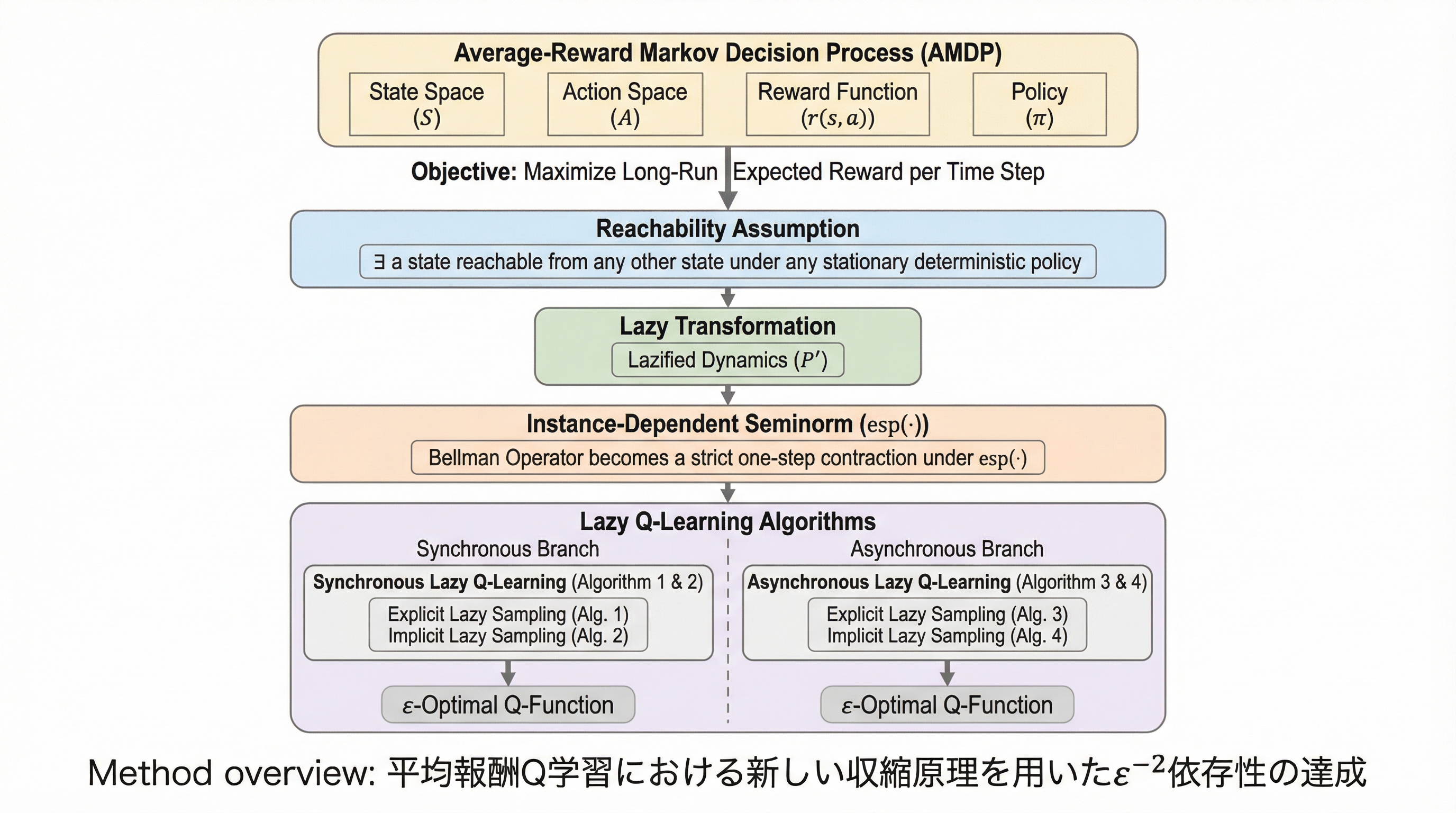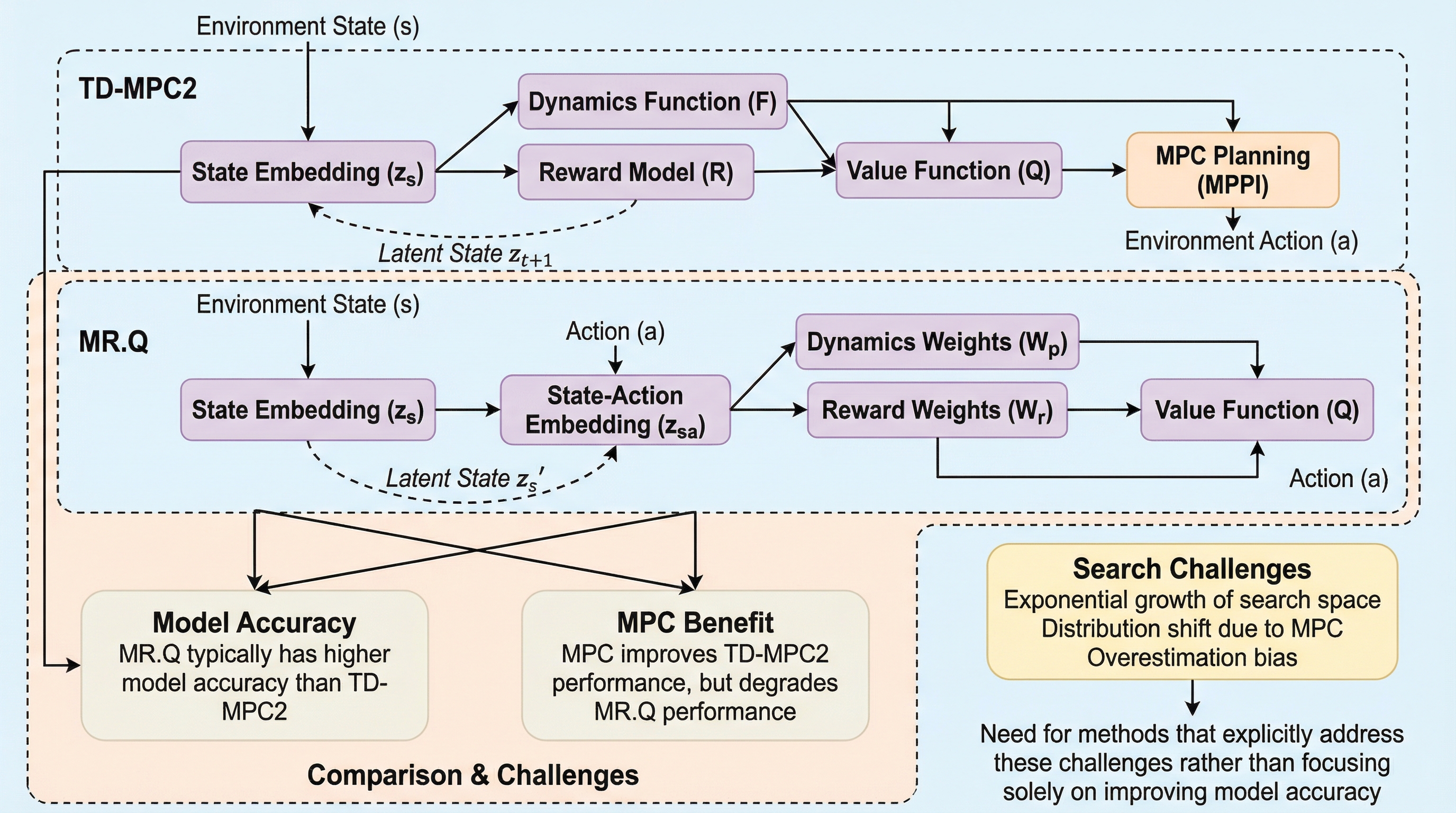