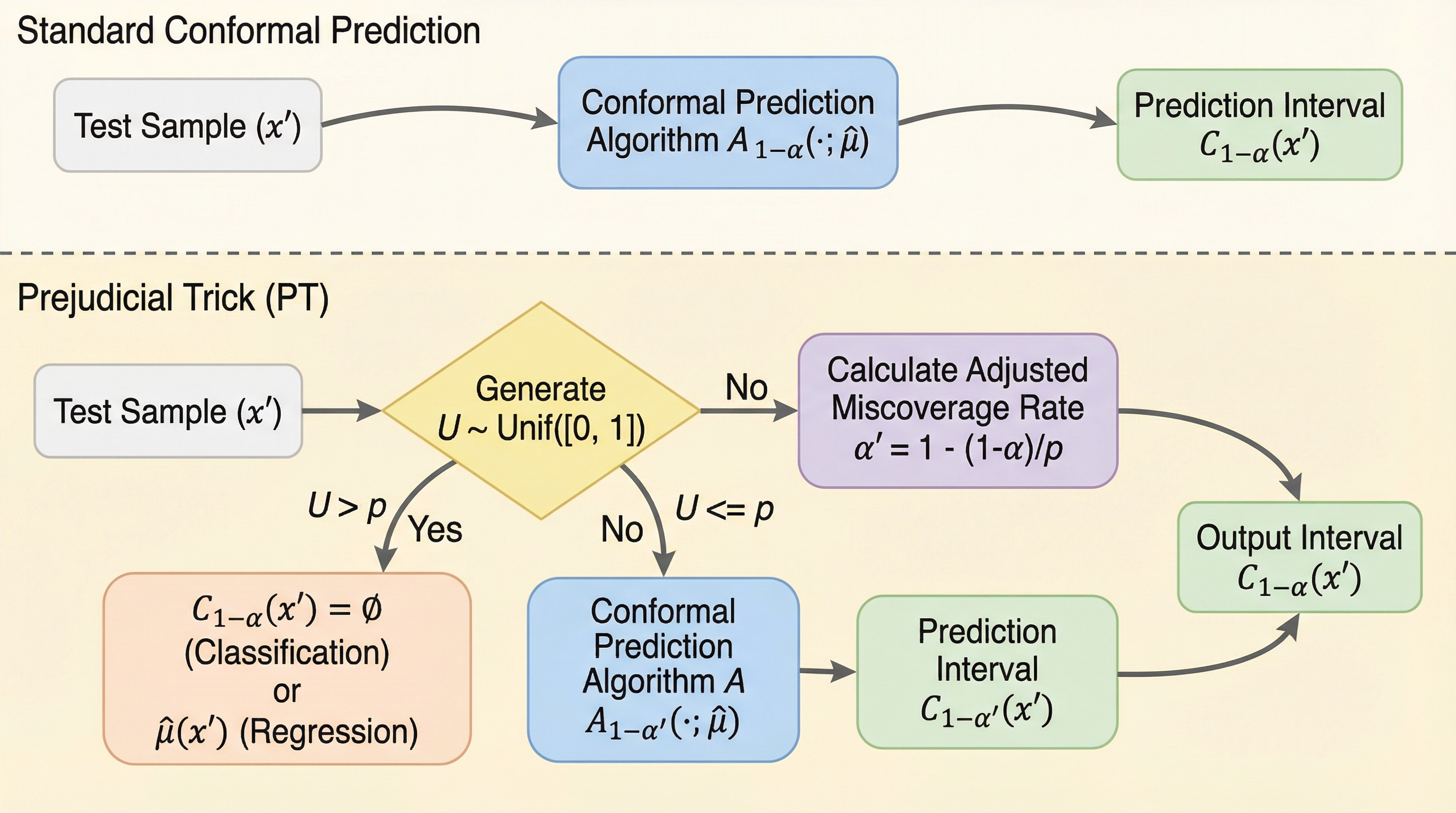
共形予測における被覆率と区間長指標への疑問:短い区間が必ずしも優れているとは限らない理由
共形予測(CP)の評価で主流の「被覆率」と「区間長」という指標は、特定の確率で空集合を返す「Prejudicial Trick(PT)」という手法によって、統計的な妥当性を維持したまま数値だけを欺瞞的に向上させることが可能です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
共形予測(CP)の評価で主流の「被覆率」と「区間長」という指標は、特定の確率で空集合を返す「Prejudicial Trick(PT)」という手法によって、統計的な妥当性を維持したまま数値だけを欺瞞的に向上させることが可能です。
