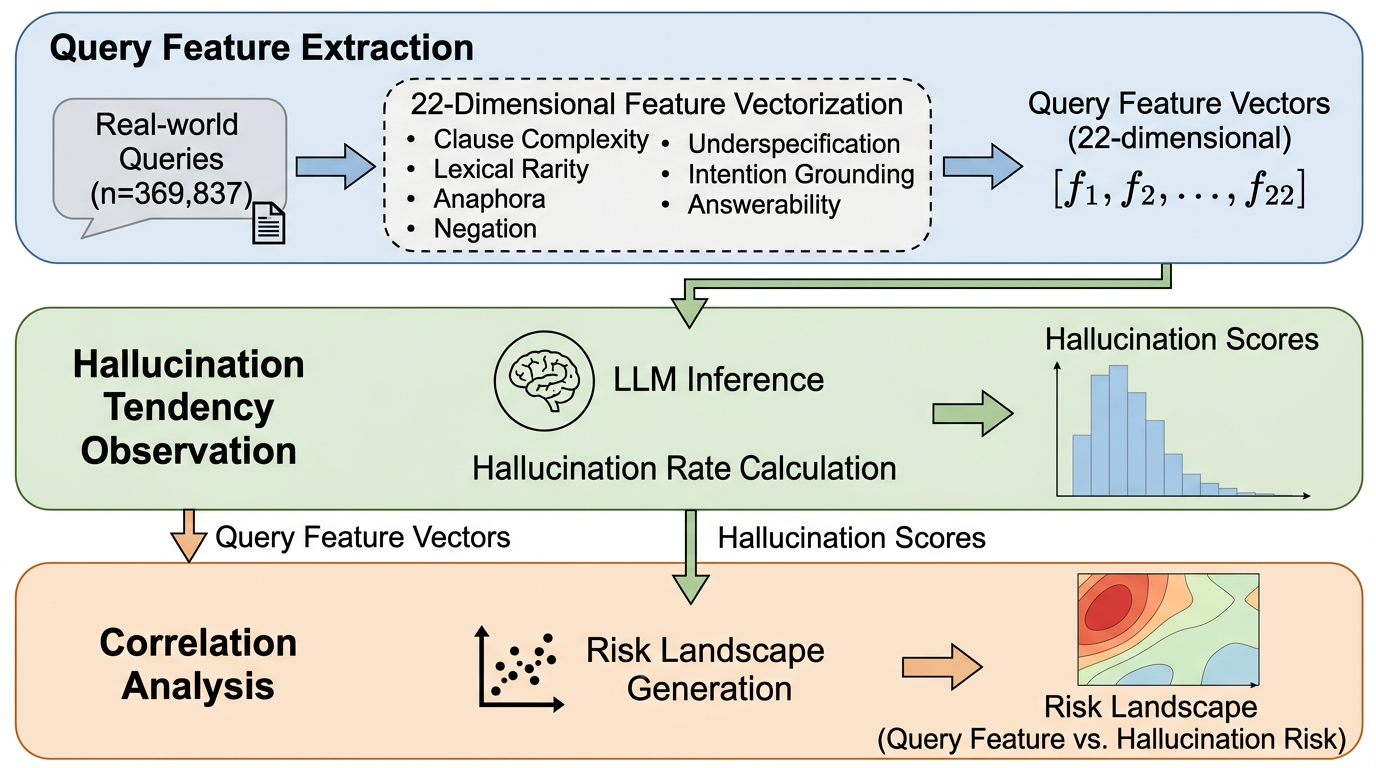
良いクエリとは何か:人間が混乱しやすい言語特徴がLLMの幻覚に与える影響を測る
LLMの幻覚リスクをクエリの言語特徴(22次元)として測り、どの問い方が高リスクかを大規模実データで示した研究です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
LLMの幻覚リスクをクエリの言語特徴(22次元)として測り、どの問い方が高リスクかを大規模実データで示した研究です。
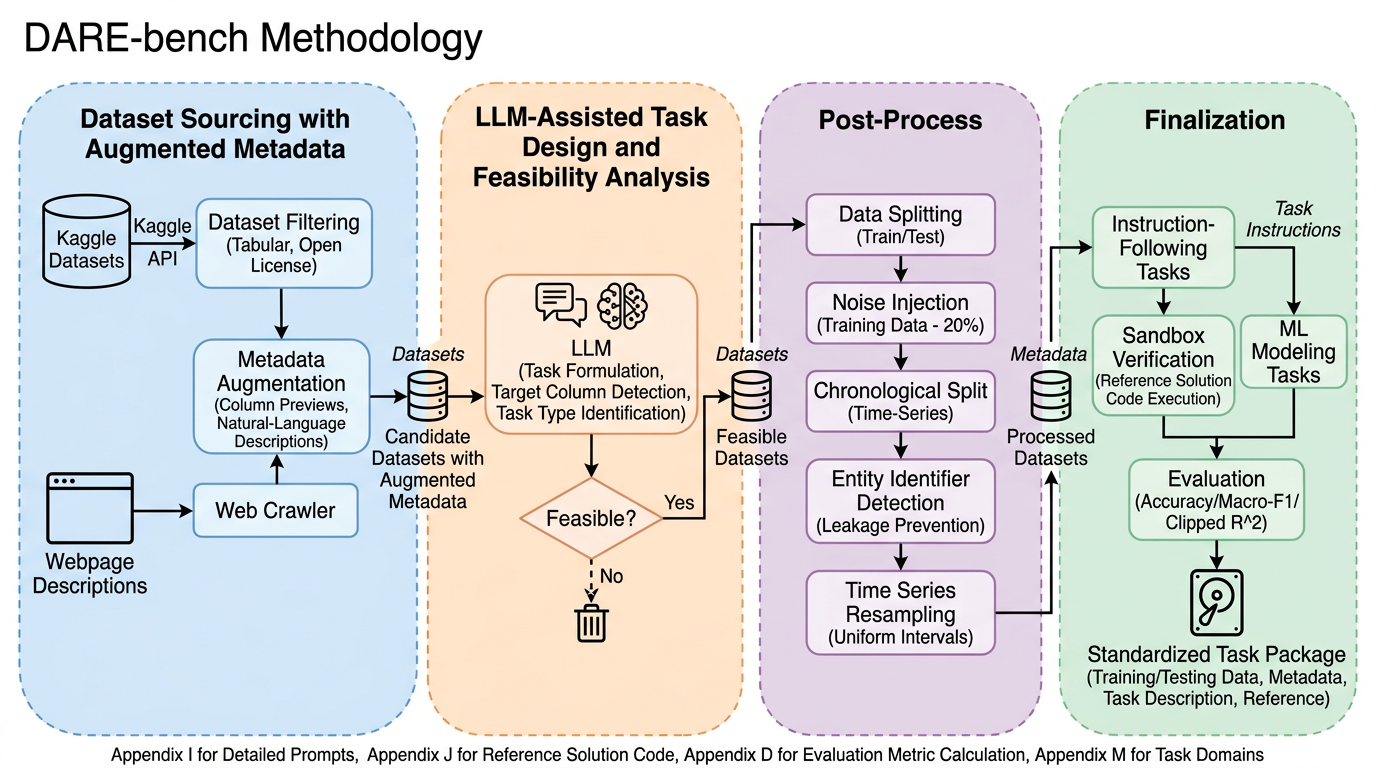
DARE-bench は、データサイエンスの複数ステップ作業に対して、最終スコアだけでなく process fidelity、つまり指示どおりの手順を守れたかまで検証できる 6,300 件規模のベンチマークです。 