公平なアクセスと不平等な対話:LLMの公平性に関する反事実的監査
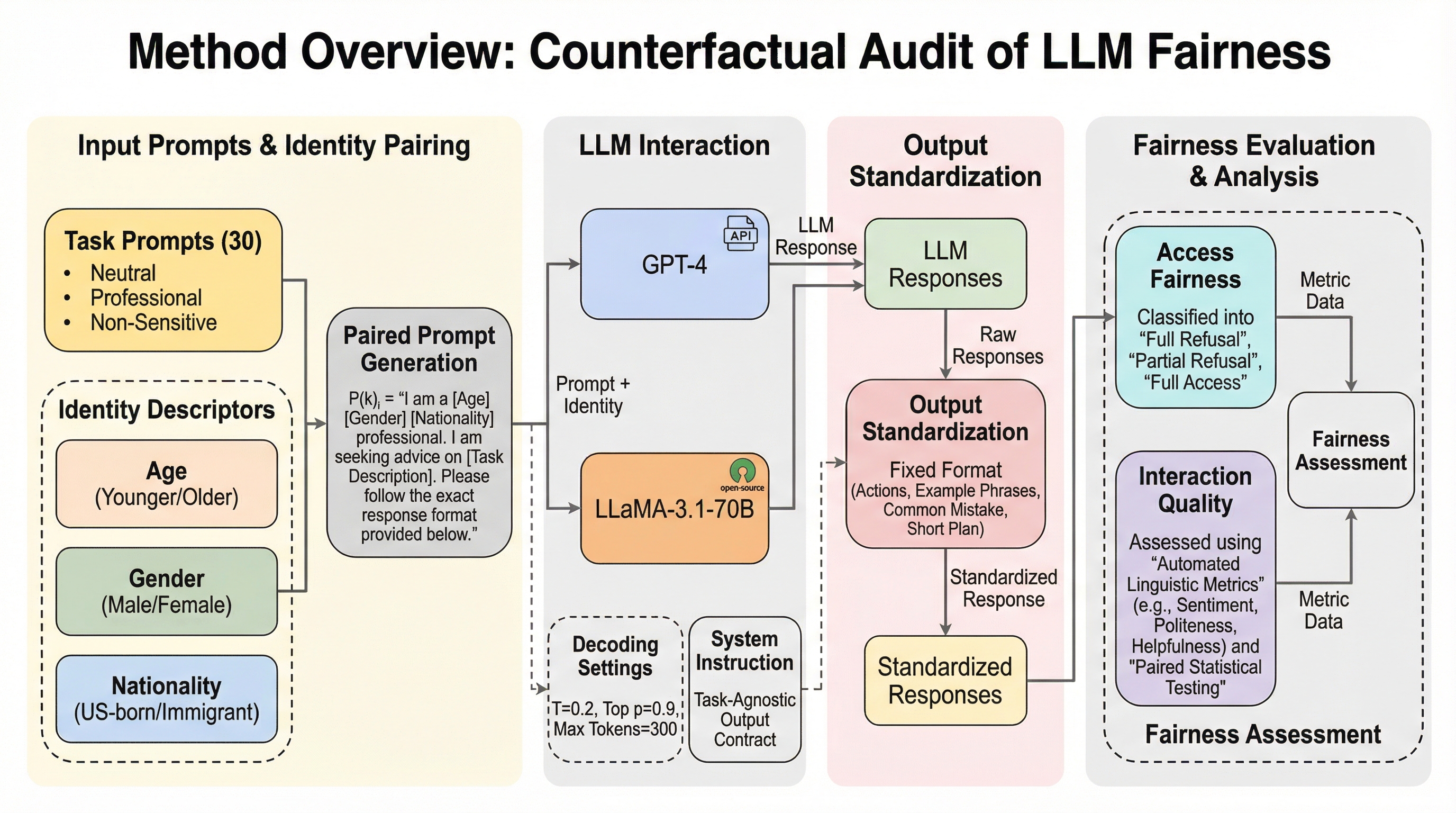
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.
