マルコフ決定過程における幾何学的整合性を用いた価値表現の構造化
強化学習における時間差分(TD)学習は、関数近似や分布の変動によって学習が不安定になり、発散や振動を引き起こすという課題を抱えていますが、本研究は順序論の視点から価値関数を半順序集合(poset)として再構成するGCR-RLを提案し、幾何学的な整合性を強制することで学習の安定化と高速化を実現しました。
TL;DR(結論)
強化学習における時間差分(TD)学習は、関数近似や分布の変動によって学習が不安定になり、発散や振動を引き起こすという課題を抱えていますが、本研究は順序論の視点から価値関数を半順序集合(poset)として再構成するGCR-RLを提案し、幾何学的な整合性を強制することで学習の安定化と高速化を実現しました。 この手法は、反射律、推移律、反対称律という半順序の特性を価値表現に導入し、特に商集合を用いたオートモーフィズム(自己同型)の学習によって価値のループを排除することで、探索空間を削減し、TD信号から得られる順序関係を段階的に洗練させていくスーパーポセット・リファインメントという新しいプロセスを確立しています。 実装面では、幾何学的整合性を正則化項として加えるソフトな強制手法と、制約付き投影を用いるハードな強制手法の2つを開発し、グリッドワールドやAtariなどの多様なタスクにおいて、従来の強力なベースラインを大幅に上回るサンプル効率の向上と、ベルマン残差の低減、および安定した収束性能を理論と実験の両面で証明しました。
なぜこの問題か
深層強化学習は、視覚的な制御から計画立案に至るまで、多くの分野で目覚ましい成功を収めてきました。しかし、その根幹を支える価値ベースの手法は、限定されたデータを用いたブートストラップ法と関数近似の組み合わせに依存しているため、本質的な脆弱性を抱えています。具体的には、時間差分(TD)学習の更新プロセスにおいて、近似誤差やデータの分布変化が生じると、学習が発散したり激しく振動したりすることが知られています。このような不安定な学習挙動は、学習の収束を遅らせるだけでなく、最終的なパフォーマンスの低下を招く大きな要因となっています。 この問題に対し、既存の研究では幾何学的な性質を利用して強化学習を正則化し、高速化する試みがなされてきました。例えば、双シミュレーション関係の抽象化、対称性構造のエンコーディング、幾何学を考慮したデータ拡張、あるいは非巡回性や選好性といった順序制約の導入などが挙げられます。しかし、これらのアプローチは断片的であり、価値関数における幾何学的構造を体系的に活用し、かつ厳密な理論的裏付けを持つフレームワークはこれまで存在していませんでした。…
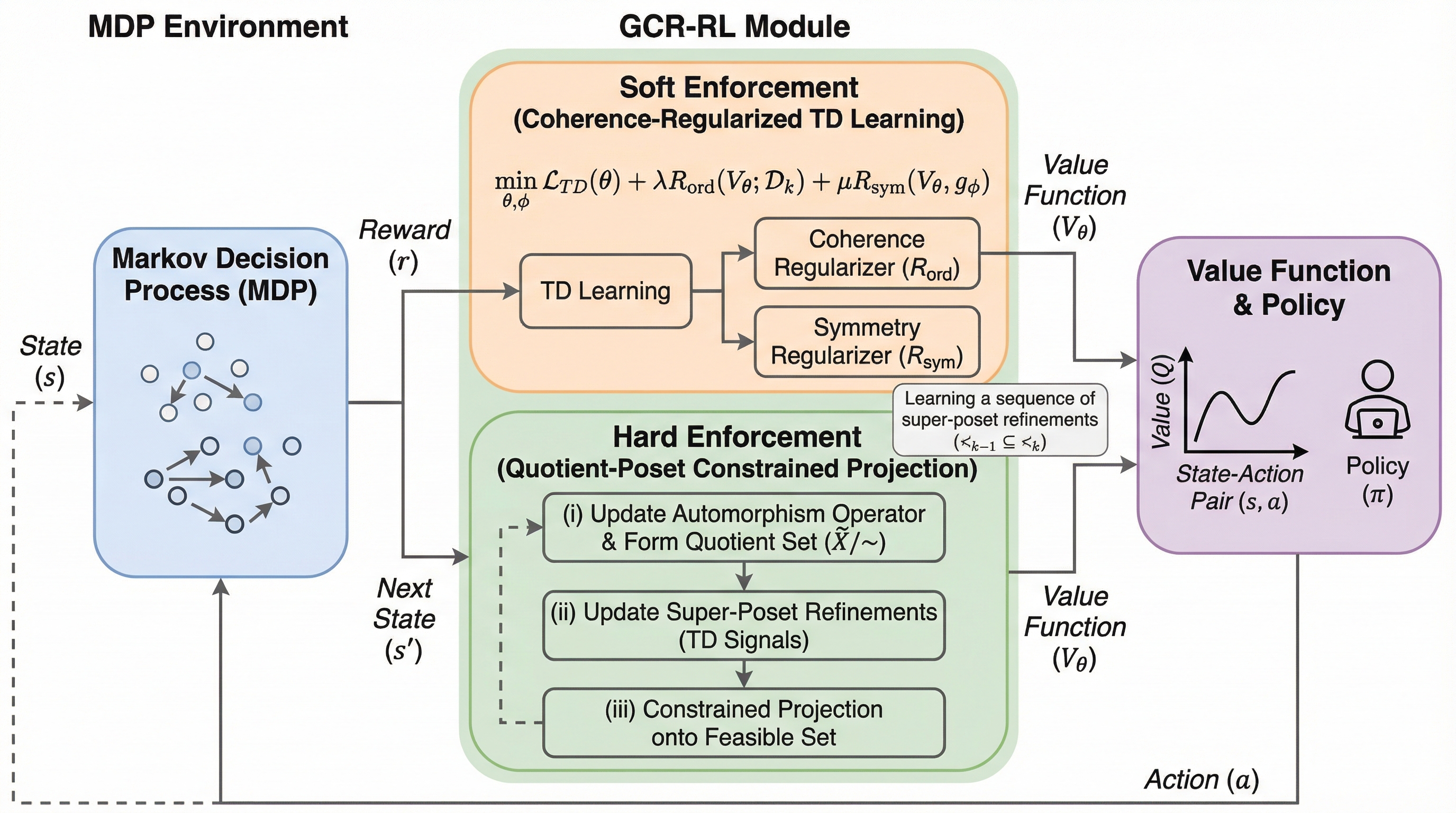
核心:何を提案したのか
本論文の核心的な提案は、強化学習における価値関数の学習を「所望の半順序集合(poset)を構築するプロセス」として再定義したことです。著者らは、状態と行動のペアを要素とし、最適な行動を決定するために必要な最小限の半順序関係を持つ集合を学習の対象と見なしました。この視点に基づき、幾何学的整合性正則化強化学習(GCR-RL)と呼ばれる新しいフレームワークを提案しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related