CPMobius:データ不要の強化学習を実現する反復的なコーチ・プレイヤー推論フレームワーク
従来の大規模言語モデルの学習は、人間が作成した高品質なデータに過度に依存しており、データの枯渇やスケーラビリティの限界が課題となっていましたが、本研究では外部データに頼らずモデルが自律的に進化する「CPMobius」という革新的なコーチ・プレイヤー協調型フレームワークを提案しました。
TL;DR(結論)
従来の大規模言語モデルの学習は、人間が作成した高品質なデータに過度に依存しており、データの枯渇やスケーラビリティの限界が課題となっていましたが、本研究では外部データに頼らずモデルが自律的に進化する「CPMobius」という革新的なコーチ・プレイヤー協調型フレームワークを提案しました。 この手法は、敵対的な自己対戦とは異なり、コーチがプレイヤーの現在の能力に合わせて最適な難易度の課題を動的に生成し、プレイヤーがそれを解くことで相互に成長する共生的な学習ループを構築しており、GRPOやREINFORCEアルゴリズムを組み合わせることで安定した自己進化を実現しています。 数学的推論タスクを用いた検証では、Qwen2.5-Math-7B-Instructにおいて平均精度が4.9ポイント向上し、未知のデータセットに対しても既存の無監督手法を凌駕する高い汎化性能を示すなど、人間の監督を必要としないデータフリー強化学習の新たな可能性を実証しました。
なぜこの問題か
現在の大規模言語モデル(LLM)の進歩は、数学的推論やコード生成などの複雑なタスクにおいて目覚ましいものがありますが、その学習プロセスの多くは人間が厳選した膨大なタスクやラベルに依存しています。教師あり微調整(SFT)や、推論に特化したデータを用いた強化学習(RL)は、専門家が作成した高品質なデータセットを必要としますが、このようなデータの希少性は高まっており、従来の学習パラダイムの持続可能性には疑問が呈されています。この依存関係を打破するために、モデルが自律的な相互作用を通じて改善を図る「データフリー学習」という領域が注目されており、ゲーム分野のAIから着想を得た自己対戦(セルフプレイ)の枠組みがLLMの自己進化に応用され始めています。 しかし、先行する自己対戦フレームワークの多くは、一方のモデルが他方を打ち負かすような課題を生成する「敵対的」または「競争的」な力学に基づいて構築されており、この設定は学習の不安定さを招きやすいという根本的な課題を抱えています。…
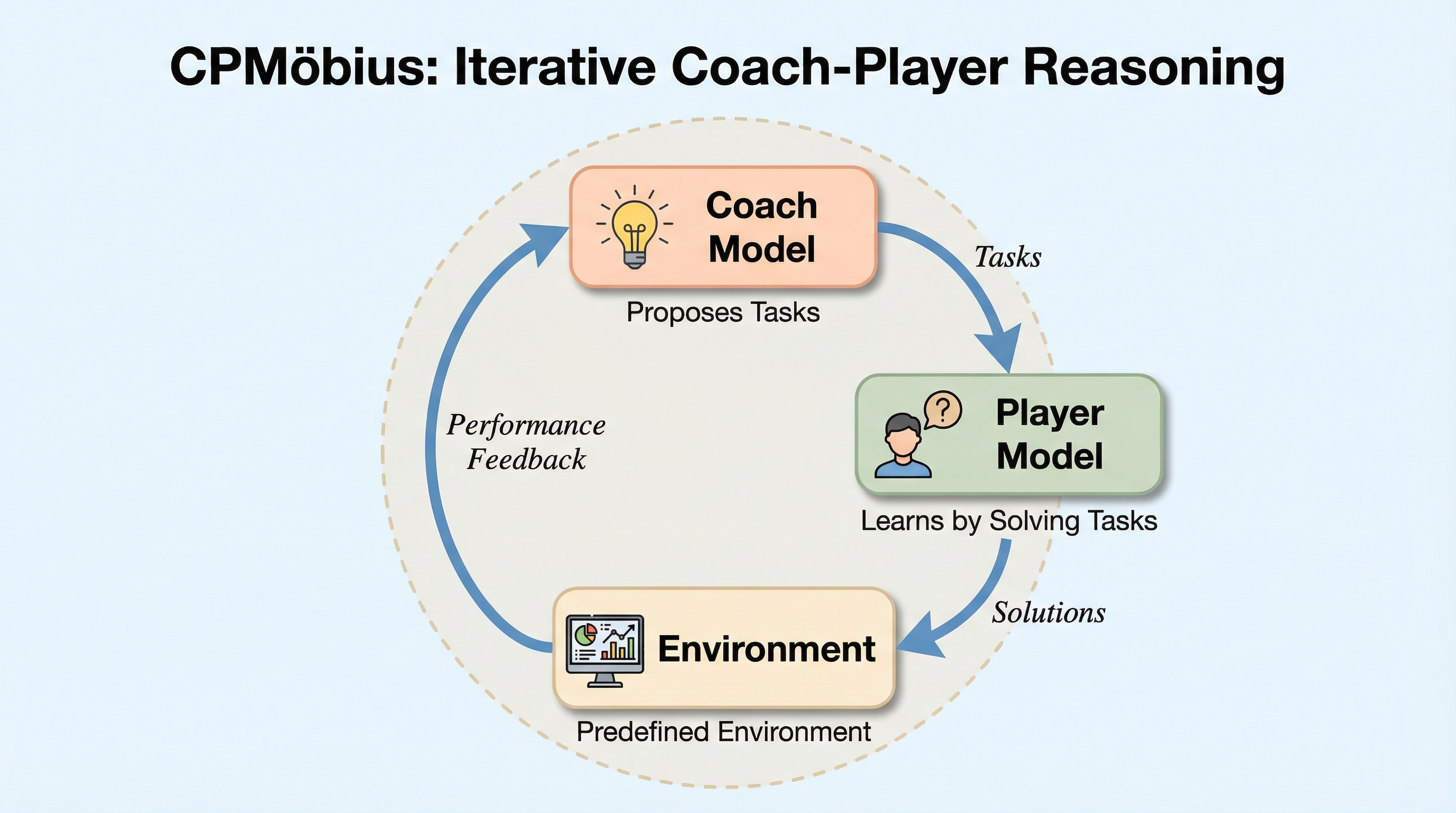
核心:何を提案したのか
本研究では、現実世界のスポーツにおけるコーチと選手の協力関係やマルチエージェントの協調から着想を得た、データフリー強化学習のための「CPMobius」というコーチ・プレイヤー・パラダイムを提案しています。このフレームワークは、従来の敵対的な自己対戦とは異なり、コーチ役のモデルとプレイヤー役のモデルを、独立していながらも共通の目標に向かって協力するパートナーとして定義している点が最大の特徴です。コーチはプレイヤーを打ち負かすのではなく、プレイヤーの現在の能力に合わせてタスクの難易度を調整し、学習効果が最大化されるようなカリキュラムを動的に設計する責任を負います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related