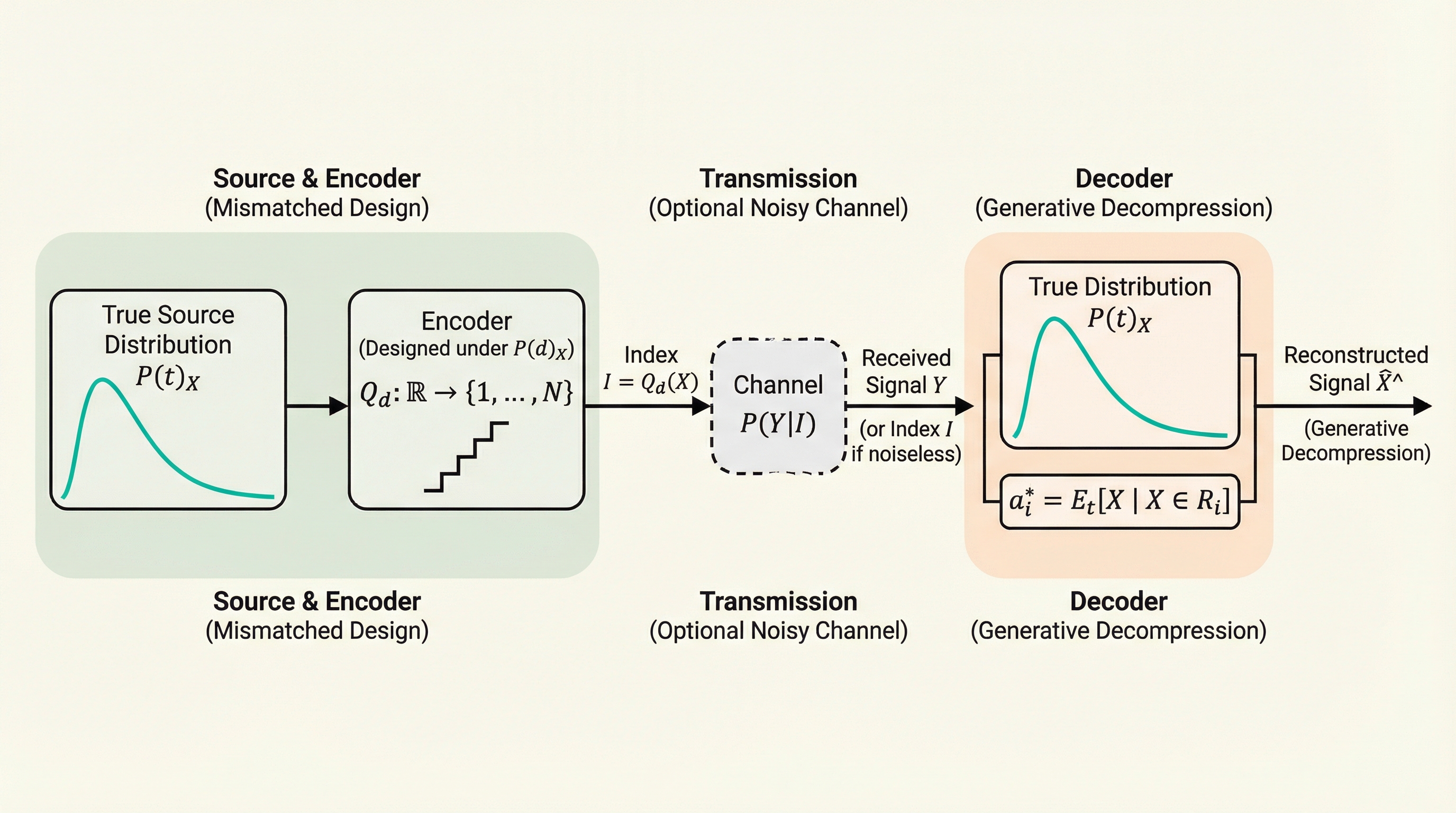
生成デコンプレッション:分布の不一致に対する最適な非可逆復号化
本論文は、圧縮機の設計時に想定したデータ分布と実際のソース分布が異なる「分布の不一致」が発生する状況において、送信側のエンコーダを一切変更することなく、受信機側のみの調整で歪みを最小化する「生成デコンプレッション」を提案している。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本論文は、圧縮機の設計時に想定したデータ分布と実際のソース分布が異なる「分布の不一致」が発生する状況において、送信側のエンコーダを一切変更することなく、受信機側のみの調整で歪みを最小化する「生成デコンプレッション」を提案している。
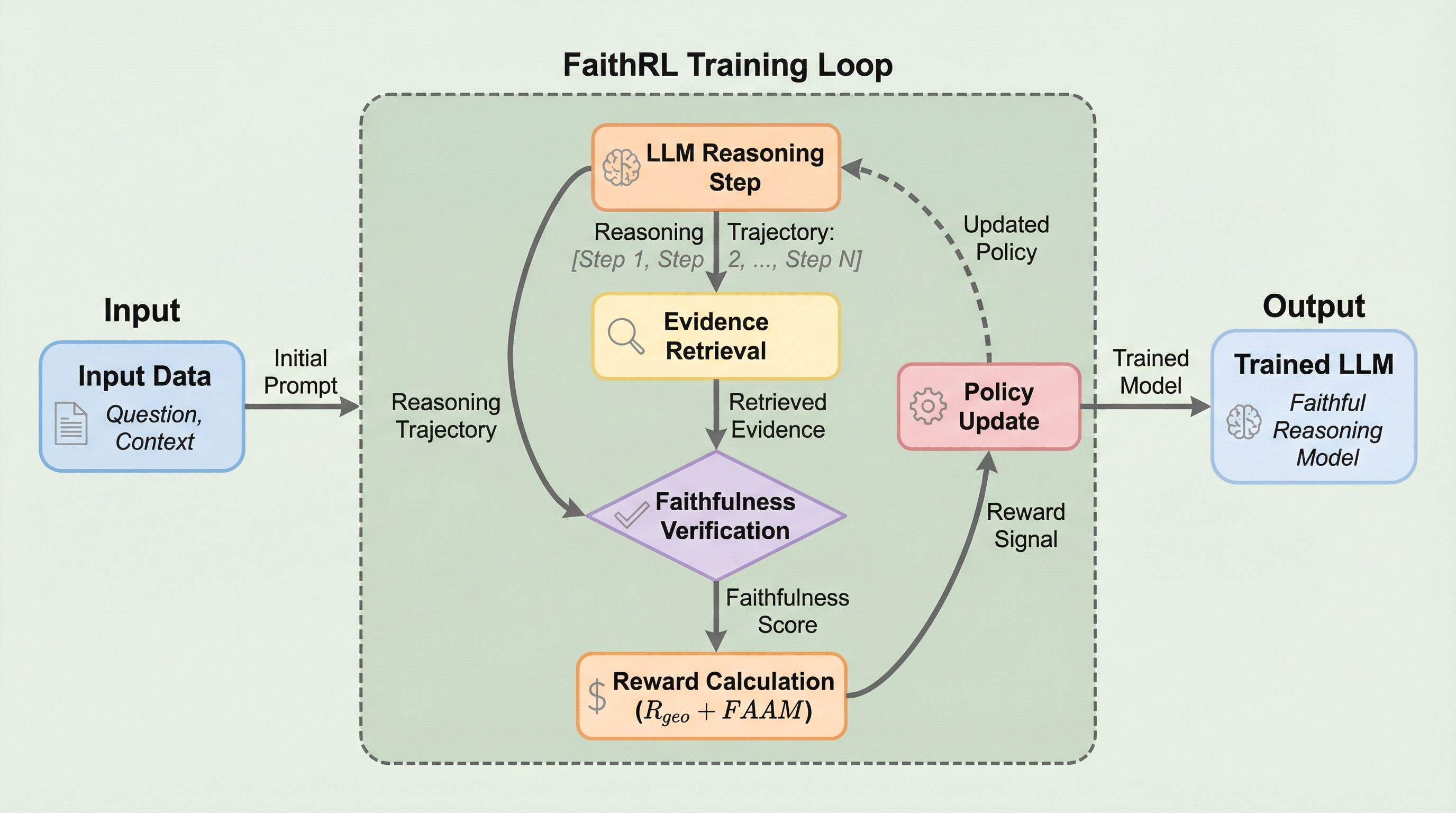
大規模言語モデルの多段階推論において、従来の最終回答のみを評価する強化学習は、論理を無視して正解を推測する過度な自信やハルシネーションを助長する課題がありましたが、本研究は推論の各ステップが証拠に基づいているかを直接評価する新しい強化学習フレームワーク「FaithRL」を提案しました。
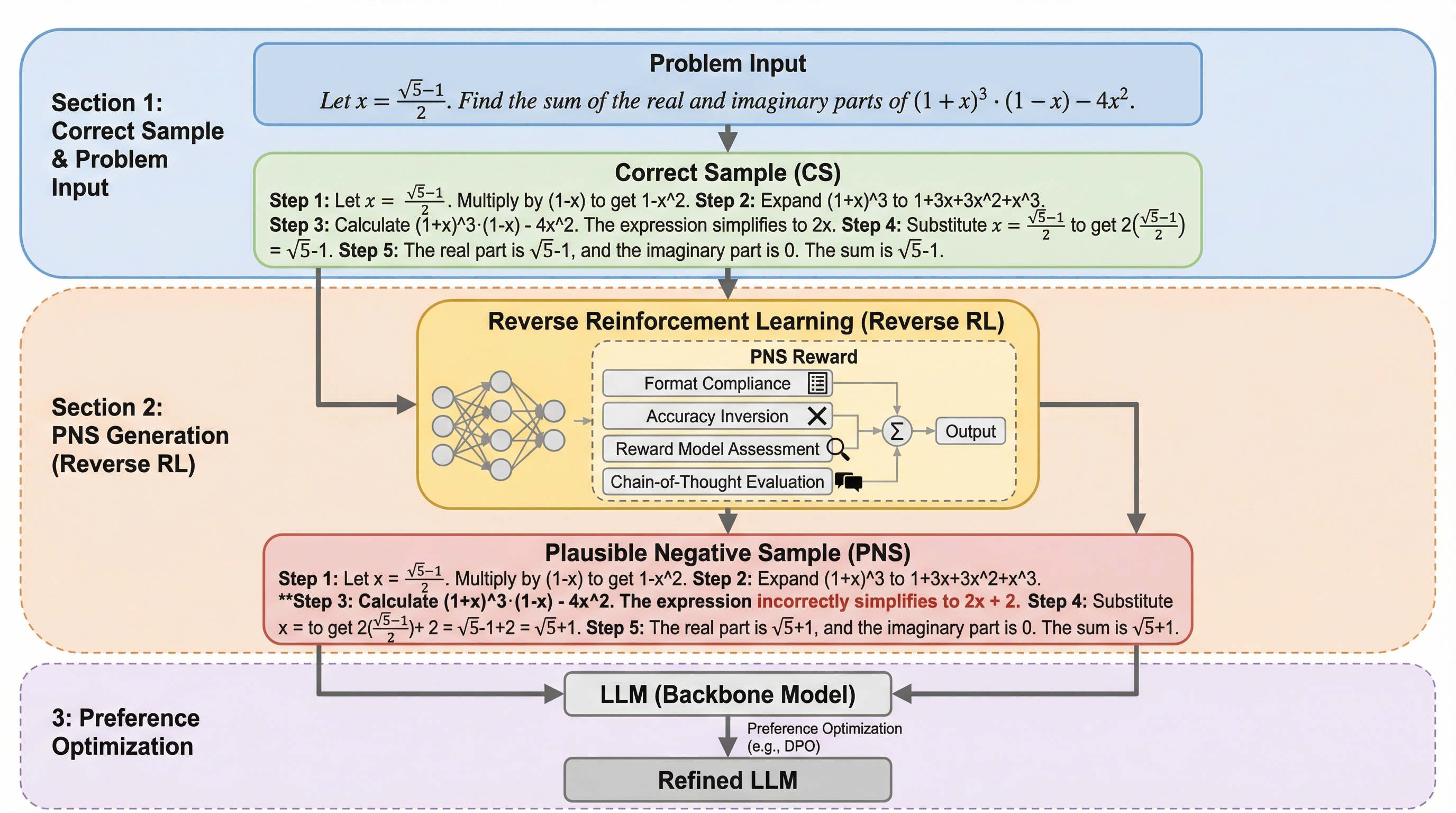