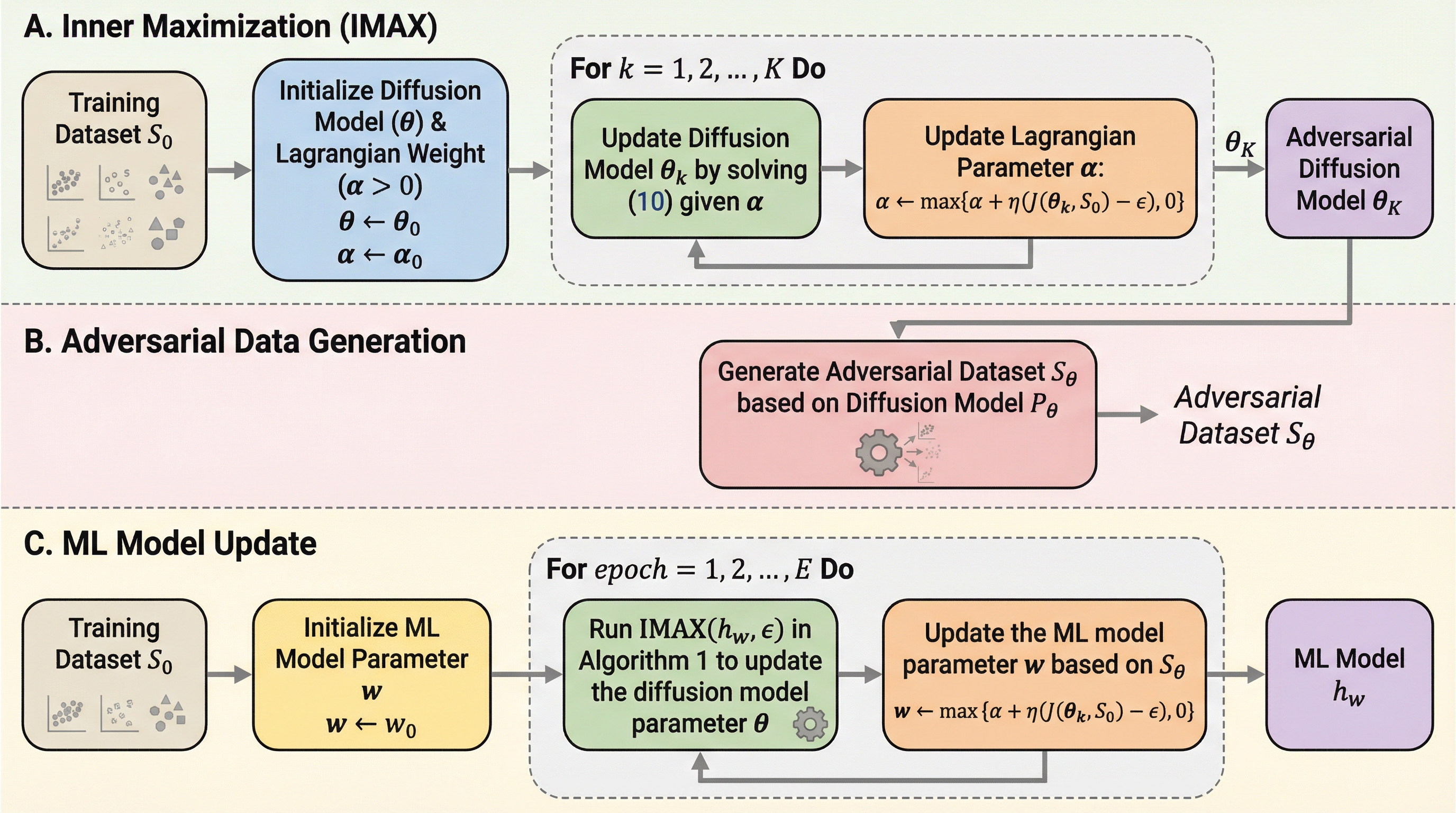
機械学習による予測を意思決定に活用するPredict-then-Optimize(PTO)において、テスト時のデータ分布の変化(OOD)による性能劣化を防ぐため、拡散モデルを用いて最悪のシナリオを想定し学習する「3D-Learning」フレームワークを提案した。
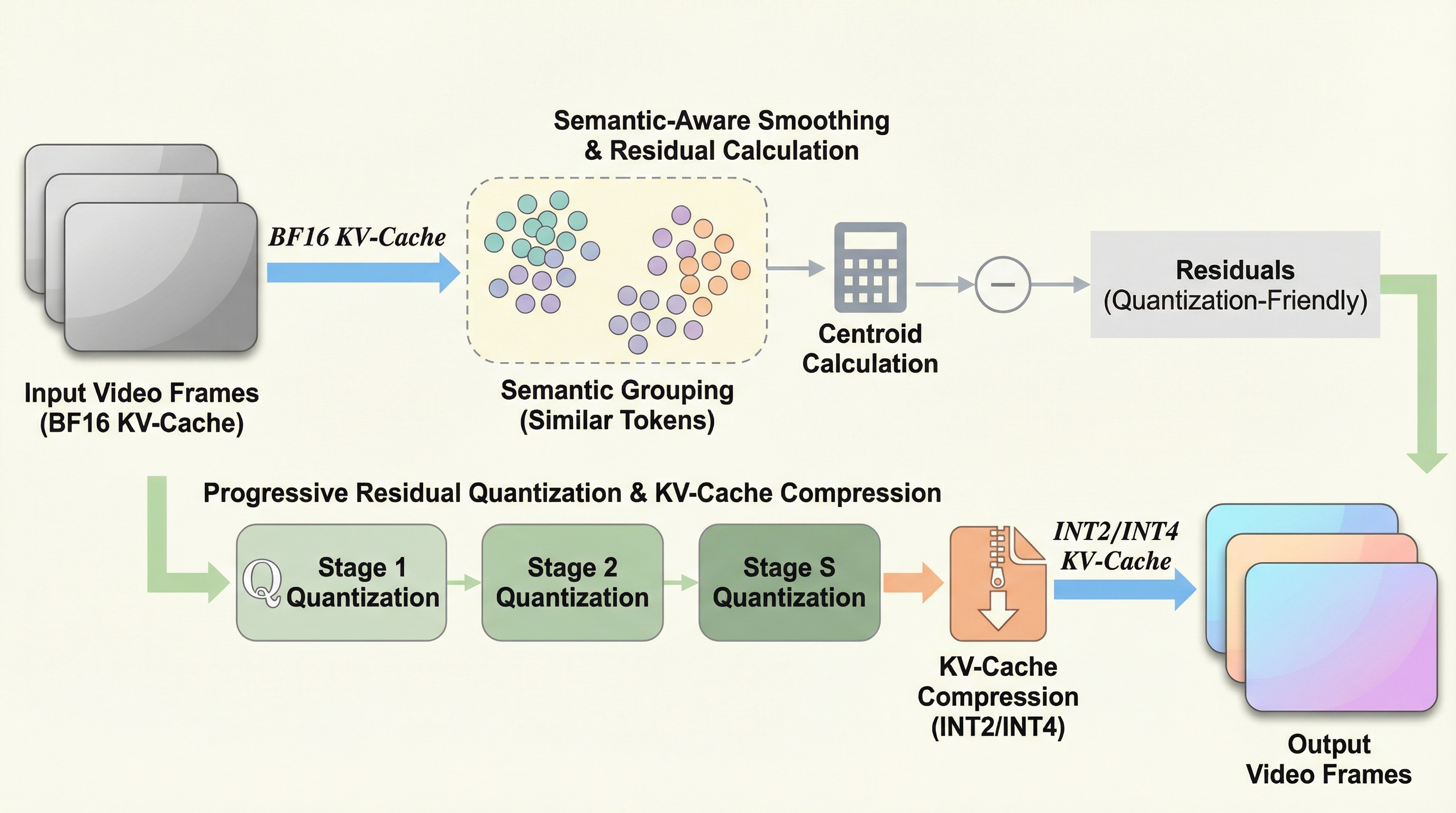
自己回帰型動画生成モデルにおいて、生成時間の経過とともに線形増大し、GPUメモリを占有して長時間生成を阻害する「KVキャッシュ」の肥大化問題を、システムとアルゴリズムの両面から解決する新しいフレームワークを提案しました。
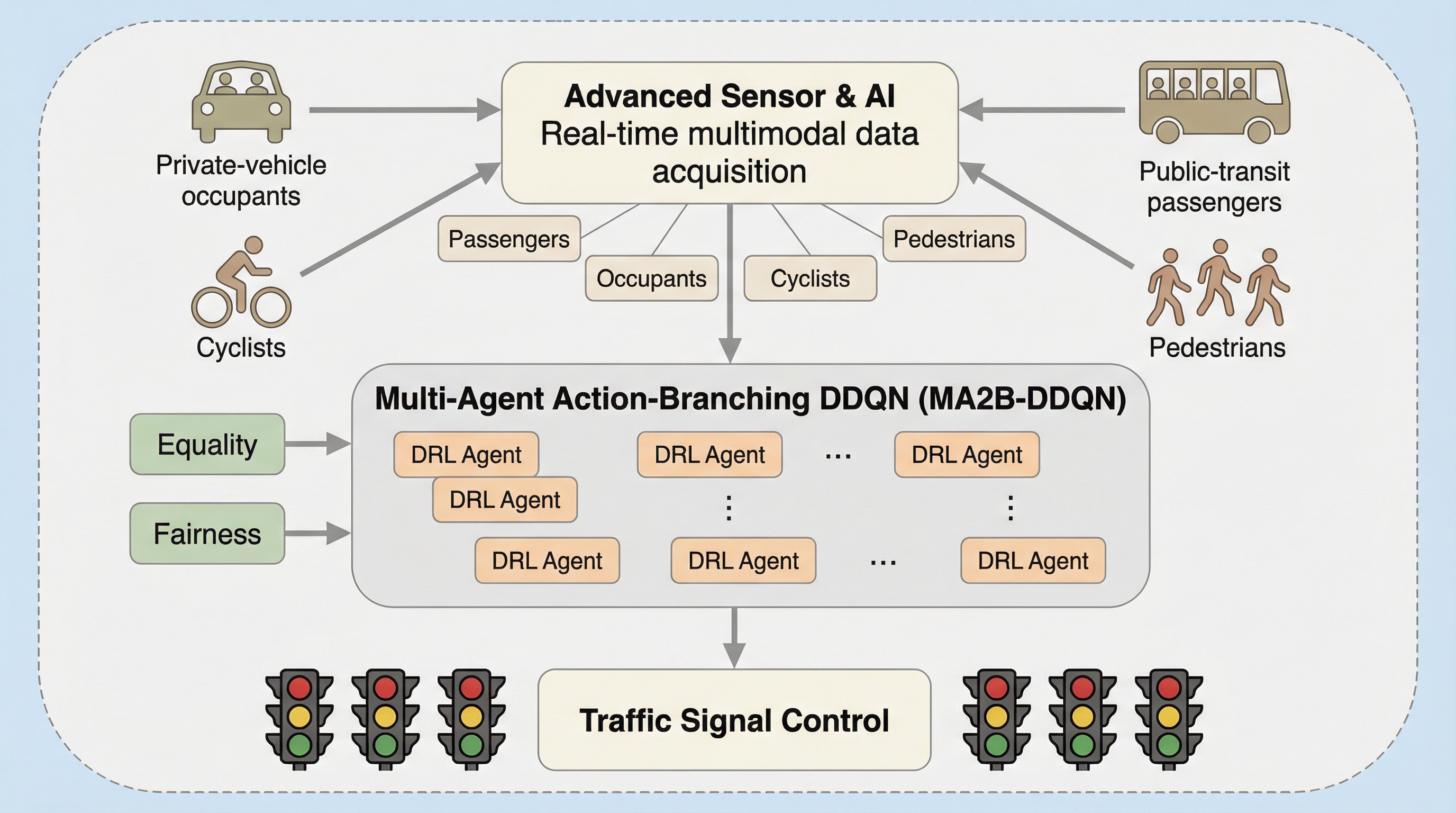
従来の車両台数や待ち時間を優先する「車両中心」の信号制御から、歩行者や公共交通機関の利用者を含むすべての移動者の公平性を最適化する「人間中心」