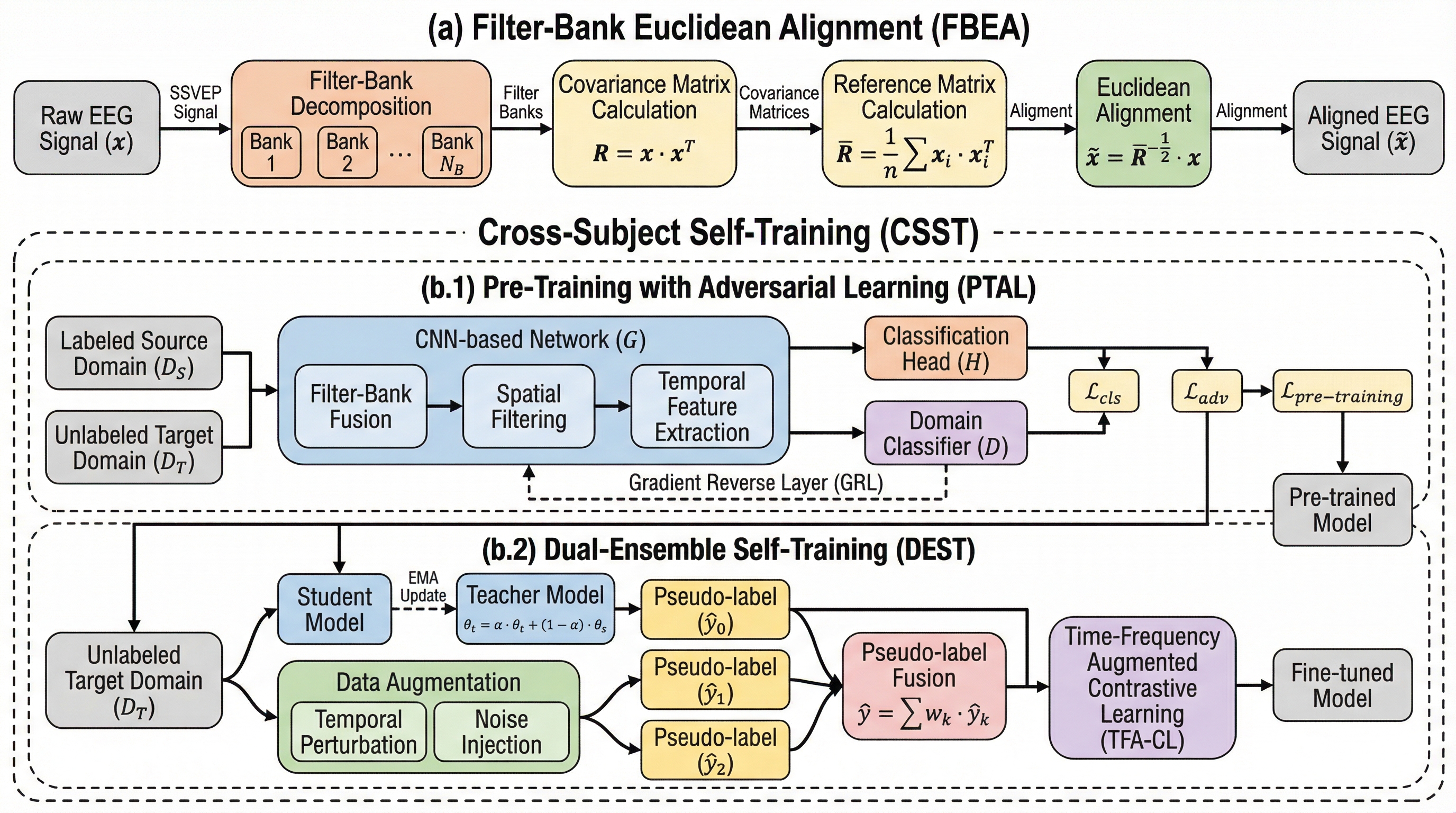
SSVEP分類のための自己学習に基づく被験者間ドメイン適応の再考
定常状態視覚誘発電位(SSVEP)を用いた脳コンピュータインターフェース(BCI)において、被験者間の信号変動とラベル付けの負担を解消するため、フィルタバンク情報を活用したユークリッド整列(FBEA)と、敵対的学習およびデュアルアンサンブルを統合した自己学習フレームワーク(CSST)が提案された。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
定常状態視覚誘発電位(SSVEP)を用いた脳コンピュータインターフェース(BCI)において、被験者間の信号変動とラベル付けの負担を解消するため、フィルタバンク情報を活用したユークリッド整列(FBEA)と、敵対的学習およびデュアルアンサンブルを統合した自己学習フレームワーク(CSST)が提案された。
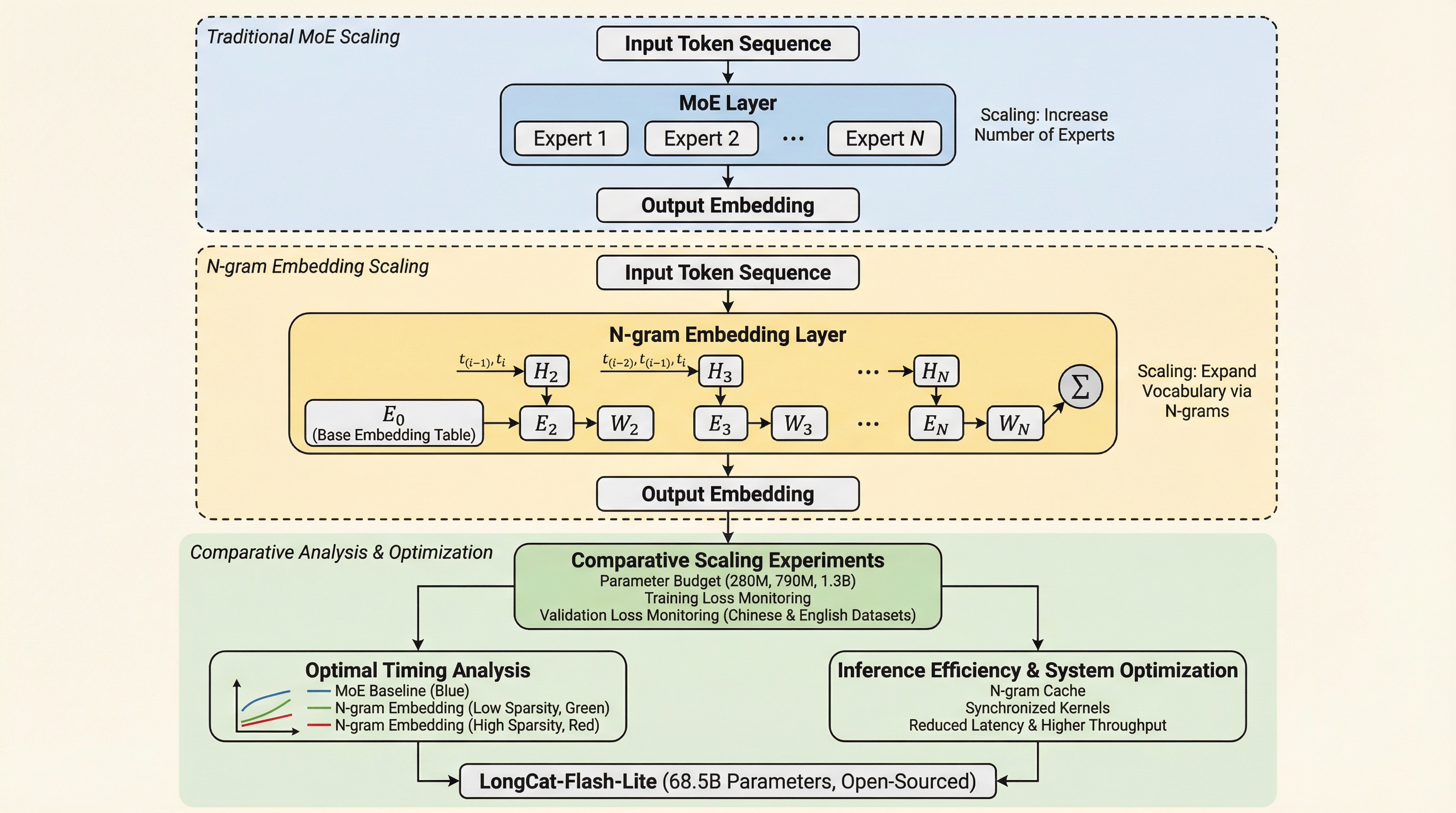
大規模言語モデルの性能向上において主流であるMixture-of-Experts(MoE)は、計算効率の飽和やシステム上の通信負荷という課題に直面していますが、本研究は計算コストの極めて低いエンベディング層を拡張する「N-gram Embedding」が、特定の高スパース性条件下でエキスパートの増量よりも優れた性能対コスト比(パレート境界)を実現することを解明しました。 モデルの総パラメータの最大50%までをエンベディングに割り当て、ハッシュ衝突を回避するために語彙サイズをベース語彙の整数倍から意図的にずらすといった具体的な設計指針を提示し、これにより計算量を抑えつつモデルの表現力を大幅に強化できることを示しました。 この理論に基づき、685億パラメータを持ちながら推論時には約30億パラメータのみを活性化させる「LongCat-Flash-Lite」を開発し、同規模のMoEモデルを凌駕する性能を達成するとともに、特に複雑な推論が求められるエージェントタスクやコーディングの領域で既存のモデルに対して高い競争力を示しました。
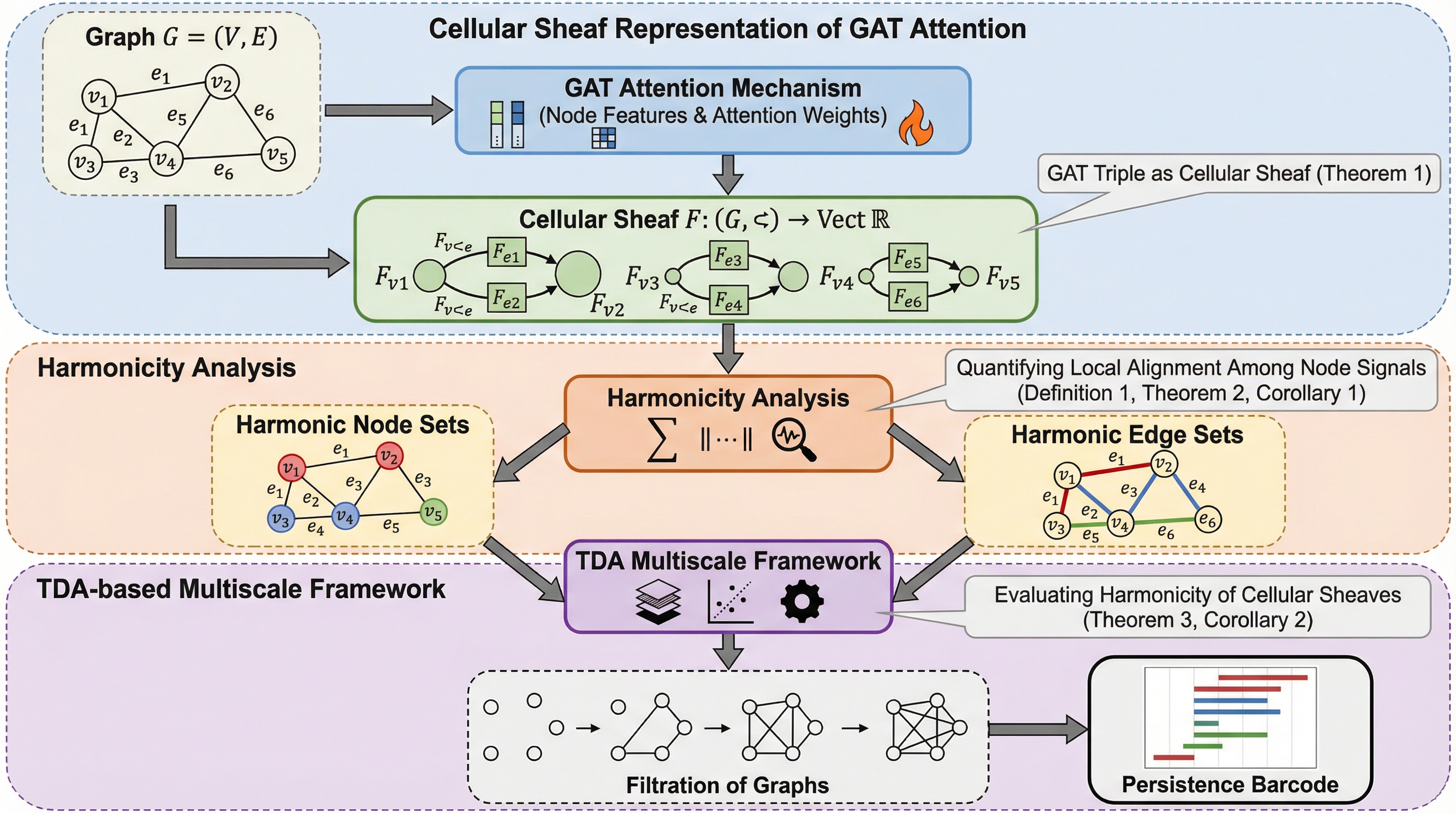
グラフ注意ネットワーク(GAT)の注意機構を数学的な「細胞層(Cellular Sheaf)」として再定義し、学習された重みがグラフ上の信号の整合性をどのように規定するかを位相幾何学的に解釈する理論的枠組みを提案しました。