大規模言語モデル(LLM)の推論能力を向上させるためには、単なる誤答ではなく、論理構成は一貫しているが結論だけが誤っている「もっともらしい負例(PNS)」が極めて重要な学習信号になることを解明した。
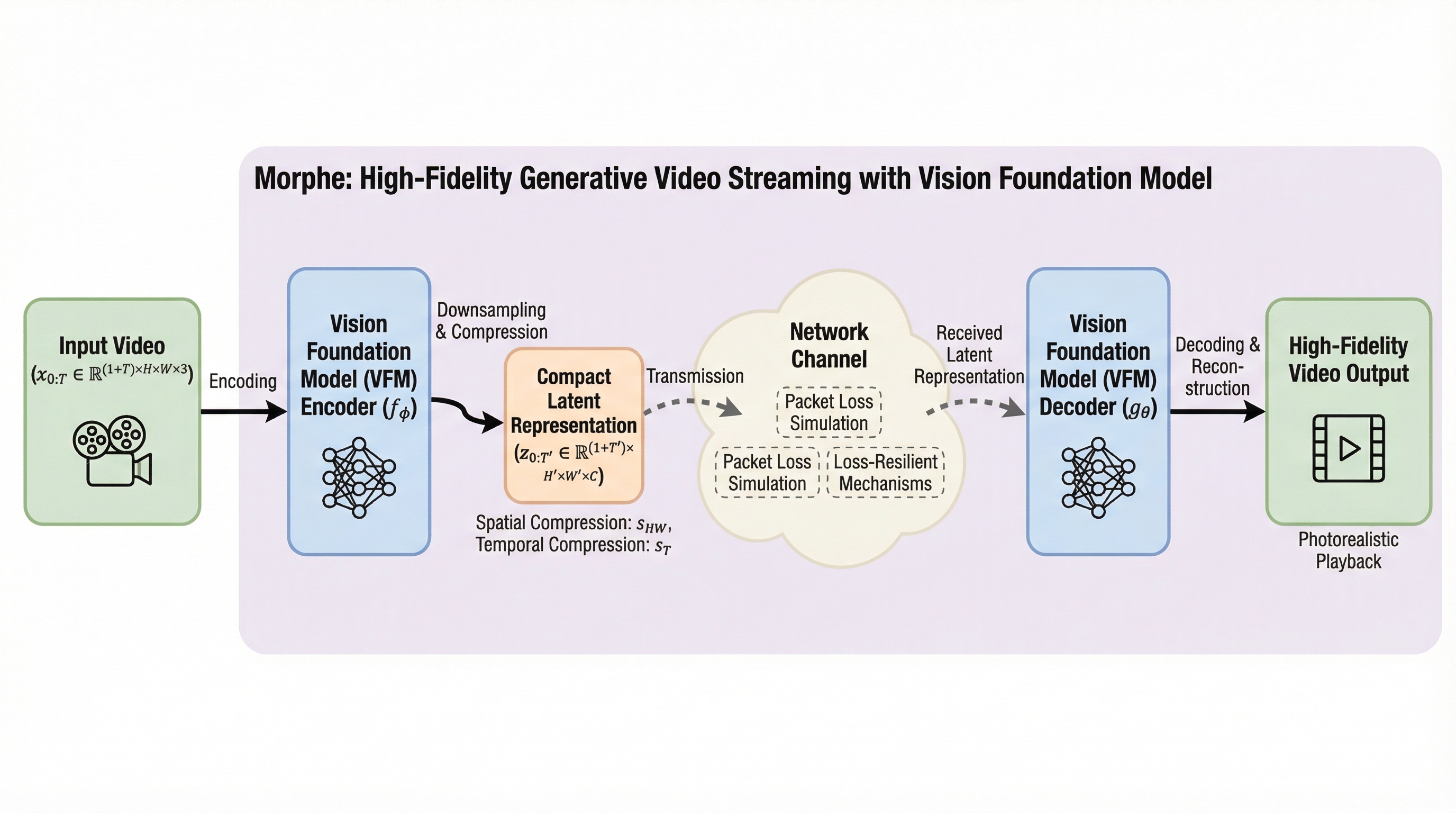
現在のインターネットトラフィックの65%以上を占めるビデオストリーミングは、高速鉄道や遠隔地などの不安定なネットワーク環境において、従来のH.264やH.265といったピクセルベースのコーデックでは帯域不足による品質劣化や再生の中断を避けられないという深刻な課題に直面しています。
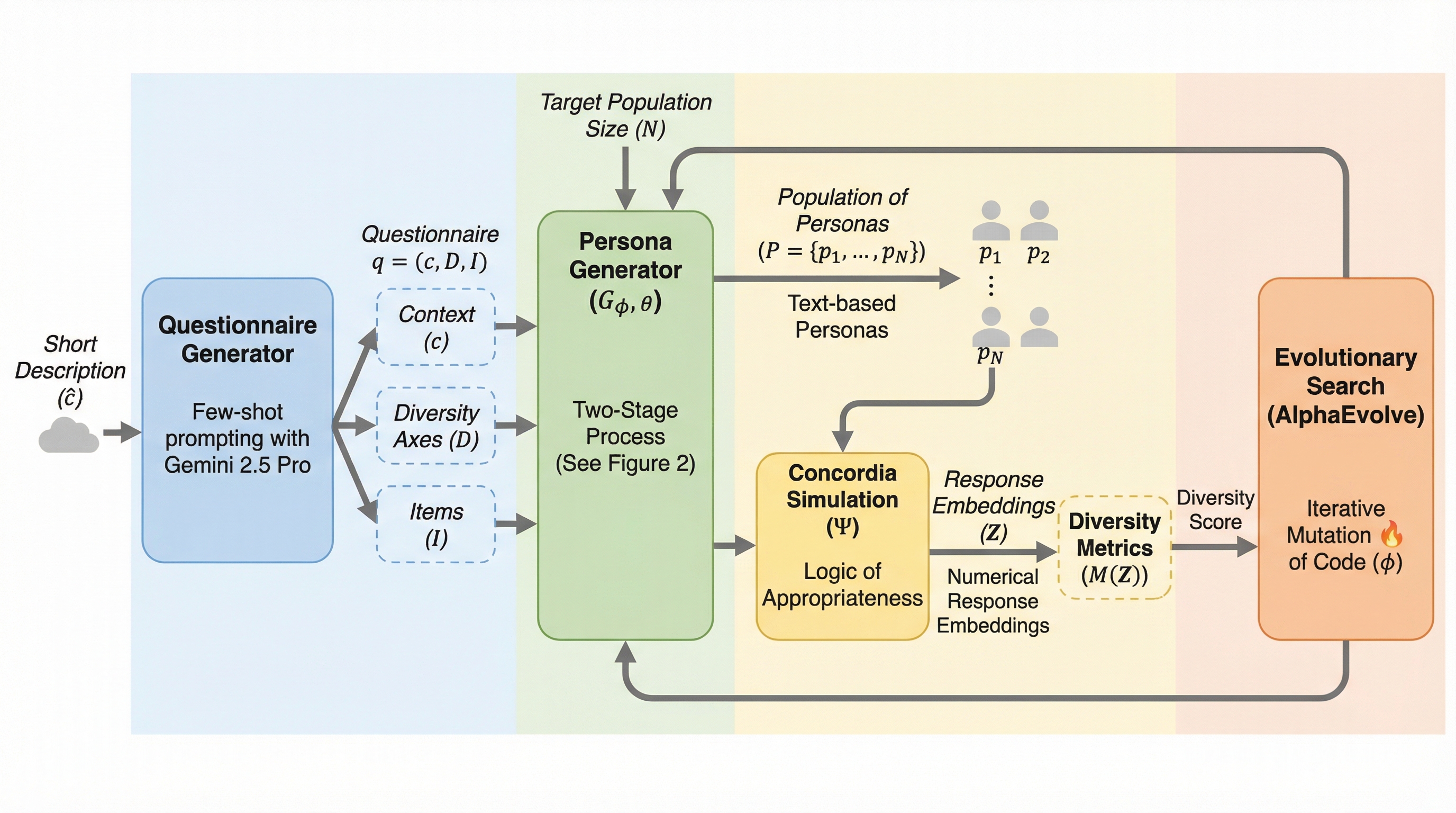
