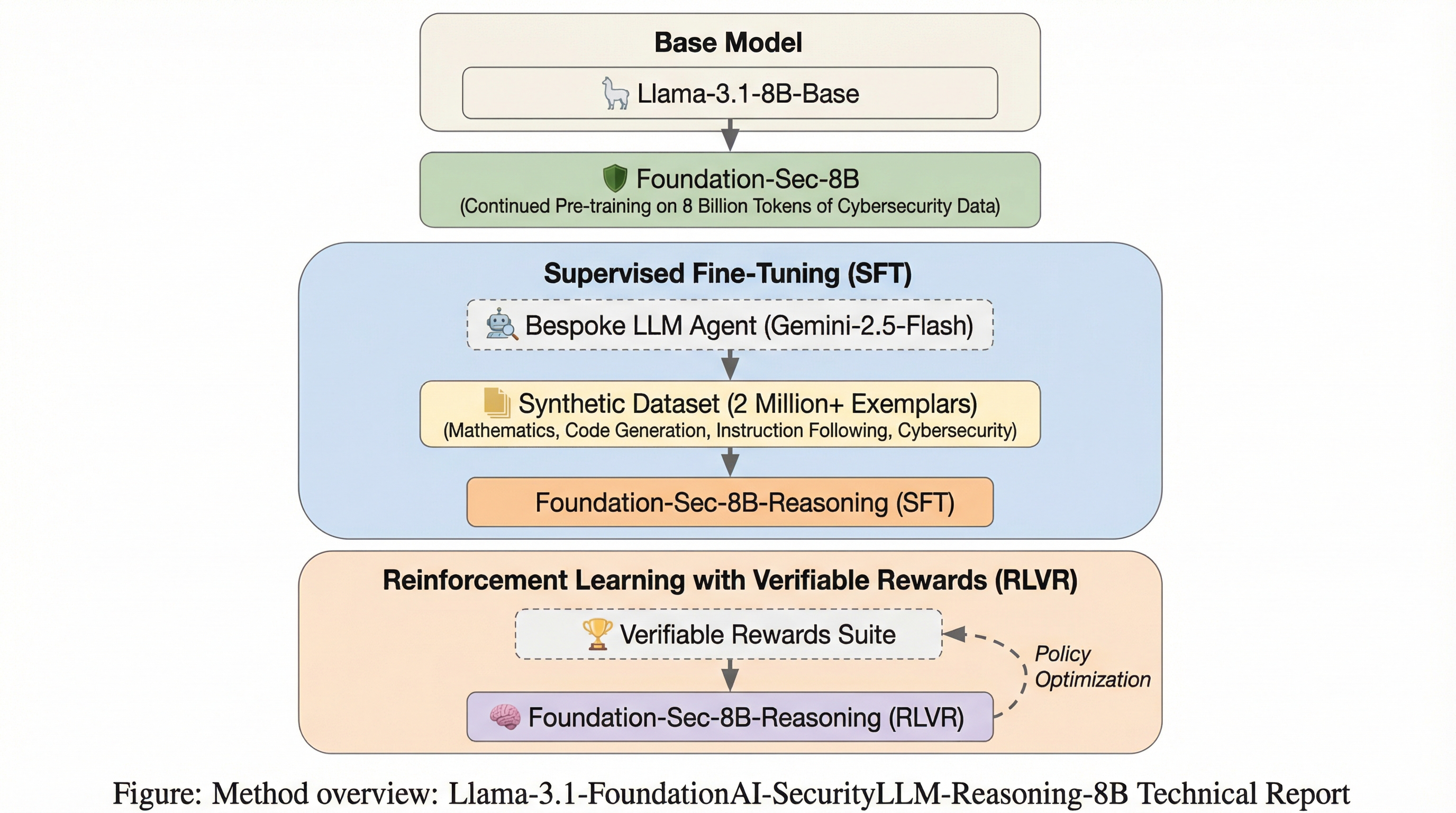
Llama-3.1-FoundationAI-SecurityLLM-Reasoning-8B 技術報告書
Foundation-Sec-8B-Reasoningは、Llama-3.1-8Bを基盤として開発された、サイバーセキュリティ分野で初となるオープンソースのネイティブ推論モデルであり、複雑なセキュリティ分析において「思考」プロセスを明示する能力を備えている。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
Foundation-Sec-8B-Reasoningは、Llama-3.1-8Bを基盤として開発された、サイバーセキュリティ分野で初となるオープンソースのネイティブ推論モデルであり、複雑なセキュリティ分析において「思考」プロセスを明示する能力を備えている。