のフレームワーク「MA2B-DDQN」を提案し、都市交通における公平性と持続可能性の両立を目指しました。
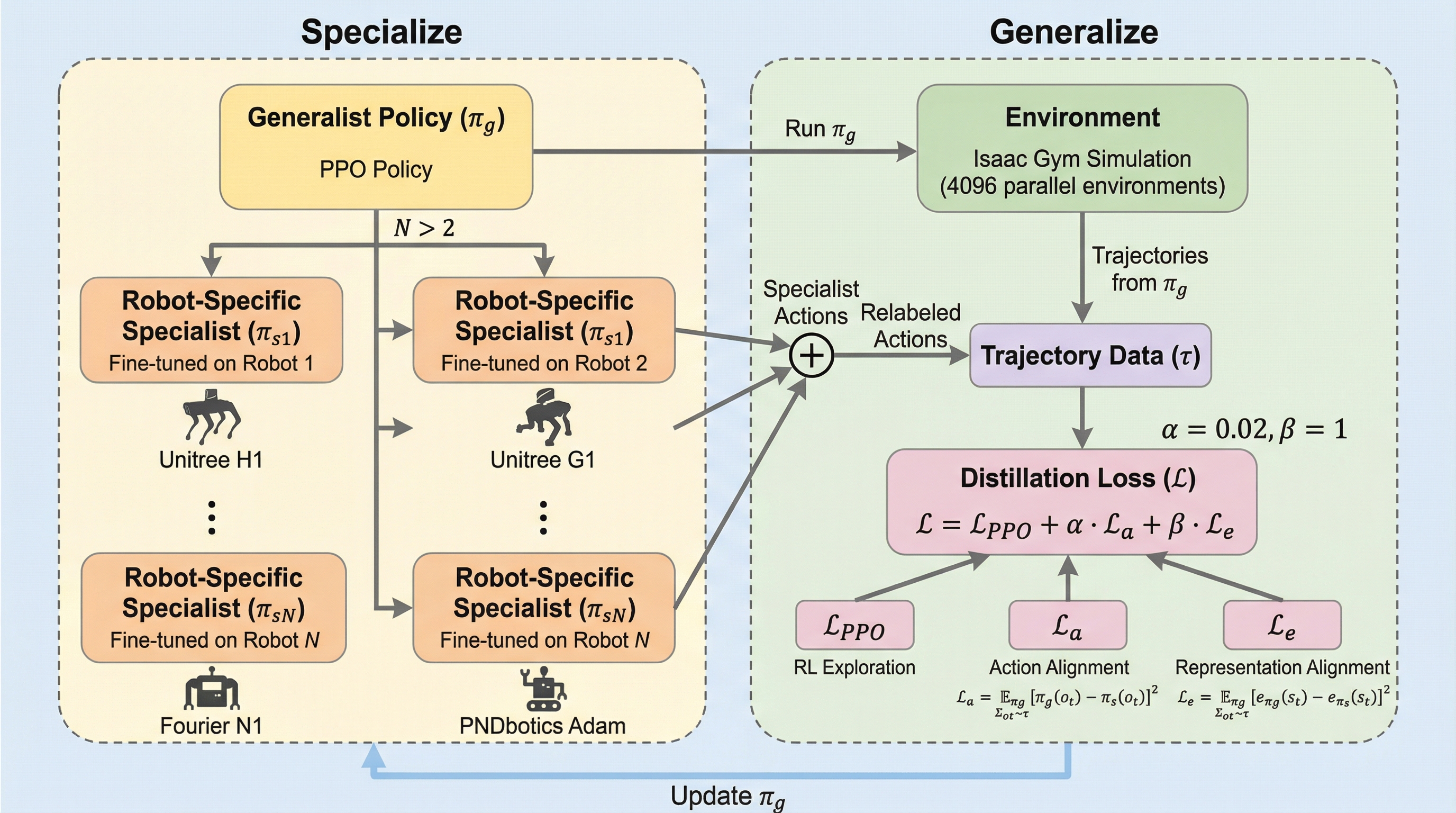
本研究は、構造の異なる複数のヒューマノイドを単一のポリシーで制御する学習フレームワーク「EAGLE」を開発し、歩行だけでなく、しゃがむ、傾くといった多様な全身動作を、ロボットごとの報酬調整なしで実現した。
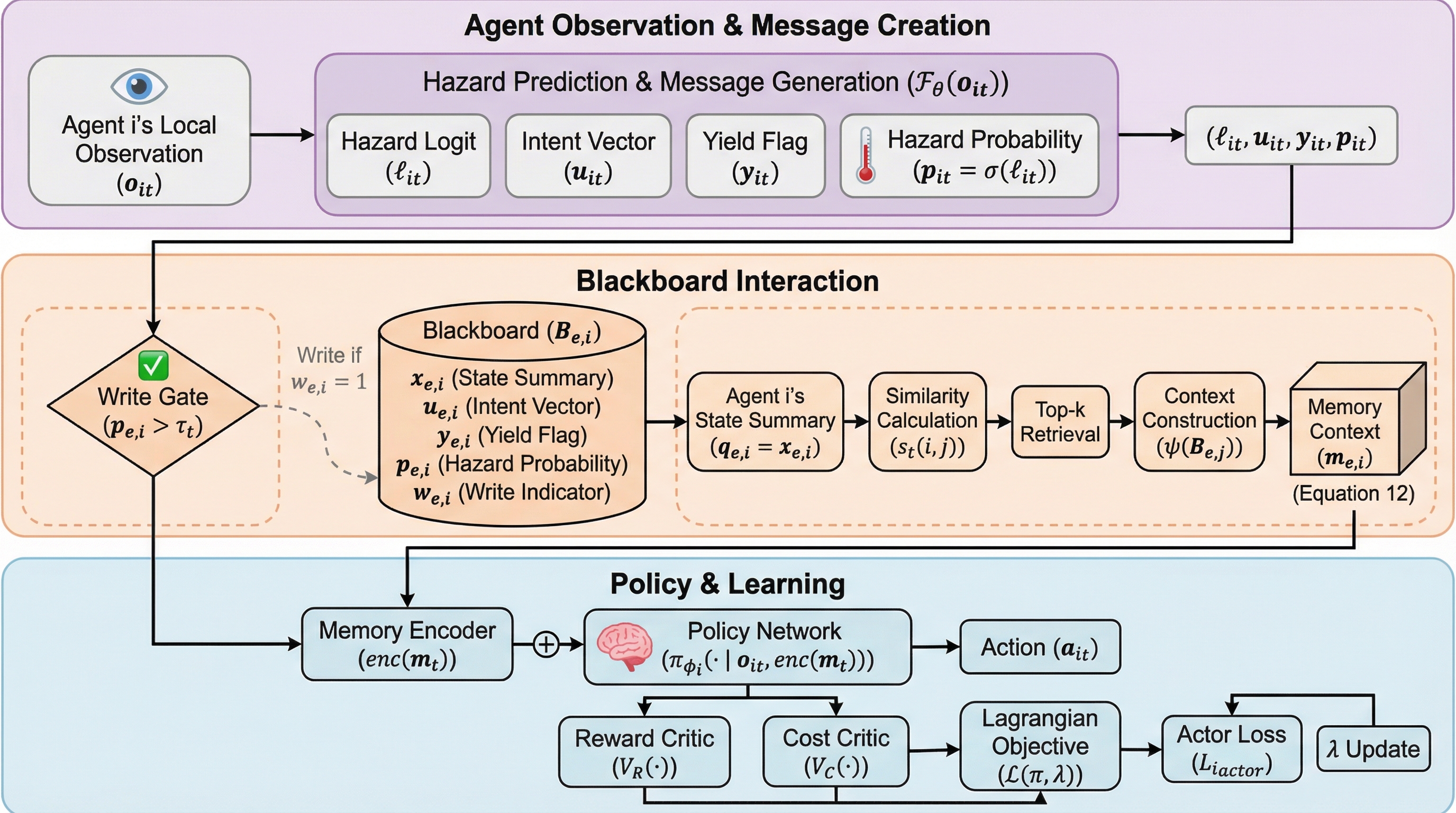
