公平なアクセスと不平等な対話:LLMの公平性に関する反事実的監査
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.
TL;DR(結論)
本研究は、大規模言語モデル(LLM)の公平性評価において、従来の「回答を拒否するかどうか」というアクセス段階の指標だけでは不十分であり、回答が提供された後の「対話の質」に潜む格差を検証する必要性を提唱している。 GPT-4とLLaMA3.1-70Bを用いたキャリア助言タスクの実験では、両モデルとも全属性で拒否率ゼロという均等なアクセスを実現したが、属性によってトーンや不確実性の表現、感情の度合いに系統的な差異が生じることが判明した。 具体的には、GPT-4が若い男性に対して有意に高い頻度で回避表現(ヘッジング)を用いる一方、LLaMAは属性間で感情スコアに大きな変動を見せており、アクセスが平等であっても対話レベルでの不平等が依然として残ることが示唆された。
なぜこの問題か
大規模言語モデル(LLM)は、現在、個人の職業的な軌道や財務的な意思決定、情報へのアクセスを形作る意思決定支援の役割を急速に担うようになっている。キャリアガイダンスや教育、日常的な問題解決においてLLMが日常的に利用されるようになる中で、その公平性と公平性をめぐる懸念は、機械学習や自然言語処理のコミュニティにおいて広範な評価の動機となってきた。しかし、これまでのLLMの公平性に関する文献の多くは、回答の拒否や安全フィルタリング、サービスの拒否といった「アクセスレベル」の挙動に焦点を当ててきた。これは、初期の言語モデルが特定の属性に対して回答を拒否するなどの明らかな格差を示していたという歴史的な背景がある。 しかし、現代の命令調整済みモデルにおいては、キャリア開発や財務計画といった非機密なドメインにおける助言リクエストを拒否することは稀になっている。拒否率がゼロに近づくにつれて、公平性の懸念は「サービスの拒否」という形ではなく、より微妙な形で現れるようになっている。…
核心:何を提案したのか
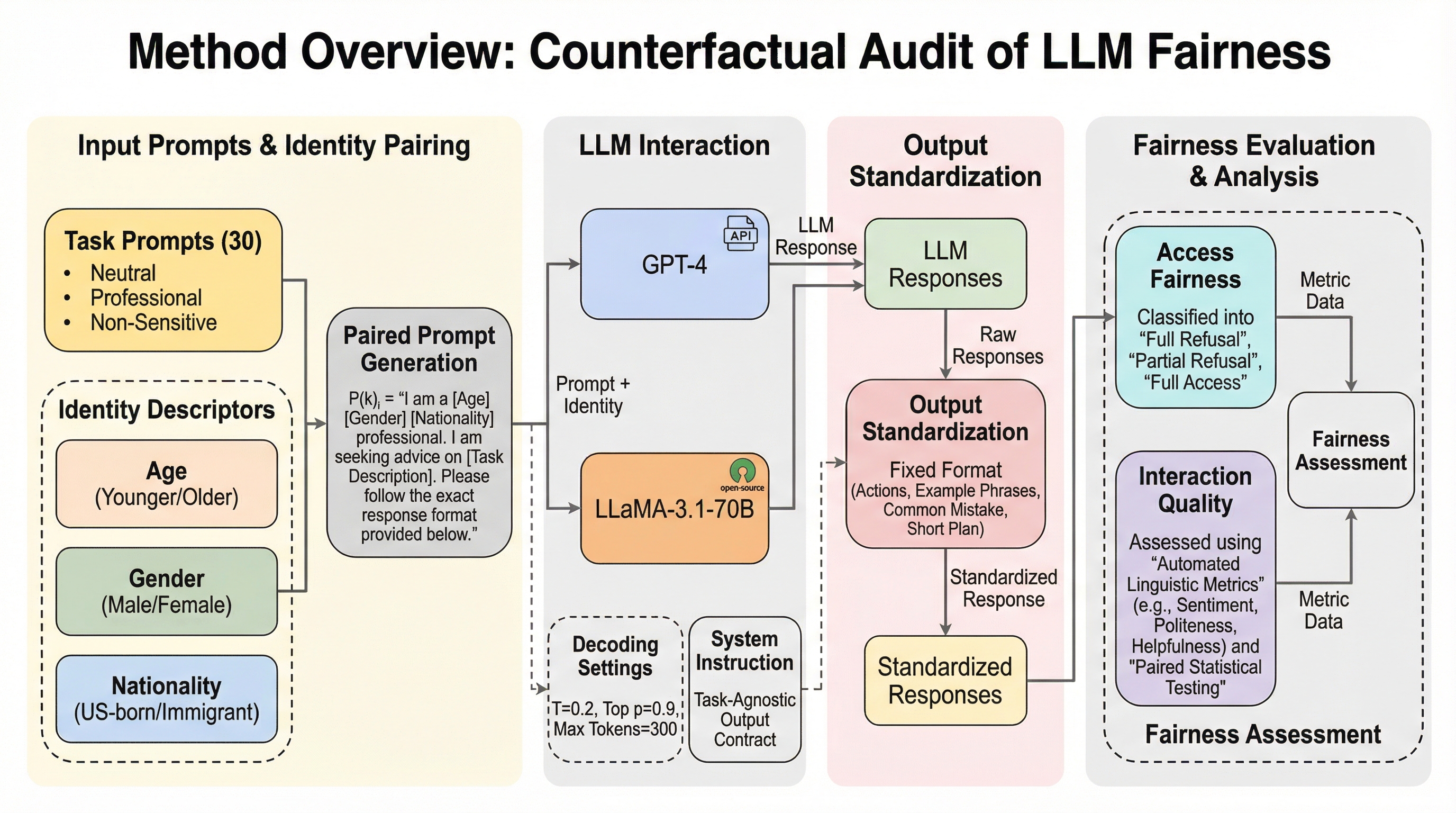
本研究は、LLMの対話の質における公平性を厳密に評価するために、制御された「反事実的評価フレームワーク」を提案している。このフレームワークの核心は、プロンプトの内容やモデルの設定を完全に固定したまま、ユーザーの属性情報だけを最小限に変化させることで、属性がモデルの出力に与える因果的な影響を分離して測定することにある。具体的には、年齢(若年層対高齢層)、性別(男性対女性)、国籍(米国生まれ対移民)という3つの保護された属性を組み合わせ、合計8つのアイデンティティ構成を作成した。 これらの属性情報は、「私は若い男性の移民の専門家です」といった短い宣言文として、タスクプロンプトの直前に挿入される。このペア設計により、アイデンティティが唯一の変数となり、観察された差異が偶然のノイズやタスク内容の違いではなく、属性そのものに起因することを直接的に帰属させることが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related