SQL-Trail:Text-to-SQLのためのインターリーブされたフィードバックを用いたマルチターン強化学習
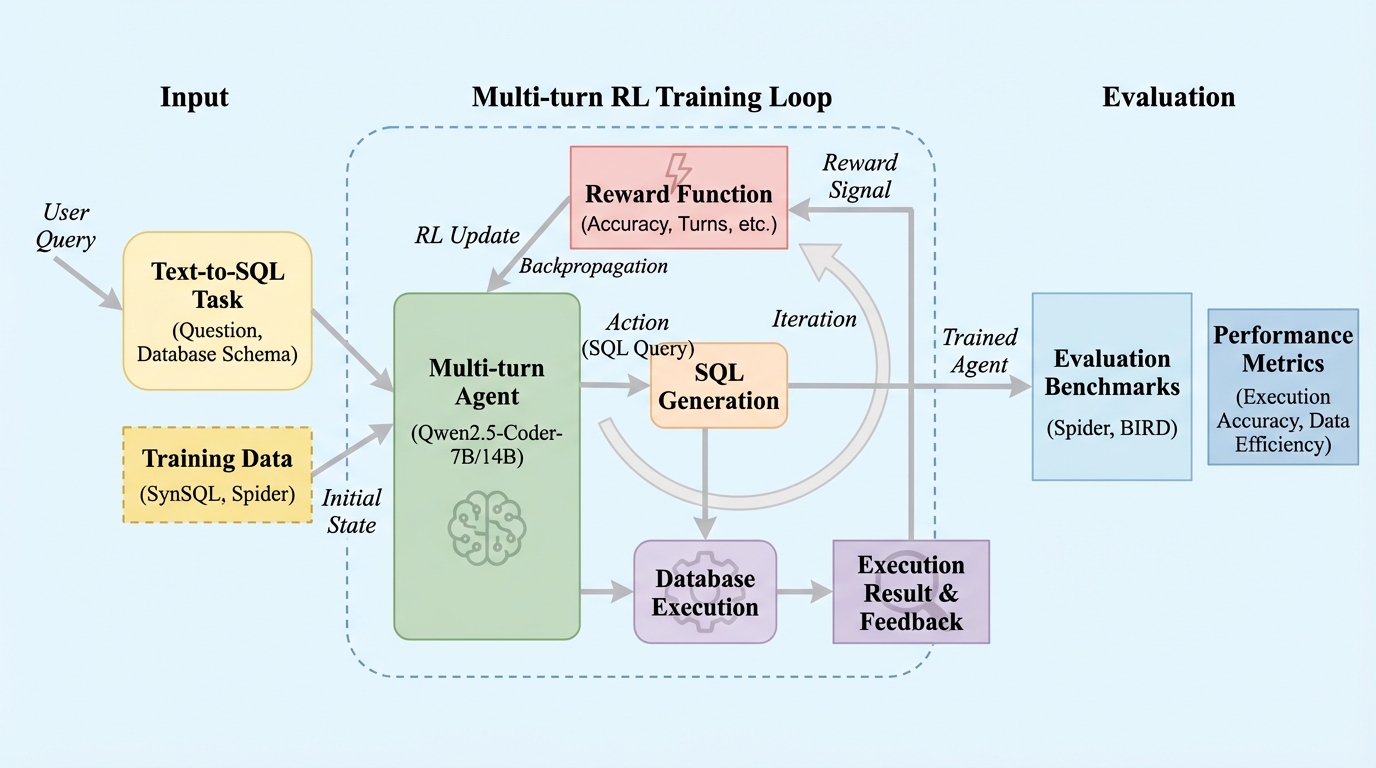
SQL-Trailは、従来の1回限りの生成(シングルパス方式)ではなく、データベースとの対話を通じてSQLを反復的に洗練させるマルチターン強化学習フレームワークであり、人間の専門家が行うような試行錯誤のプロセスをAIで再現することに成功しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
SQL-Trailは、従来の1回限りの生成(シングルパス方式)ではなく、データベースとの対話を通じてSQLを反復的に洗練させるマルチターン強化学習フレームワークであり、人間の専門家が行うような試行錯誤のプロセスをAIで再現することに成功しました。