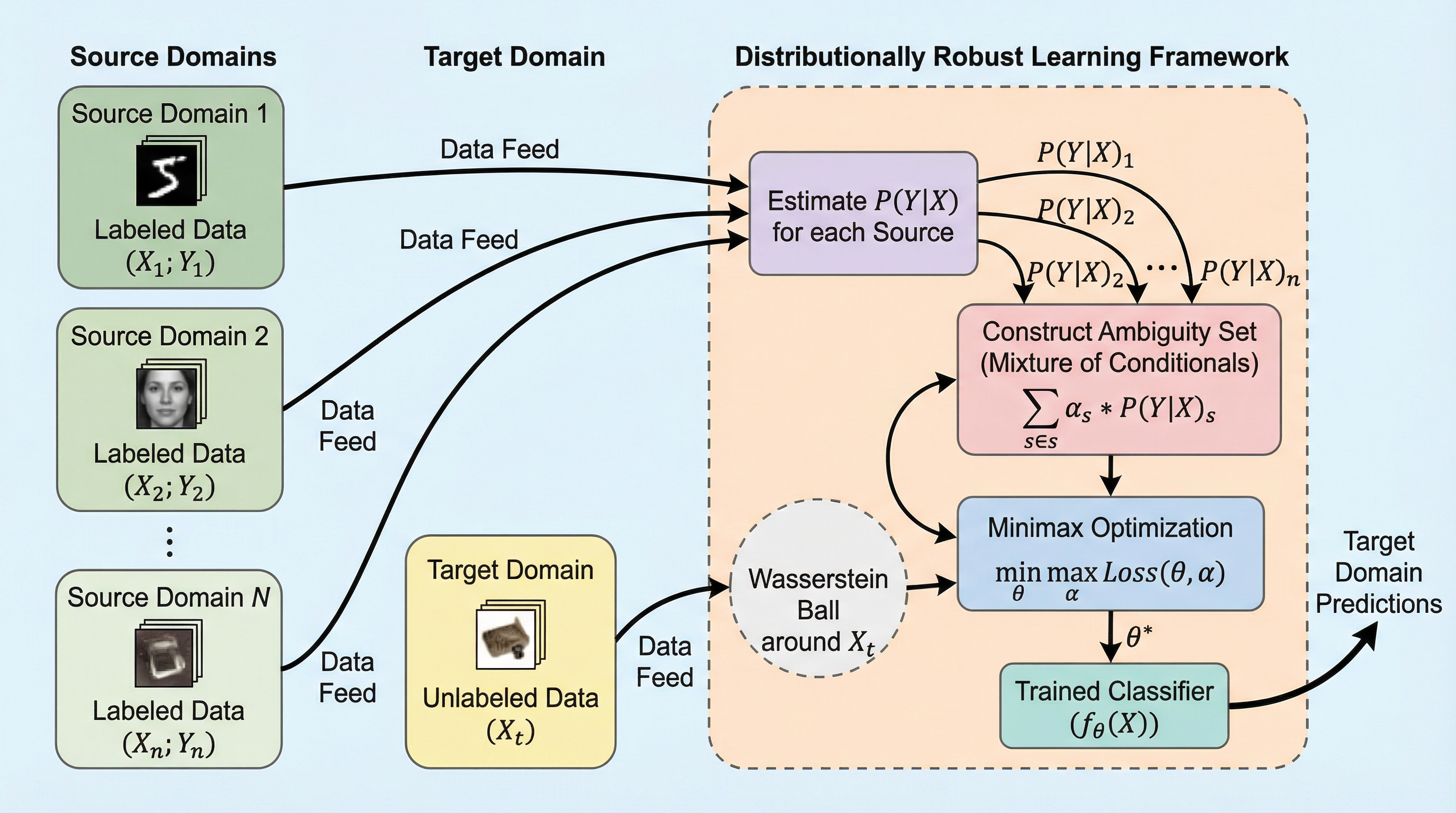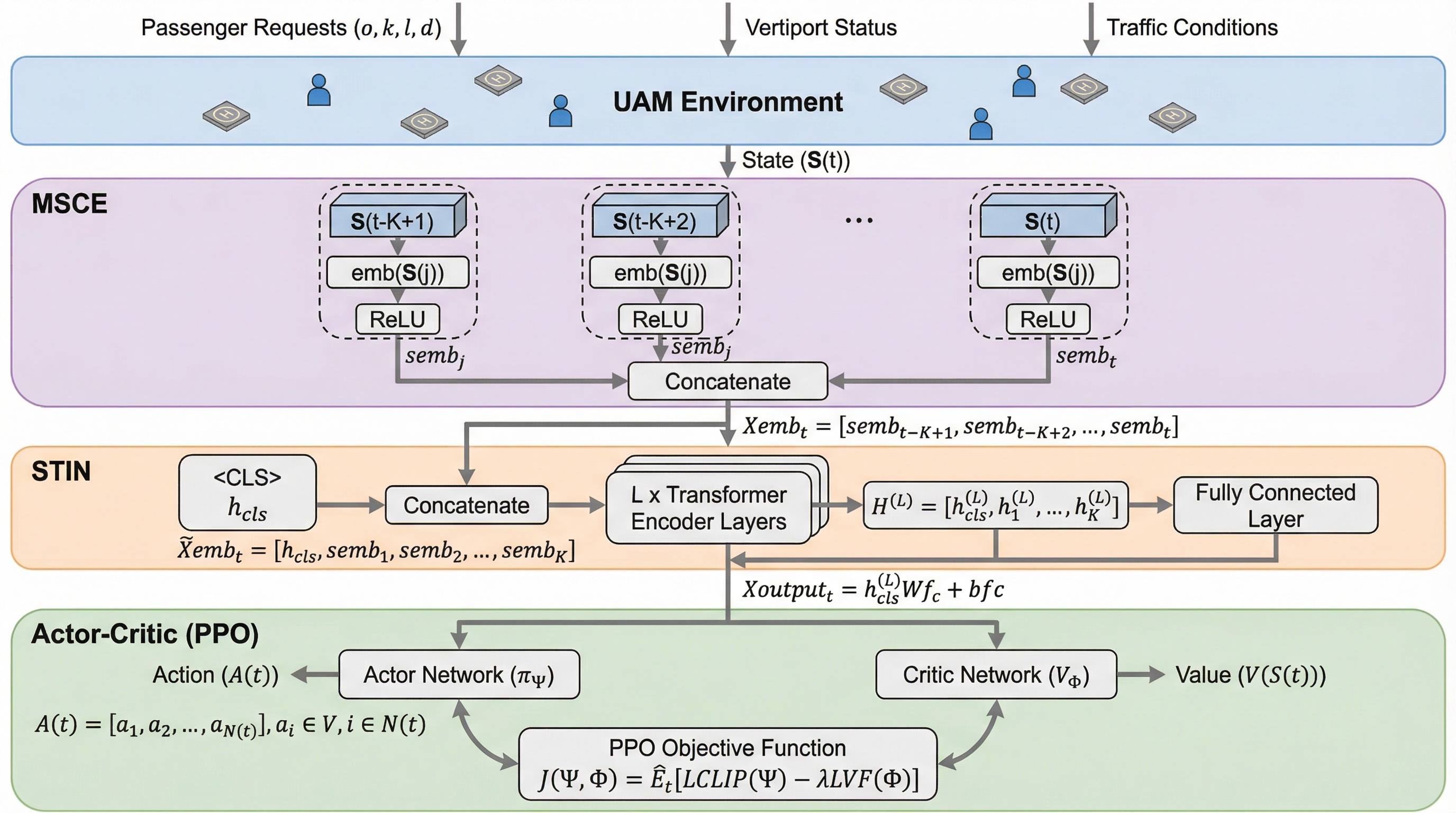
サイバー物理システムにおける証明可能な状態の