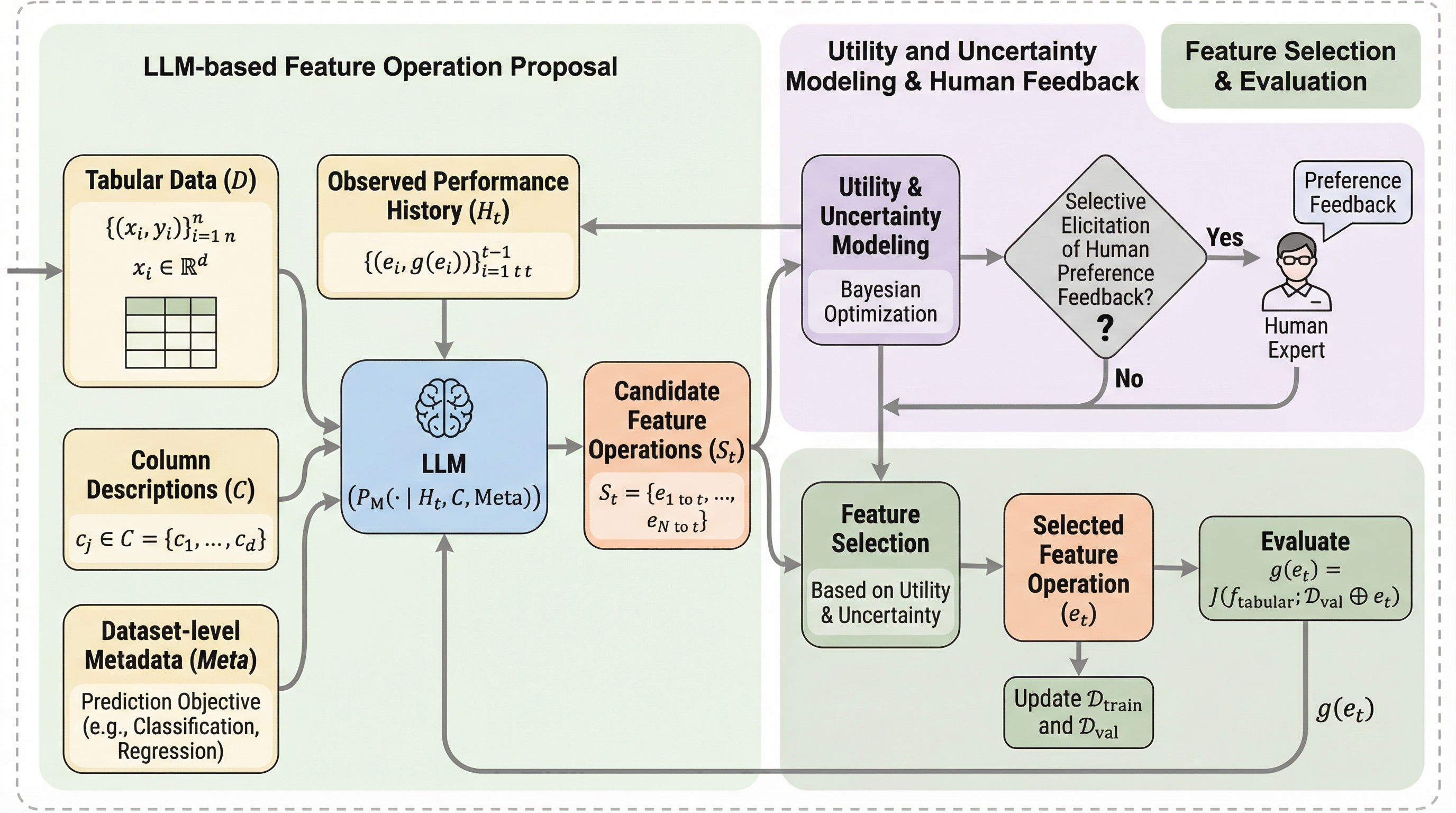
大規模言語モデルを特徴量候補の提案役に特化させ、その選択プロセスをベイズ最適化に基づく効用モデルと分離することで、モデルの内部的な直感に頼った非効率な探索を排除し、低収益な操作の繰り返しを抑制する新しいフレームワークを提案した。
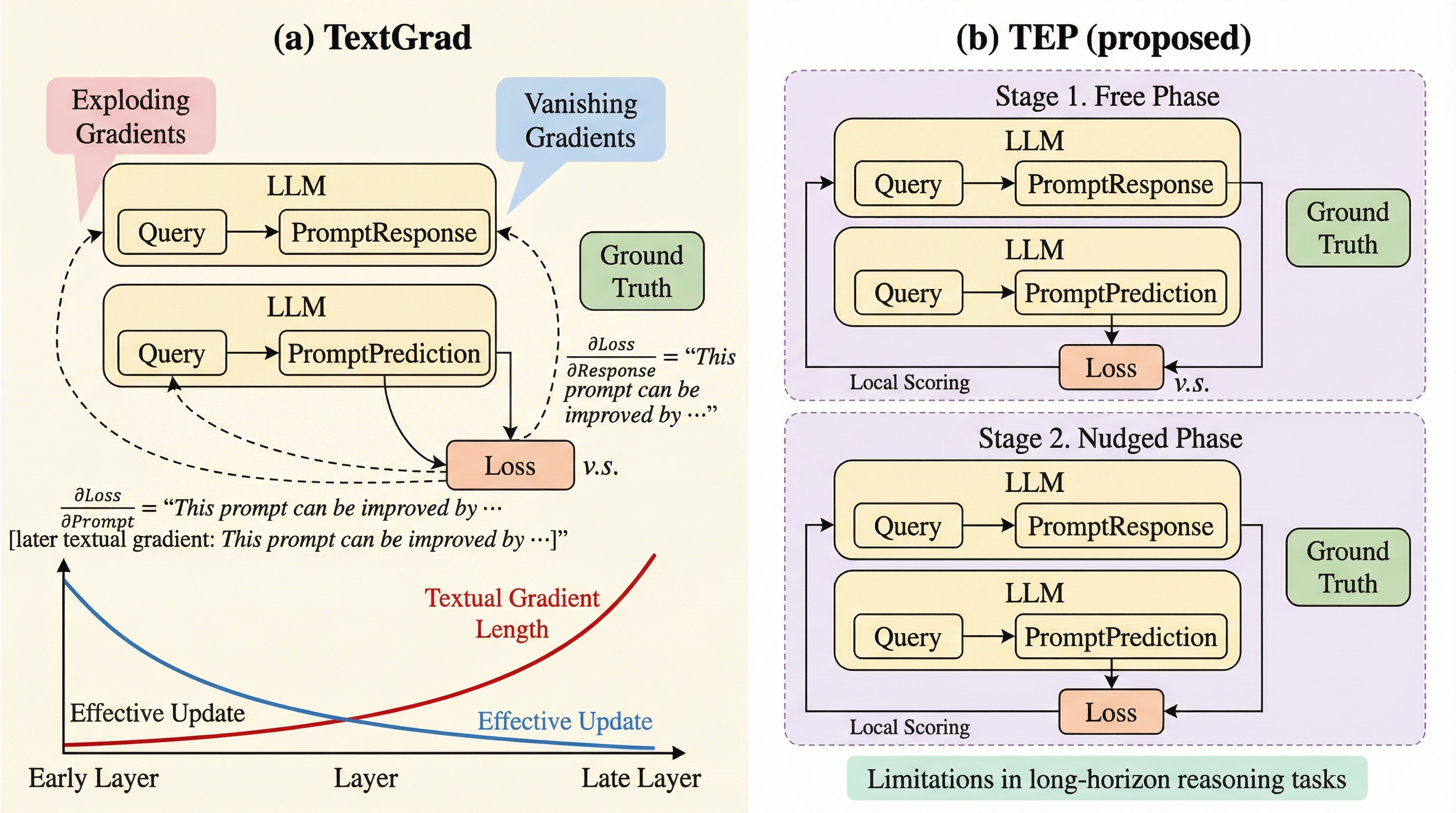
大規模言語モデル(LLM)やツールを組み合わせた複合AIシステムが深層化するにつれ、従来のグローバルなテキストフィードバック手法では、情報の爆発によるコンテキスト超過や、情報の消失による具体性の欠如という深刻な課題に直面しています。
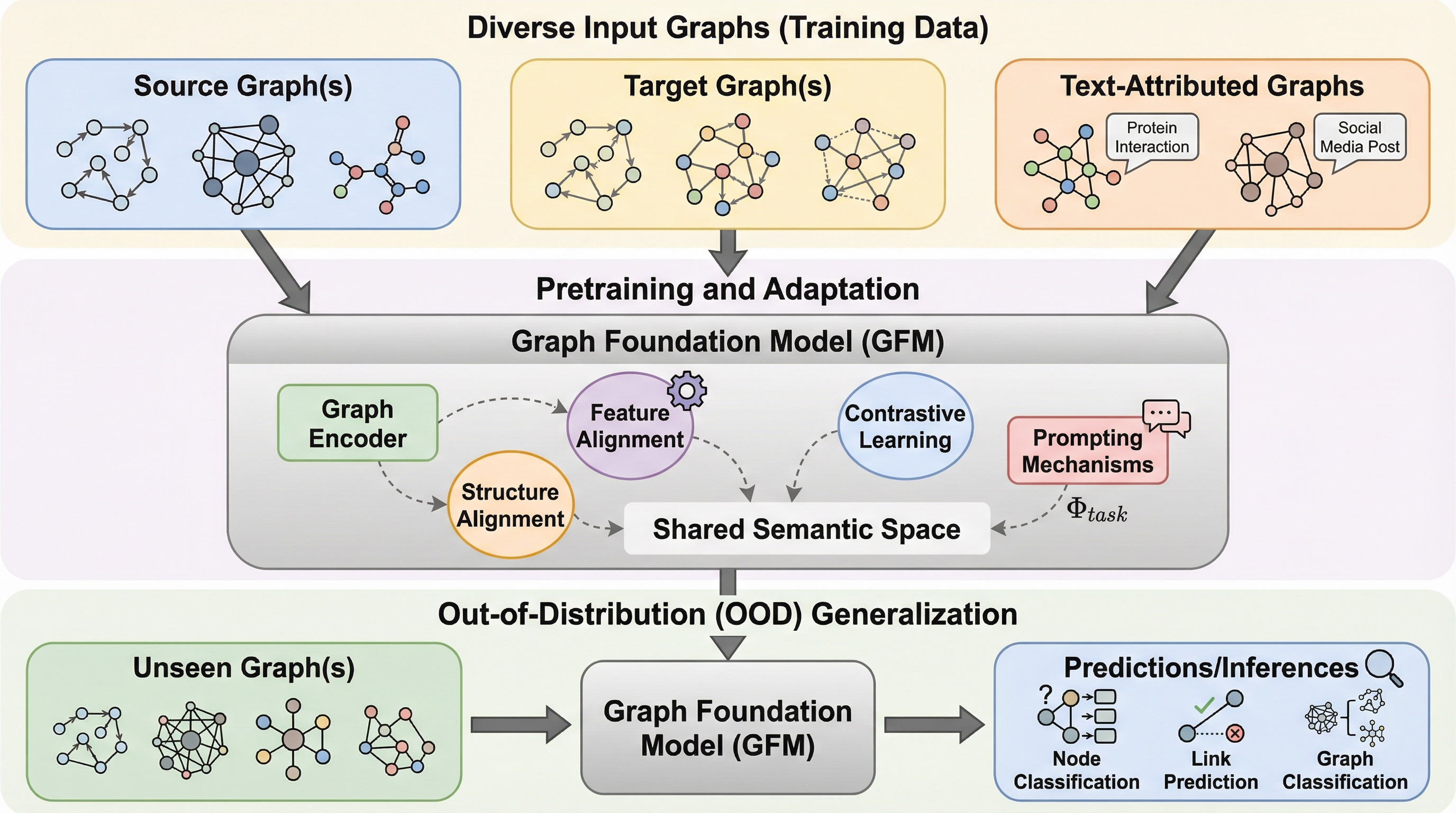
