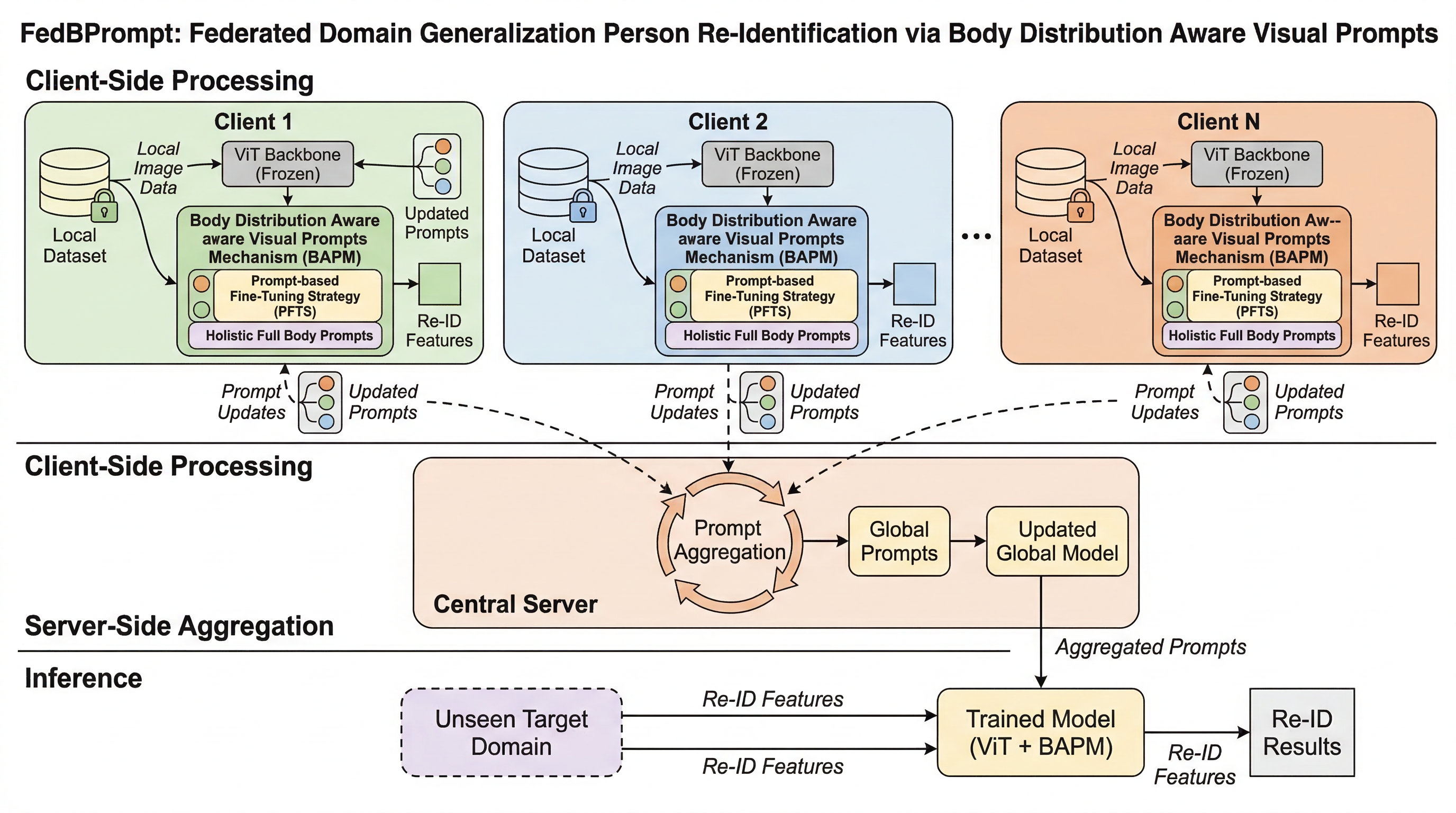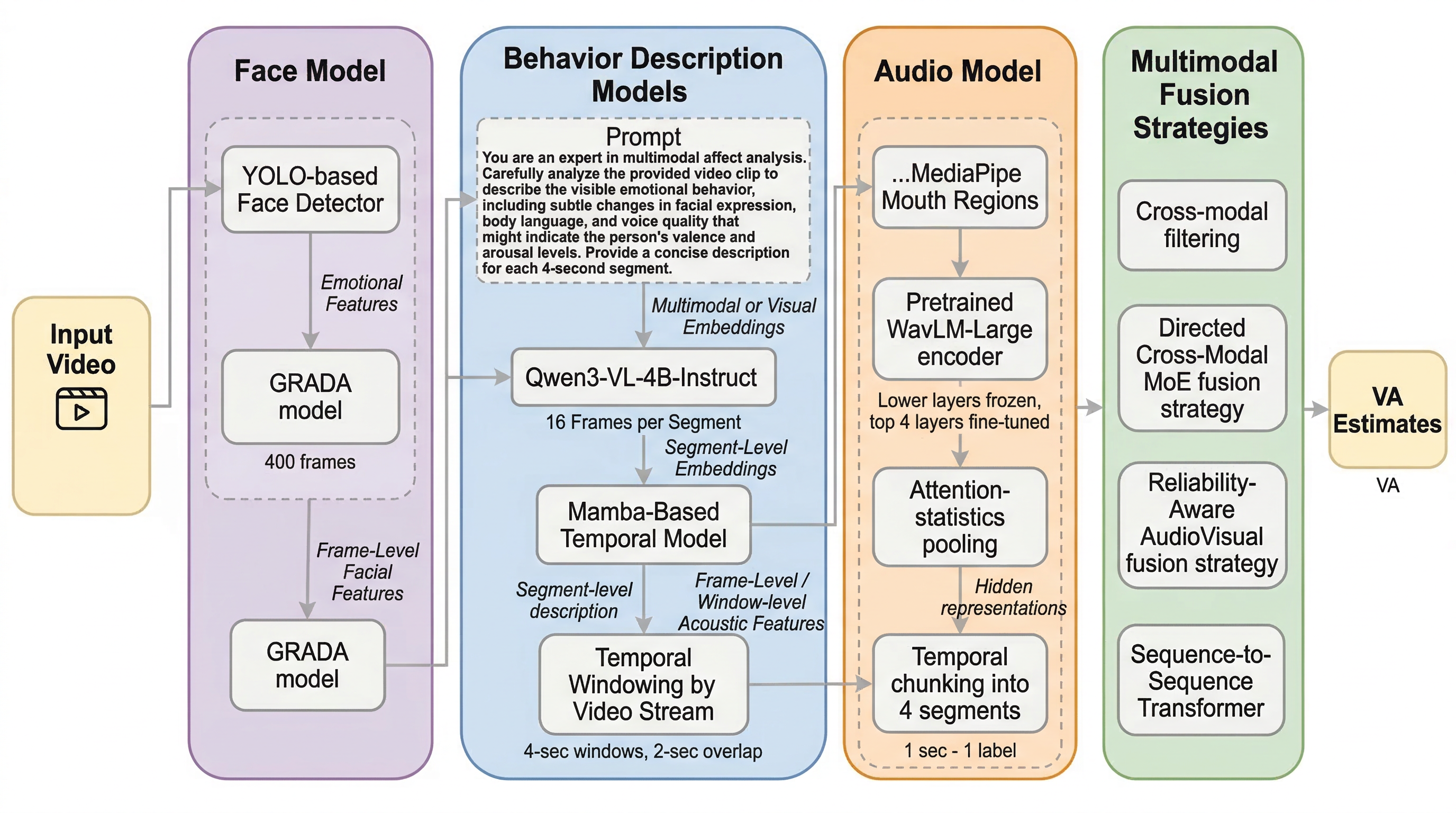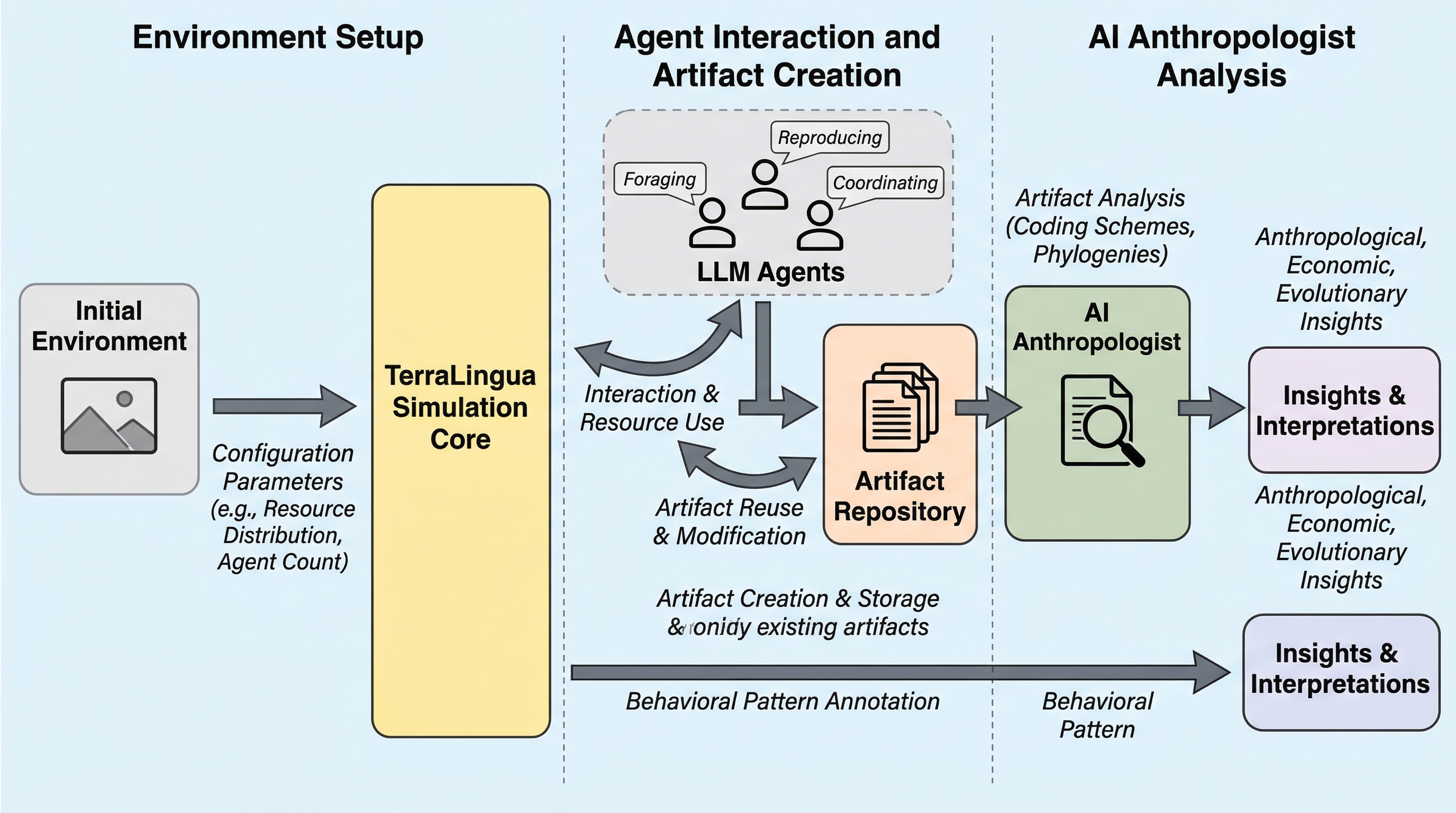
TerraLingua:LLMどうしの社会に文化の蓄積は生まれるのかを測る生態系実験基盤
TerraLinguaは、LLMエージェントを「その場限りの会話相手」ではなく、資源制約・寿命・共有人工物を持つ持続的な生態系に置き、協力規範や分業、統治の芽生え、人工物の系譜がどの条件で立ち上がるかを調べる実験基盤です。 核心は、世界そのものを持続させる環境と、そのログを後段で読むAI Anthropologistを組み合わせた点にあります。エージェントの個別行動だけでなく、集団構造、人工物の複雑化、共有文化の発生を同時に追跡できます。 実験では、単に賢いモデルや豊富な資源があれば開放的発展が起きるわけではなく、資源圧力、認知負荷、動機づけ、人工物へのアクセスが釣り合った条件で初めて、長寿命の社会と継続的な創造の両立が起きることを示しました。