完全性:モジュール型主権が可塑性・安定性のパラドックスを解決する理由
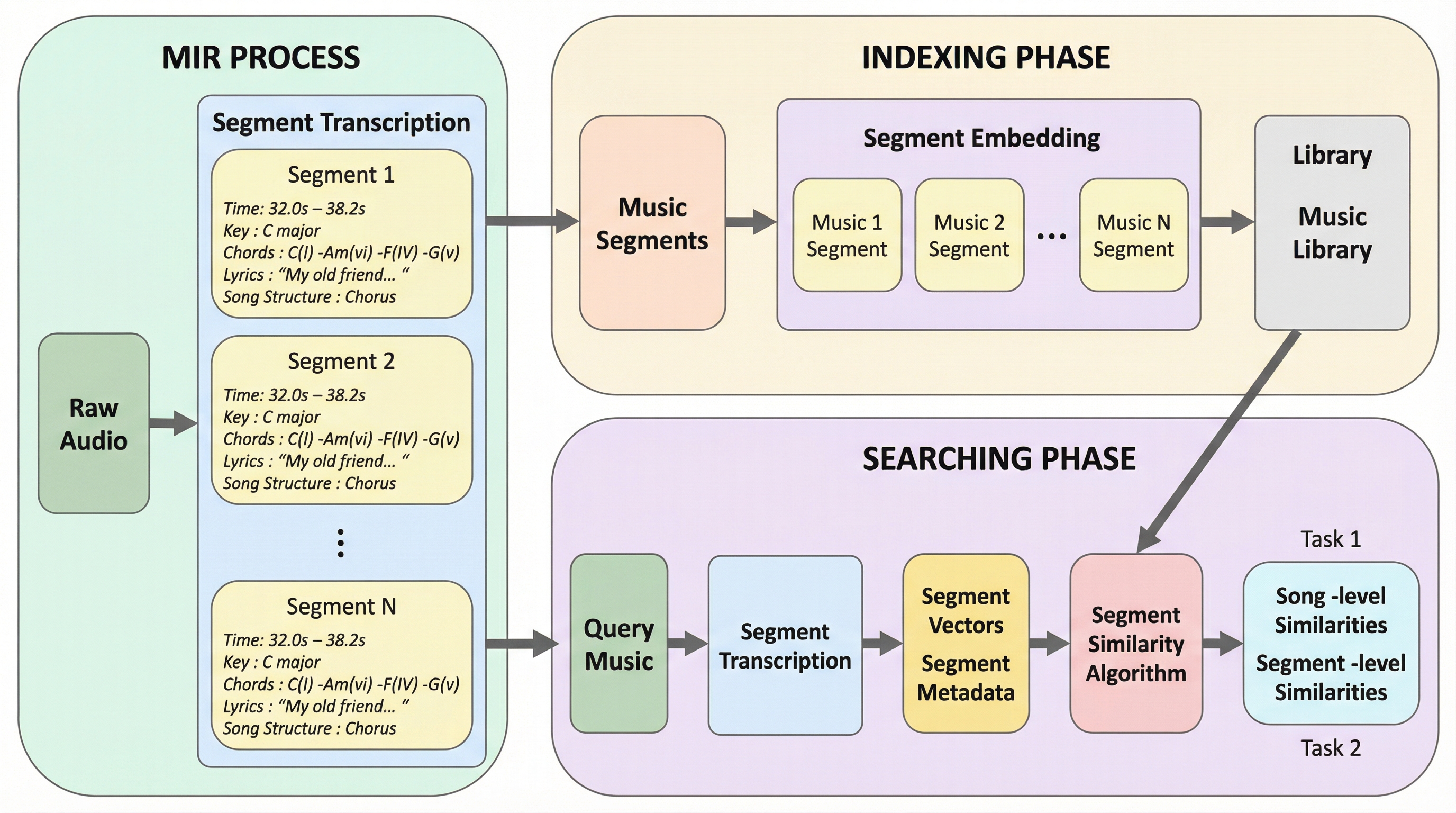
