グラフ基盤モデルにおける分布外汎化
グラフ基盤モデル(GFM)は、多様なグラフデータから汎用的な表現を学習し、未知のデータ分布(分布外、OOD)に対しても高い適応力を発揮することを目指す新しいパラダイムであり、本論文はその最新動向を「分布外汎化」の観点から整理した初の包括的サーベイである。
TL;DR(結論)
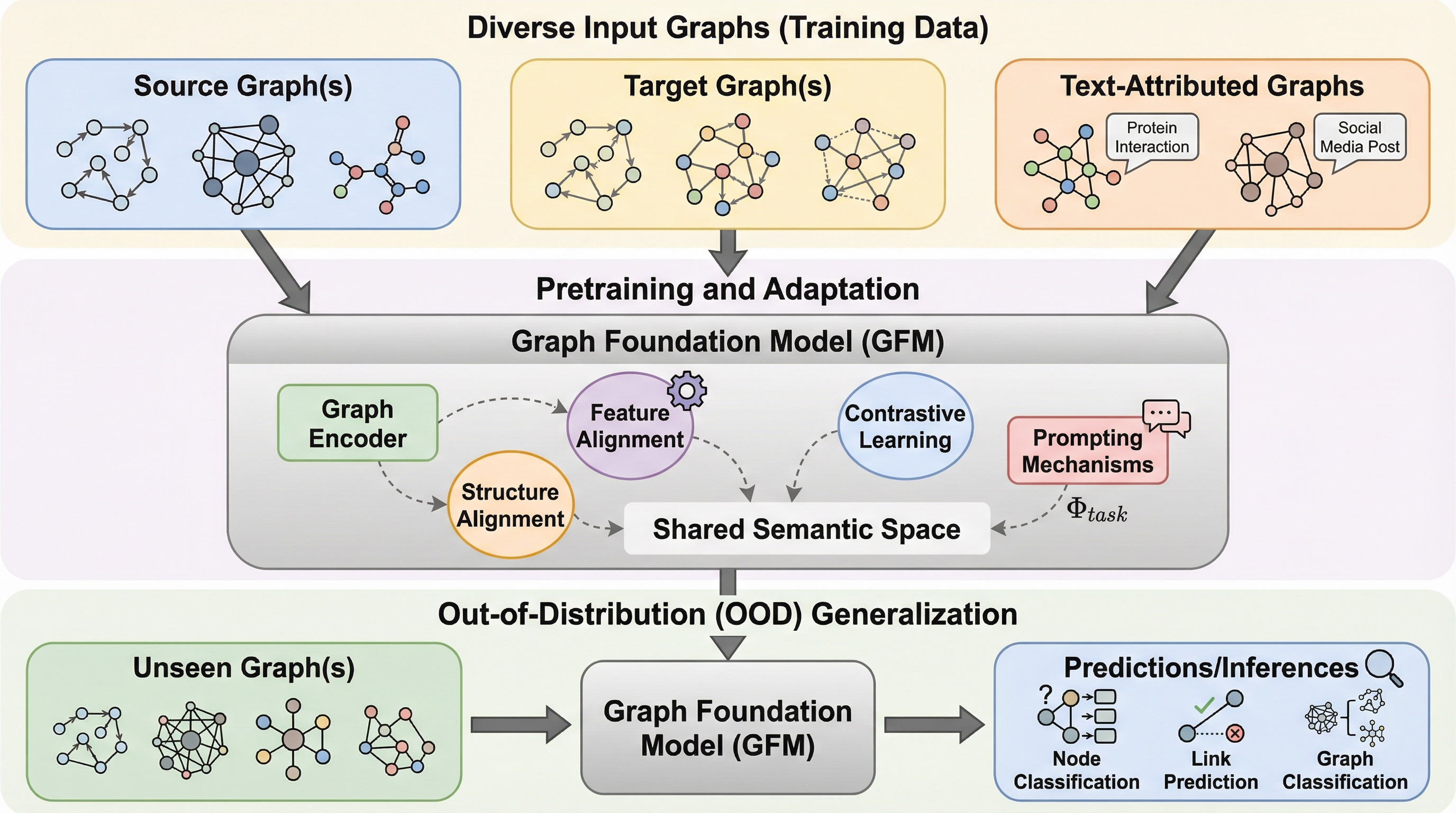
グラフ基盤モデル(GFM)は、多様なグラフデータから汎用的な表現を学習し、未知のデータ分布(分布外、OOD)に対しても高い適応力を発揮することを目指す新しいパラダイムであり、本論文はその最新動向を「分布外汎化」の観点から整理した初の包括的サーベイである。 グラフ学習における分布シフトを「構造・ドメイン・モダリティ・タスク」の4つの階層で定義し、既存モデルを「均一タスク型」と「不均一タスク型」に分類することで、大規模事前学習がどのように特定のデータセット特有のバイアスを排除し、不変な特徴を抽出しているかを体系化している。 不変表現学習、ドメイン整列、プロンプト技術、大規模言語モデル(LLM)との統合といった戦略を詳細に分析し、ラベルの少ない未知の環境においても再学習なしで高精度な推論を可能にするための技術的指針と、負の転移や動的グラフへの対応といった今後の重要課題を提示している。
なぜこの問題か
グラフデータは、実世界における要素間の複雑な関係性を表現するための不可欠なデータ構造であり、ソーシャルネットワーク、分子システム、知識グラフ、推薦システムなど、広範な分野で利用されている。しかし、従来のグラフ学習、特にグラフニューラルネットワーク(GNN)は、特定のデータセット内での予測には優れているものの、学習時とは異なるデータ分布に直面すると性能が著しく低下するという致命的な弱点を持っている。実際の運用環境では、グラフの接続パターン(トポロジー)の変化、データ収集時のバイアスによるドメイン固有のセマンティクスの違い、利用可能な補助情報(テキストや画像などのモダリティ)の欠如やノイズ、さらには予測すべきタスク形式の変更など、多岐にわたる「分布シフト」が発生する。 例えば、ある特定の化合物群で学習したモデルは、異なる化学的性質を持つ新しい分子に対しては、構造と性質の相関関係が変化するため、正確な予測ができなくなる。また、特定のドメインで生じたスプリアスな相関(見せかけの相関)にモデルが過剰適合してしまうと、新しいドメインへの展開が困難になる。…
核心:何を提案したのか
本論文は、急速に発展しているグラフ基盤モデル(GFM)の分野において、特に「分布外(OOD)汎化」という観点から既存研究を整理・体系化した世界初のサーベイ論文である。著者らは、GFMがどのようにして多様な分布シフトを克服し、汎用的な知識を獲得しているかを明らかにするため、統一的な問題定式化を導入した。この定式化では、グラフの生成プロセスを制御する潜在的な因子として、構造(トポロジーや属性)、ドメイン(収集バイアス)、モダリティ(補助情報の有無)、タスク(出力形式)の4つを定義し、これらの因子が変化しても安定した予測を行うことをGFMの究極の目標として設定している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related