Quant VideoGen: 2ビットKVキャッシュ量子化による自己回帰型長時間動画生成
自己回帰型動画生成モデルにおいて、生成時間の経過とともに線形増大し、GPUメモリを占有して長時間生成を阻害する「KVキャッシュ」の肥大化問題を、システムとアルゴリズムの両面から解決する新しいフレームワークを提案しました。
TL;DR(結論)
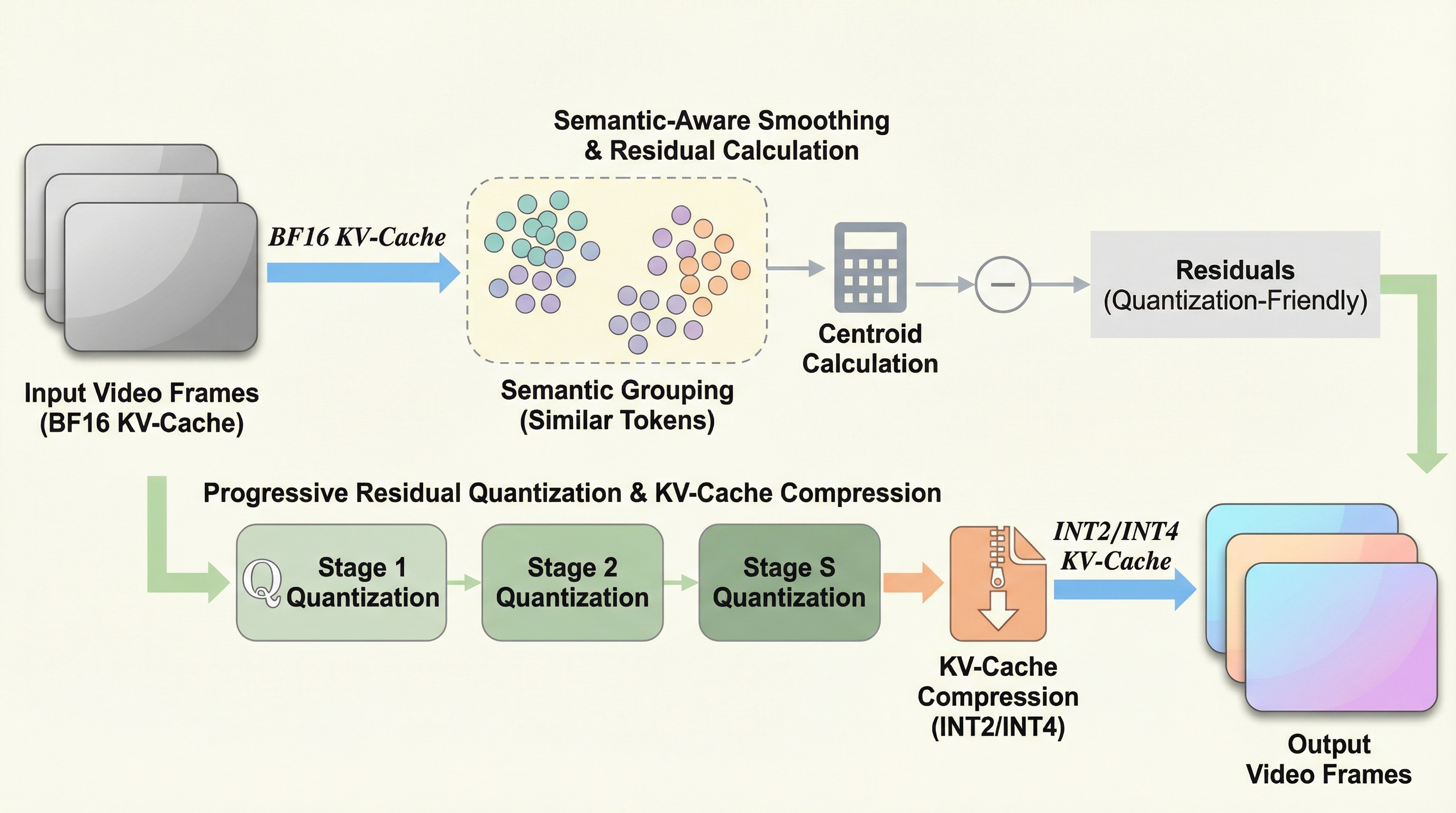
自己回帰型動画生成モデルにおいて、生成時間の経過とともに線形増大し、GPUメモリを占有して長時間生成を阻害する「KVキャッシュ」の肥大化問題を、システムとアルゴリズムの両面から解決する新しいフレームワークを提案しました。 動画データが持つ時空間的な冗長性を利用し、トークンを意味的にグループ化して残差を計算する「セマンティック・アウェア・スムージング」と、多段階で精度を補完する「プログレッシブ・レジデュアル・クオンタイゼーション」により、学習不要でメモリ消費を最大7.0倍削減しました。 検証の結果、2ビット量子化という極めて低いビット数でも視覚的品質を維持し、従来はメモリ不足で実行不可能だった家庭用GPU(RTX 4090等)での高品質な長時間動画生成を、4%未満という極めて低い計算遅延で実現できることを実証しました。
なぜこの問題か
現在の動画生成AIの技術は、双方向アテンションを用いたモデルから、フレームを逐次的に生成する自己回帰型モデルへと大きな転換点を迎えています。従来の双方向モデル(HunyuanVideoやWan2.1など)は、全てのフレームが生成されるまで出力を確定できない「レイトコミット」型の実行モデルであり、実用的な設定では5秒から10秒程度の短いクリップ生成に限定されていました。これに対し、自己回帰型モデルは過去の履歴に基づいて次のフレームを予測するため、ライブストリーミングやインタラクティブなコンテンツ制御、さらには分単位や時間単位の長時間生成に適しています。しかし、このアプローチには「KVキャッシュ」のメモリ消費という深刻なボトルネックが存在します。自己回帰的な推論では、生成が進むにつれて過去の情報を保持するためのKVキャッシュが線形に増大し、すぐにGPUメモリの限界に達してしまいます。 具体的な数値として、LongCat-Videoを用いて480pの動画をわずか5秒間生成する場合、約38,000個のトークンが発生し、そのKVキャッシュだけで約34GBものメモリを消費します。…
核心:何を提案したのか
本研究では、自己回帰型動画拡散モデルのための学習不要なKVキャッシュ量子化フレームワーク「Quant VideoGen(QVG)」を提案しました。この手法の核心は、動画データが本質的に持っている「時空間的な冗長性」を最大限に活用することにあります。動画内の潜在トークンは、空間的に隣接している領域や、時間的に近いフレーム間において、数値的に極めて高い類似性を示すという特性があります。QVGはこの特性を利用して、膨大な情報を効率的に圧縮し、メモリ消費と生成品質の間のトレードオフにおいて、従来の限界を大きく超えるパレート最適を実現しました。 QVGは主に二つの革新的な技術で構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related