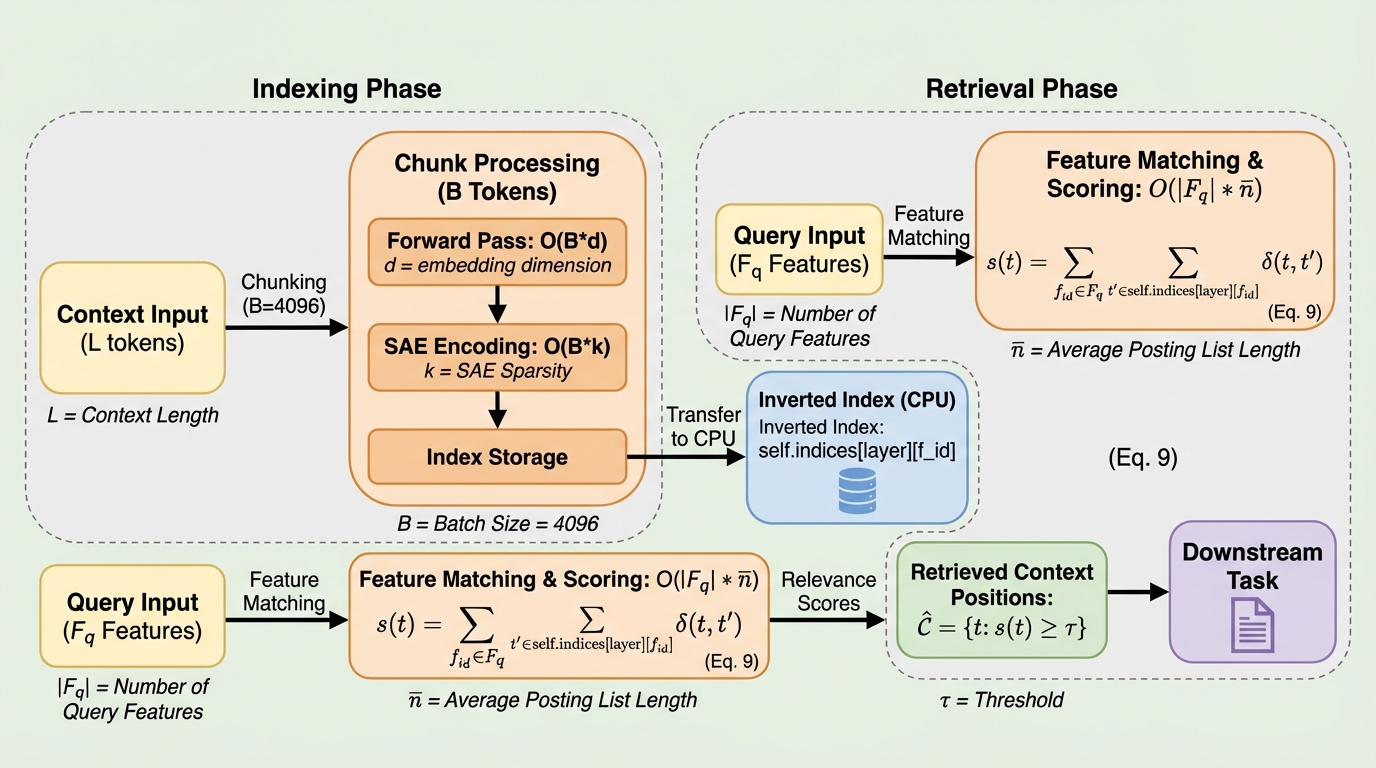
大規模言語モデルの長文脈推論において、GPUメモリの線形増加と外部検索(RAG)による意味的ミスマッチという二大課題を解決するため、モデル内部の信号を直接利用する「内因性検索」フレームワークであるS^3-Attentionを提案しました。
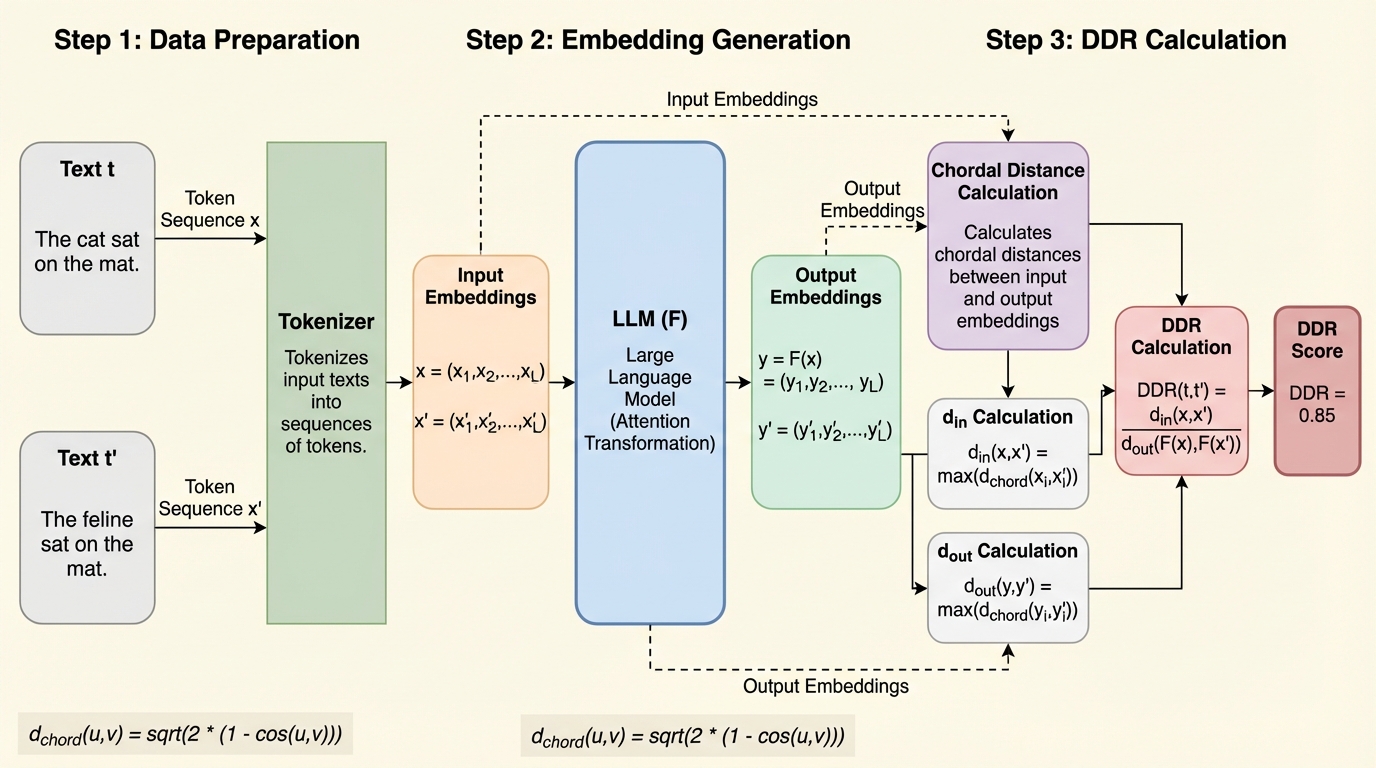
従来のLLM文埋め込みで主流だったコサイン類似度は、局所的な意味の変化に対する感度が低く、人間が感じる類似性を十分に反映できないという課題がありました。 