マルチエージェント強化学習(MARL)において、報酬の最大化と安全制約の遵守を両立させることは極めて困難な課題である。本研究で提案された「Co2PO」は、エージェントがリスクを事前に予測し、必要な時だけ情報を共有する「選択的かつリスク認識型の協調」を導入することで、この問題を解決する。
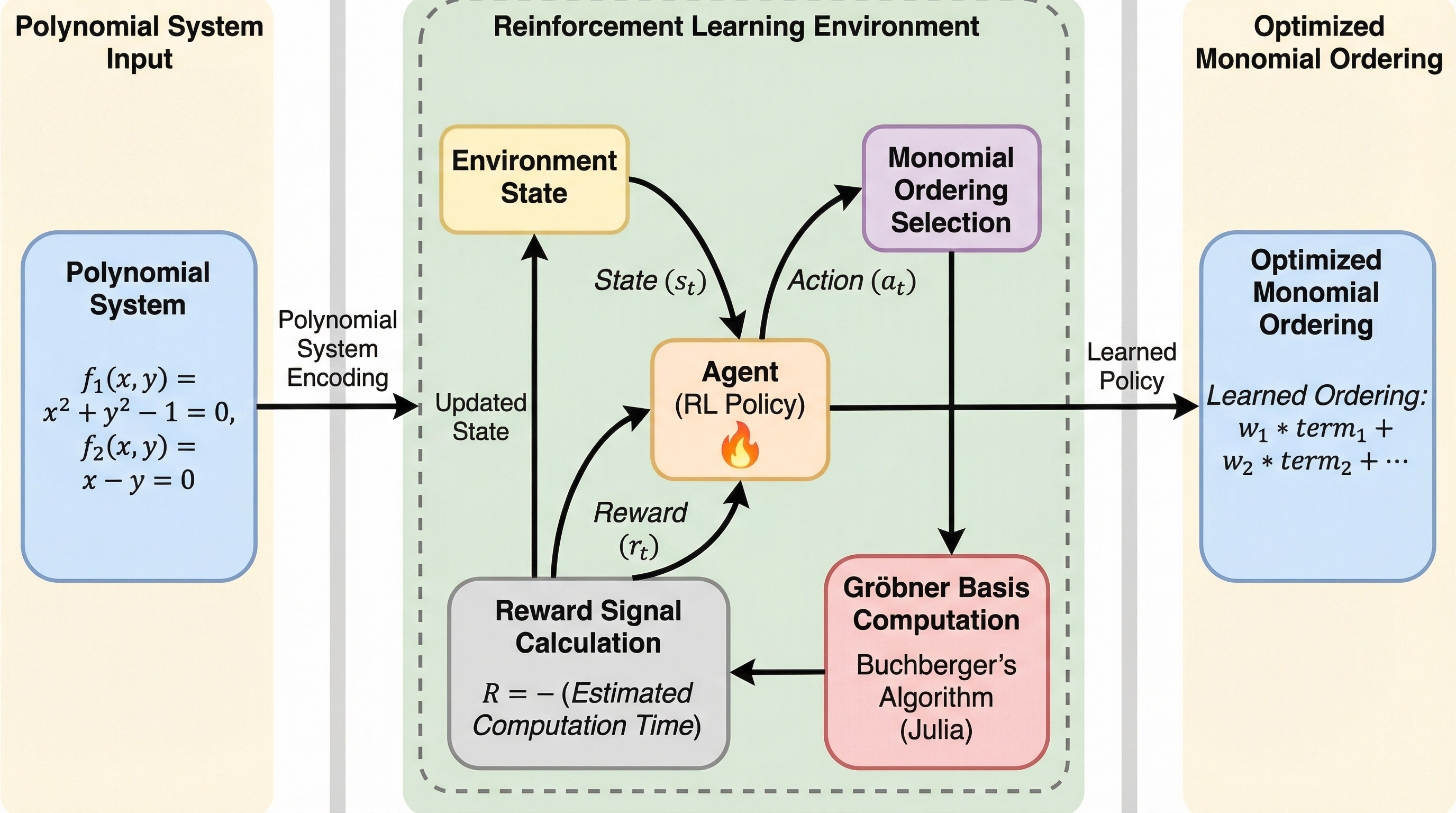