グラフ基盤モデル(GFM)は、多様なグラフデータから汎用的な表現を学習し、未知のデータ分布(分布外、OOD)に対しても高い適応力を発揮することを目指す新しいパラダイムであり、本論文はその最新動向を「分布外汎化」の観点から整理した初の包括的サーベイである。
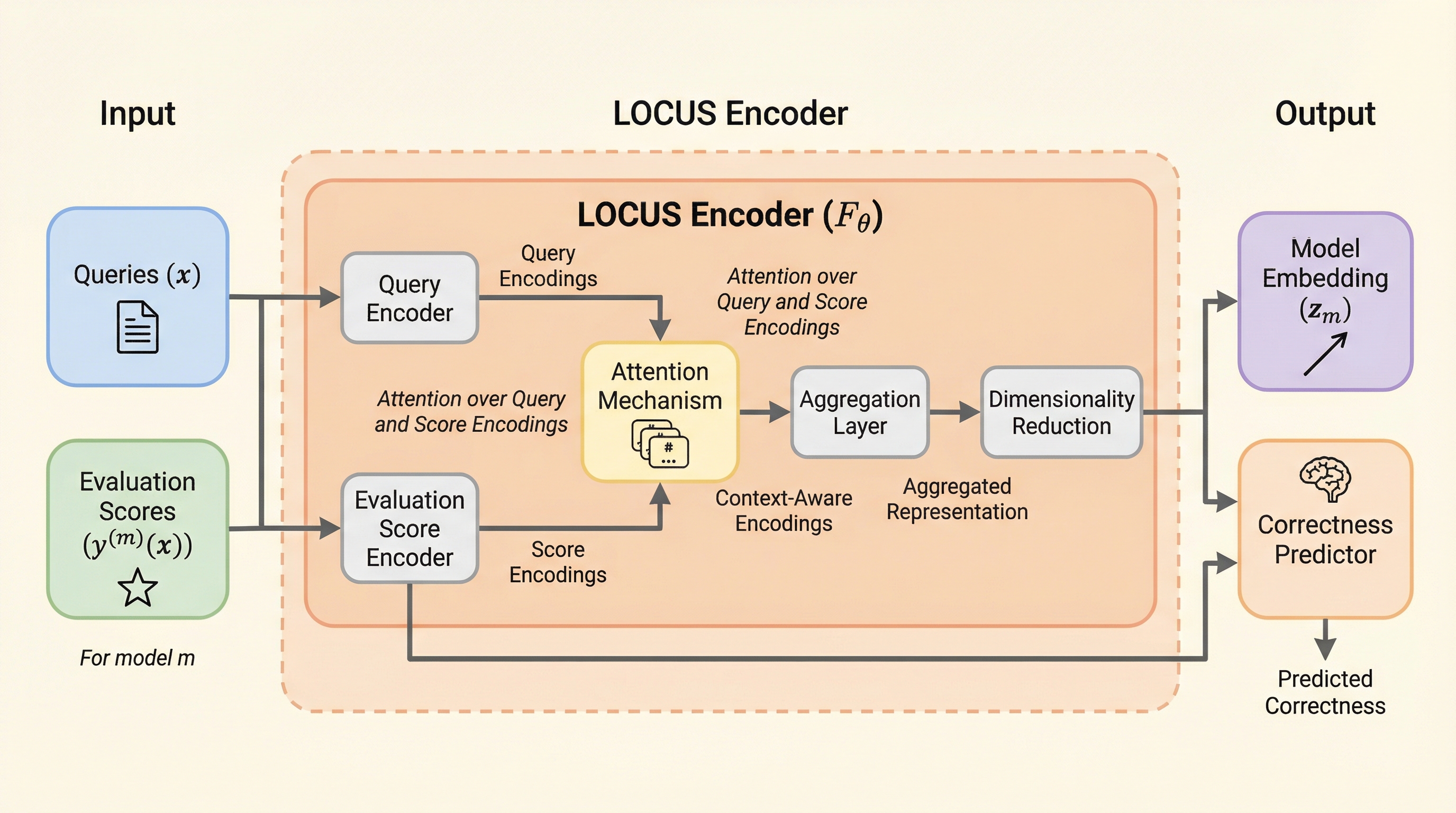
LOCUSは、大規模言語モデル(LLM)の多様な能力をアテンション機構によって低次元のベクトル(モデル埋め込み)として表現する新しい手法であり、モデルの比較や選択、クエリルーティングを大幅に効率化する。
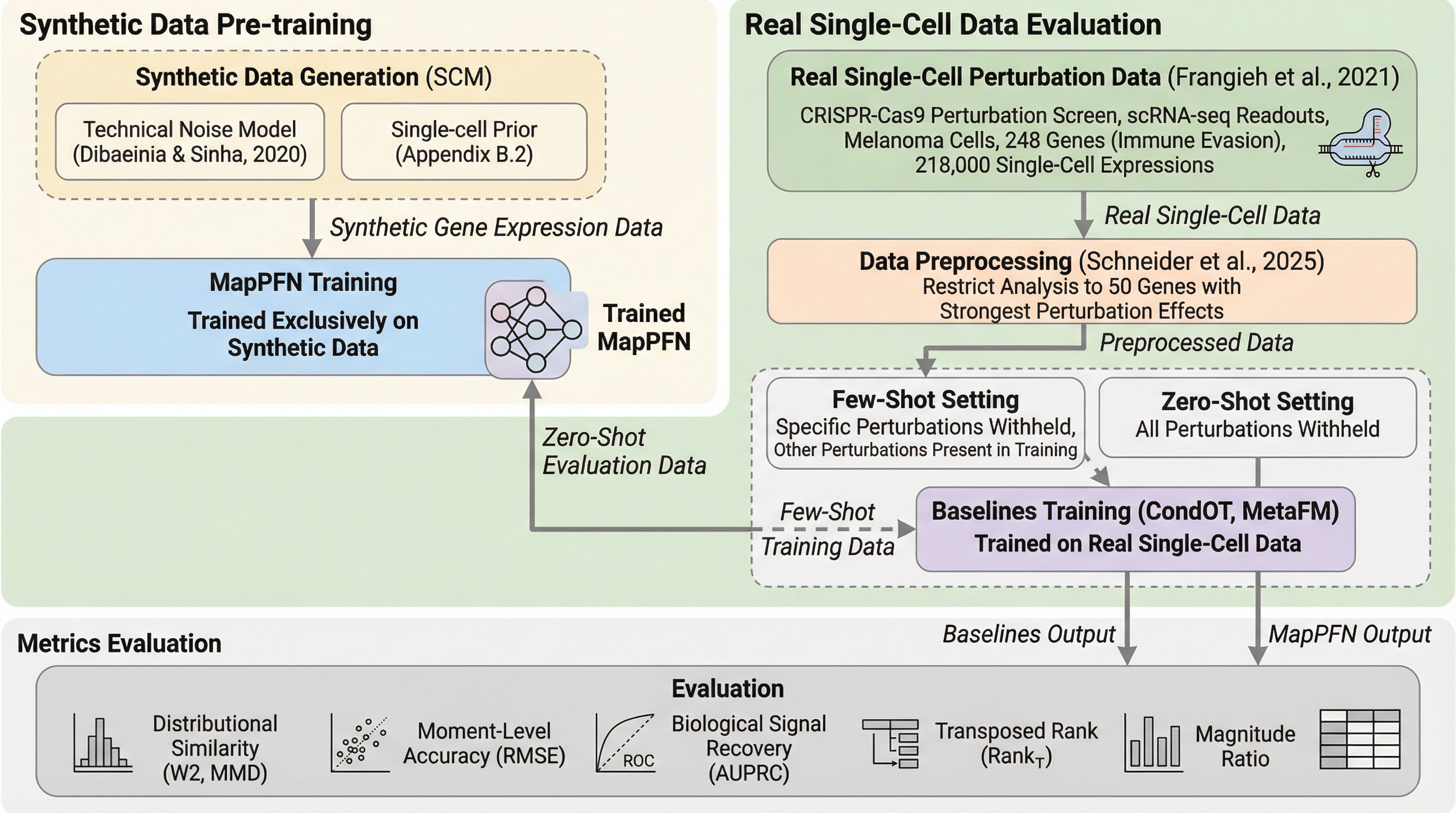
MapPFNは、未知の生物学的コンテキストにおける遺伝子摂動の影響を予測するために、インコンテキスト学習を活用する新しい事前データ適合ネットワーク(PFN)です。