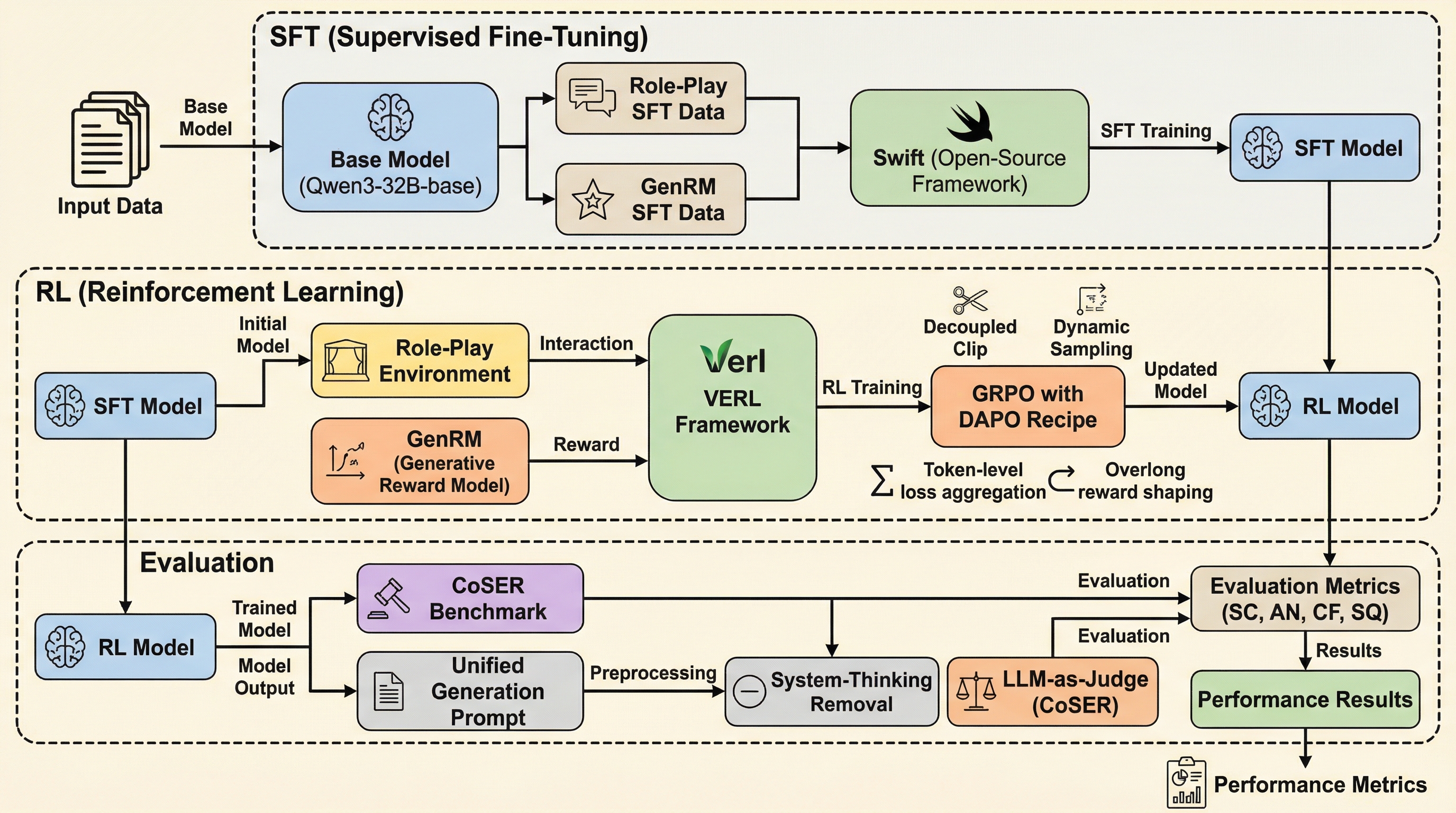
現在の大規模言語モデル(LLM)によるロールプレイは、キャラクターの口調や知識の模倣には長けているものの、その行動の背後にある内面的な思考や推論をシミュレートすることが困難であるという課題を抱えています。
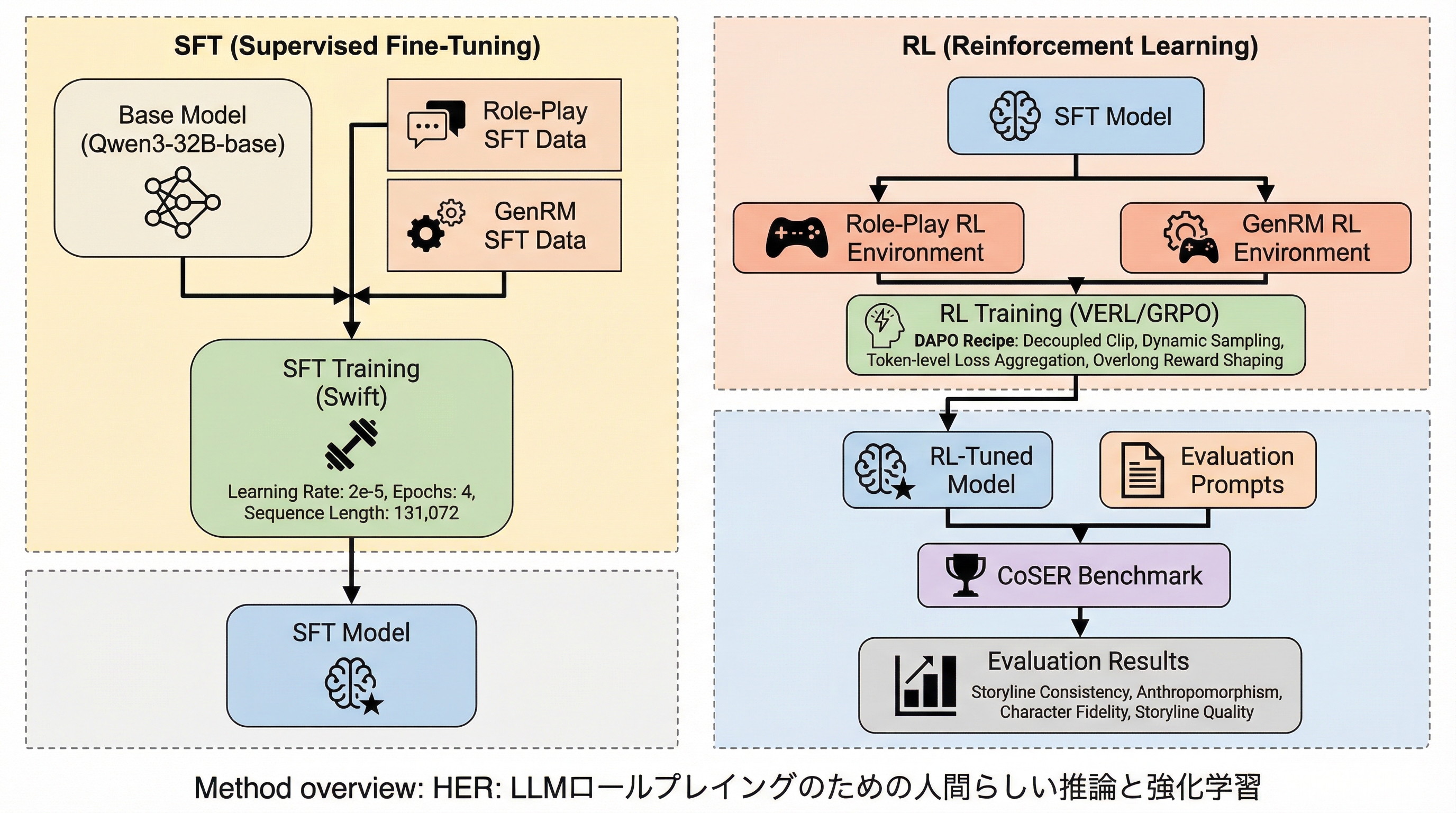
HER(Human Emulation Reasoning)は、LLMのロールプレイングにおいてキャラクターの内面的な思考を高度にシミュレートするための統合フレームワークであり、隠された三人称視点の「システム思考」と、公開される一人称視点の「ロール思考」を分離した二層構造の思考プロセスを導入しています。
