音響・視覚共同表現のための非対称な階層的アンカリング:堅牢なクロスモーダル汎化に向けた情報割り当ての曖昧さの解消
従来の音声と視覚の共同表現学習におけるクロスモーダル汎化では、対称的な構造が情報の割り当てに曖昧さを生じさせ、意味情報が特定のモダリティ固有のブランチに漏洩することで、ラベルのないターゲットモダリティへの知識転送が阻害されるという深刻な課題がありました。
TL;DR(結論)
従来の音声と視覚の共同表現学習におけるクロスモーダル汎化では、対称的な構造が情報の割り当てに曖昧さを生じさせ、意味情報が特定のモダリティ固有のブランチに漏洩することで、ラベルのないターゲットモダリティへの知識転送が阻害されるという深刻な課題がありました。 本研究では、音声の残留ベクトル量子化(RVQ)が持つ階層構造を意味的なアンカーとして利用し、視覚特徴の蒸留を構造的に方向付ける「非対称階層的アンカリング(AHA)」を提案し、さらに勾配反転レイヤー(GRL)を用いた敵対的デカプラーと局所スライディングアライメント(LSA)を導入しました。 AVEやAVVPなどの主要なベンチマークを用いた実験の結果、提案手法は従来の対称的なベースラインを全ての転送設定で安定して上回り、特にきめ細かな時間的整合性が求められるタスクで顕著な改善を示し、意味の一貫性と情報の分離において極めて優れた性能を実証することに成功しました。
なぜこの問題か
マルチモーダル学習は、人間が視覚と聴覚を統合して世界を理解する知覚プロセスを模倣することを目指しており、視覚的な質問応答や音声・視覚イベントのローカリゼーションといった高度なタスクで大きな進歩を遂げてきました。しかし、音声と視覚という本質的に異なるモダリティ間には「モダリティ・ギャップ」と呼ばれる隔たりが存在し、潜在空間においてそれぞれの特徴が分離してしまうという根本的な問題が解決されていません。これを解決するために、共有された離散的な表現空間を通じて、ラベルのあるソースモダリティからラベルのないターゲットモダリティへ知識を転送するクロスモーダル汎化(CMG)という枠組みが注目されています。 従来の対称的なフレームワークでは、構造的な誘導バイアスが不足しているため、どの情報が共有されるべき意味情報で、どの情報が特定のモダリティに固有の情報であるかという「情報割り当ての曖昧さ」が生じていました。この曖昧さにより、本来は共有空間に留まるべき意味情報が、制約の少ないモダリティ専用のブランチへと漏洩してしまい、結果として共有空間における意味コードブックの崩壊や、情報の絡まり合いが発生します。…
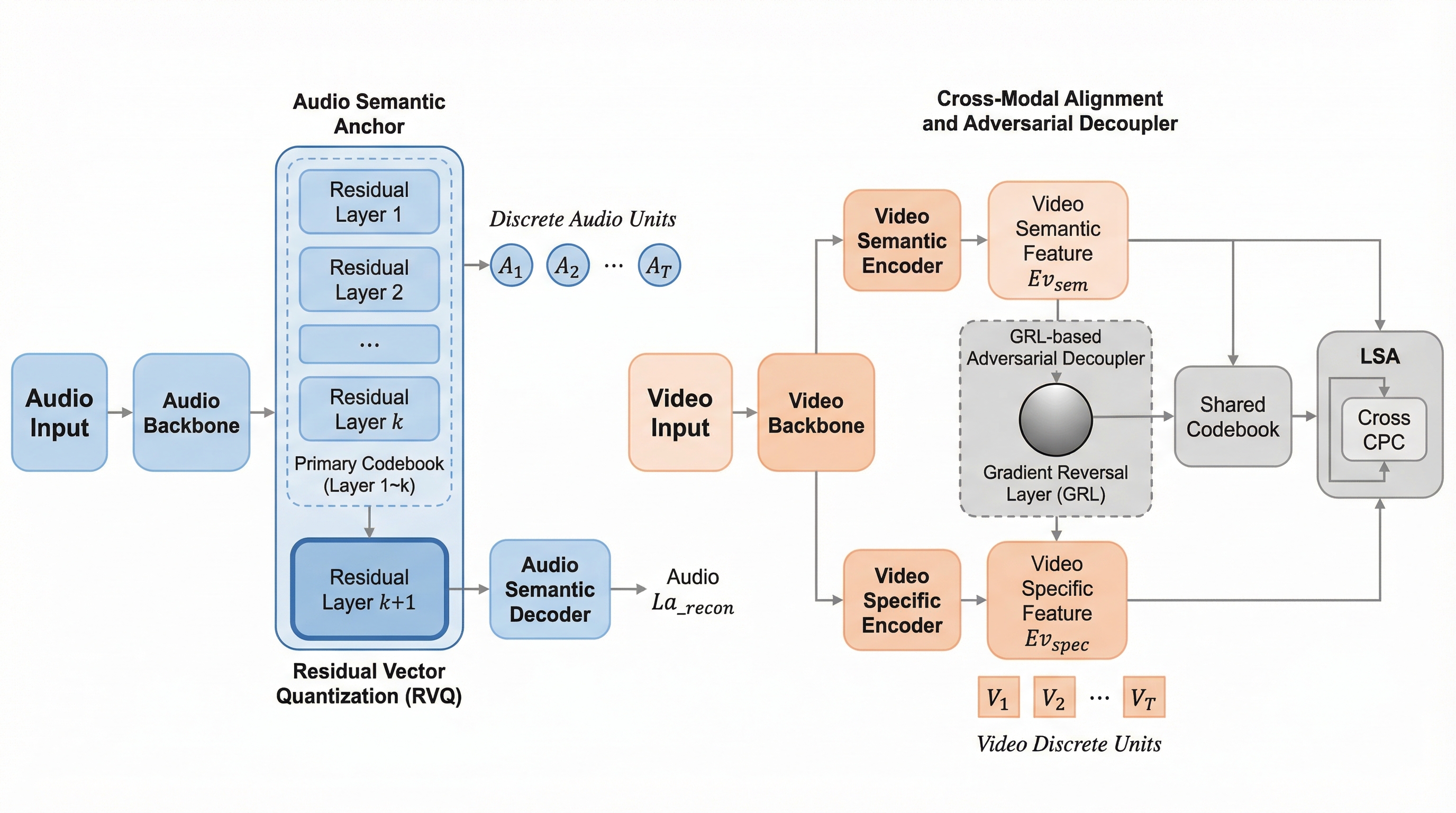
核心:何を提案したのか
本研究では、情報の割り当てに関するジレンマを根本から解決するために、「非対称階層的アンカリング(AHA)」という革新的なアーキテクチャを提案しました。この手法の核心は、音声モダリティを意味的なアンカーとして明示的に指定し、方向性を持った情報の割り当てを強制することにあります。音声は、背景ノイズの多い視覚情報と比較して、高レベルの意味論に対してコンパクトで頑健な手がかりを提供することが多いため、アンカーとして非常に適しているという洞察に基づいています。 具体的には、音声信号処理の分野で広く採用されている残留ベクトル量子化(RVQ)の階層構造を巧みに利用しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related