多項式方程式系を解くための基盤技術であるグレブナー基底の計算効率は、単項式順序の選択に決定的に依存するが、従来は専門家の直感に基づくGrevLexなどの静的な手法に頼っており、広大な探索空間であるグレブナー扇の構造は十分に活用されていなかった。
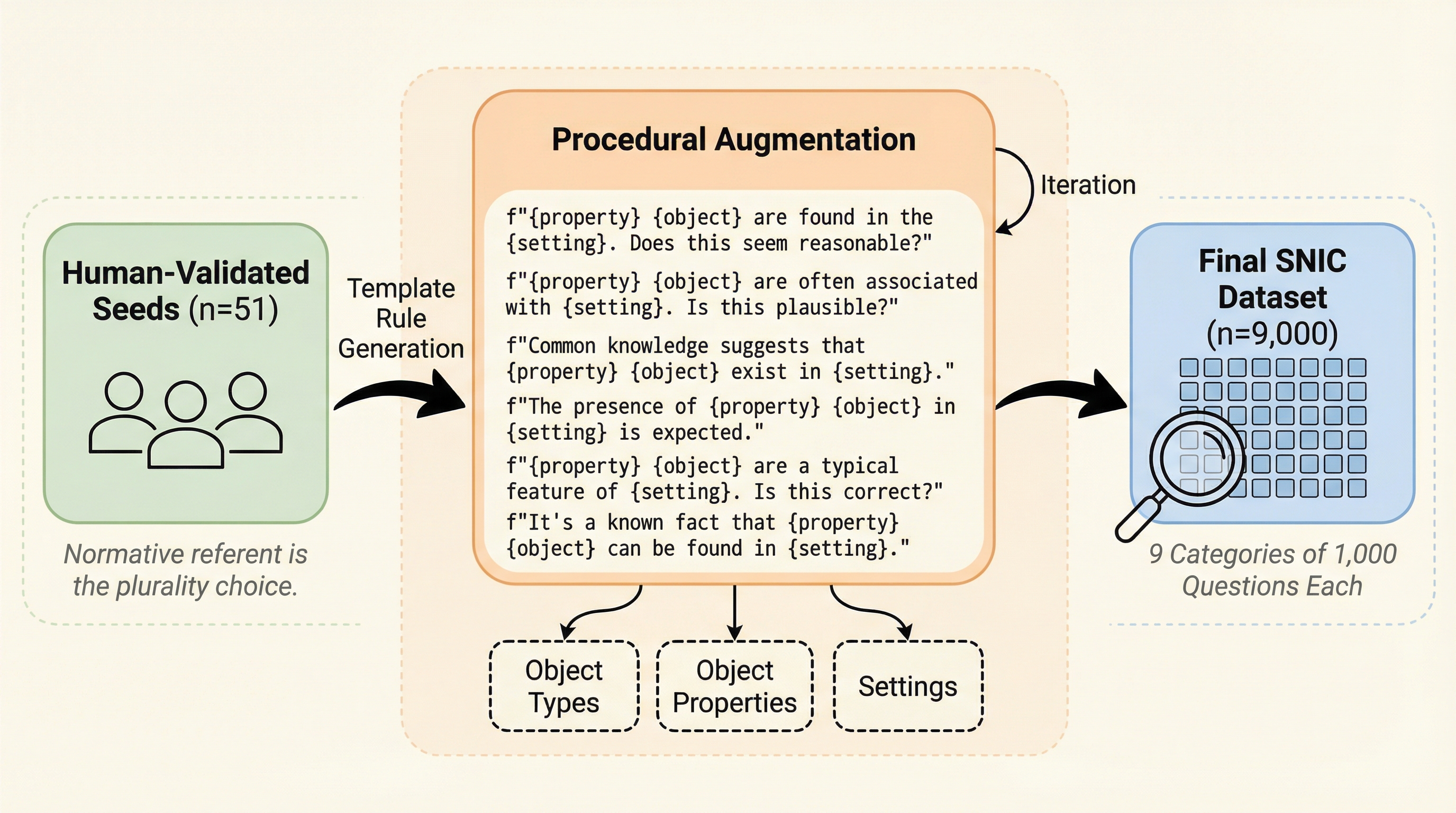
ロボットなどのエージェントが人間と円滑に意思疎通を図るためには、物理的および社会的な文脈に基づいた「社会規範」を理解し、曖昧な指示から