本論文では、リプシッツ連続性の概念に着想を得て、入力時の単語埋め込みと出力時のLLM埋め込みの間の変化率を測定する新指標「DDR(Distance-to-Distance Ratio)」を提案しました。 実験の結果、DDRは類義語置換とランダム置換を明確に区別でき、従来のCentroid法やEOS法を大幅に上回る識別性能と高次元空間における安定性を持つことが確認されました。
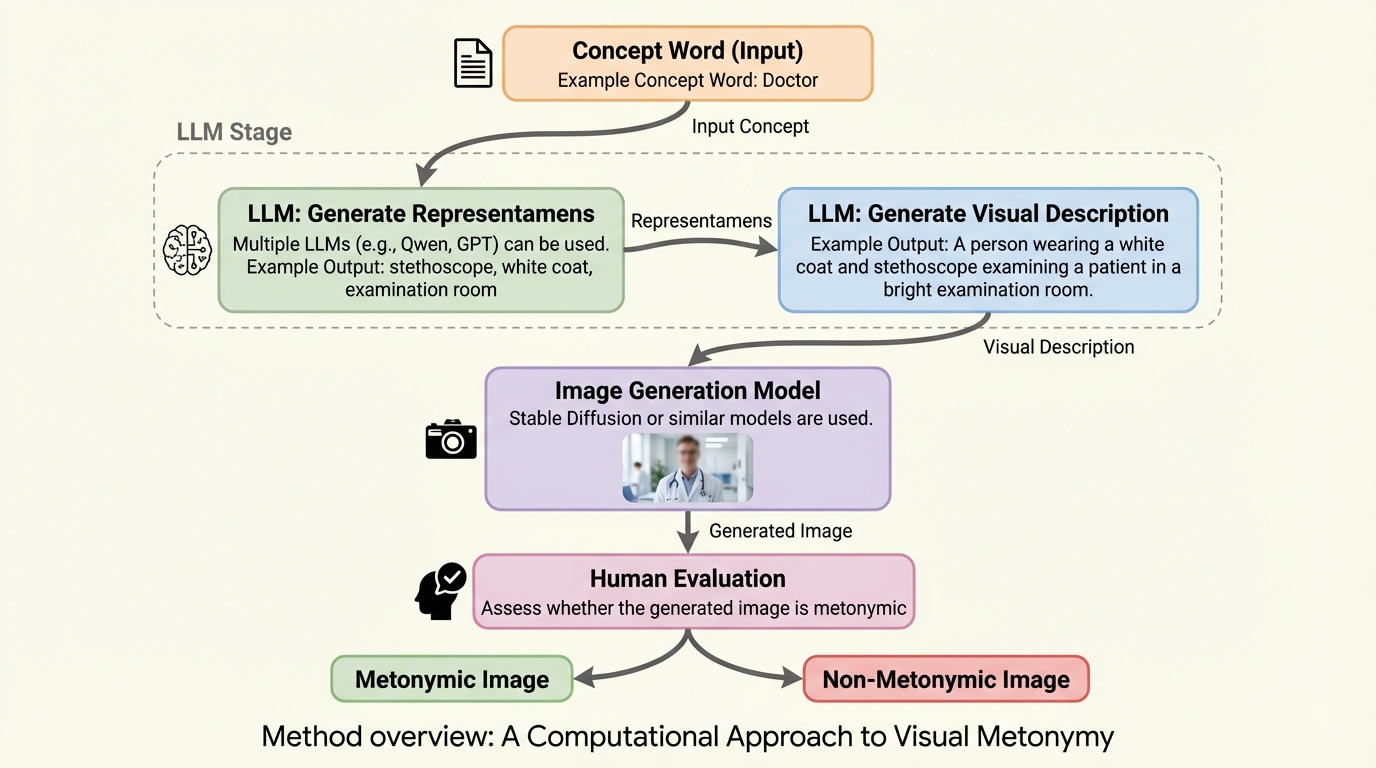
画像が文字通りの意味を超えて、関連する手がかりから対象概念を想起させる「視覚的換喩」について、記号論に基づいた初の計算機的な調査が行われました。大規模言語モデル(LLM)と画像生成モデルを組み合わせ、関連オブジェクトを通じて概念を間接的に表現する新しい生成パイプラインを構築し、2,000問の多肢選択式問題からなるデータセット「ViMET」を開発しました。 