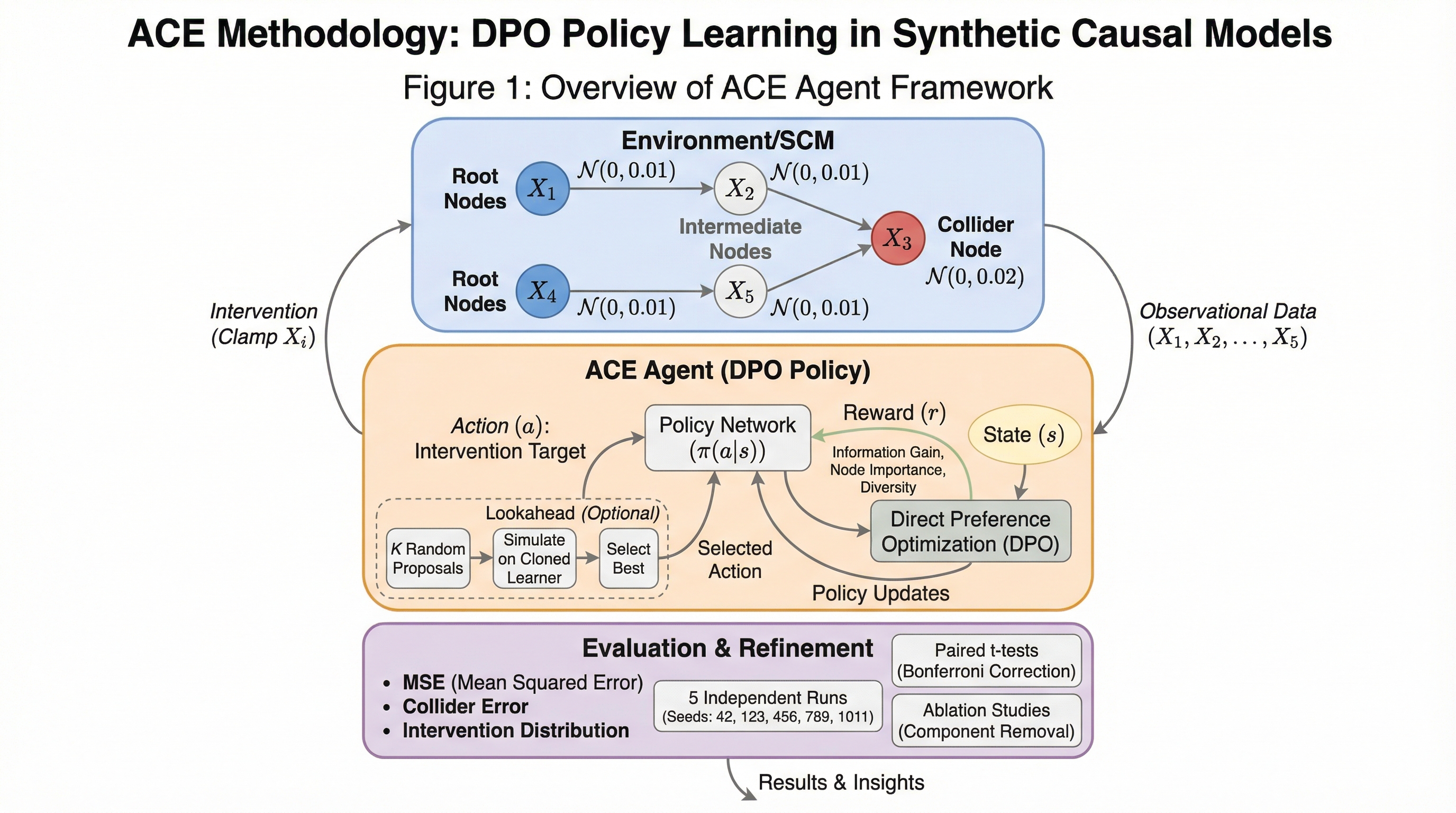