AIシステムの安全性や信頼性を評価するためには多様なユーザー行動の再現が不可欠だが、従来の生成手法は平均的な分布の再現に偏り、稀な特性を持つ「ロングテール」の挙動を見落とす課題があった。 本研究はAlphaEvolveを用いたコード最適化により、任意の文脈で多様な合成ペルソナをオンデマンド生成する「ペルソナ・ジェネレーター」を開発し、可能性の全範囲を網羅する「カバレッジ」の最大化を実現した。 検証の結果、進化したジェネレーターは未知のテストセットで80%以上のカバレッジを達成し、標準的な言語モデルの出力では困難だった極端な意見や複雑な性格の組み合わせを効率的に生成することに成功した。
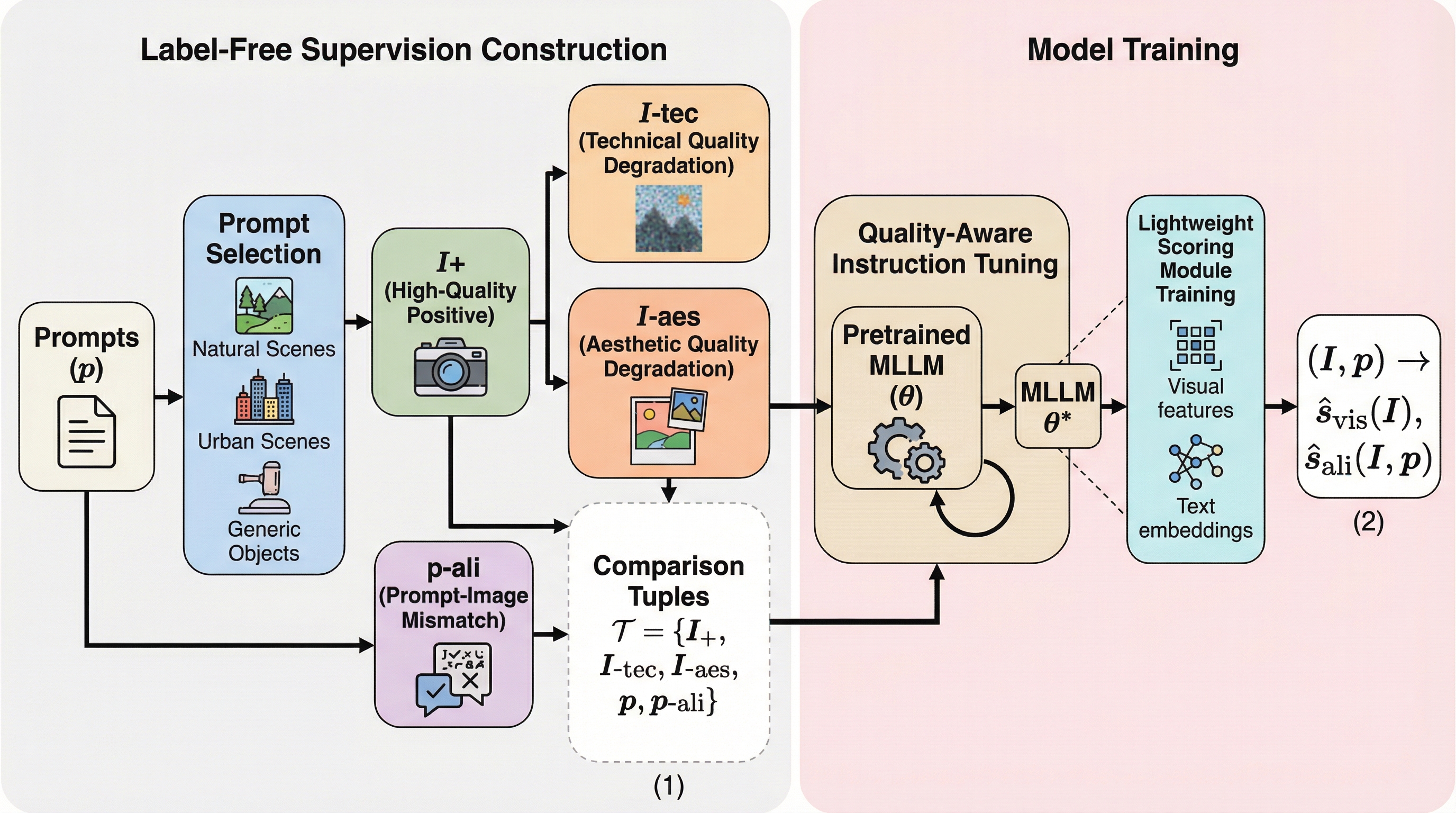
画像生成AIの急速な進化は、従来の人間による評価スコア(MOS)を「知覚的ドリフト」によって急速に陳腐化させ、再評価に膨大なコストを強いるという課題を生んでいる。本研究が提案するELIQは、人間の注釈を一切介さず、最新の生成モデルを用いた高品質な正例と、意図的に劣化させた負例のペアを自動構築することで、視覚的品質とプロンプト整合性の両面からAI生成画像を評価する革新的なラベルフリー・フレームワークである。 命令チューニングを施したマルチモーダル言語モデル(MLLM)を「品質に敏感な批評家」として適応させ、さらに軽量なQuality Query Transformer(QQT)とゲート付き融合メカニズムを組み合わせることで、単一画像からの高精度な品質予測を実現している。 複数のベンチマークにおける検証の結果、ELIQは既存のラベルフリー手法を大幅に凌駕し、教師あり学習モデルに迫る性能を示した。さらに、AI生成画像(AIGC)だけでなくユーザー生成コンテンツ(UGC)にもそのまま適用可能な高い汎用性を持ち、生成モデルの進化に合わせて評価基準を動的に更新できるスケーラブルな評価基盤としての有効性が証明されている。
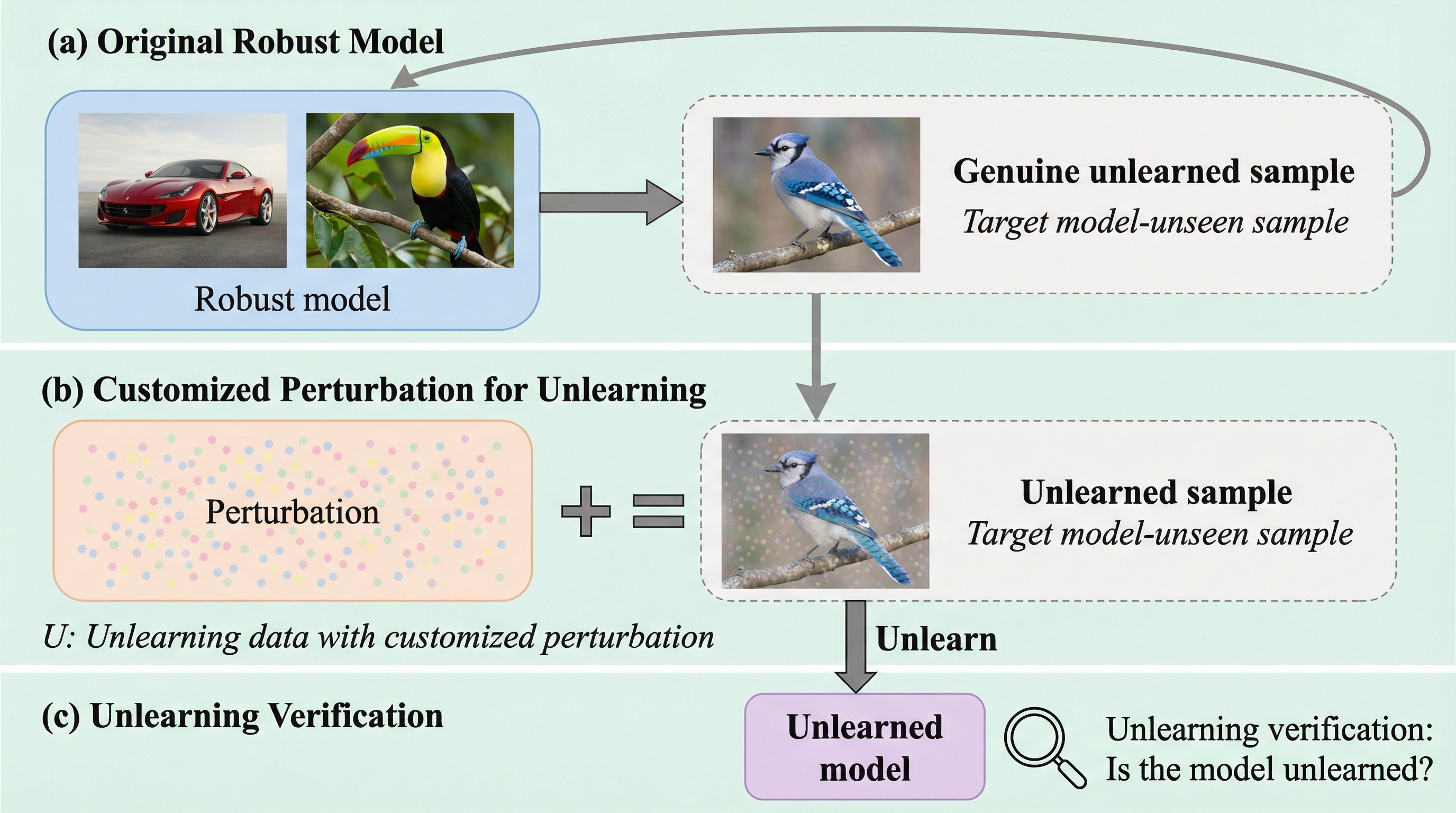