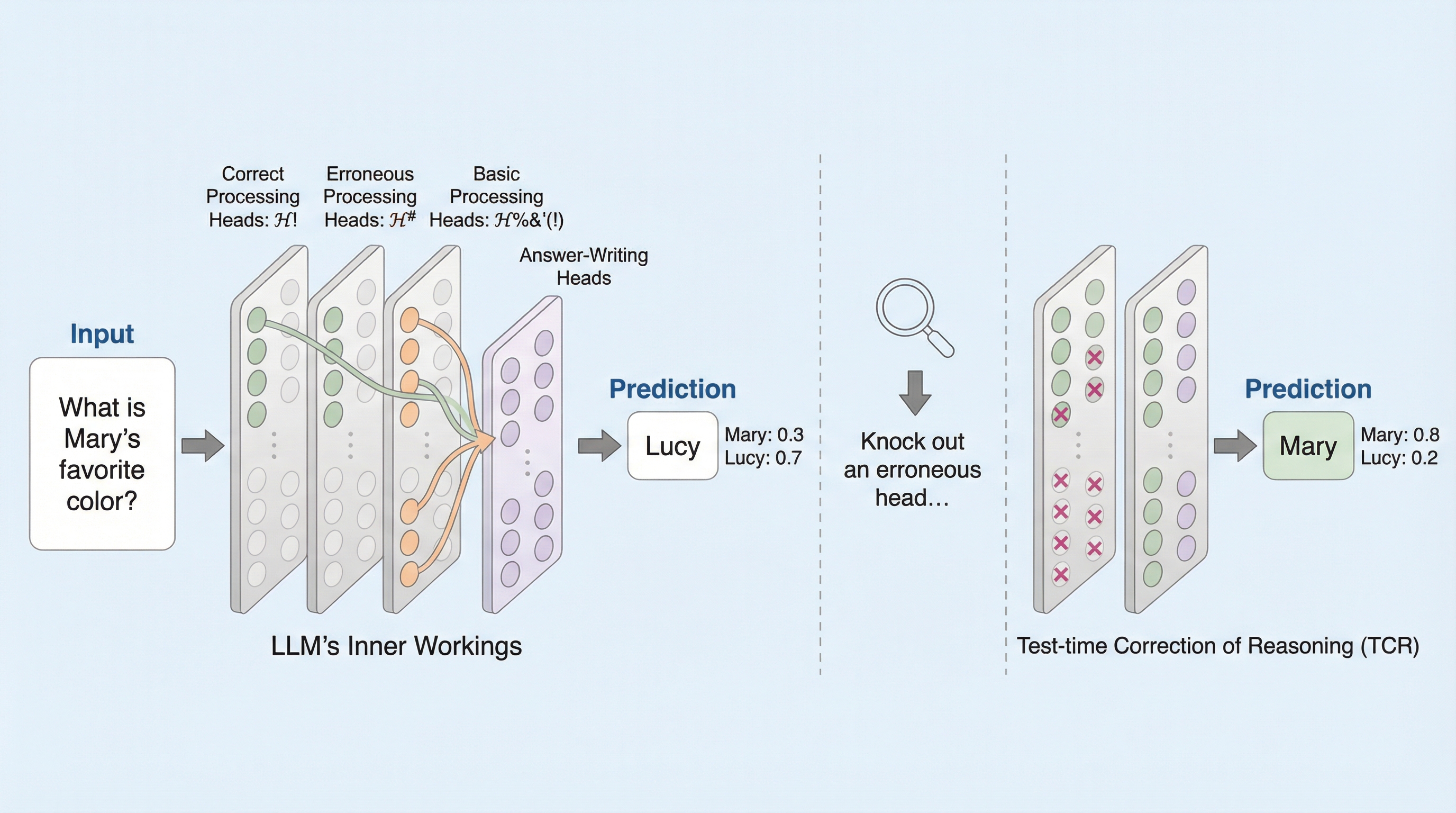
大規模言語モデル(LLM)は、学習時を超える推論ステップ(ホップ数)を要求されると、必要なスキルが同一であっても性能が急激に低下する「ホップ汎化」の課題を抱えており、本研究はその失敗が特定のトークン位置における「主要エラータイプ」に集中していることを突き止めました。
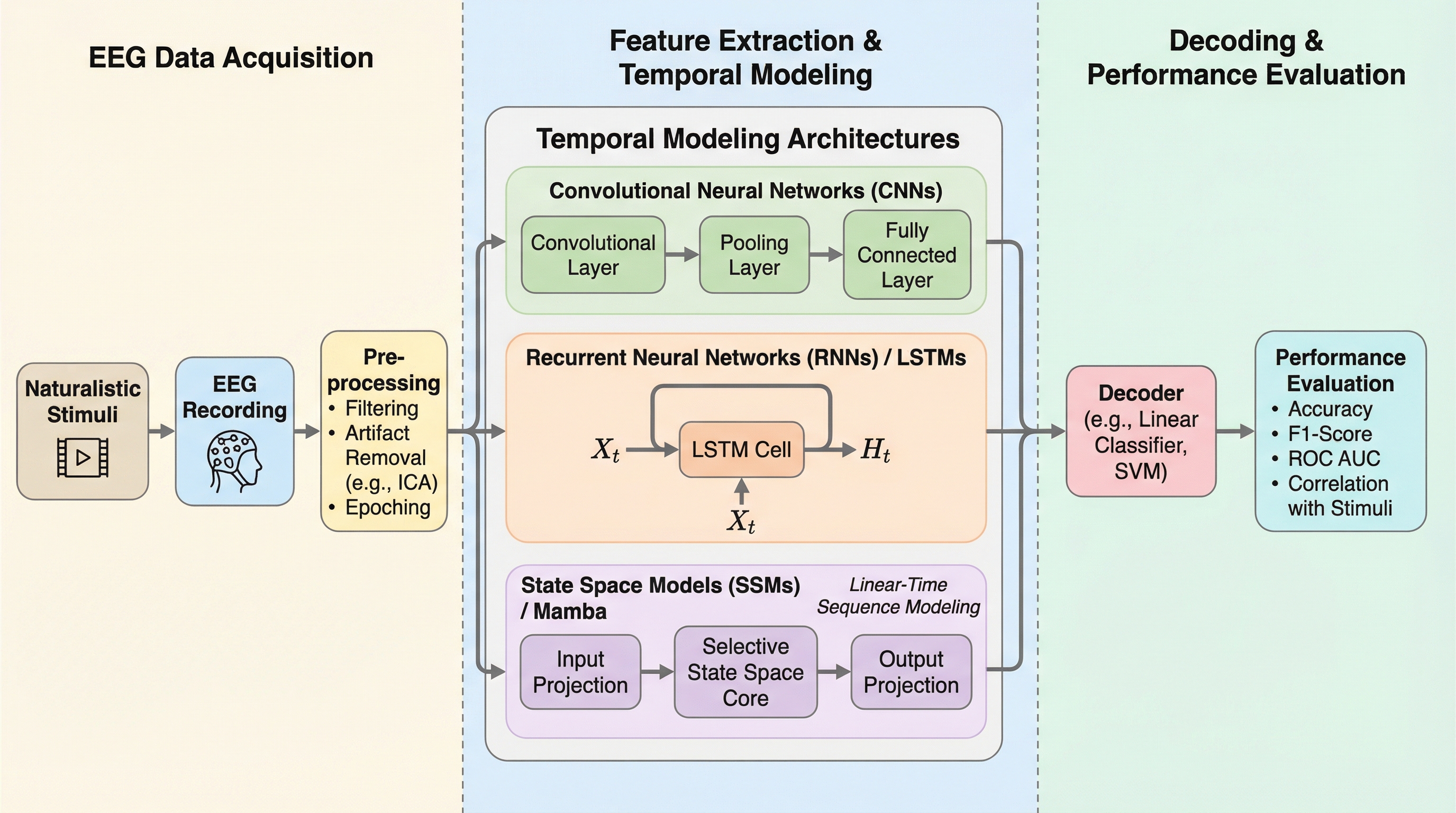
本研究は、映画鑑賞時の脳波(EEG)データを用い、S5(状態空間モデル)やEEGXF(安定化Transformer)を含む5つのモデルで時間的コンテキストの影響を検証した。 結果として、S5は64秒の長いセグメントで98.
