すべての負例が等しいわけではない:LLMはもっともらしい推論からより良く学習する
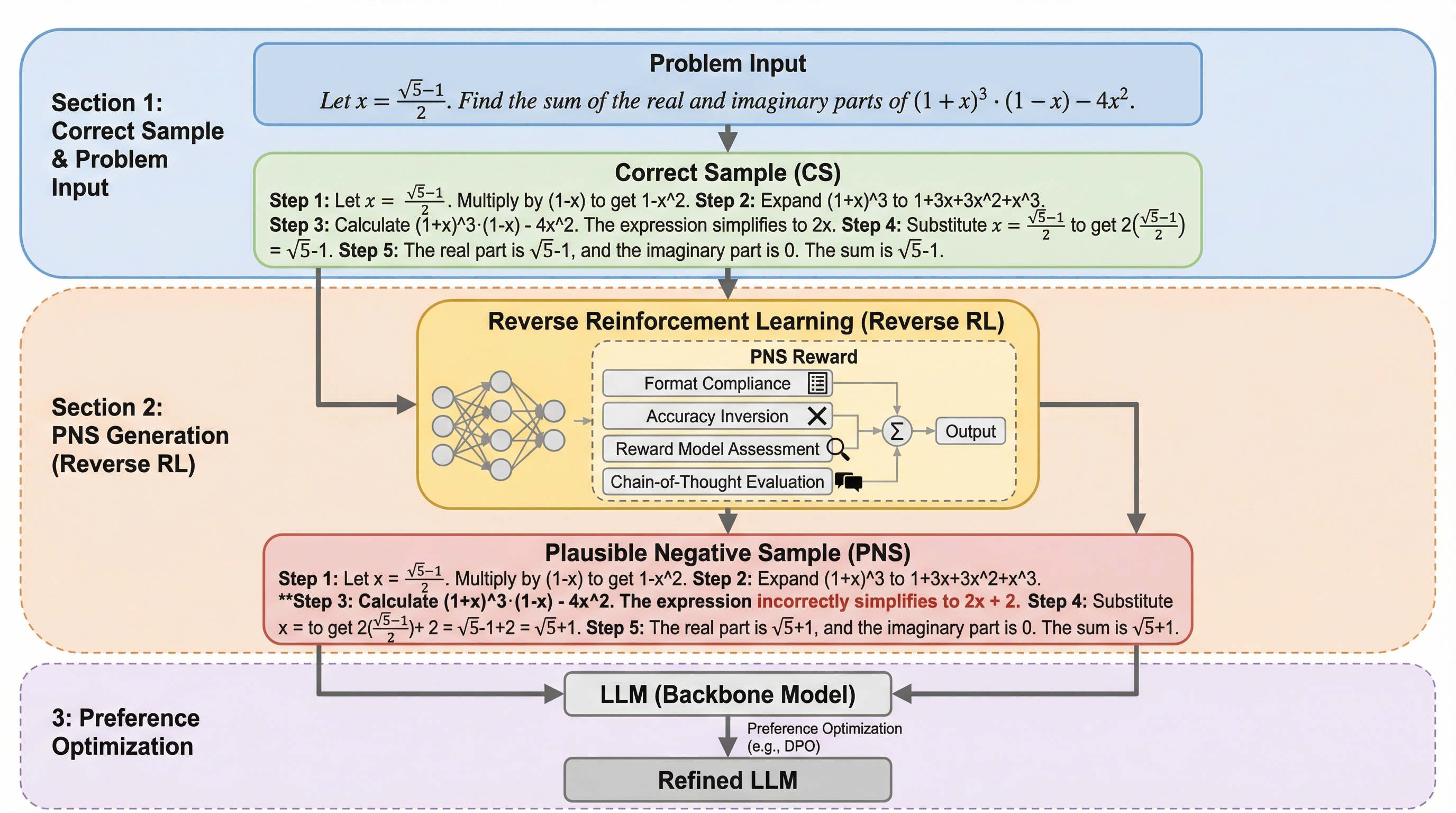
大規模言語モデル(LLM)の推論能力を向上させるためには、単なる誤答ではなく、論理構成は一貫しているが結論だけが誤っている「もっともらしい負例(PNS)」が極めて重要な学習信号になることを解明した。
TL;DR(結論)
大規模言語モデル(LLM)の推論能力を向上させるためには、単なる誤答ではなく、論理構成は一貫しているが結論だけが誤っている「もっともらしい負例(PNS)」が極めて重要な学習信号になることを解明した。逆強化学習(Reverse RL)の一種である「Reverse GRPO」を用い、形式の整合性、正解の反転、報酬モデルによる評価、思考の連鎖の質を組み合わせた複合報酬により、正解と見分けがつかないほど高品質な誤答プロセスを自動生成する手法を開発した。Qwen2.5やLlama3.1を用いた検証の結果、提案手法は数学的推論ベンチマークにおいて既存の強化学習モデルを平均2.03%上回り、特に難易度の高い競技数学レベルの問題で顕著な性能向上を達成することを確認した。
なぜこの問題か
大規模言語モデル(LLM)の訓練において、これまでは高品質な正解データ(正例)をいかに集めるかに焦点が当てられてきたが、誤答データ(負例)に含まれる豊富な情報を十分に活用できていないという大きな課題があった。既存の学習手法では、最終的な答えが間違っているという理由だけで、すべての誤答を等しく価値の低い情報として扱っており、サンプルの「質」という重要な視点が欠落していた。例えば、単純なフォーマットのミスやタイピングエラーによる誤答と、深く複雑な推論過程の末に生じたわずかな論理的逸脱による誤答が、どちらも同じ「負例」として処理されているのが現状である。モデルは表面的なエラーを避けることはすぐに学習するが、推論の微妙な欠陥に隠された高度な学習信号を十分に吸収できていない。 人間が間違いから学ぶプロセスを参考にすると、単純なミスは認識も修正も容易であるが、真の認知的な進歩は「一見正解のように見える間違い」に向き合い、その微細な差異を理解することで得られる。LLMにおいても同様の原理が当てはまると考えられる。…
核心:何を提案したのか
本研究では、高品質な負例を合成するための革新的な手法として「Plausible Negative Samples(PNS)」を提案した。この手法は、期待されるフォーマットと構造的な一貫性を完璧に備えつつ、最終的には誤った答えを導き出すような、人間でも見抜くのが困難な推論パスを生成することを目的としている。PNSは、逆強化学習(Reverse RL)の一種である「Reverse Group Relative Policy Optimization(Reverse GRPO)」アルゴリズムを基盤としており、モデルを「構造化されているが誤っている」という特殊な軌跡へと誘導するための複合的な報酬メカニズムを採用している。 PNSの構築プロセスは、大きく分けて2つのフェーズで構成されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related