Llama-3.1-FoundationAI-SecurityLLM-Reasoning-8B 技術報告書
Foundation-Sec-8B-Reasoningは、Llama-3.1-8Bを基盤として開発された、サイバーセキュリティ分野で初となるオープンソースのネイティブ推論モデルであり、複雑なセキュリティ分析において「思考」プロセスを明示する能力を備えている。
TL;DR(結論)
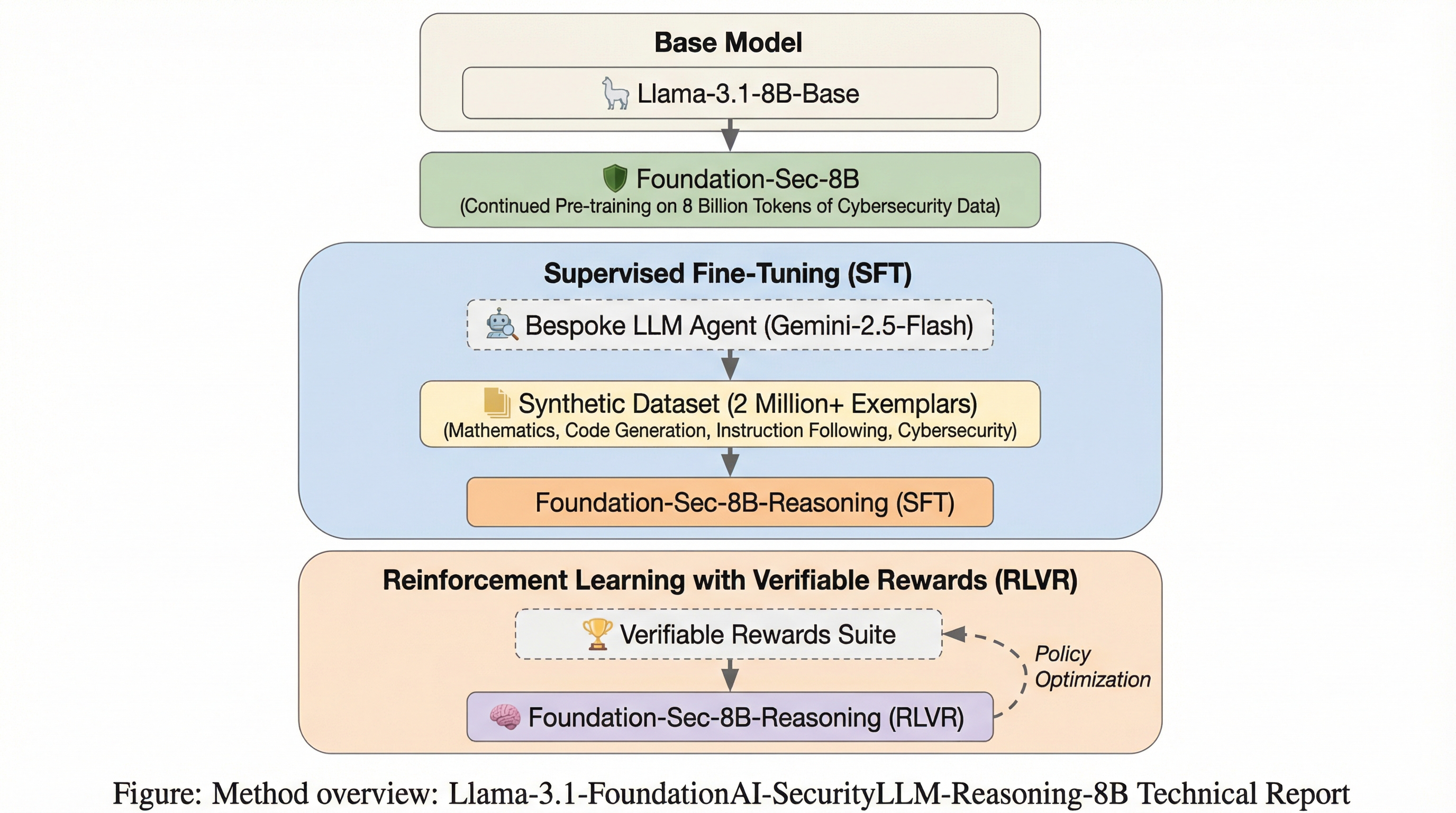
Foundation-Sec-8B-Reasoningは、Llama-3.1-8Bを基盤として開発された、サイバーセキュリティ分野で初となるオープンソースのネイティブ推論モデルであり、複雑なセキュリティ分析において「思考」プロセスを明示する能力を備えている。 このモデルは、200万件以上のデータを用いた教師あり微調整(SFT)と、検証可能な報酬を活用した強化学習(RLVR)の二段階プロセスで訓練されており、セキュリティ専門知識、数学的論理、コード生成、指示追従など多岐にわたる独自の推論データセットを活用している。 10件のセキュリティベンチマークと10件の汎用ベンチマークでの評価により、8Bというサイズでありながら70Bクラスの巨大モデルに匹敵するセキュリティ性能を実現し、マルチホップ推論や脆弱性分類において高い実用性と安全性を実証した。
なぜこの問題か
大規模言語モデル(LLM)の開発最前線では、OpenAI o1やDeepSeek-R1に代表される、ネイティブな推論能力を持つモデルが登場し、大きな進歩を遂げている。これらのモデルの大きな特徴は、最終的な回答を出す前に、内部的な思考プロセスを「
核心:何を提案したのか
本研究では、サイバーセキュリティの複雑な状況に対応するために設計された、80億パラメータを持つネイティブ推論モデル「Foundation-Sec-8B-Reasoning」を提案している。このモデルは、Llama-3.1-8B-Baseから派生し、80億トークンの独自のセキュリティ特化データで継続的な事前学習を行った「Foundation-Sec-8B」をベースに構築されている。本モデルの最大の特徴は、既存の指示追従モデルを微調整するのではなく、ベースモデルから直接ネイティブな推論能力を育成している点にある。 開発チームは、モデルが「話す前に考える」ように設計した。これにより、セキュリティ実務者が分析プロセスを詳細に確認できる、透明性の高い推論トレースの生成が可能になった。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related