1. 機械学習モデルから特定のデータを削除する「アンラーニング」が正しく実行されたかを検証するため、モデルの初期学習フェーズへの関与を一切必要とせず、アンラーニングの実行段階のみで効率的に動作する新しい検証手法「EVE」を提案する。 2.
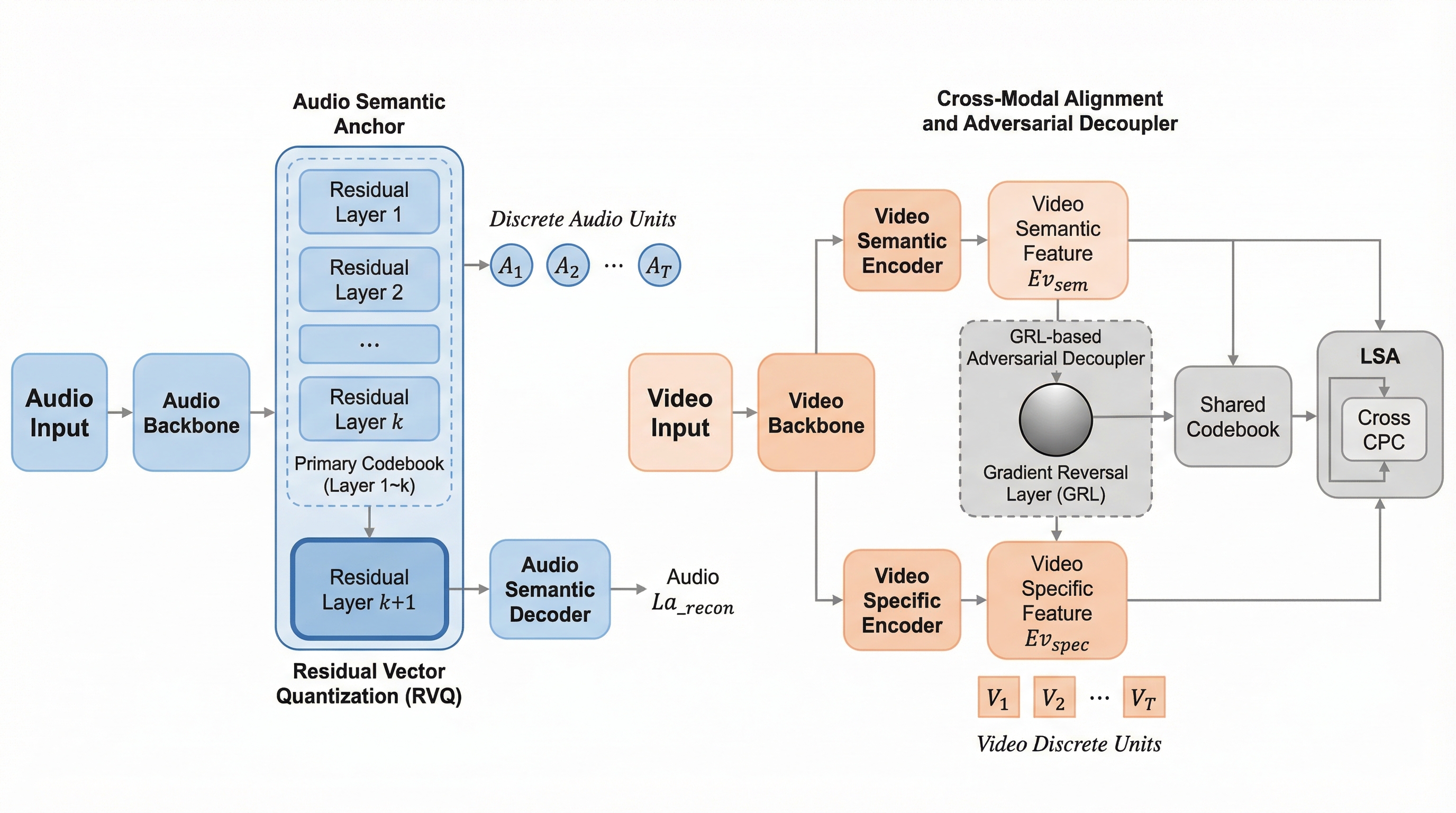
従来の音声と視覚の共同表現学習におけるクロスモーダル汎化では、対称的な構造が情報の割り当てに曖昧さを生じさせ、意味情報が特定のモダリティ固有のブランチに漏洩することで、ラベルのないターゲットモダリティへの知識転送が阻害されるという深刻な課題がありました。