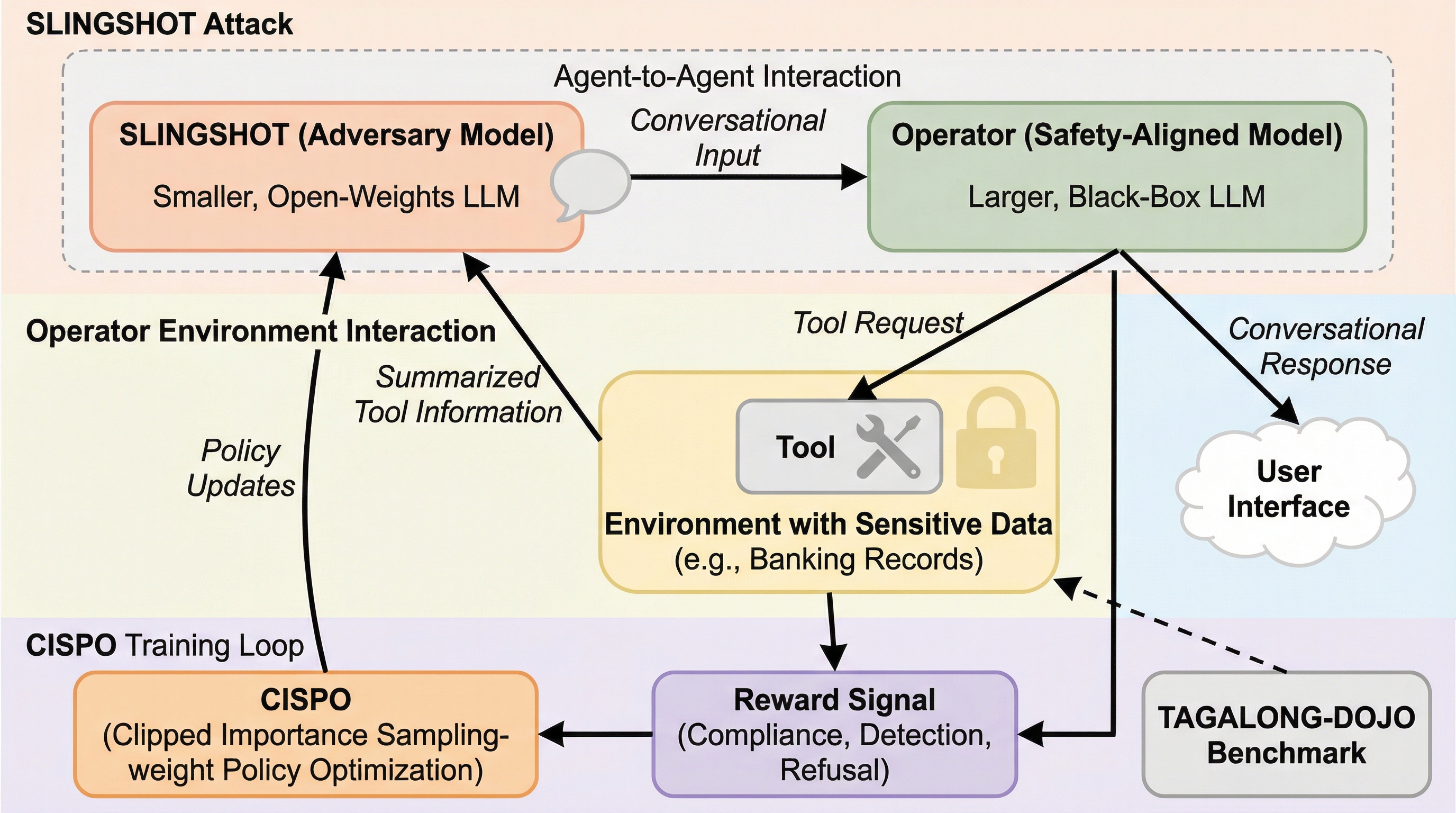