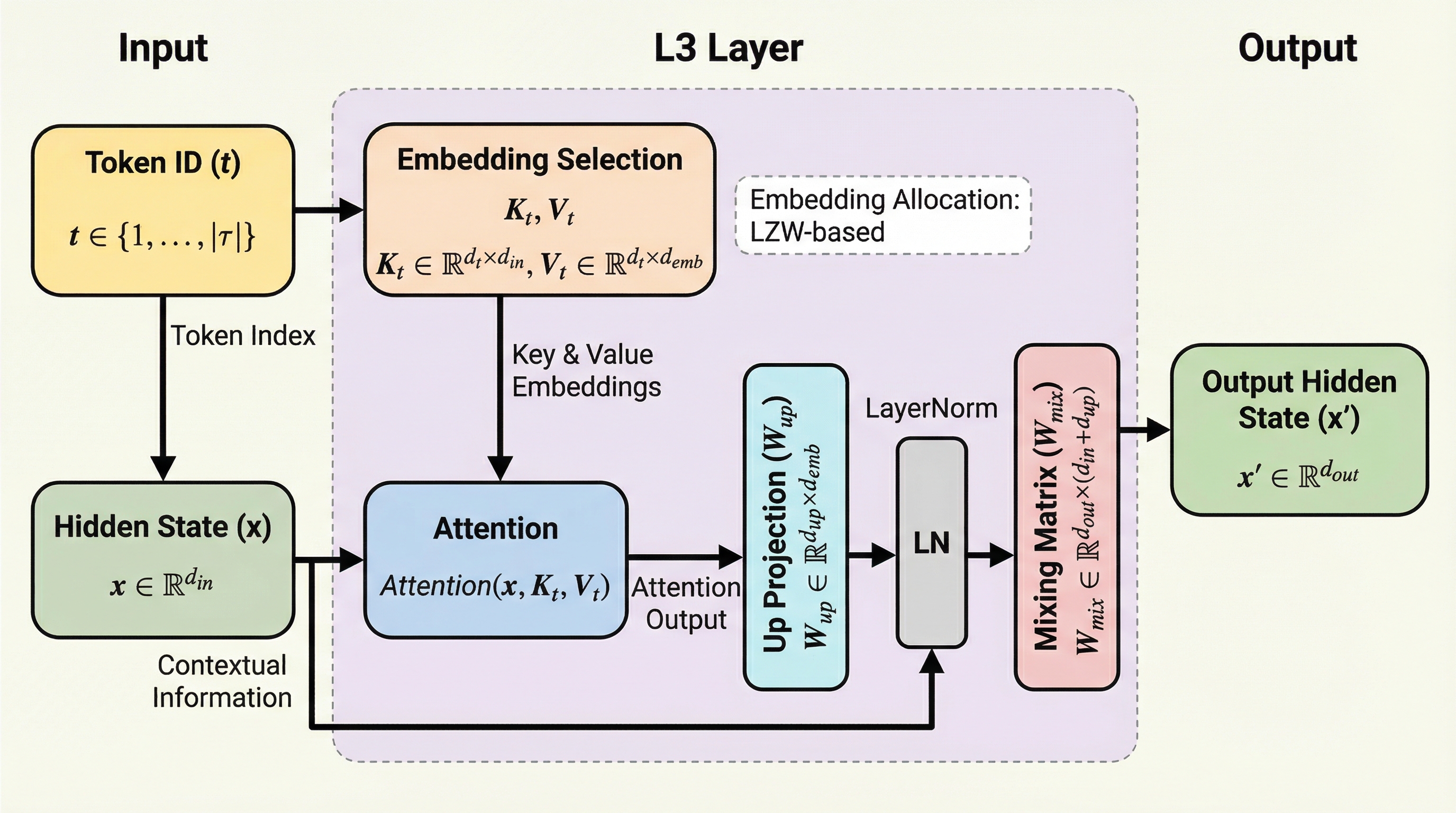
L3(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱える動的ルーティングに伴うハードウェア効率の低下や学習の不安定さを解消するために提案された、新しいスパースアーキテクチャである。
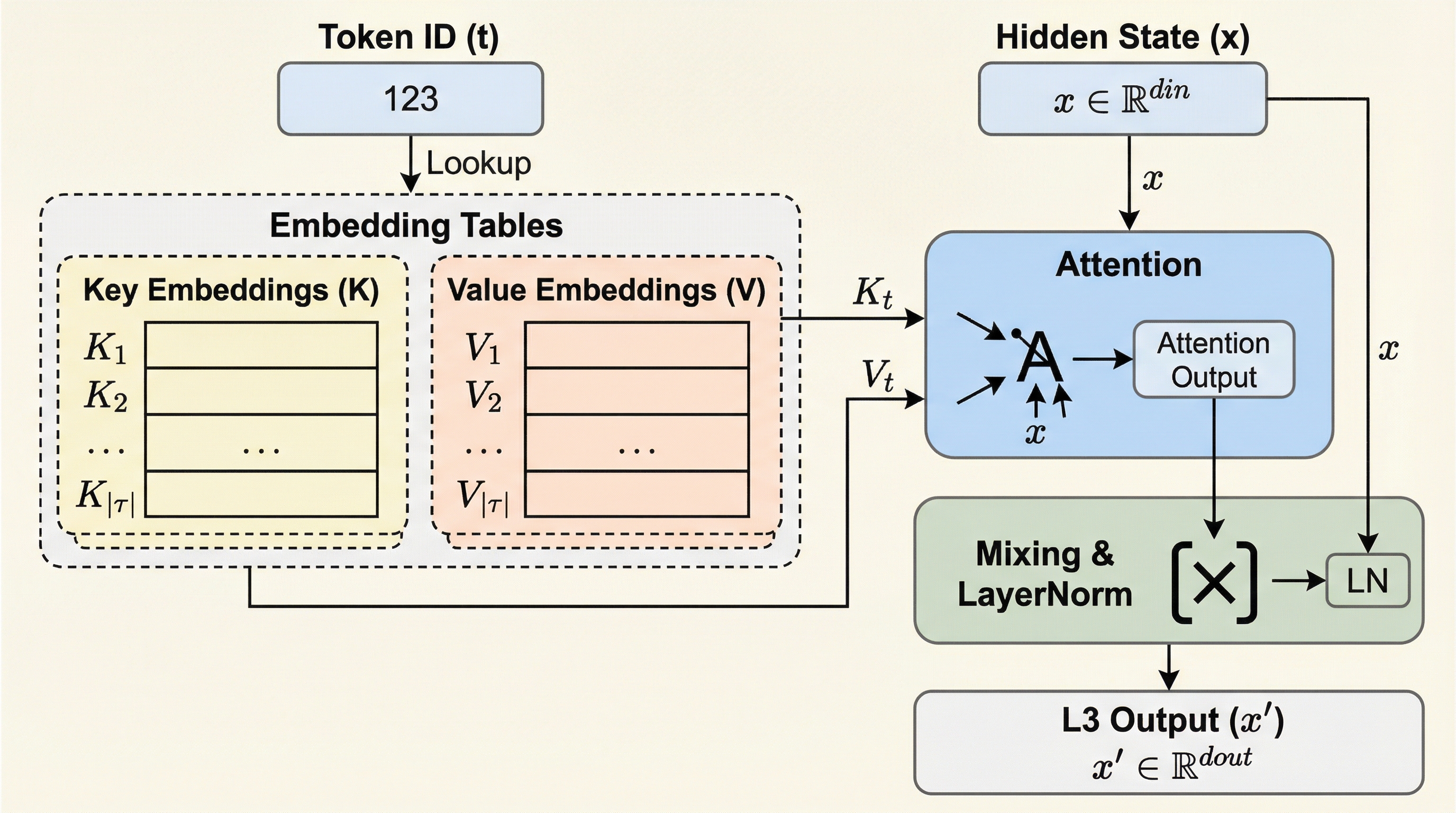
L$^3$(Large Lookup Layer)は、従来のMixture-of-Experts(MoE)が抱えるハードウェア効率の低下や学習の不安定さを克服するために提案された、新しいスパースなデコーダ層のアーキテクチャである。
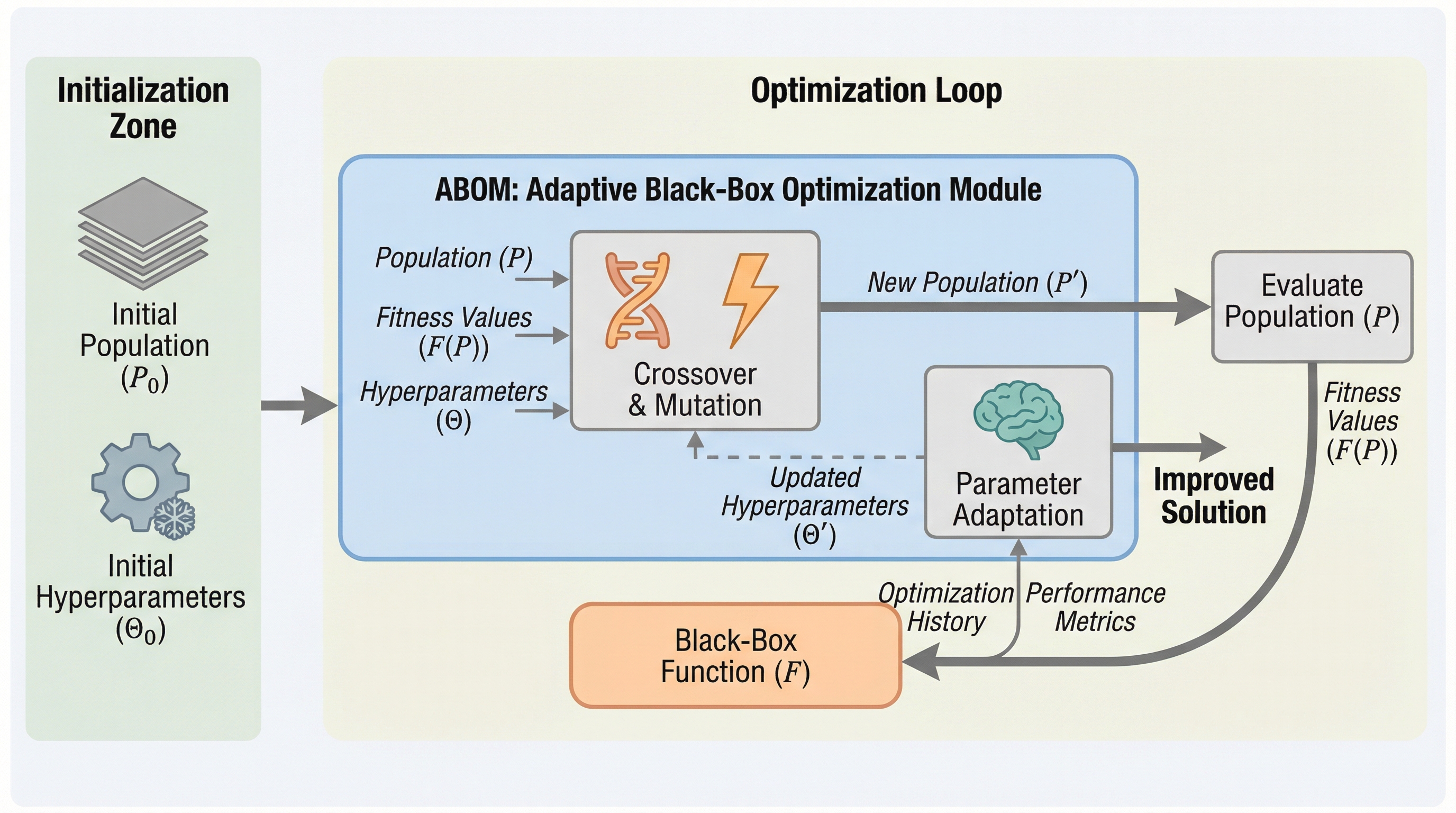