このモデルは、勾配ベースの最適化を必要とせず、少数の実験結果をコンテキストとして取り込むことで、新しい介入後の細胞状態の分布を即座に推論する能力を持っています。 合成データのみを用いた事前学習を行っているにもかかわらず、実世界の単一細胞データにおいて差分的発現遺伝子を特定する性能は、実際のデータで学習された既存のモデルに匹敵する水準に達しています。これにより、高コストな実験を削減し、創薬ターゲットの発見を加速させる仮想細胞モデルとしての活用が期待されます。 マルチモーダル拡散トランスフォーマー(MMDiT)アーキテクチャを採用し、細胞をトークンとして扱うことで、事前分布と介入後の分布の間の複雑な写像を学習することに成功しています。特に、複数の介入結果を条件として与えることで予測精度が向上し、従来のモデルが抱えていた、新しい環境への適応能力の欠如という課題を克服しています。
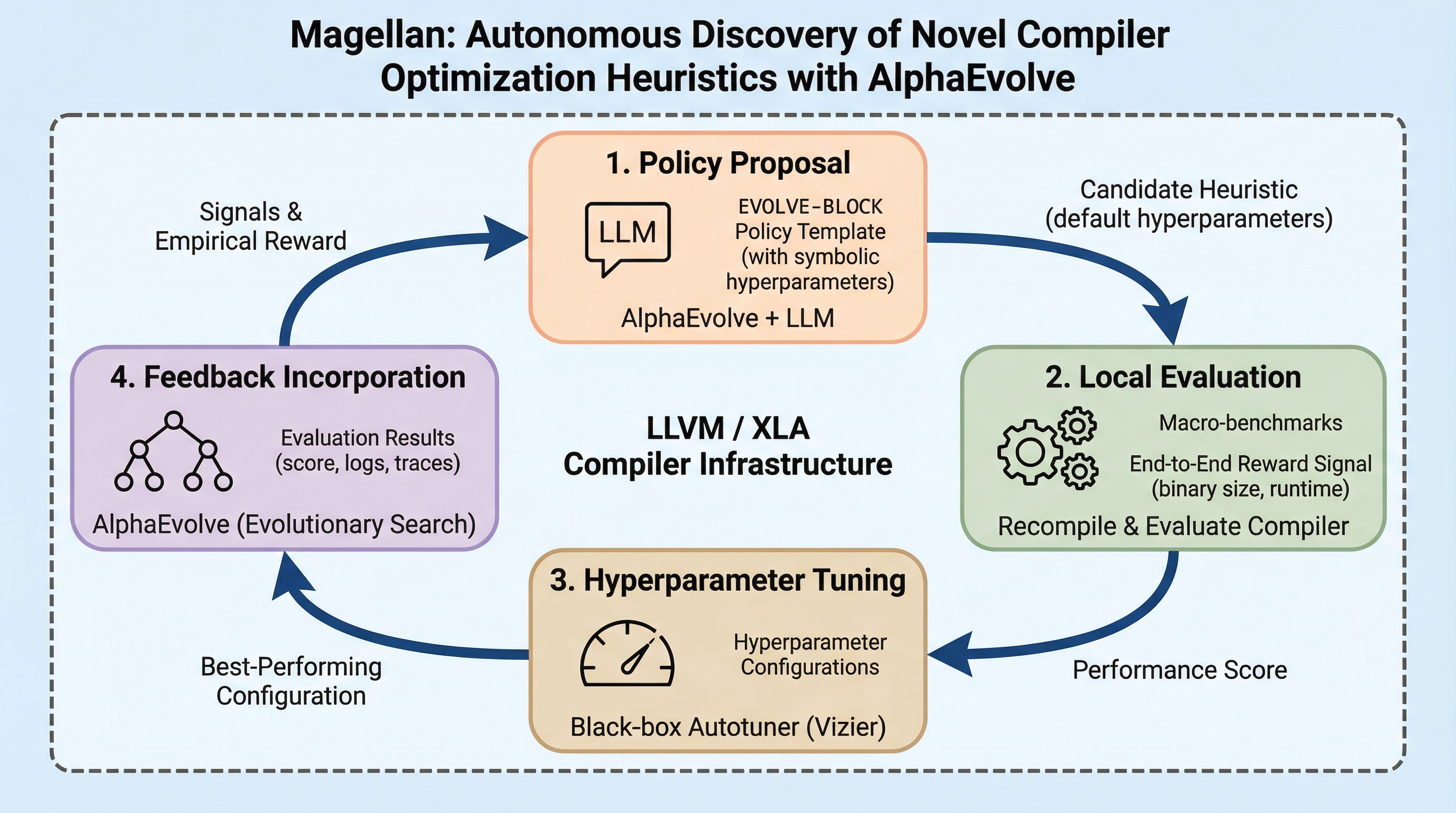
Magellanは、大規模言語モデル(LLM)と進化的探索、自動チューニングを組み合わせることで、コンパイラの最適化パスを制御するC++の意思決定ロジックを自律的に生成するエージェント型フレームワークである。 LLVMの関数インライニングにおいて、数十年にわたる手動エンジニアリングを凌駕する5.
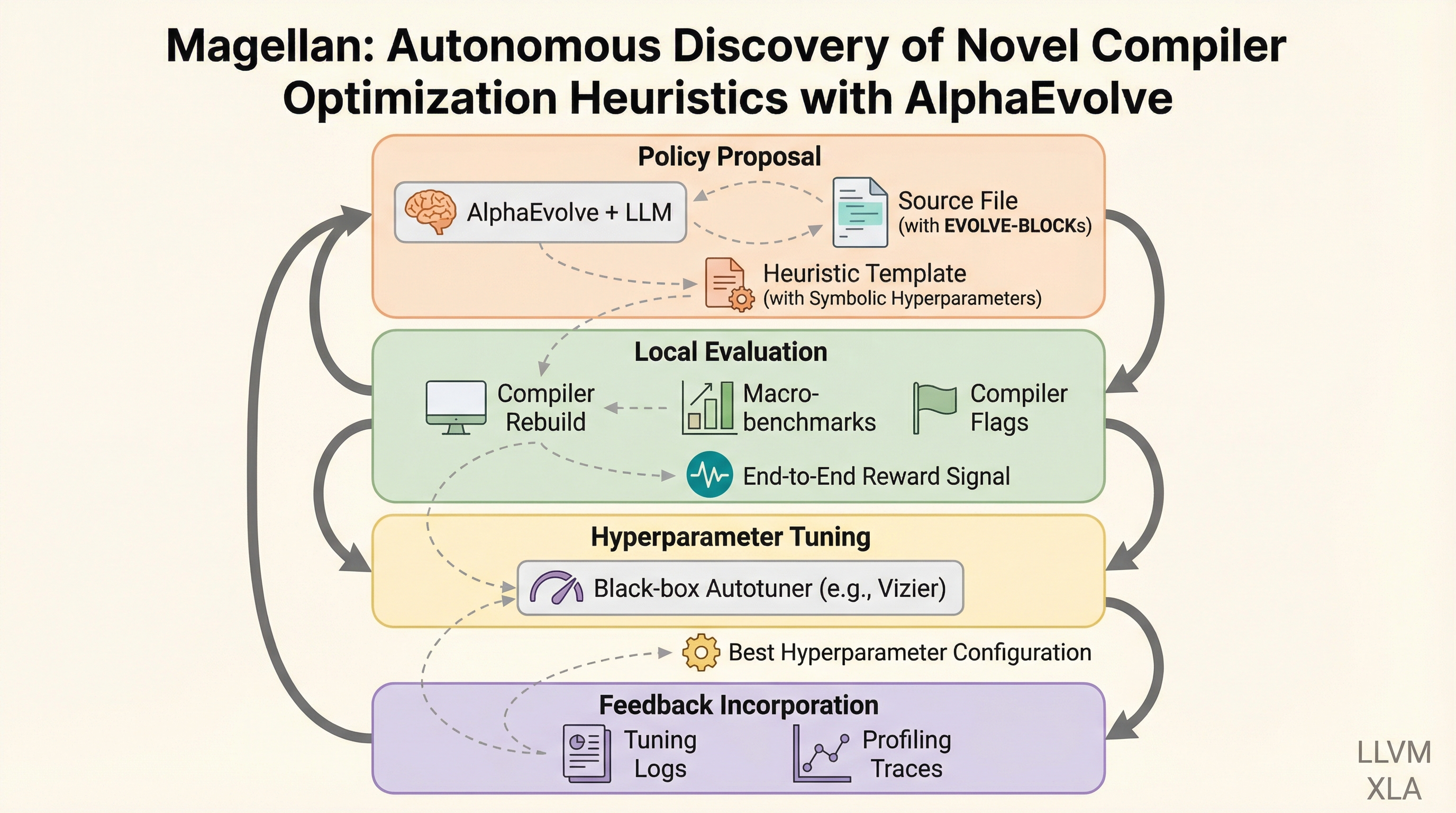
現代のコンパイラが依存する手動設計のヒューリスティクスは、複雑なソフトウェアや多様なハードウェアへの適応が困難で保守負担も大きいという課題がありますが、本研究ではLLMと進化探索、自動チューニングを組み合わせたエージェント型フレームワーク「Magellan」を提案し、実行可能なC++の決定ロジックを直接合成することでこの問題を解決します。 LLVMの関数インライニングにおいて、Magellanは数十年にわたる専門家の手動設計を上回る新しいヒューリスティクスを合成し、バイナリサイズの削減率で5.23%の向上を達成したほか、生成されたコードは手動実装の約15分の1という極めて簡潔な記述でありながら、既存のコンパイラに直接統合して運用できる高い実用性を備えていることが確認されました。 この手法はレジスタ割り当てやXLAなどの異なる最適化タスクやコンパイラ基盤にも適用可能であり、特定のベンチマークへの過学習を避けつつ、時間の経過や異なるアプリケーション領域に対しても高い汎用性を示すことが実証されており、ニューラルネットワークを直接コンパイラに組み込む手法に代わる、保守性と性能を両立した新しい自動設計の道を切り拓いています。
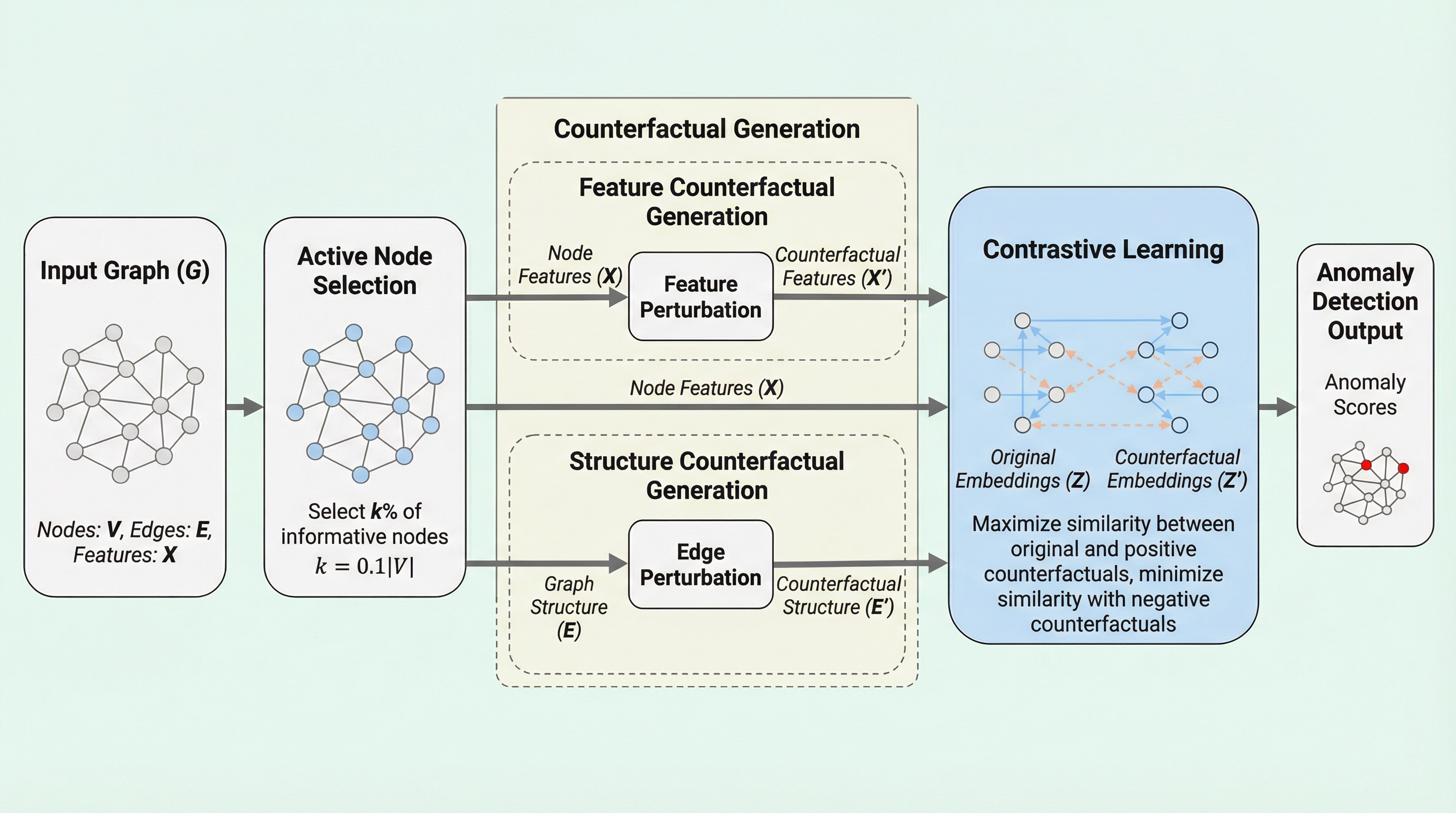
グラフ異常検知におけるラベル不足と深刻なクラス不均衡という二つの根本的な課題を解決するため、能動学習と反事実推論を統合した革新的なフレームワーク「AC2L-GAD」が提案されました。 従来の手法が抱えていた「ランダムなデータ拡張による意味的一貫性の崩壊」と「単純な負例による学習効率の低下」という致命的な欠陥に対し、異常性を維持する正例と正常化された硬い負例を生成することで、モデルの識別能力を飛躍的に向上させています。 情報理論に基づき学習に最も寄与するノードを戦略的に選択して反事実生成を行うことで、計算コストを約65%削減しつつ、金融不正検知を含む9つのベンチマークで既存の18手法を上回る性能を実証しました。