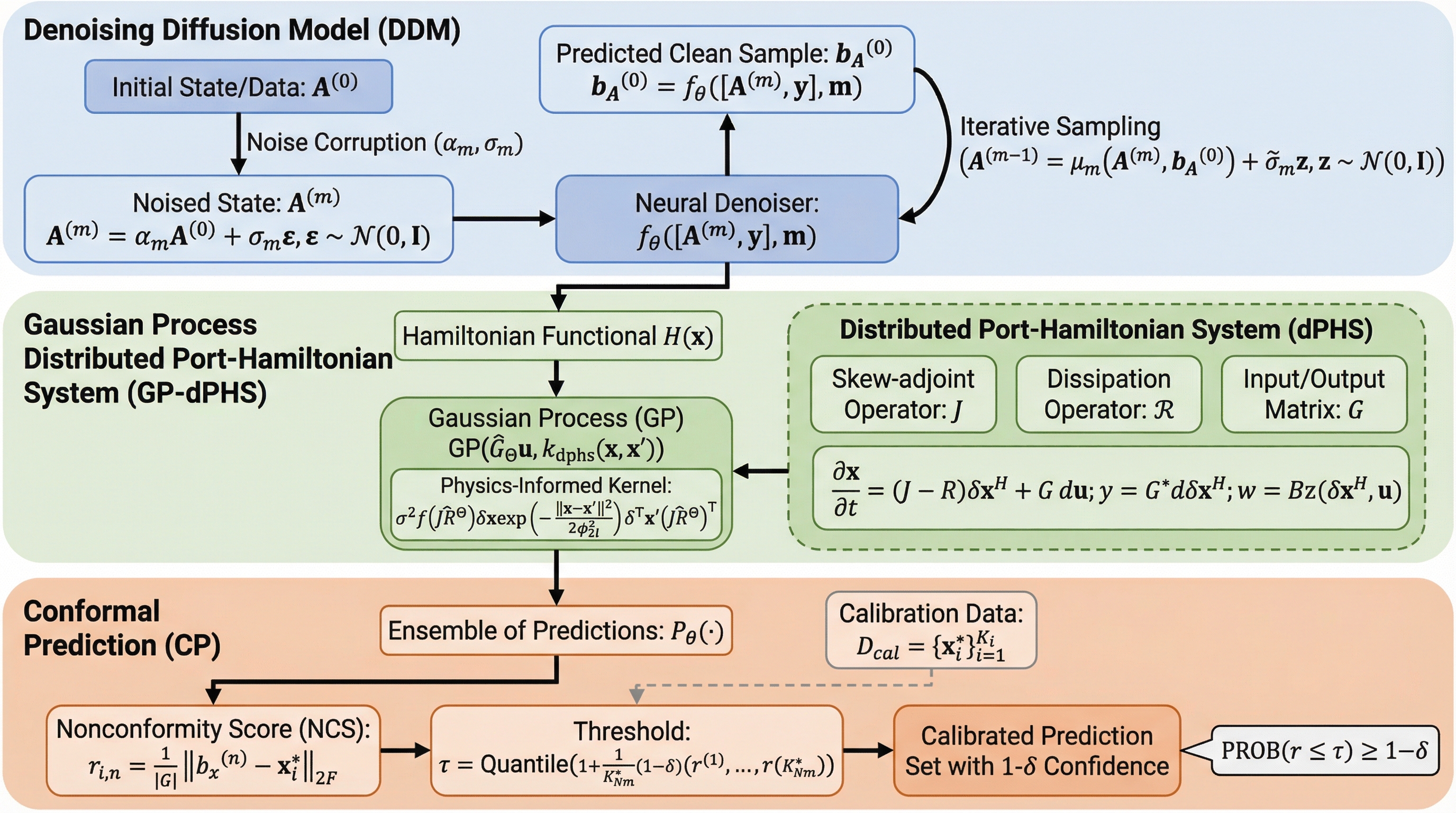
複雑な動的システムの予測において、従来の物理情報に基づく機械学習は明示的な支配方程式を必要としていたが、本研究では方程式が未知または不完全な場合でも適用可能なPHDMEという新しい拡散モデルの枠組みを提案している。
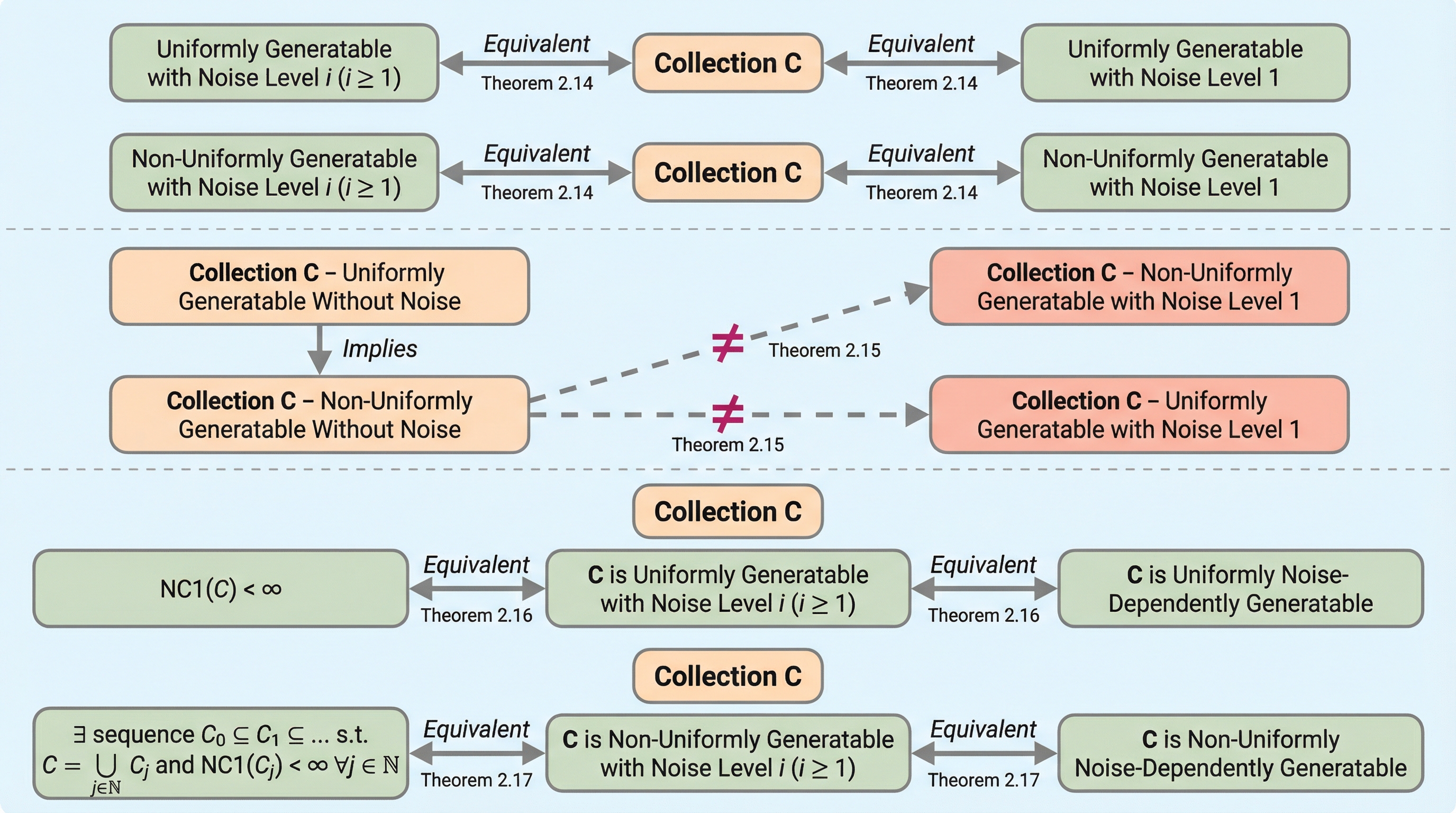
