SSDの意味勾配をどう安定して読むか:PCA sweepで次元選択の恣意性を絞る
Supervised Semantic Differential(SSD)は、テキスト意味のずれを心理尺度などの連続変数に沿って読む混合的手法ですが、PCA の次元数 K をどう選ぶかに系統的な基準がなく、研究者の裁量が入りやすいという弱点を抱えていました。 著者らは、表現容量、意味勾配の解釈可能性、近傍の K に対する安定性を同時に見て K を選ぶ PCA sweep を提案し、AI に関する短文投稿とナルシシズム尺度のケーススタディで、その有効性を示しています。 事例では Admiration に関して K=15 の安定で解釈しやすい意味勾配が得られ、AI を協調的・前向きに語る側と、不信・嘲笑・敵対で語る側が対置されましたが、Rivalry では頑健な整列が出ず、方法上の慎重さも同時に確認されました。
TL;DR(結論)
- Supervised Semantic Differential(SSD)は、テキスト意味のずれを心理尺度などの連続変数に沿って読む混合的手法ですが、PCA の次元数 K をどう選ぶかに系統的な基準がなく、研究者の裁量が入りやすいという弱点を抱えていました。
- 著者らは、表現容量、意味勾配の解釈可能性、近傍の K に対する安定性を同時に見て K を選ぶ PCA sweep を提案し、AI に関する短文投稿とナルシシズム尺度のケーススタディで、その有効性を示しています。
- 事例では Admiration に関して K=15 の安定で解釈しやすい意味勾配が得られ、AI を協調的・前向きに語る側と、不信・嘲笑・敵対で語る側が対置されましたが、Rivalry では頑健な整列が出ず、方法上の慎重さも同時に確認されました。
なぜこの問題か
SSD は、言葉の意味を単に頻度やトピックで見るのではなく、個人差変数に沿って「どんな意味の傾きがあるか」を読む方法です。心理学の Semantic Differential と、分布意味論・埋め込み表現をつなぎ、ある概念やテキスト集合が、たとえば態度尺度や性格特性に応じてどちらの極へ寄るのかを、埋め込み空間の方向として捉えます。定量と解釈を往復できるのが魅力です。
核心:何を提案したのか
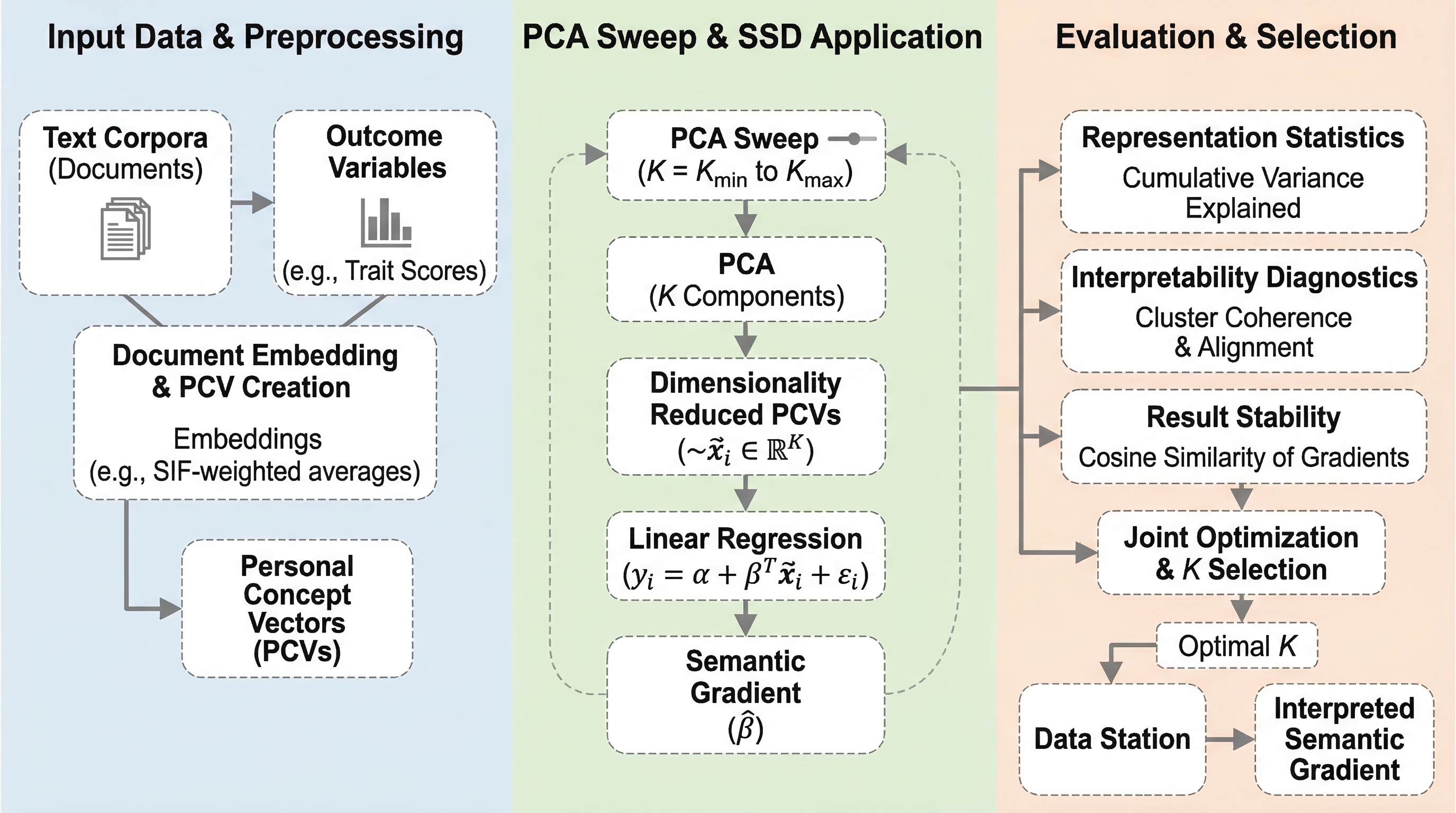
提案の核は PCA sweep です。著者らは、K の選択を単一指標の最適化ではなく、三つの観点を束ねた joint optimization problem として扱います。その三つとは、第一に次元圧縮後の表現がどれだけ情報を持っているか、第二に得られた意味勾配がどれだけ解釈しやすいか、第三に K を少し変えたとき勾配がどれだけ安定しているかです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related