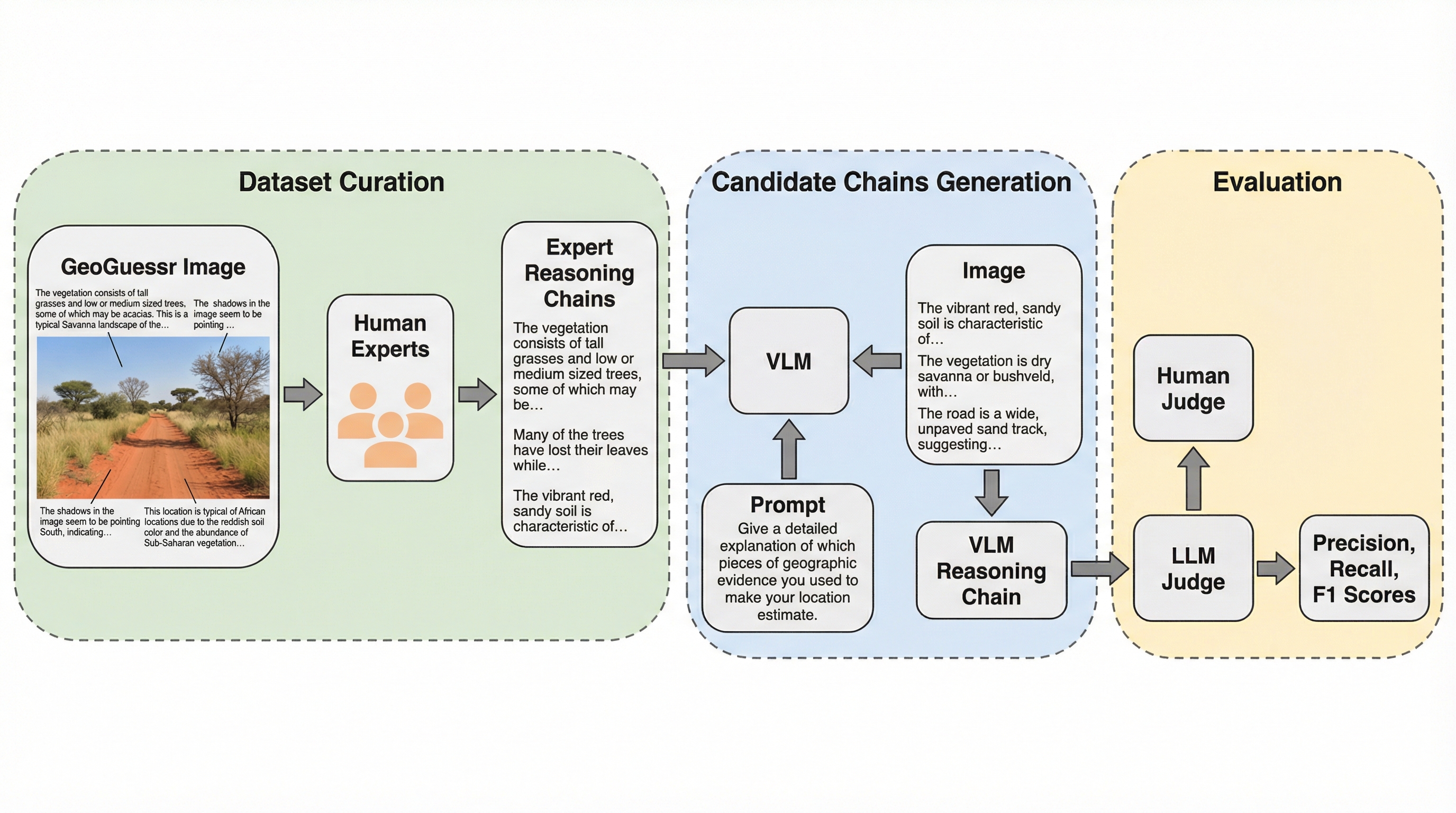
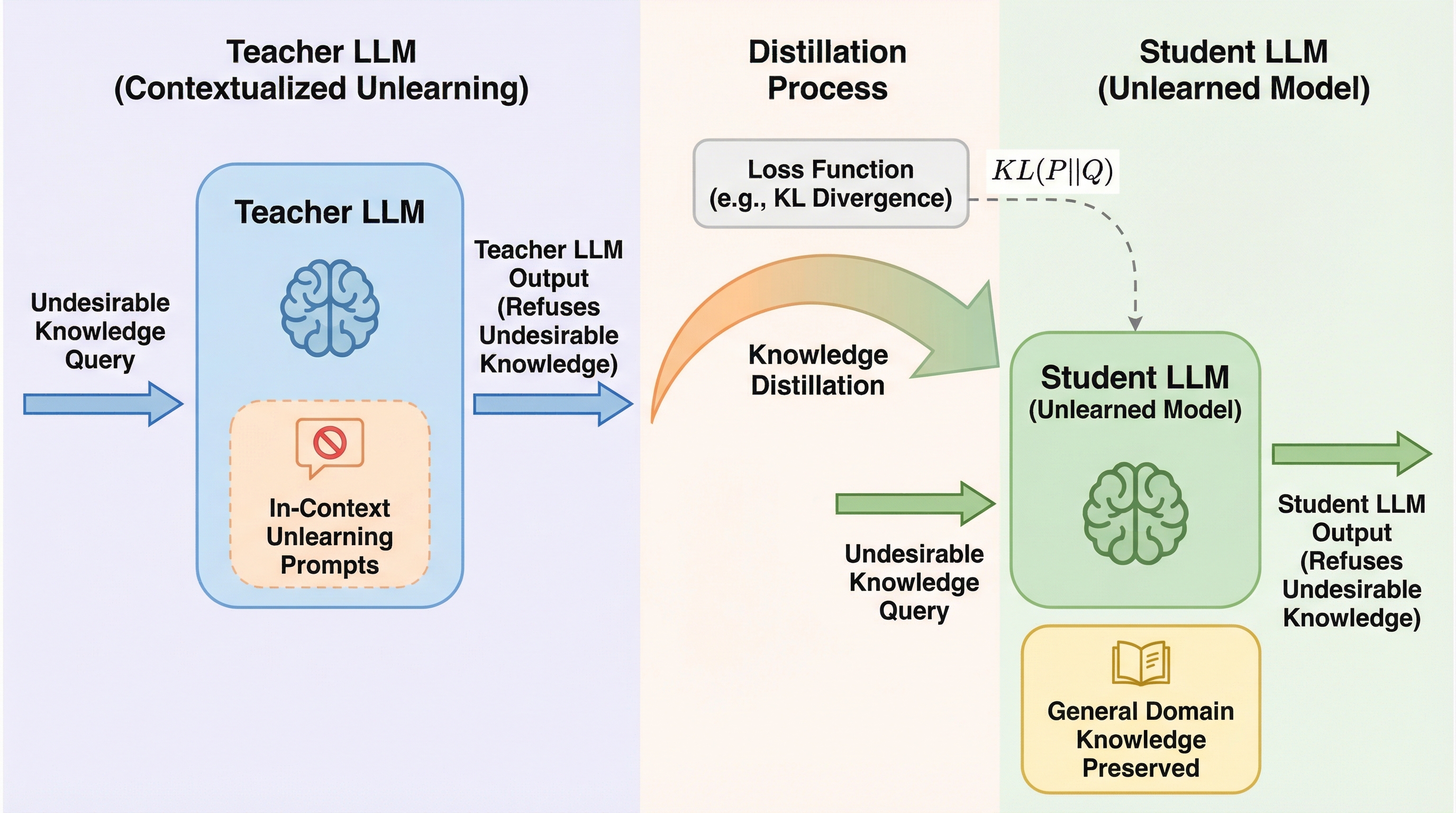
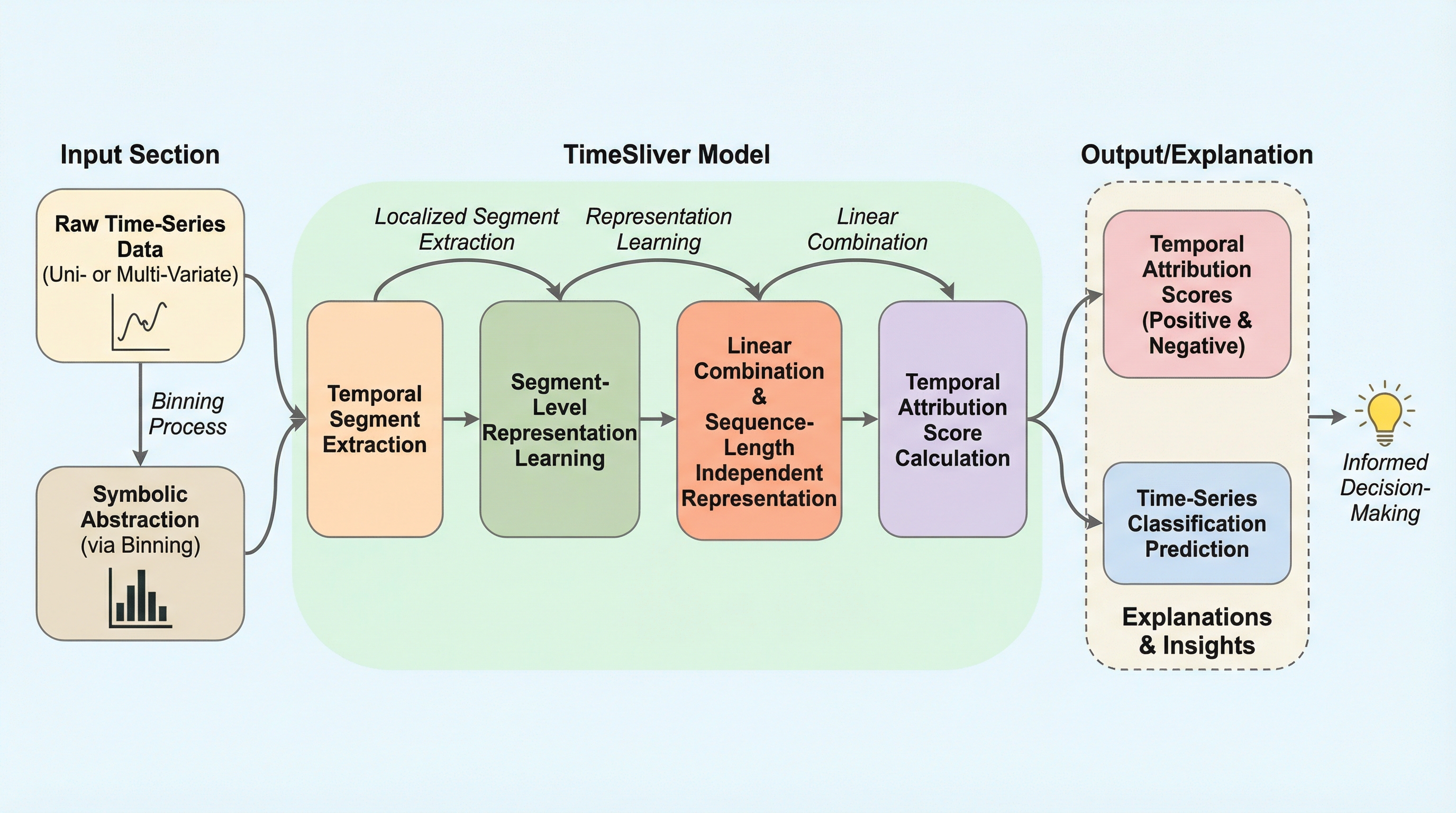