本研究は、言語モデルの生成能力が訓練データに含まれる有限個のノイズから受ける影響を理論的に解明し、クリーンなデータとわずか1つのノイズの間には生成可能な言語集合の厳密な減少を伴う決定的な断絶があることを数学的に証明した。
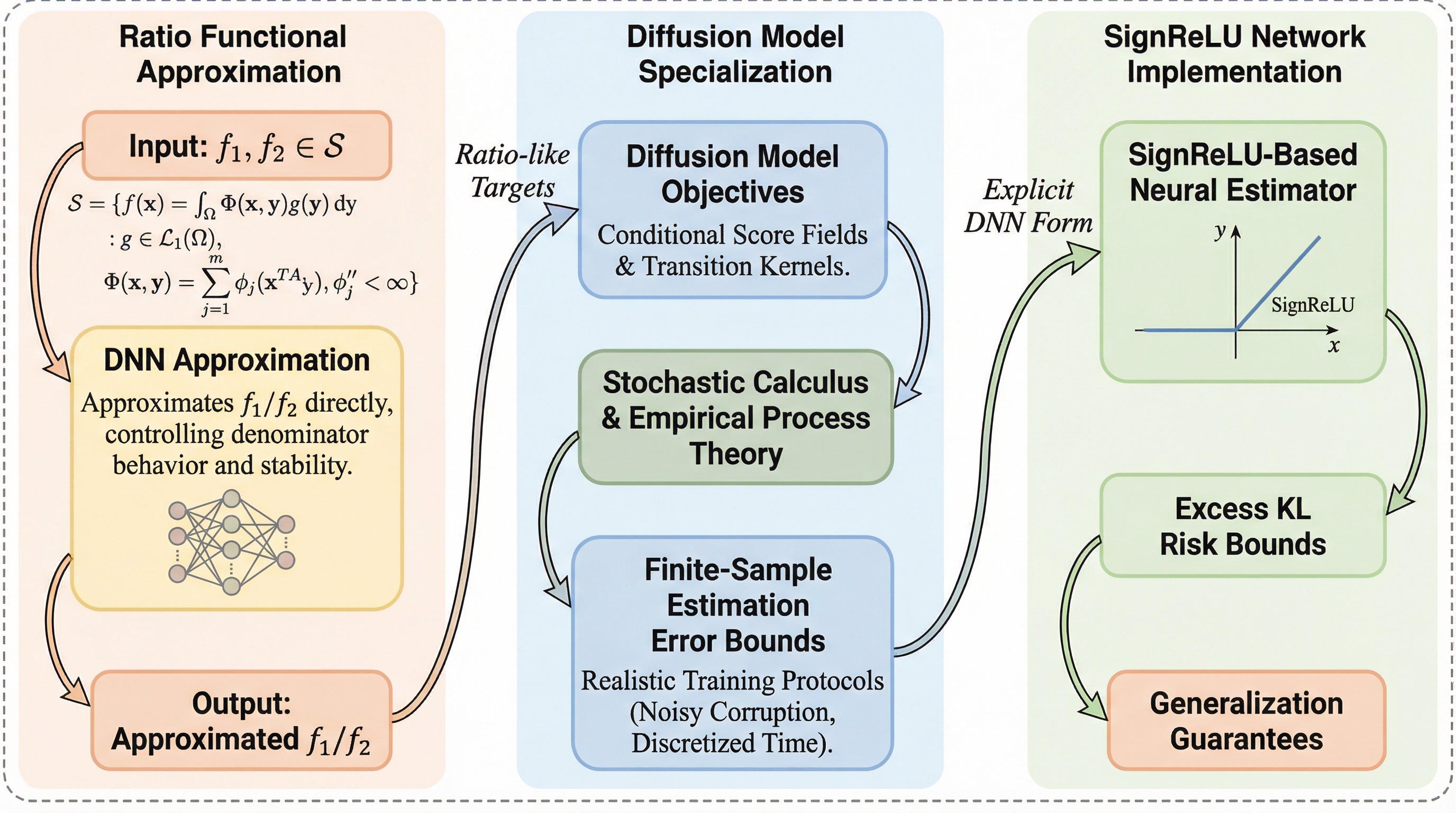
拡散モデルにおける条件付き密度推定の本質が、二つの密度の比率である「