検証の結果、最新の視覚言語モデル(VLM)の正解率は65.9%にとどまり、人間の86.9%という精度と比較して21%もの大きな性能差があることが判明し、AIが間接的な視覚的参照を解釈する能力には依然として大きな限界があることが浮き彫りになりました。 この研究は、単なる物体認識を超えた「AIがいかに視覚情報を解釈するか」という認知的な推論能力を評価するための新しい基準を提示しており、文化や文脈、象徴的な関連性を理解する次世代のマルチモーダルAI開発に向けた重要な基礎を築いています。
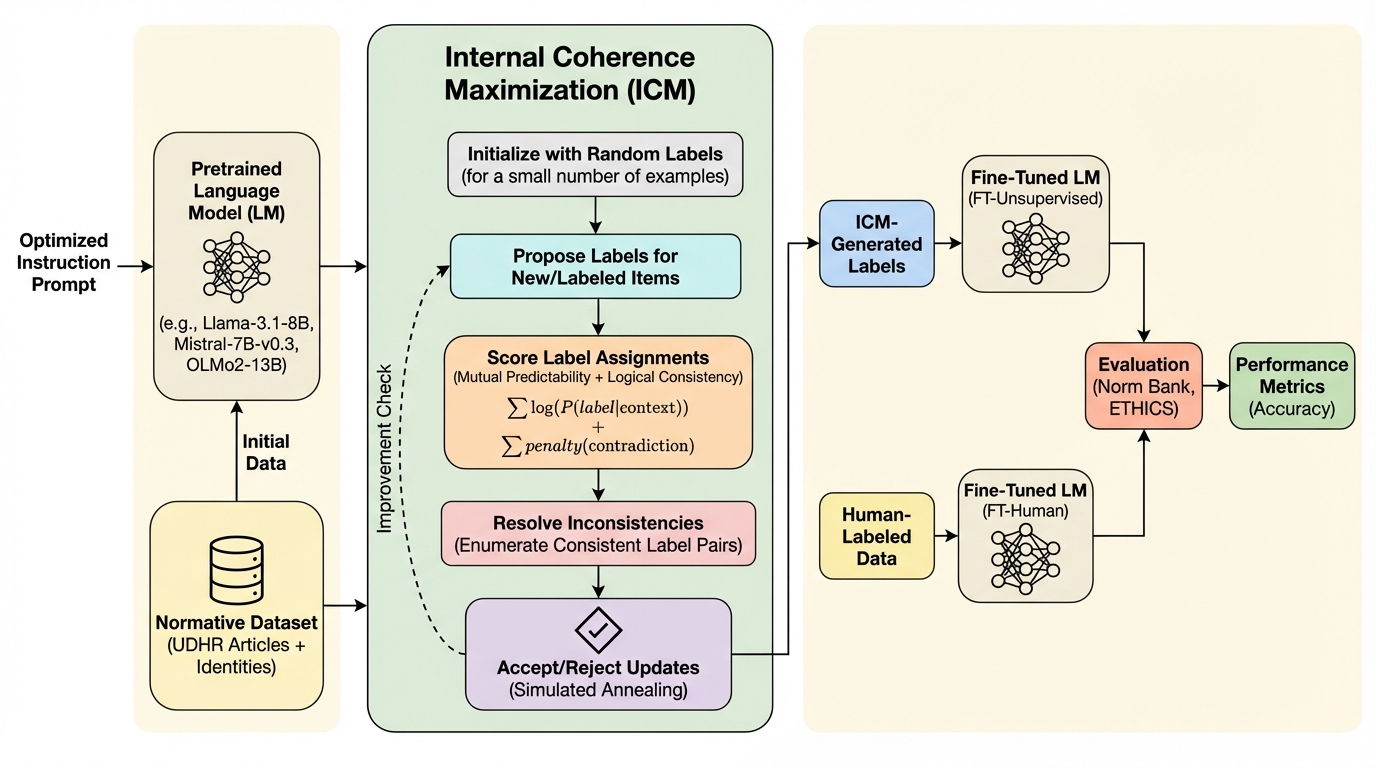