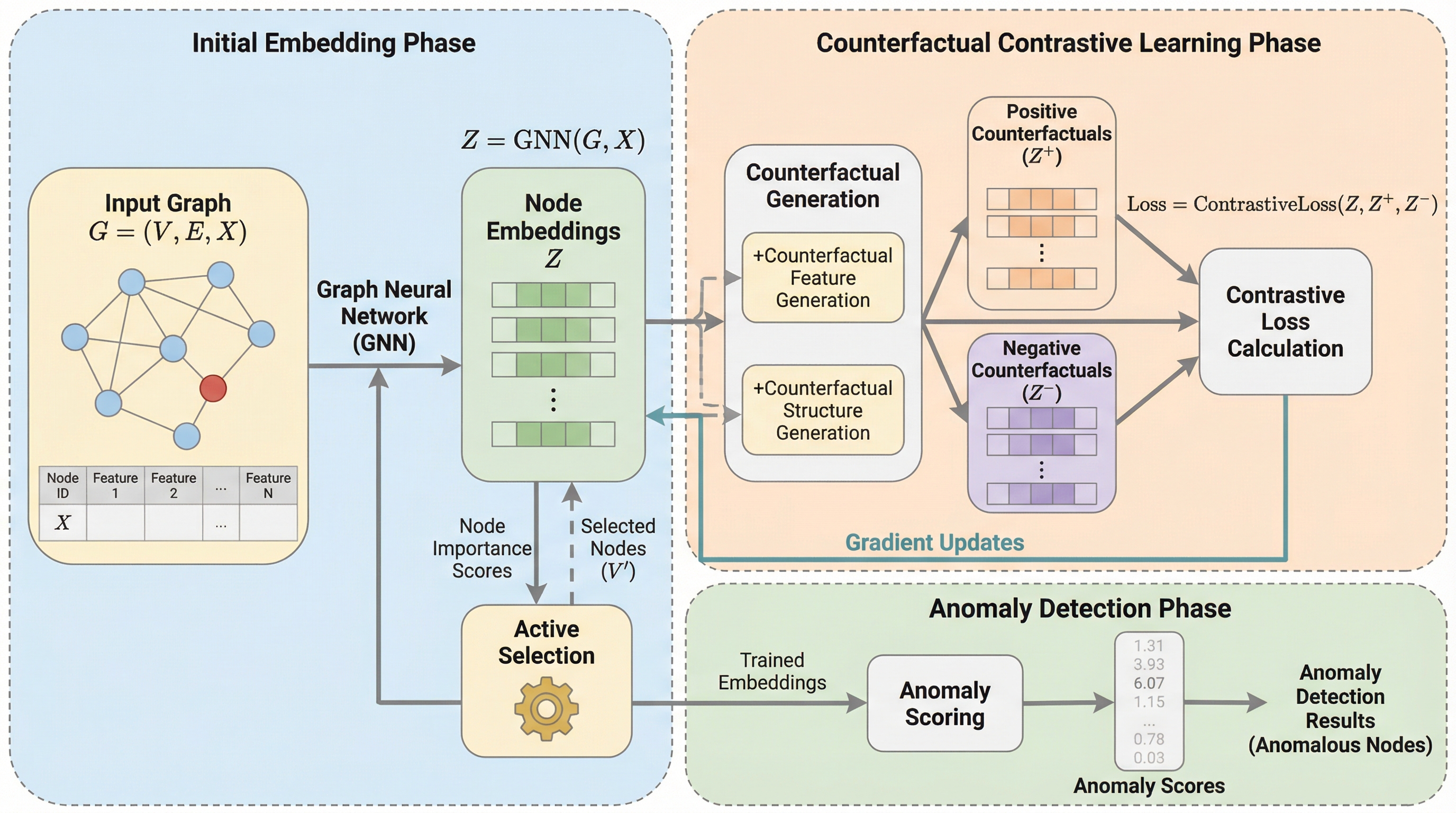
グラフ異常検知における「ラベル不足」と「極端なクラス不均衡」という二大課題を解決するため、能動学習と反事実的推論を統合した新フレームワーク「AC2L-GAD」が提案されました。 従来の対照学習が抱えていた、ランダムなデータ拡張による意味的一貫性の喪失(Gap G1)と、単純な負例サンプリングによる識別能力の停滞(Gap G2)という根本的な欠陥を、情報理論に基づく戦略的なノード選択と、異常の性質を精密に制御する反事実的なデータ生成によって克服しています。 9つのベンチマークを用いた実験では、18の主要な既存手法を上回る検知精度を達成しながら、計算コストを約65%削減することに成功しており、大規模ネットワークにおける実用性と高精度な識別能力を極めて高いレベルで両立させています。