3D-Learning:拡散拡張された分布頑健な意思決定重視学習
機械学習による予測を意思決定に活用するPredict-then-Optimize(PTO)において、テスト時のデータ分布の変化(OOD)による性能劣化を防ぐため、拡散モデルを用いて最悪のシナリオを想定し学習する「3D-Learning」フレームワークを提案した。
TL;DR(結論)
機械学習による予測を意思決定に活用するPredict-then-Optimize(PTO)において、テスト時のデータ分布の変化(OOD)による性能劣化を防ぐため、拡散モデルを用いて最悪のシナリオを想定し学習する「3D-Learning」フレームワークを提案した。 従来の分布頑健最適化(DRO)が抱えていた、データのサポート(存在範囲)が変化するような分布シフトに対応できないという数学的な制約を、拡散モデルのパラメータ空間内で最悪の分布を探索する新しい曖昧さ集合の定義によって克服している。 大規模言語モデル(LLM)のリソース割り当てタスクを用いた実験では、既存のDRO手法やデータ拡張手法を大幅に上回る汎化性能を示し、特に最悪ケースにおける損失の低減と、入力ノイズに対する極めて高い安定性を実現することに成功した。
なぜこの問題か
現代の計算システムや通信ネットワークの運用において、機械学習モデルを用いて将来の状況を予測し、その結果を後続の意思決定タスクに利用する「Predict-then-Optimize(PTO)」パイプラインは、非常に重要な役割を担っている。具体的な応用例としては、クラウドにおける大規模言語モデル(LLM)のサービング、データセンターにおけるデマンドレスポンス、エッジコンピューティングにおけるワークロードのスケジューリングなどが挙げられる。しかし、これらのシステムで用いられる機械学習モデルは、テスト時に学習時のデータ分布とは異なる「分布外(Out-of-Distribution, OOD)」のサンプルに直面すると、予測誤差が急増し、結果として意思決定の質が大幅に劣化するという深刻な脆弱性を抱えている。 特にPTOアプリケーションにおいては、意思決定の性能が特定の種類の予測誤差に対して非常に敏感であるという非対称な特徴がある。例えば、クラウドのリソースプロビジョニングにおいて、ワークロードを過小評価してしまうと深刻なサービス品質の低下(SLA違反)を招く一方で、過大評価は単に追加の電力コストが発生するだけで済む場合がある。…
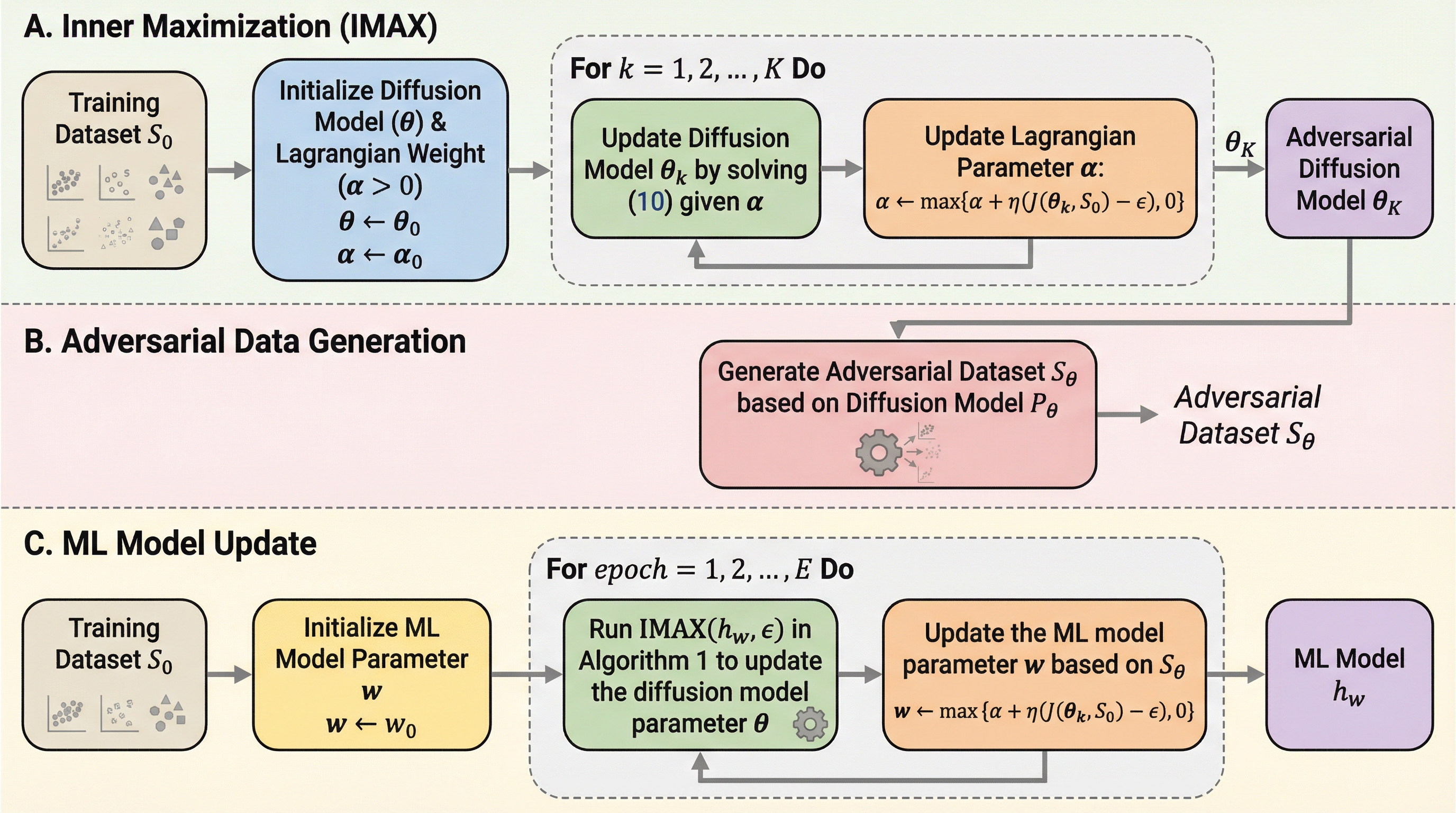
核心:何を提案したのか
本論文では、分布のシフトに対して高い耐性を持つ意思決定を実現するために、「分布頑健な意思決定特化型学習(Distributionally Robust Decision-Focused Learning, DR-DFL)」という新しい枠組みを導入し、その具体的な実現手法として「3D-Learning(Diffusion-Augmented Distributionally Robust Decision-Focused Learning)」を提案している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related