人工知能が社会のあらゆる意思決定プロセスに深く浸透する中で、AIの挙動を人間の道徳的価値観に整合させる「AIアライメント」の重要性がかつてないほど高まっていますが、従来の人手によるラベル付けは、膨大なコストがかかるだけでなく、注釈者の主観的なバイアスや文化的な多様性、さらには時代とともに変化する規範(道徳的相対主義)への対応という極めて困難な課題に直面しています。 本研究では、事前学習済みの言語モデルが膨大なテキスト学習を通じて既に獲得している潜在的な道徳的推論能力を、人間の監督を一切介さずに直接引き出す「内部一貫性最大化(ICM)」という革新的な教師なしアルゴリズムを提案し、モデル内部の論理的な整合性と相互予測可能性を最大化することで、外部からの「教育」ではなくモデル自身の知見を「抽出」する新しいアライメントの道を切り拓きました。 複数の倫理ベンチマークを用いた検証の結果、ICMは既存のチャットモデルや人間がラベル付けしたデータによる微調整を凌駕する高い精度を達成し、特に正義や常識的道徳の分野で顕著な成果を上げたほか、人種や社会経済的地位に関する深刻な社会的バイアスを半分以下に抑制できることを実証し、大規模言語モデルの安全性をスケーラブルかつ客観的に向上させる手法としての有効性を示しました。
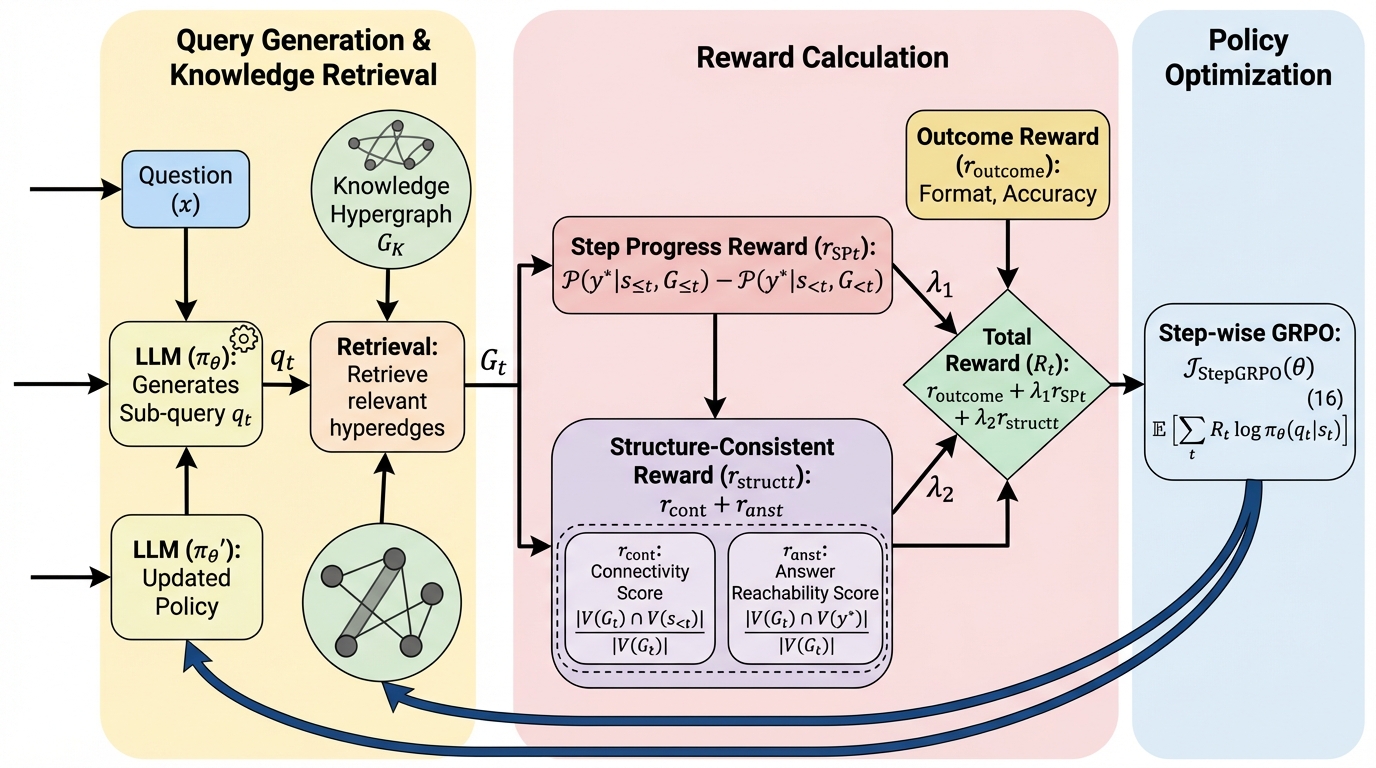
大規模言語モデルが知識集約的なタスクで起こすハルシネーションを抑制するため、グラフ構造のつながりと推論の進捗状況を同時に考慮する新しい強化学習フレームワーク「ProGraph-R1」が開発されました。
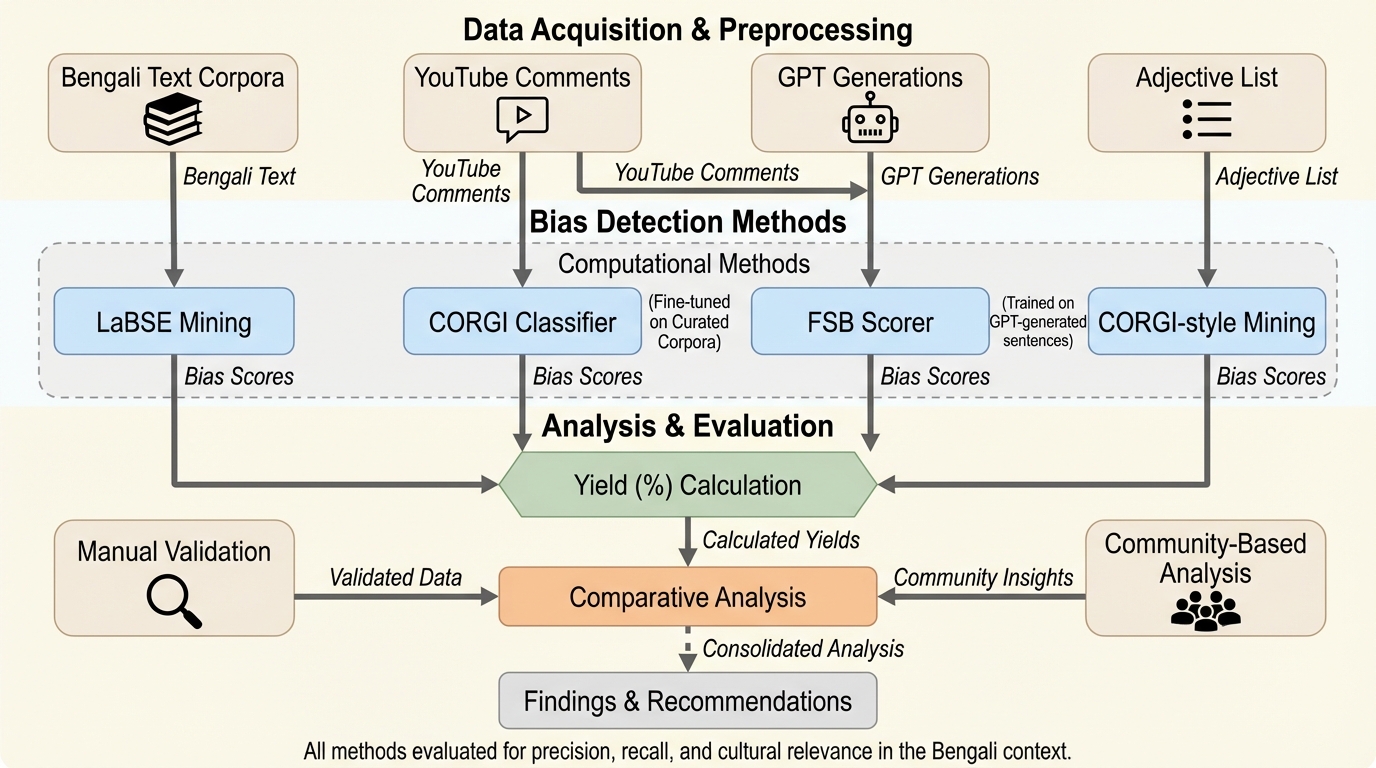