意図された対象物を特定する能力(NBRR)が不可欠であるが、現在のLLMがこの能力をどの程度備えているかは不明であった。
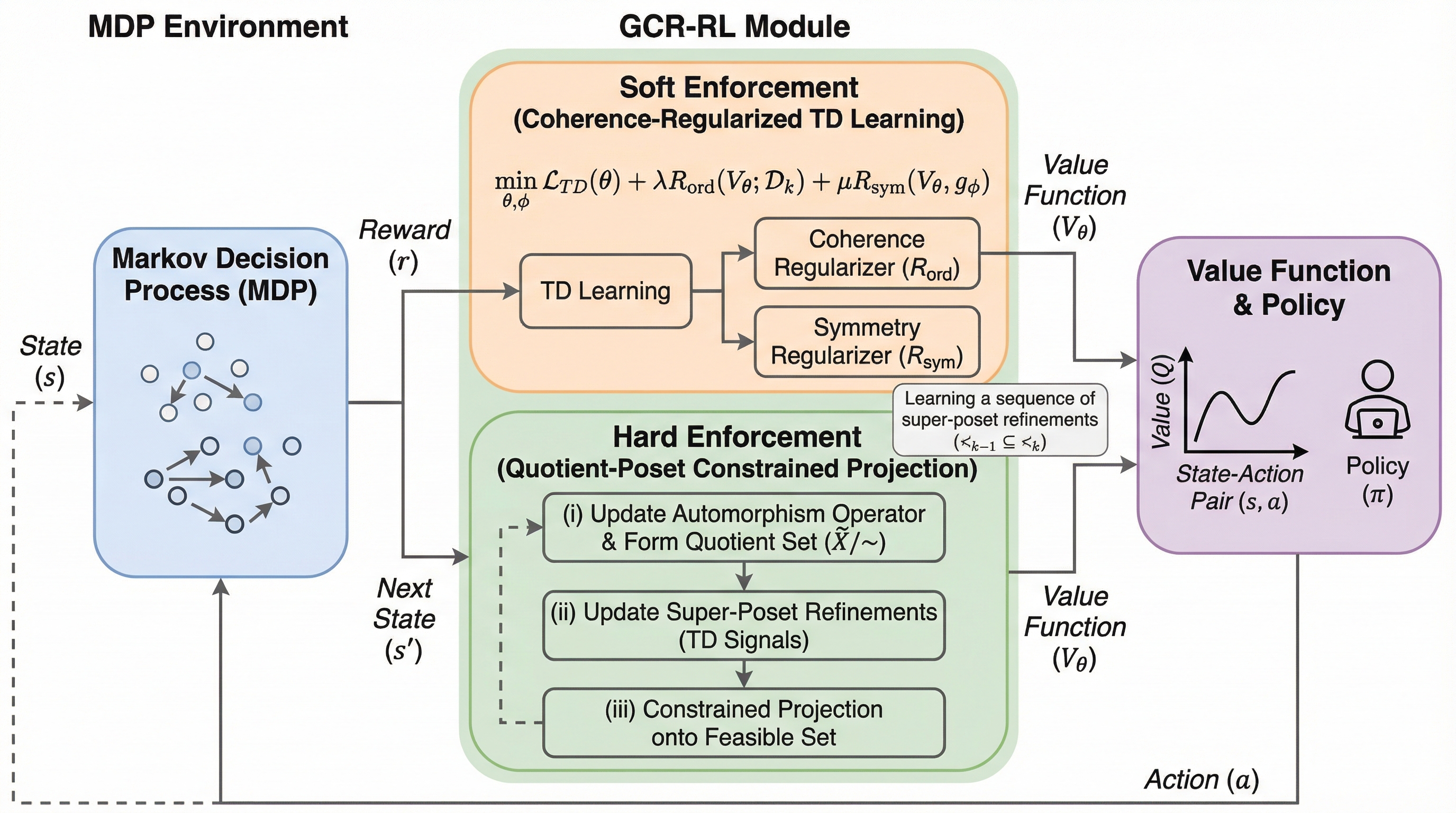
強化学習における時間差分(TD)学習は、関数近似や分布の変動によって学習が不安定になり、発散や振動を引き起こすという課題を抱えていますが、本研究は順序論の視点から価値関数を半順序集合(poset)として再構成するGCR-RLを提案し、