従来のメタブラックボックス最適化(MetaBBO)は、未知のタスクに汎化させるために事前に大量の手動設計された学習タスクを必要とするという大きな制約がありましたが、本研究で提案された「ABOM」は、ターゲットとなるタスクの最適化プロセスで生成されるデータのみを用いてオンラインでパラメータを適応させることで、この制約を根本から解消します。 進化計算の主要な操作である選択、交叉、変異を注意機構(Attention Mechanism)を用いた微分可能な関数として定義し、生成された個体群をエリートアーカイブに近づけるように自己更新を行うクローズドループの学習メカニズムを導入することで、事前のメタ学習を一切行わない「ゼロショット最適化」を実現しました。 合成ベンチマークおよび無人航空機の経路計画問題を用いた検証により、提案手法は高次元の問題においても既存の高度なアルゴリズムを凌駕する性能を達成しただけでなく、注意行列の可視化を通じて自然選択や遺伝的再結合といった探索パターンの統計的な解釈性を提供することが確認されています。
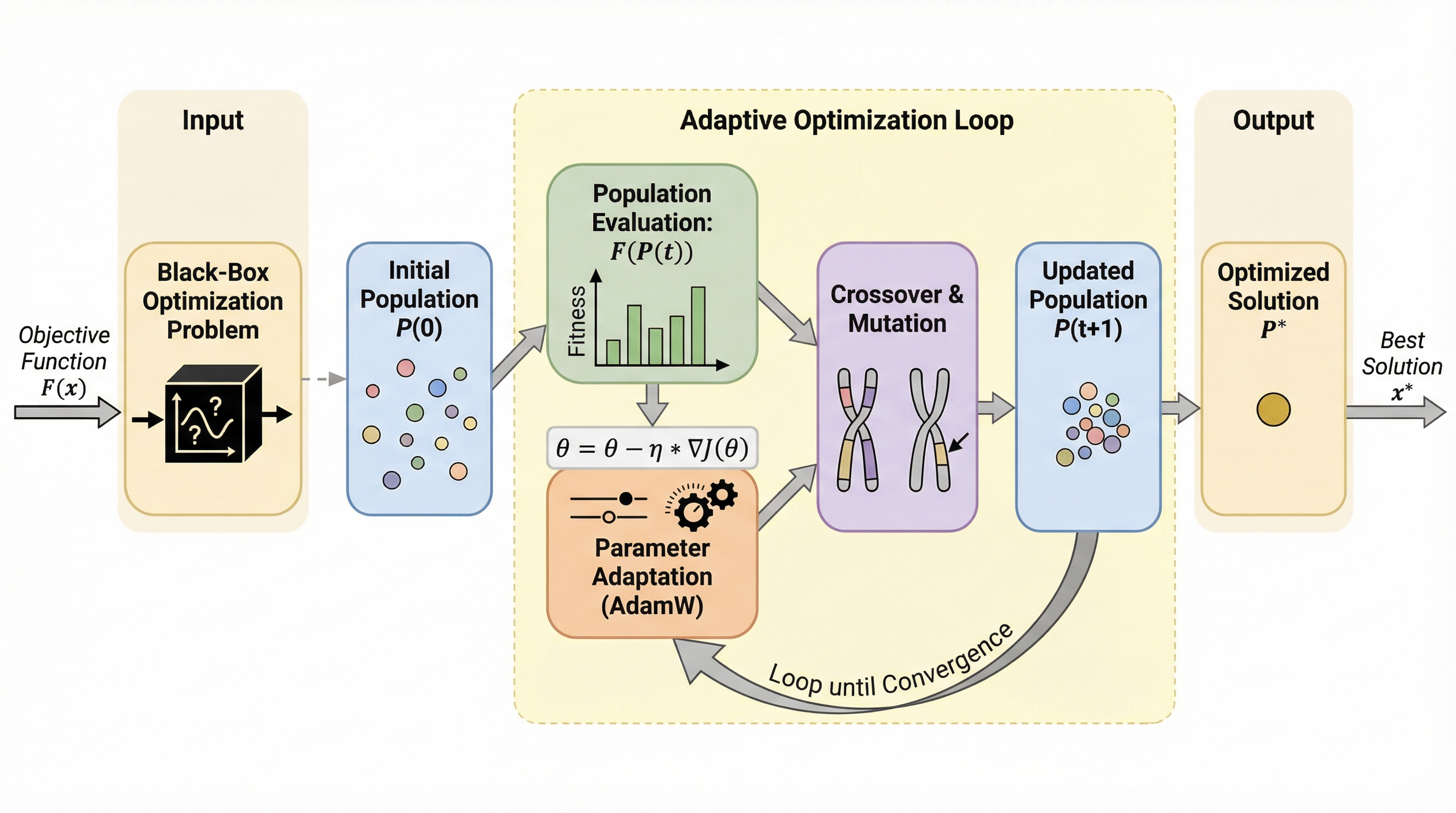
従来のメタブラックボックス最適化(MetaBBO)は、未知のタスクへ適応するために事前に設計された膨大な学習用タスク分布を必要としていたが、本研究が提案するABOM(Adaptive meta Black-box Optimization Model)は、ターゲットとなるタスクから得られる自己生成データのみを用いてオンラインでパラメータを適応させる。 このモデルは、進化計算の主要なオペレータである選択、交叉、突然変異をアテンション機構に基づいた微分可能な関数として定義しており、