大規模言語モデル(LLM)におけるジェンダーバイアスの研究は英語に偏っており、ベンガル語のような低リソース言語かつ独自の文化背景を持つ言語での実態は十分に解明されていませんでした。 本研究では、翻訳、分類器、GPTによる生成、辞書ベースのマイニングなど多角的な手法を用いてベンガル語のバイアスを検証し、英語中心の検出枠組みをそのまま適用することの限界を明らかにしました。 農村部でのフィールド調査を含むコミュニティ主導のアプローチを導入することで、自動化システムでは捉えきれない文化特有のバイアスを特定し、より公平な自然言語処理システムの構築に向けた基盤を提示しました。
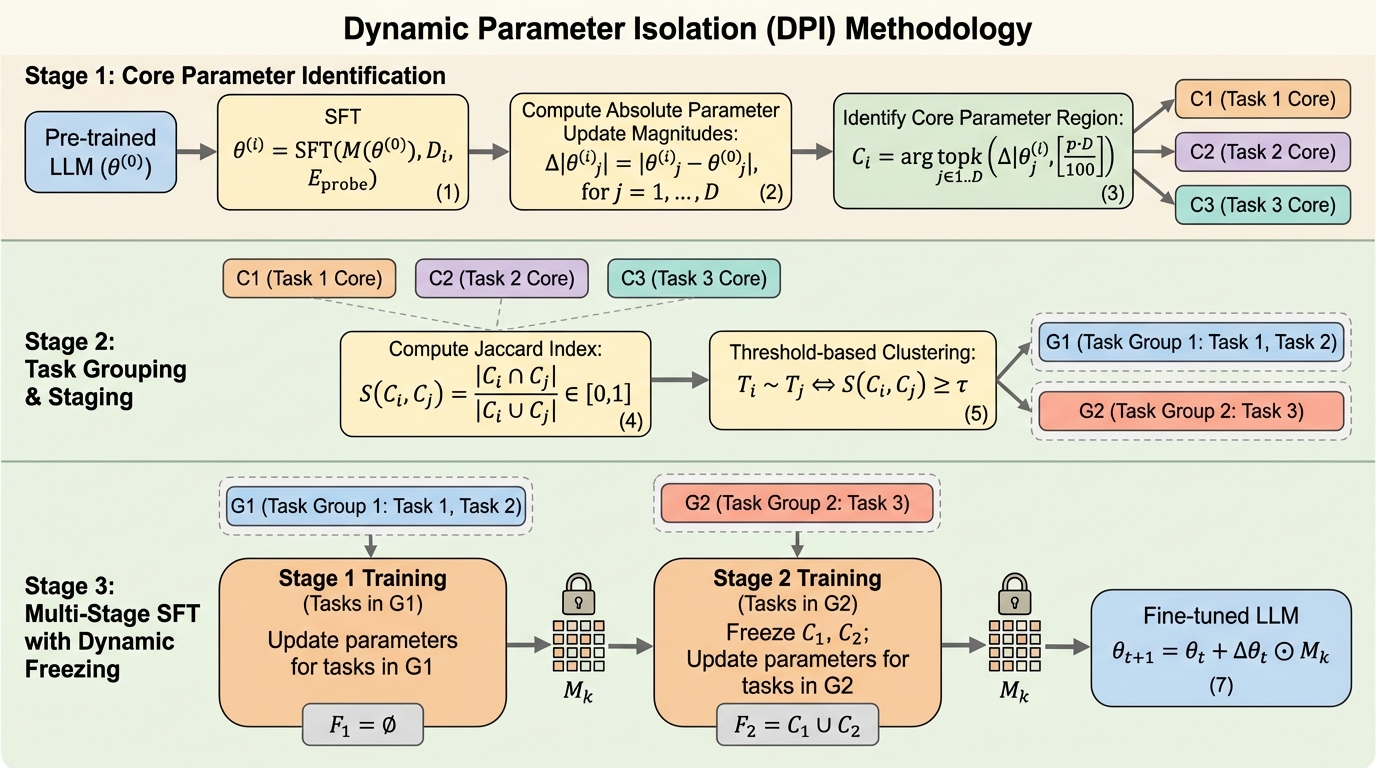