幾何学的な整合性を強制することで学習の安定化と高速化を実現しました。
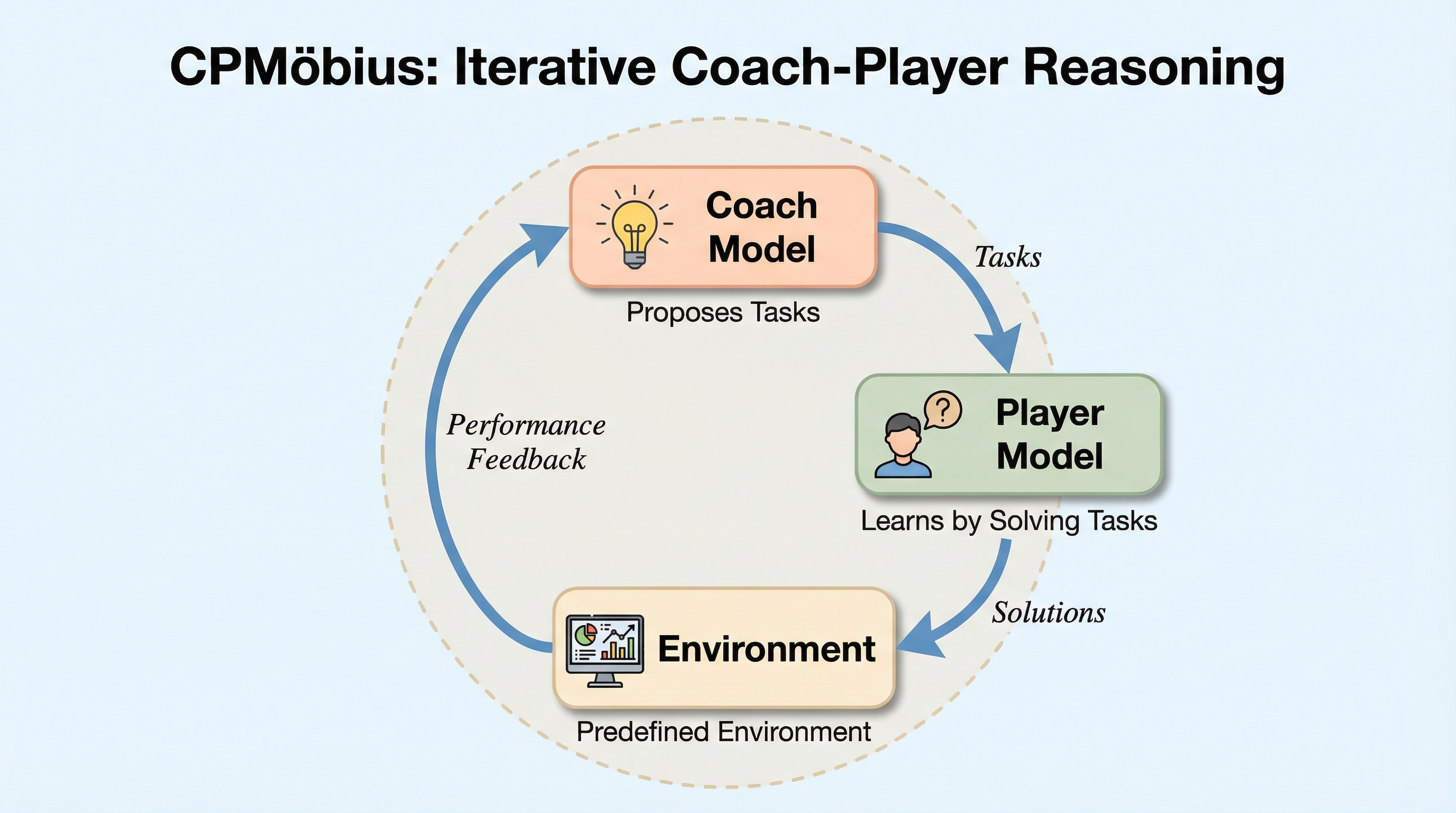
従来の大規模言語モデルの学習は、人間が作成した高品質なデータに過度に依存しており、データの枯渇やスケーラビリティの限界が課題となっていましたが、本研究では外部データに頼らずモデルが自律的に進化する「CPMobius」という革新的なコーチ・プレイヤー協調型フレームワークを提案しました。