生成された個体群とエリートアーカイブの距離を最小化するようにパラメータをリアルタイムで更新することで、事前のメタ学習フェーズを一切必要としない「ゼロショット最適化」を実現している。 合成ベンチマーク(BBOB)や実世界の無人航空機(UAV)経路計画問題において、ABOMは事前に学習済みの最新メタ学習手法や高度に調整された適応型アルゴリズムと同等以上の性能を発揮し、さらにGPU加速への対応やアテンション行列を通じた探索パターンの可視化による高い解釈性、および全域収束性の理論的保証を兼ね備えている。
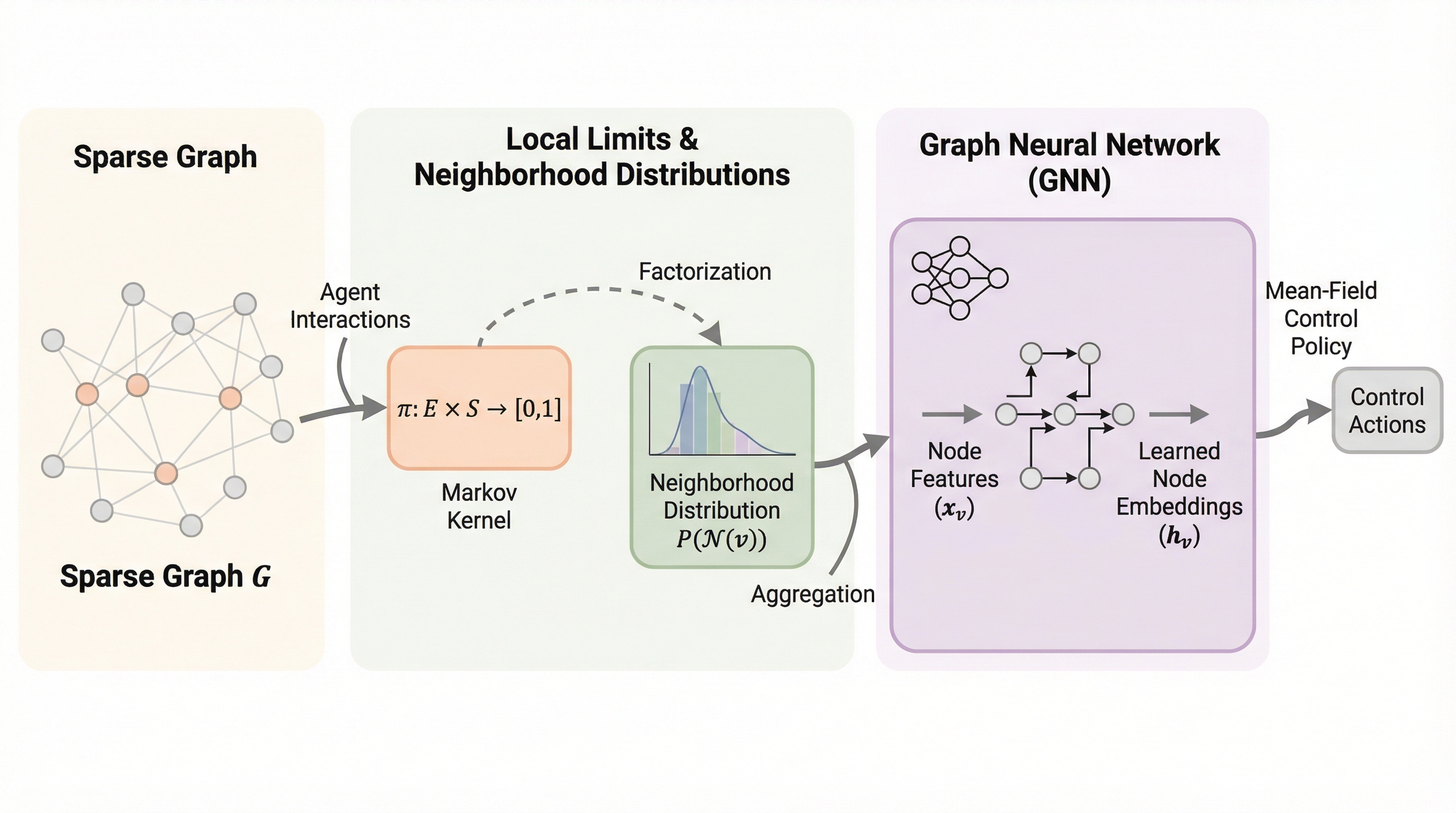
大規模マルチエージェントシステムにおいて、従来の平均場制御が前提としていた「全エージェント間の一様な相互作用」という制約を打破し、現実的な希薄グラフ上での制御を可能にする理論的枠組み「Sparse-MFC」が提案されました。