大規模言語モデル(LLM)の教師あり微調整(SFT)において、異なるタスク間の目的が衝突することで一方の性能が上がると他方が下がる「シーソー現象」を解決するため、タスクごとに依存するパラメータ領域が異なるという「パラメータの不均一性」に着目した新しい手法「DPI」が提案された。
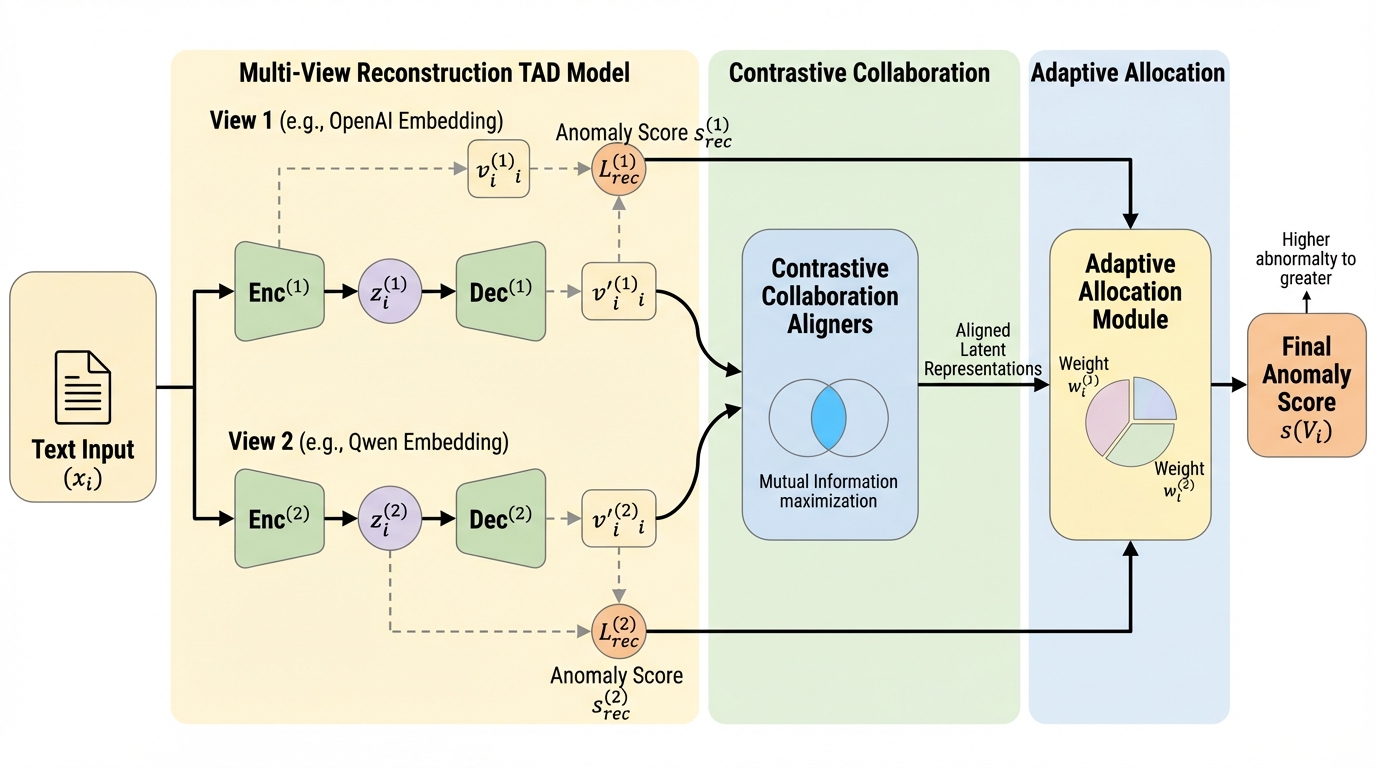
従来のテキスト異常検知は単一の埋め込みモデルに依存しており、特定のデータ分布への偏りや未知の異常に対する適応力の不足が大きな課題となっていましたが、本研究では複数の言語モデルの表現を統合する新しいフレームワークであるMCA²を提案しました。
DIETAは、イタリア語と英語の双方向翻訳に特化して設計された、5億パラメータという比較的小規模なデコーダ専用Transformerモデルであり、大規模な精選コーパスと逆翻訳データを活用して構築されました。