Kaggle 由来データを自動整形し、Instruction Following と ML Modeling の二系統を verifiable ground truth 付きで構成しているため、judge ベースでなく客観採点ができます。 強い汎用 LLM でも素のままでは大きく崩れ、Qwen3-4B の total score は 4.39 に留まりますが、DARE-bench 由来データで学習すると RL で 37.40 まで伸び、Qwen3-32B でも SFT により約 1.83 倍の改善が出ています。
SOTAlign は、少数の画像・テキスト対と大量の非ペアデータを使って、視覚と言語の表現空間をそろえる半教師あり手法です。線形教師で作った粗い共通幾何を KLOT により非ペア側へ移し、検索やゼロショット分類で既存手法を広く上回ります。
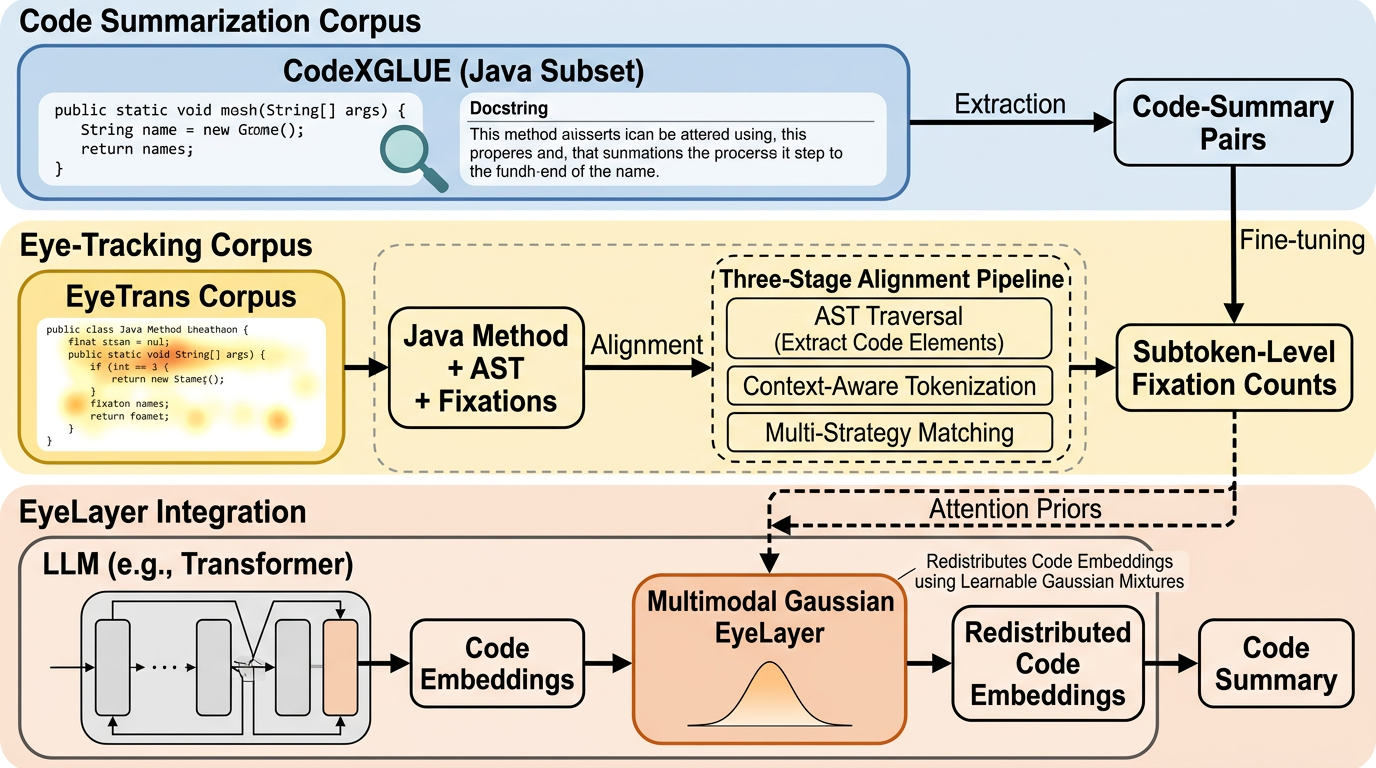
コード要約では高性能な大規模言語モデルでも、人が理解のために実際に注目する箇所とモデル側の焦点がずれる余地があり、そのずれを人の視線情報で埋められるかが未解決の問いとして扱われています。 / EyeLayerは、コード読解中の注視をマルチモーダルなガウス混合として注意の事前分布に落とし込み、学習した中心 μ と広がり σ² に基づいてトークン埋め込みを再配分することで、既存表現を乱さずにLLMへ統合できる軽量モジュールです。 / LLaMA-3.2、Qwen3、CodeBERTに対してCodeXGLUE(Java)で評価したところ、同一データで学習した強い教師あり微調整ベースラインを標準指標で一貫して上回り、BLEU-4で最大13.17%の改善が示され、視線が補完的な注意信号としてモデル間で移植可能に働く含意が示されています。