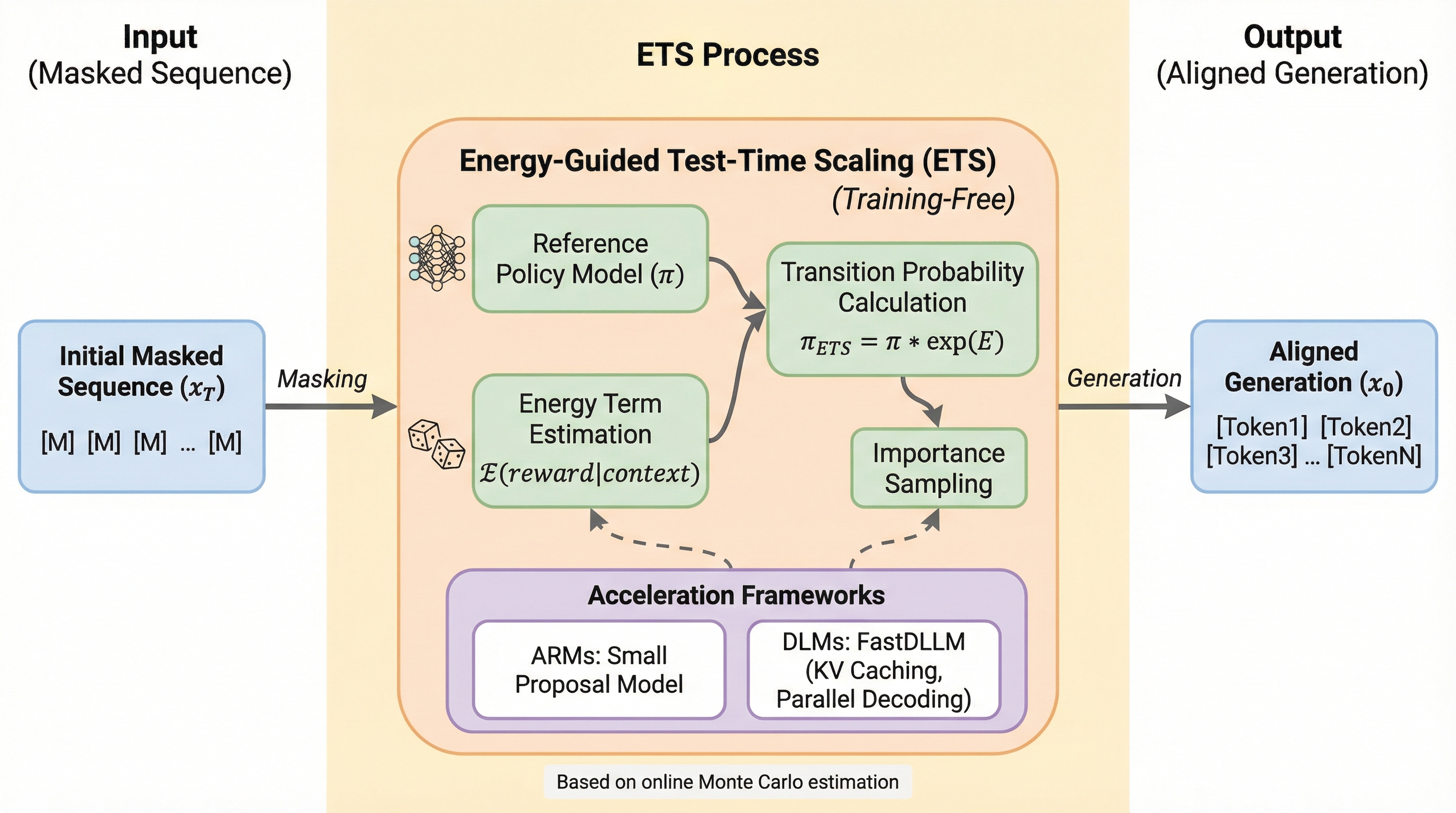
言語モデルの強化学習(RL)による事後学習アライメントは、複雑なトレーニングプロセスや高コストな報酬モデリング、不安定な学習動態といった課題を抱えていますが、本研究では追加の学習を一切行わずに推論時に最適なRLポリシーから直接サンプリングを行う手法「Energy-Guided Test-Time Scaling(ETS)」を提案しています。 ETSは、マスク言語モデリング(MLM)の枠組みにおいて遷移確率をリファレンスポリシーとエネルギー項に分解し、オンラインモンテカルロ法を用いてこのエネルギー項を推定することで、学習なしでのアライメントを実現し、推論時の計算量を増やすことで生成品質を向上させる新しいテスト時スケーリングの形態を提示しています。 