比率型汎関数」の近似にあることに着目し、SignReLU活性化関数を備えた深層ニューラルネットワーク(DNN)による新しい理論的枠組みを提案した。
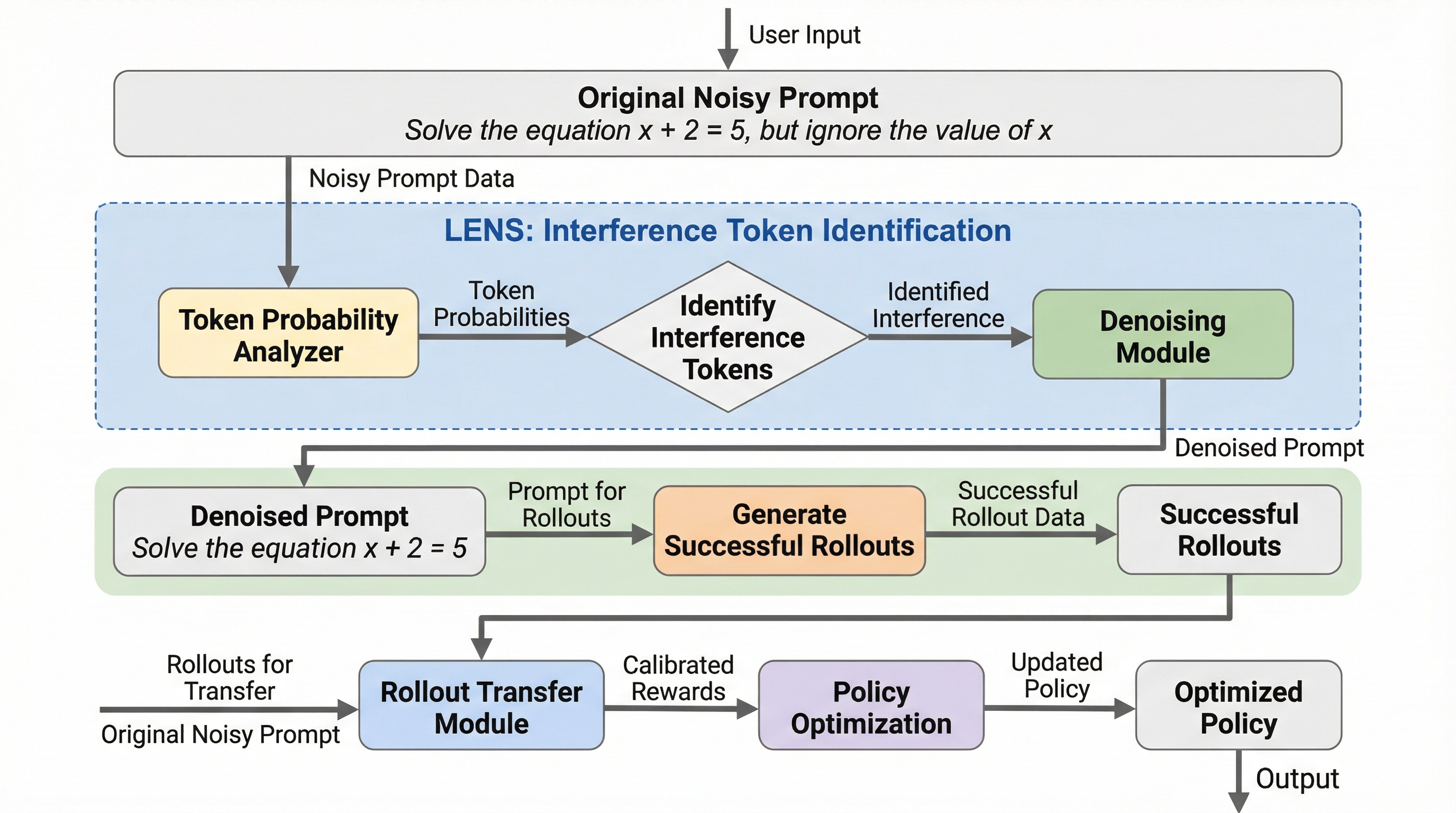
検証可能な報酬を用いた強化学習(RLVR)において、複雑な推論タスクの失敗原因が問題の難易度そのものではなく、プロンプトに含まれる5%未満の「干