SteuerEx は、実際のドイツ大学税法試験から構築された公開ベンチマークです。これに特化した 28B の SteuerLLM は、72B 級の汎用 instruction-tuned モデルや GPT-4o-mini を上回り、税法ではサイズより専門特化が効くことを示しました。
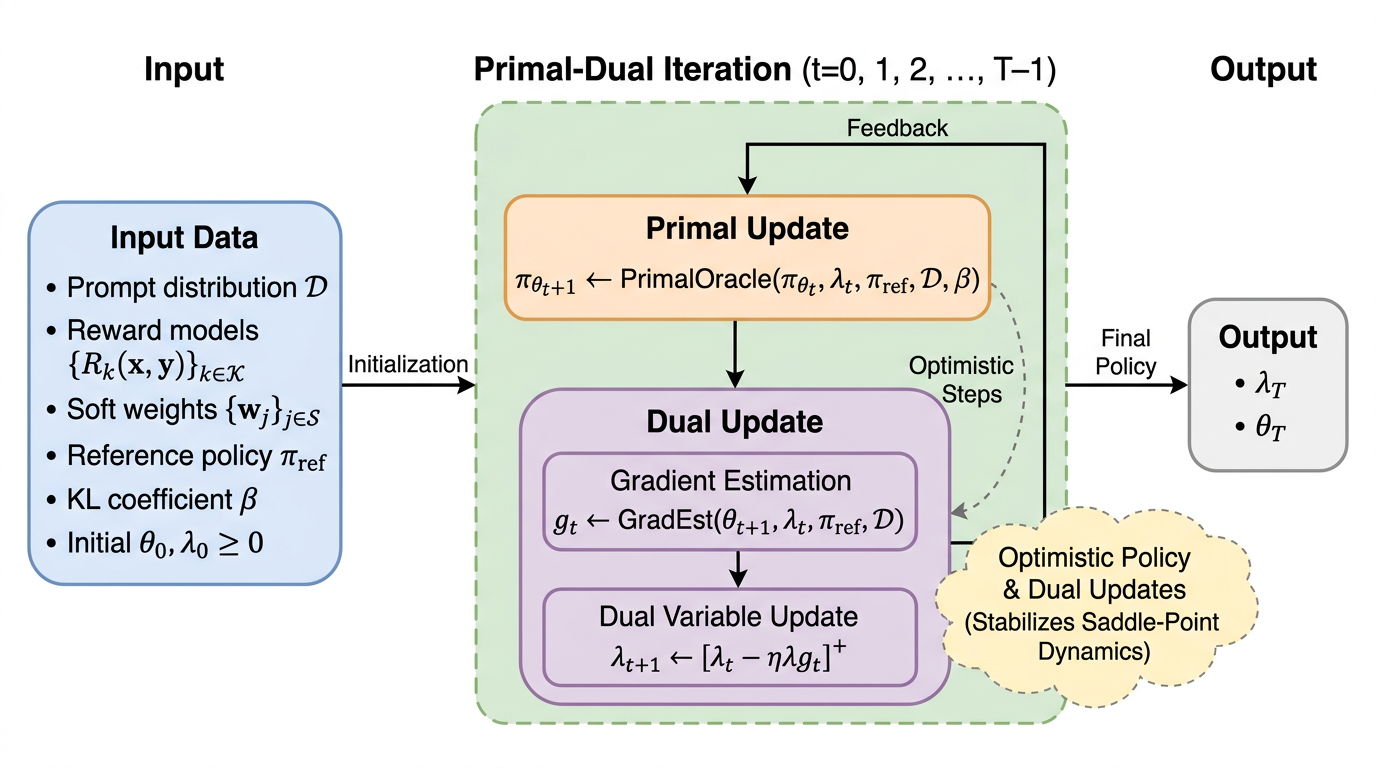
期待報酬の制約を伴う多目的セーフRLHFは方策と非負の双対変数の鞍点問題として書けますが、標準的な同時プライマル・デュアル更新は最終反復が振動して不安定になりやすく、学習の最後の方策をそのまま配備する運用と噛み合いにくいです。
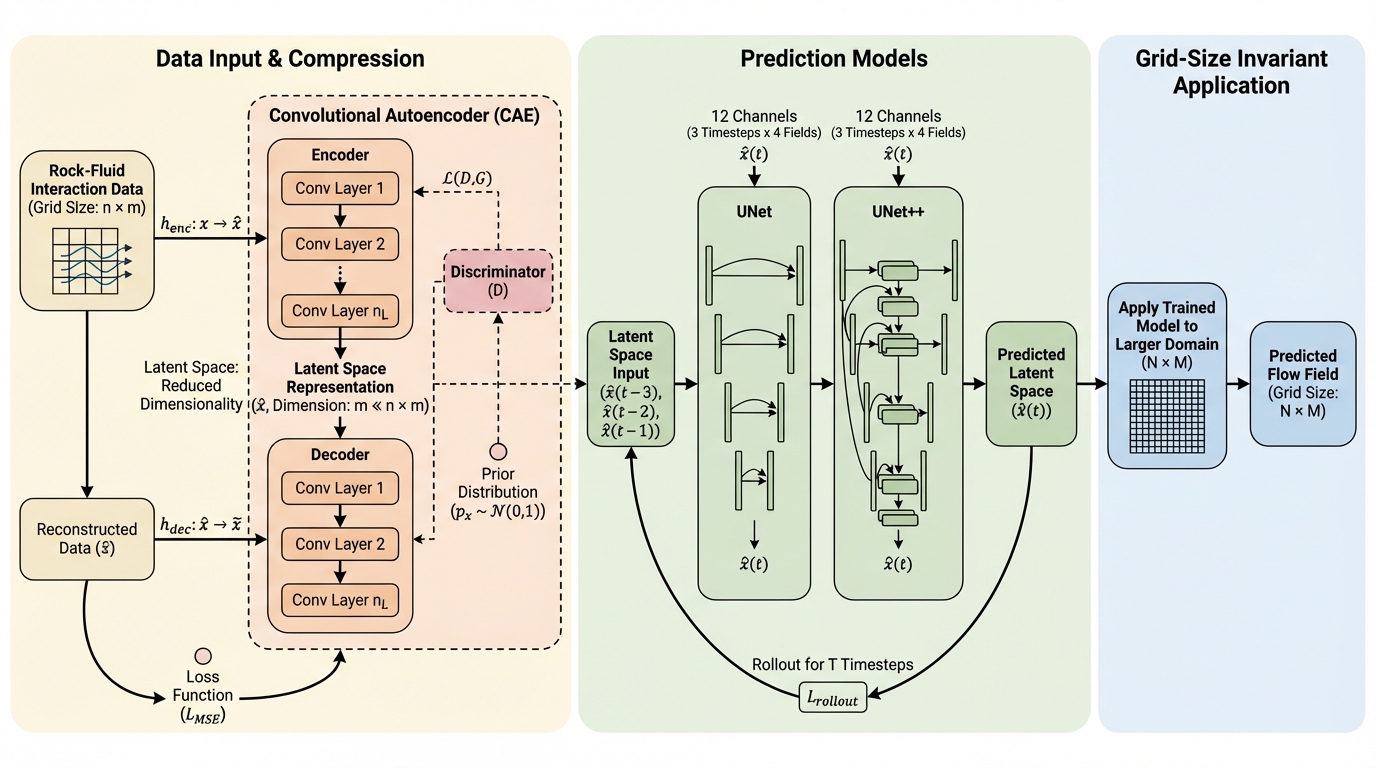
