複数ソースの教師なしドメイン適応に向けた分布頑健な分類手法
本研究は、教師なしドメイン適応(UDA)において、標的ドメインのラベルなしデータが極端に不足している状況や、訓練データに「偽の相関」が含まれる場合に生じる性能低下を克服するための、革新的な分布頑健学習(DRO)フレームワークを提案している。
TL;DR(結論)
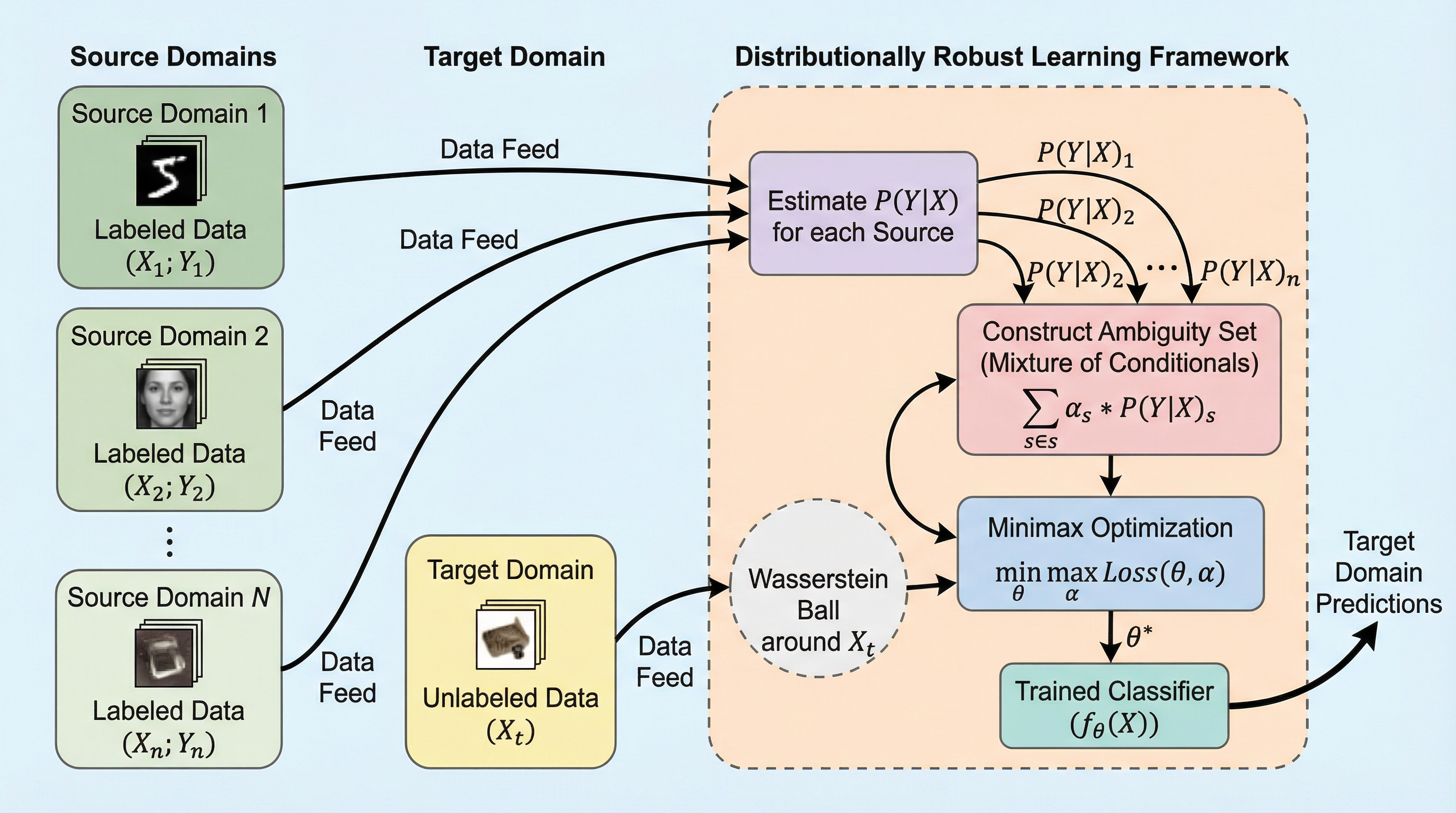
本研究は、教師なしドメイン適応(UDA)において、標的ドメインのラベルなしデータが極端に不足している状況や、訓練データに「偽の相関」が含まれる場合に生じる性能低下を克服するための、革新的な分布頑健学習(DRO)フレームワークを提案している。 具体的には、入力データの分布変動をワッサースタイン距離に基づく近傍集合で捉え、同時にラベルの条件付き分布を複数ソースの混合モデルとして表現することで、未知の環境変化に対して最悪のケースを想定した頑健な予測モデルを構築する手法を開発した。 この枠組みは、複数ソースの設定だけでなく単一ソースでも擬似ソース生成により適用可能であり、既存のUDA手法とシームレスに統合できる高い汎用性を持ち、特に標的データが極めて少ない過酷な条件下での有効性が実証された。
なぜこの問題か
機械学習モデルを実世界に適用する際、訓練時とテスト時でデータの統計的性質が変化する「分布シフト」は避けて通れない課題である。 従来の教師なしドメイン適応(UDA)は、ラベル付きのソースデータとラベルなしの標的データを活用してこの差異を埋めようとしてきたが、現実のシナリオでは二つの大きな壁に直面する。 一つ目は、標的ドメインのラベルなしデータが十分に得られない「データの希少性」である。 既存の分布整列手法や擬似ラベル手法は、標的データの統計量を正確に推定できることを前提としているため、サンプル数が少ないと推定が不安定になり、誤った知識の転送が行われてしまう。 二つ目は、ソースデータに含まれる「偽の相関」の問題である。 例えば、背景の色や特定の属性が特定のラベルと偶然強く結びついている場合、モデルは本来の分類根拠ではなく、これらの「近道(ショートカット)」を学習してしまう。 このような偽の相関は標的ドメインでは通用しないため、汎化性能が著しく低下する。 既存の手法は、これらの偽の相関を排除することが難しく、特に標的データが不足している場合にはその傾向が強まる。…
核心:何を提案したのか
本研究が提案する核心的な解決策は、分類タスクに特化した新しい分布頑健学習(DRO)のフレームワークである。 この手法の最大の特徴は、標的ドメインにおける不確実性を「入力分布(共変量分布)」と「条件付きラベル分布」の両面から同時にモデル化する「曖昧さ集合(Ambiguity Set)」を導入した点にある。 具体的には、標的ドメインの条件付き分布が、複数のソースドメインから得られた条件付き分布の混合として表現可能であると仮定する。 この混合比率を柔軟に変化させることで、モデルはどのソースの情報をどの程度信頼すべきかを動的に判断し、最悪のシナリオにおいても高い精度を維持できるよう設計されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related