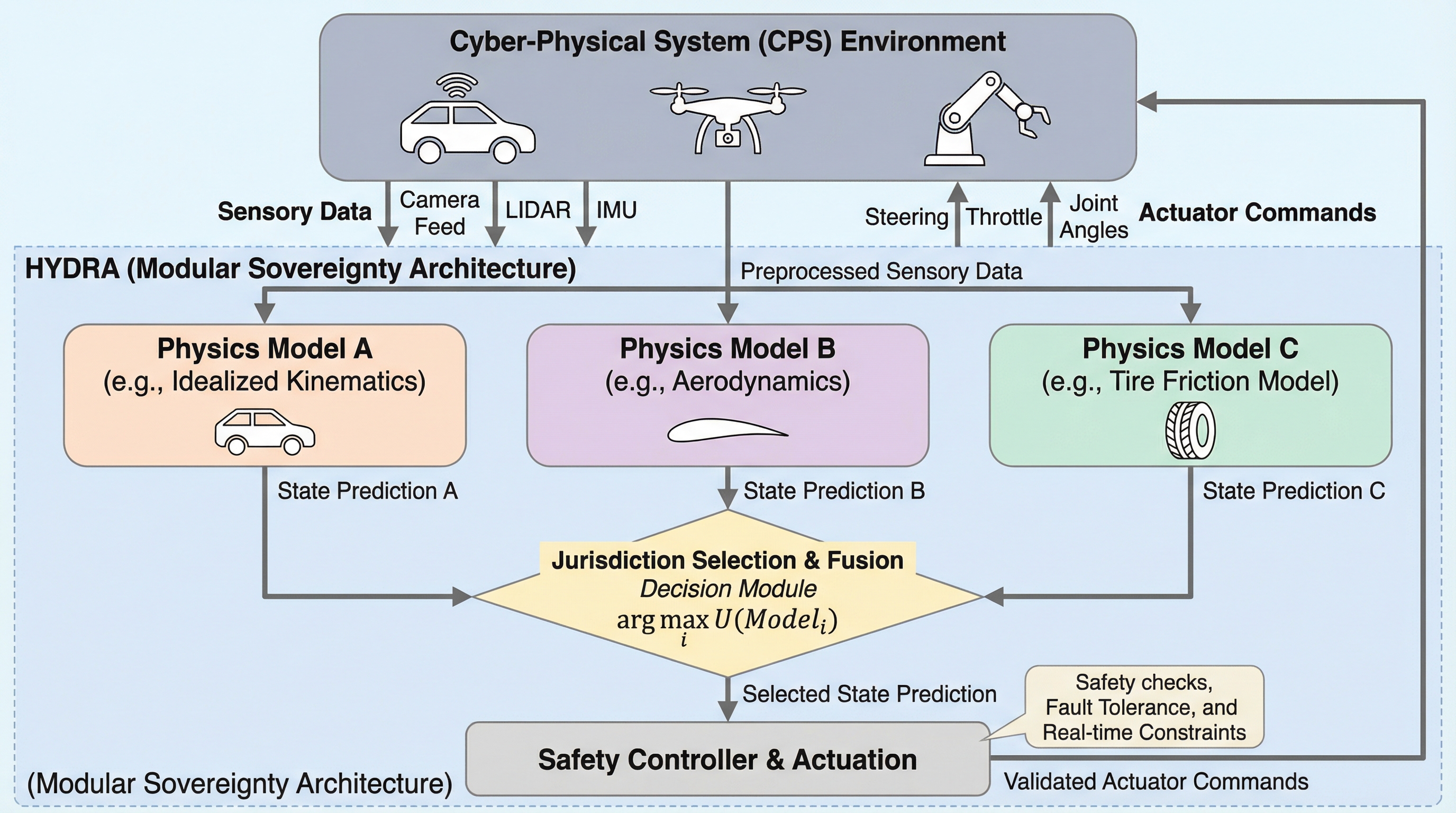
サイバー物理システム(CPS)において、従来の巨大なモノリシックモデルは新しい環境への適応と過去の知識の維持を両立できず、破滅的忘却や高周波の異常検知漏れを引き起こすという課題がある。 本論文は「モジュール型主権(Modular Sovereignty)」というパラダイムを提案し、特定の動作領域に特化した凍結済みの小型専門家モデル群(HYDRA)を、不確実性を考慮したガバナーによって統合する手法を提示する。 この枠組みは、物理的な不変条件を維持しつつ、各モジュールの独立した検証と監査を可能にすることで、安全性が重視されるシステムにおいて、物理的実体とデジタル表現の間の因果関係を保証する「状態の完全性」を実現する。