岩石―流体相互作用を含む多孔質媒体の流動予測は高解像度の数値計算ほど計算負荷が重くなりやすいため、学習ベースのサロゲートで「多数の条件を何度も回す」用途に適した代替手段を整理して示しています。 / 圧縮と予測を分ける縮約モデルと、学習時より大きい計算領域にも推論できるグリッドサイズ不変の単一ネットワークという二系統で計8モデルを構築し、UNetとUNet++、敵対的学習、rollout training、境界条件の罰則化などの設計差を比較しています。 / UNet++がUNetよりサロゲートとして良い予測性能を示し、学習メモリを抑えやすいグリッドサイズ不変アプローチが予測と真値の相関の良さにつながり、検討した縮約モデルより良い結果を示したと報告されています。
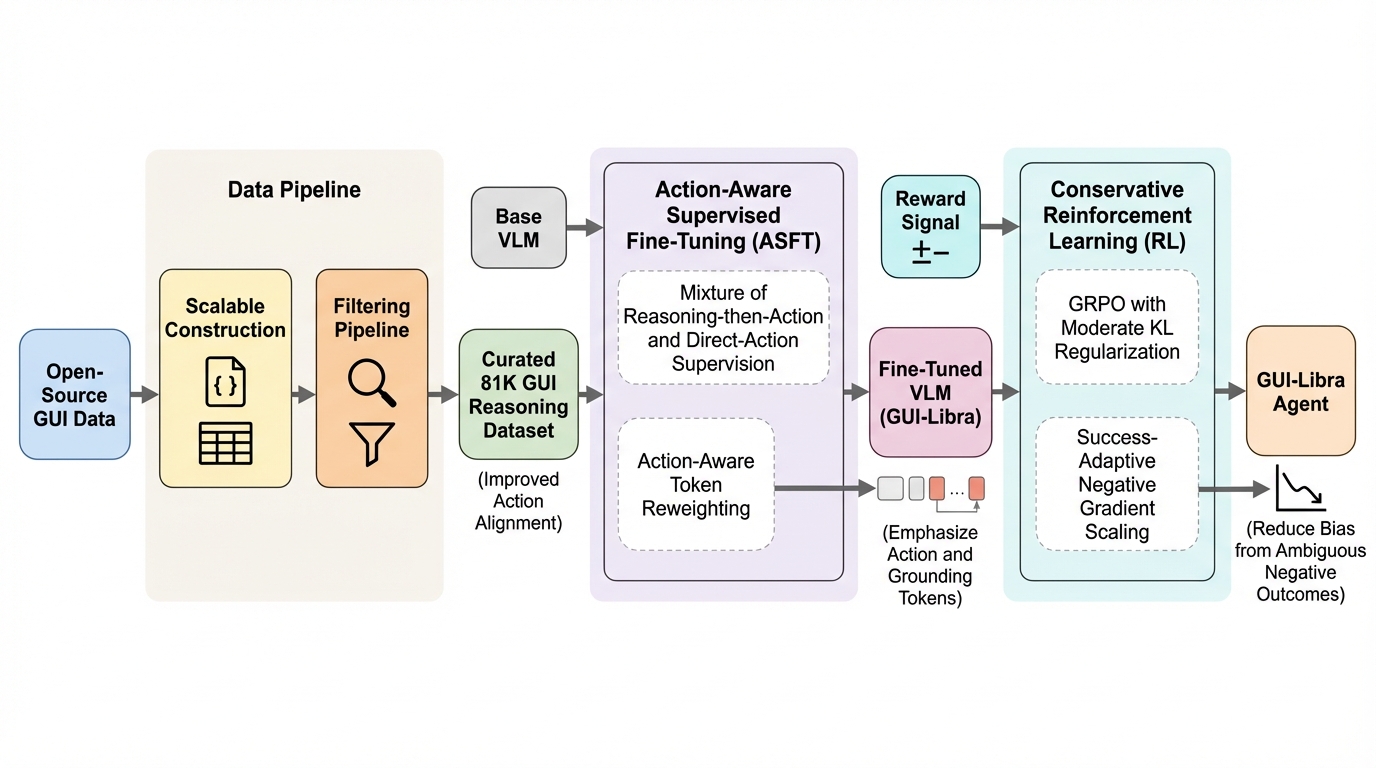