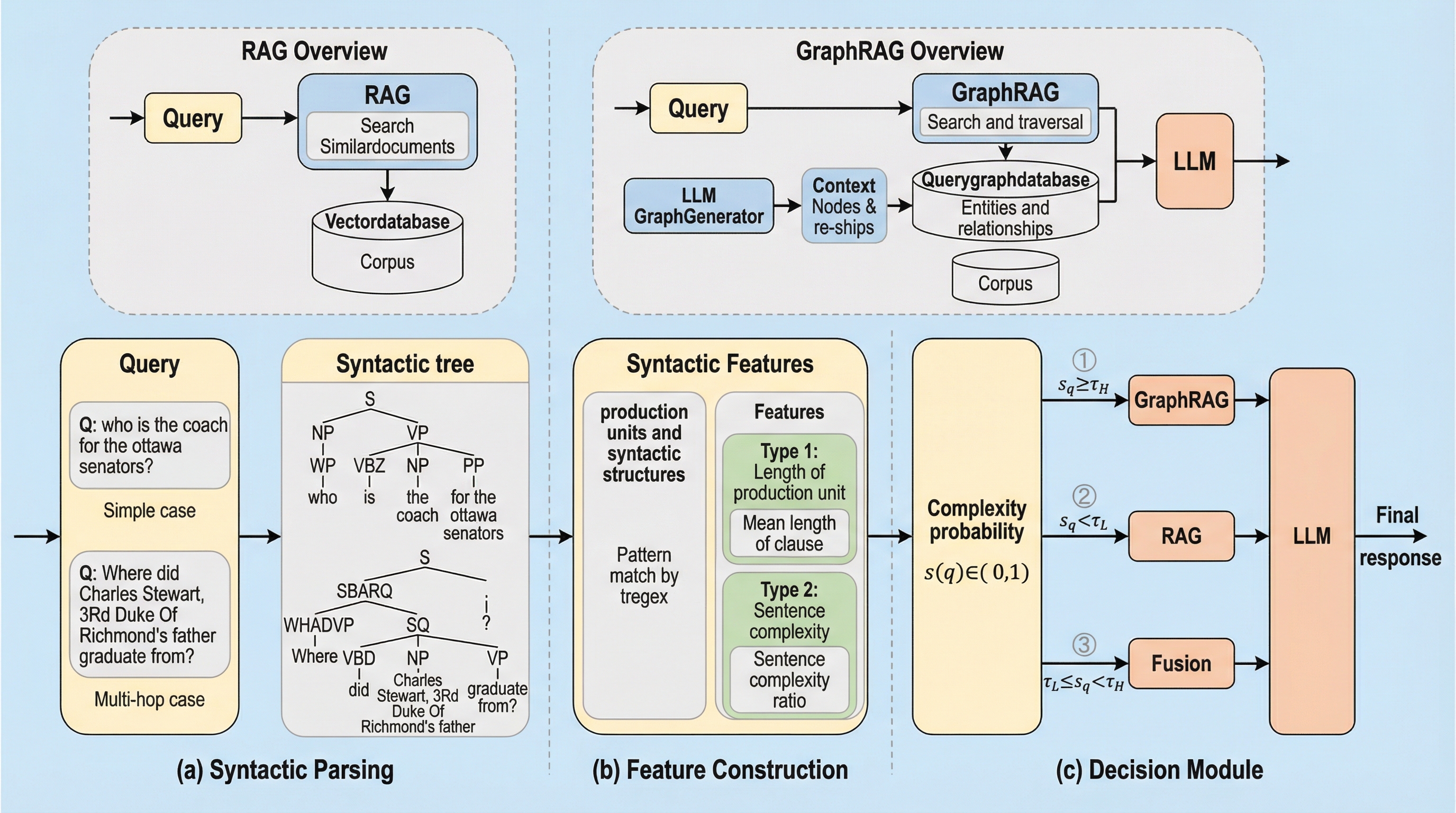
大規模言語モデルのハルシネーションや知識の風化を防ぐため、クエリの構文的な複雑さを解析して、従来のRAG(検索拡張生成)と構造的な知識グラフを用いるGraphRAGを動的に切り替える新フレームワーク「EA-GraphRAG」が提案されました。
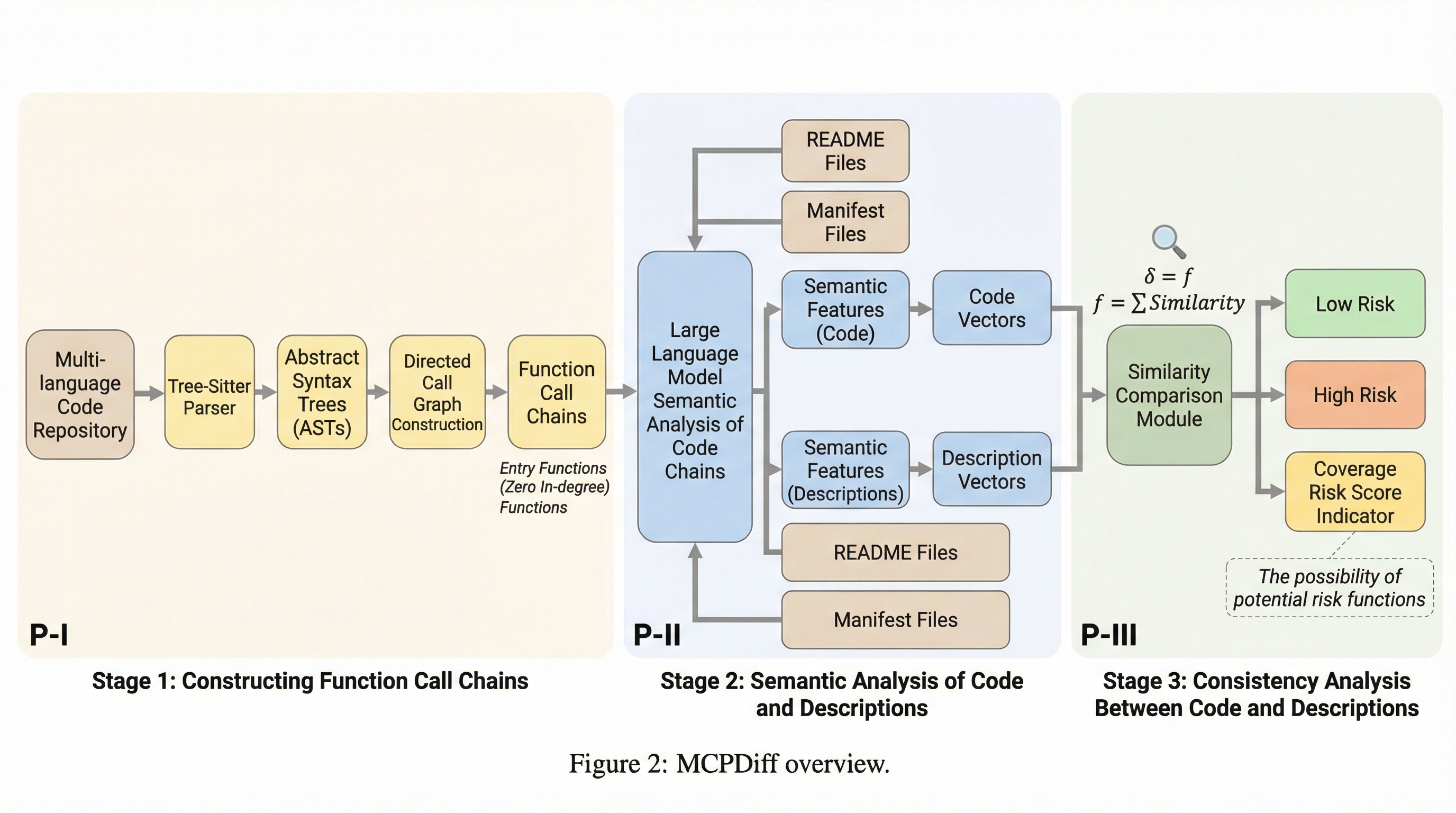
Model Context Protocol(MCP)は、大規模言語モデル(LLM)が自然言語の説明を通じて外部ツールを呼び出すための標準規格ですが、ツールの説明文と実際の実行コードの整合性を強制する仕組みが欠如しています。