顔・行動・音声をどう混ぜると感情が読めるか:ABAW 競技で試した 感情価・覚醒度 推定の実践設計
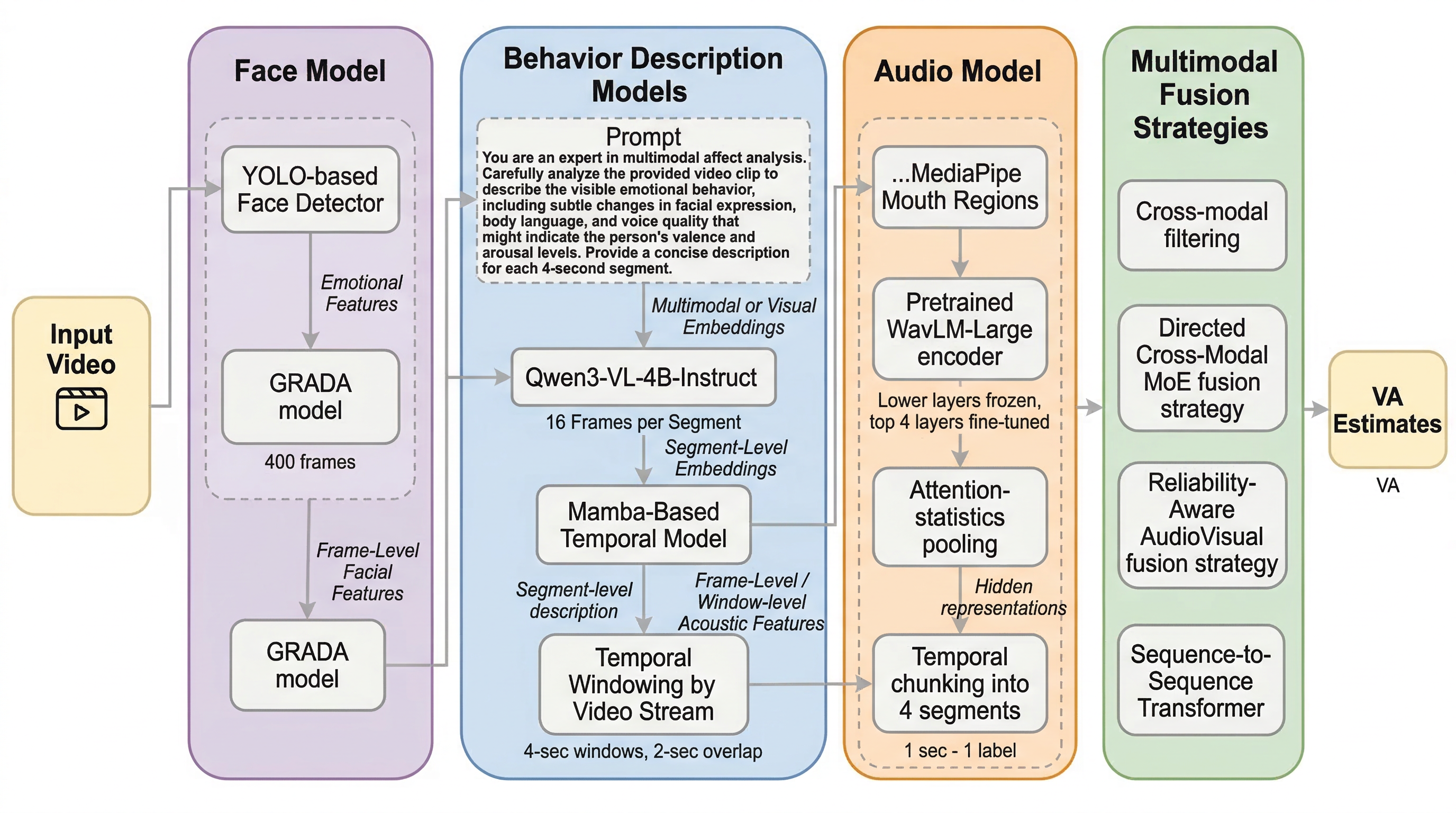
自然環境下での感情推定では、顔だけ、音声だけ、行動だけでは取りこぼしが大きい。提案手法は 顔、行動、音声の3モダリティを組み合わせ、valence と arousal を連続値で推定する競技向けマルチモーダル構成です。 行動側では Qwen3-VL-4B-Instruct から得た 行動記述に寄った埋め込み表現 を Mamba で時間モデリングし、音声側では WavLM-Large に 口の開き方を使ったモダリティ横断フィルタリング を組み合わせています。融合は 指向付きクロスモーダルMixture-of-Experts と 信頼度考慮型の音声・映像融合 の 2 系統で比較します。 Aff-Wild2 の開発セットでは、単体の顔モデル平均 一致相関係数(CCC) 0.6189 に対し、3 モダリティ融合で 0.6487、さらに RAA-V では 0.6576 まで向上しました。大きな新理論というより、信頼度の違う情報源をどう役割分担させるかで性能を押し上げた実装論文です。
TL;DR(結論)
- 自然環境下での感情推定では、顔だけ、音声だけ、行動だけでは取りこぼしが大きい。提案手法は 顔、行動、音声の3モダリティを組み合わせ、valence と arousal を連続値で推定する競技向けマルチモーダル構成です。
- 行動側では Qwen3-VL-4B-Instruct から得た 行動記述に寄った埋め込み表現 を Mamba で時間モデリングし、音声側では WavLM-Large に 口の開き方を使ったモダリティ横断フィルタリング を組み合わせています。融合は 指向付きクロスモーダルMixture-of-Experts と 信頼度考慮型の音声・映像融合 の 2 系統で比較します。
- Aff-Wild2 の開発セットでは、単体の顔モデル平均 一致相関係数(CCC) 0.6189 に対し、3 モダリティ融合で 0.6487、さらに RAA-V では 0.6576 まで向上しました。大きな新理論というより、信頼度の違う情報源をどう役割分担させるかで性能を押し上げた実装論文です。
なぜこの問題か
感情認識は古くから研究されてきましたが、現実環境での連続的な 感情価・覚醒度 推定は今でも難題です。理由は単純で、感情表出は顔だけに出るとは限らず、しかも顔が見えていても照明、頭部姿勢、遮蔽、個人差で読み取りやすさが大きく変わるからです。音声も有力ですが、雑音や無音、口の動きと音の非同期が入る。行動文脈は有用でも、単純なフレーム特徴では取りにくい。結果として、どれか一つのモダリティへ頼ると、状況が少し変わっただけで崩れやすくなります。
核心:何を提案したのか
提案の核は、三つのモダリティを役割分担つきで統合するマルチモーダル構成です。第一の face modality は、GRADA ベースのフレーム埋め込み と Transformer による時系列回帰 を使います。顔は valence と arousal の主信号源なので、ここが基礎性能の土台です。実際、単体モデルでも平均 一致相関係数(CCC) 0.6189 と、他の単体モダリティより明確に強い。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related