オープンソースのネイティブGUIエージェントが長い手順のナビゲーションで伸びにくい背景として、行動に整合した高品質な推論データの不足と、GUI特有の難しさを十分に織り込まない事後学習手順の流用があり、GUI-Libraはこの両方を同時にほどく設計になっています。
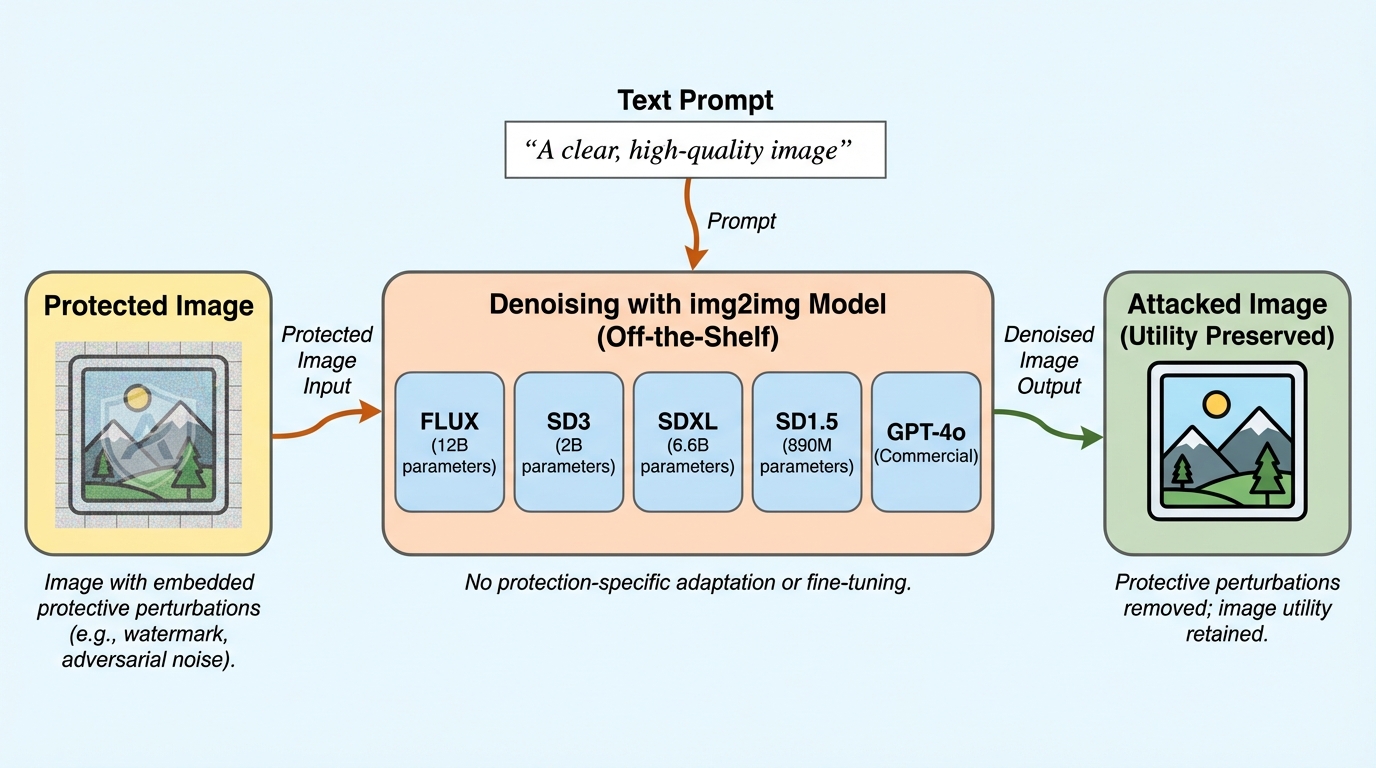
画像に知覚しにくい保護用の摂動を加えて無断利用を防ぐ方式は、既製の画像から画像への生成モデルをそのまま「汎用のノイズ除去器」として使う攻撃で、幅広く除去され得ることが示されています。 / 保護済み画像を入力し、ノイズを取り除く趣旨の簡単なテキスト指示で画像変換を行うだけで、方式の内部を知らず追加学習もしないまま、保護摂動がノイズとして処理されてしまう状況が複数の事例で確認されています。 / 6種類の保護方式にまたがる8つのケーススタディで回避が示され、方式特化の除去攻撃より良い結果も報告されているため、現行の保護が「安全だと思い込ませる」危険があり、今後の防御は既製モデル攻撃を前提に評価すべきだと述べられています。
多言語の大規模言語モデルを公平に評価するには、翻訳済みベンチマークの品質ばらつきによる意味のずれや文脈欠落を減らし、指標が誤解を招かない状態に整える必要があります。 / データセット向けとベンチマーク向けを切り分けた完全自動の翻訳フレームワークを用い、テスト時の計算量スケーリング戦略としてUSIと多ラウンド順位付けのT-RANK、さらにSCやBest-of-Nも選べる形で翻訳工程を構成します。 / 東欧・南欧の8言語に人気ベンチマーク/データセットを翻訳して参照ベース指標とLLM-as-a-judgeで検証したところ、既存資源を上回る翻訳が得られ、下流のモデル評価をより正確にし得ることと、枠組みと改善版ベンチマークを公開する点が示されています。