Co2PO: 協調的な制約付き方策最適化によるマルチエージェント強化学習
マルチエージェント強化学習(MARL)において、報酬の最大化と安全制約の遵守を両立させることは極めて困難な課題である。本研究で提案された「Co2PO」は、エージェントがリスクを事前に予測し、必要な時だけ情報を共有する「選択的かつリスク認識型の協調」を導入することで、この問題を解決する。
TL;DR(結論)
マルチエージェント強化学習(MARL)において、報酬の最大化と安全制約の遵守を両立させることは極めて困難な課題である。本研究で提案された「Co2PO」は、エージェントがリスクを事前に予測し、必要な時だけ情報を共有する「選択的かつリスク認識型の協調」を導入することで、この問題を解決する。具体的には、共有ブラックボードを介して位置の意図や譲歩信号をやり取りし、学習されたハザード予測器が将来の制約違反を予見することで、従来の事後的な制約処理に伴う過度な保守性を回避している。 複数の複雑な安全ベンチマークを用いた検証の結果、Co2POは既存の主要な制約付き手法を上回る「実行可能な報酬」を獲得しつつ、最終的には制約を厳格に遵守する方策を実現した。特に、学習初期に一時的な違反を許容することで探索を促進し、最終的なデプロイ時には高い安全性と性能を両立させることに成功している。このアプローチは、通信帯域の節約と安全性の向上を同時に達成する新しい枠組みとして、実用的なマルチエージェントシステムの設計に大きく貢献するものである。 本手法は、単なる制約の遵守にとどまらず、エージェント間の「協調の崩壊」を未然に防ぐためのプロアクティブな通信メカニズムを確立した。これにより、部分観測環境下でもエージェント同士が互いの意図を理解し、衝突や危険な状態を回避しながら、集団としての目標を効率的に達成することが可能となった。
なぜこの問題か
制約付きマルチエージェント強化学習(MARL)の分野では、集団全体の報酬を最大化することと、個々のエージェントが安全制約を厳格に守ることの間に、解消しがたい緊張関係が存在している。協力的なタスクにおいて、エージェントが未知の環境を積極的に探索しようとすると、どうしてもコストのかかる制約違反を招きやすくなる。一方で、違反を恐れて過度に保守的な更新を行うと、学習が早期に停滞してしまい、エージェントが本来達成可能な高い性能を持つ共同行動を発見することが妨げられてしまう。既存の主要なアプローチであるラグランジュ法などは、違反が発生した後に反応するグローバルな罰則や中央集権的なクリティックに依存していることが多く、これが探索を抑制し、結果として過度な保守性を引き起こす大きな原因となっている。 さらに、この問題は部分観測性や、エージェント間の相互作用によって駆動される動的な環境において、より一層複雑化する。エージェントたちが同じ報酬目標を共有している場合であっても、安全性の失敗は必ずしも個々のインセンティブの衝突から生じるわけではない。…
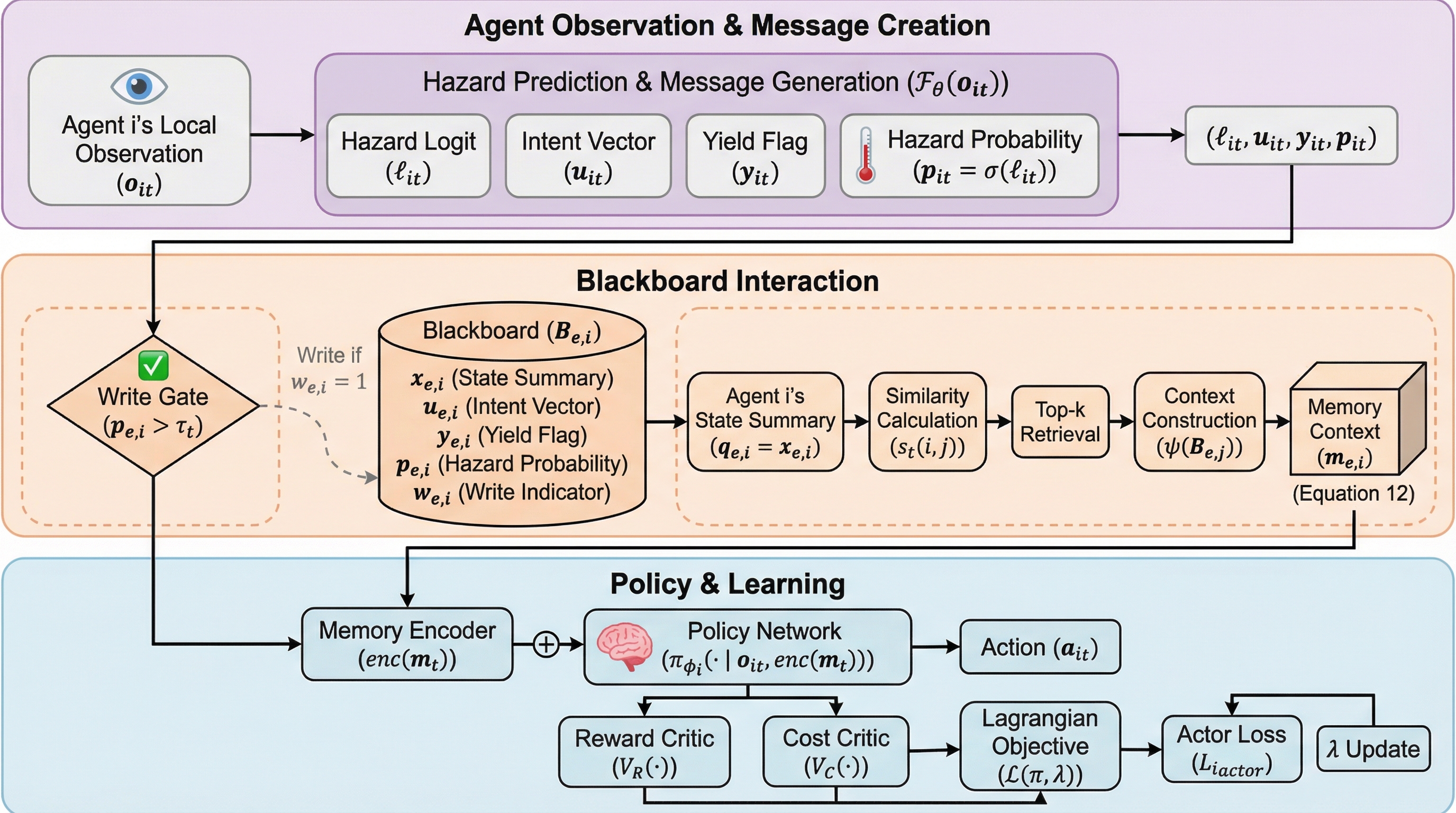
核心:何を提案したのか
本論文で提案されたCo2PO(Coordinated Constrained Policy Optimization)は、選択的かつリスク認識型の協調を可能にする新しいマルチエージェント強化学習フレームワークである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related