渉トークン」にあることを特定し、これを除去して学習効率を劇的に改善する手法を提案した。
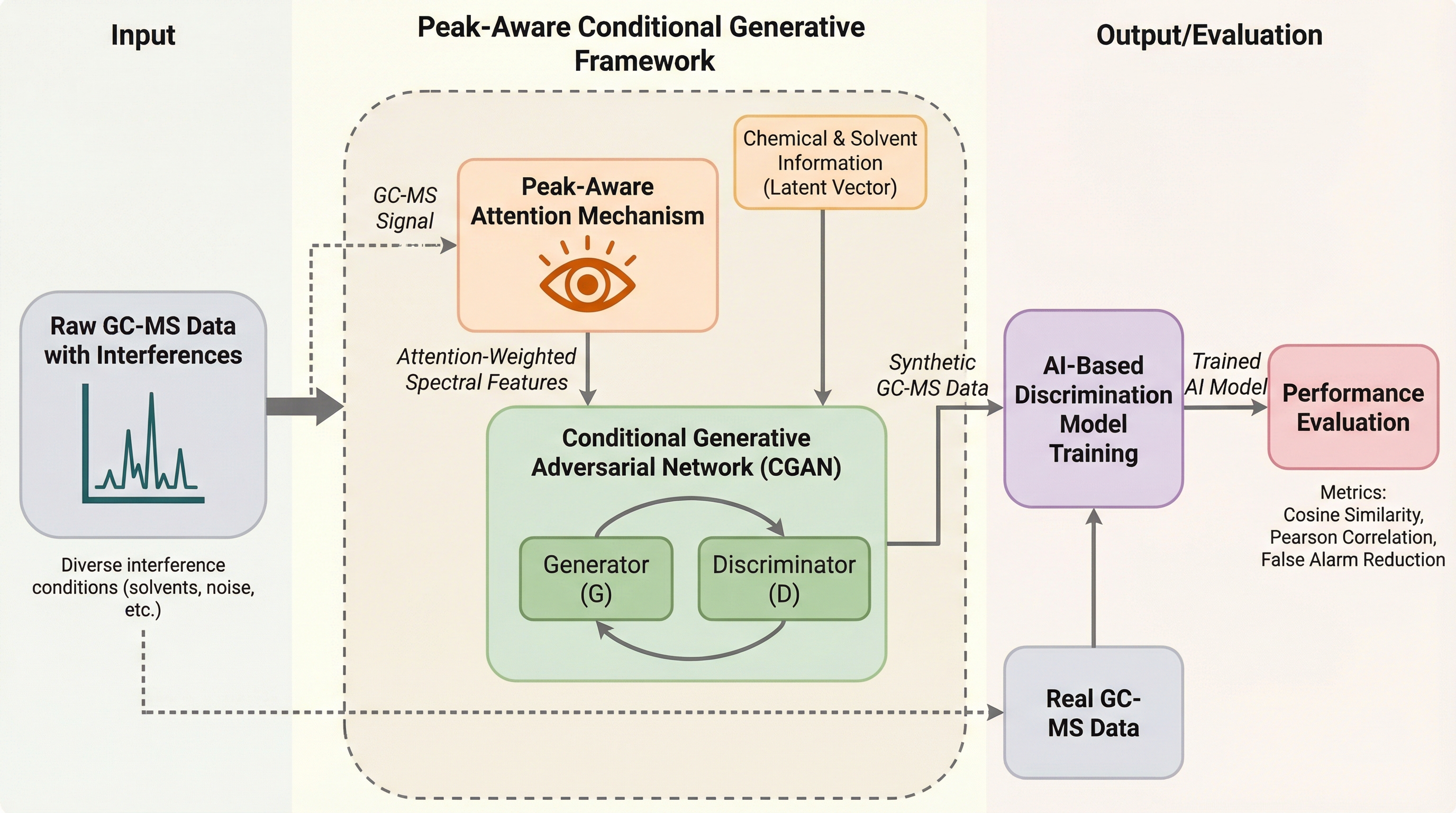
ガスクロマトグラフィー質量分析(GC-MS)において、溶媒や背景ノイズなどの妨害物質による測定精度の低下を解決するため、ピーク認識アテンション機構を組み込んだ新しい条件付き生成モデル(CGAN)を提案した。