実用的な効率を確保するために、重点サンプリングと軽量なプロポーザルモデルを組み合わせた加速戦略を導入しており、理論的な収束性を保証しながら推論の遅延を大幅に削減し、推論やコーディングなどのベンチマークにおいて従来の学習ベースのRL手法を凌駕する性能を一貫して達成していることが確認されました。
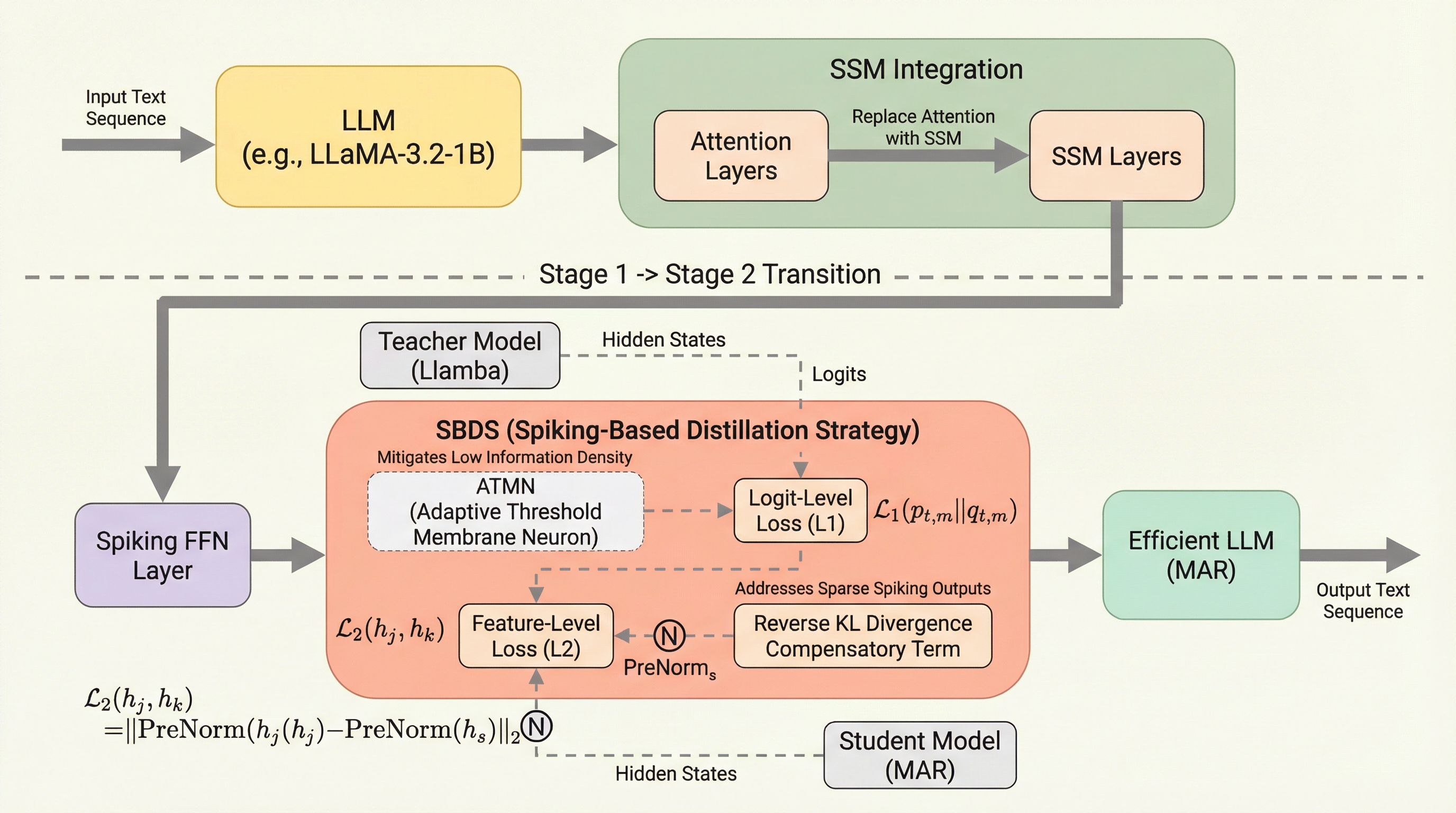
大規模言語モデルの計算コストとエネルギー消費を削減するため、アテンション機構を状態空間モデル(SSM)に置き換えて線形時間処理を実現し、さらにFFN層をスパイキングニューラルネットワーク(SNN)で疎化する二段階フレームワーク「MAR」を提案しています。