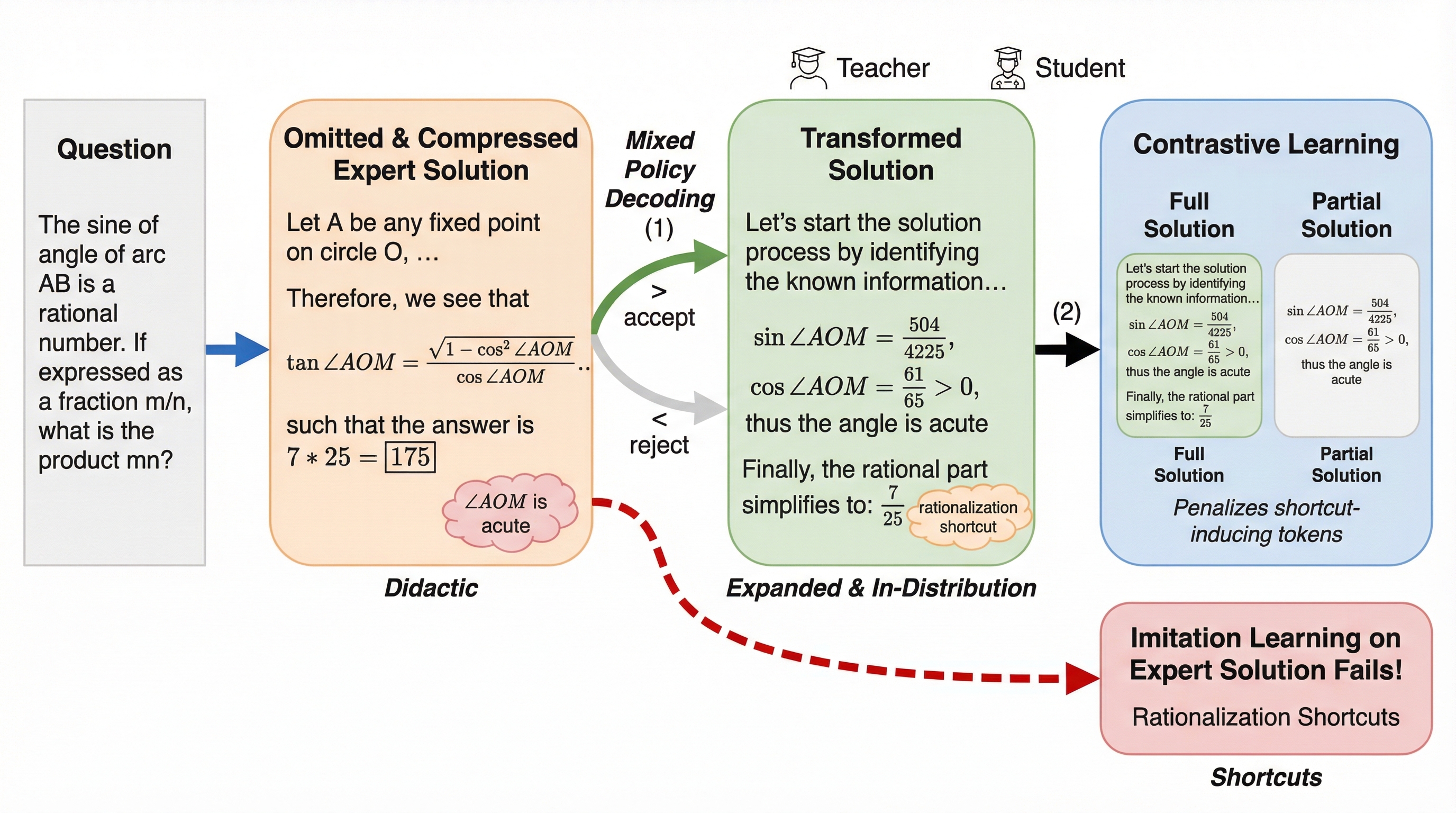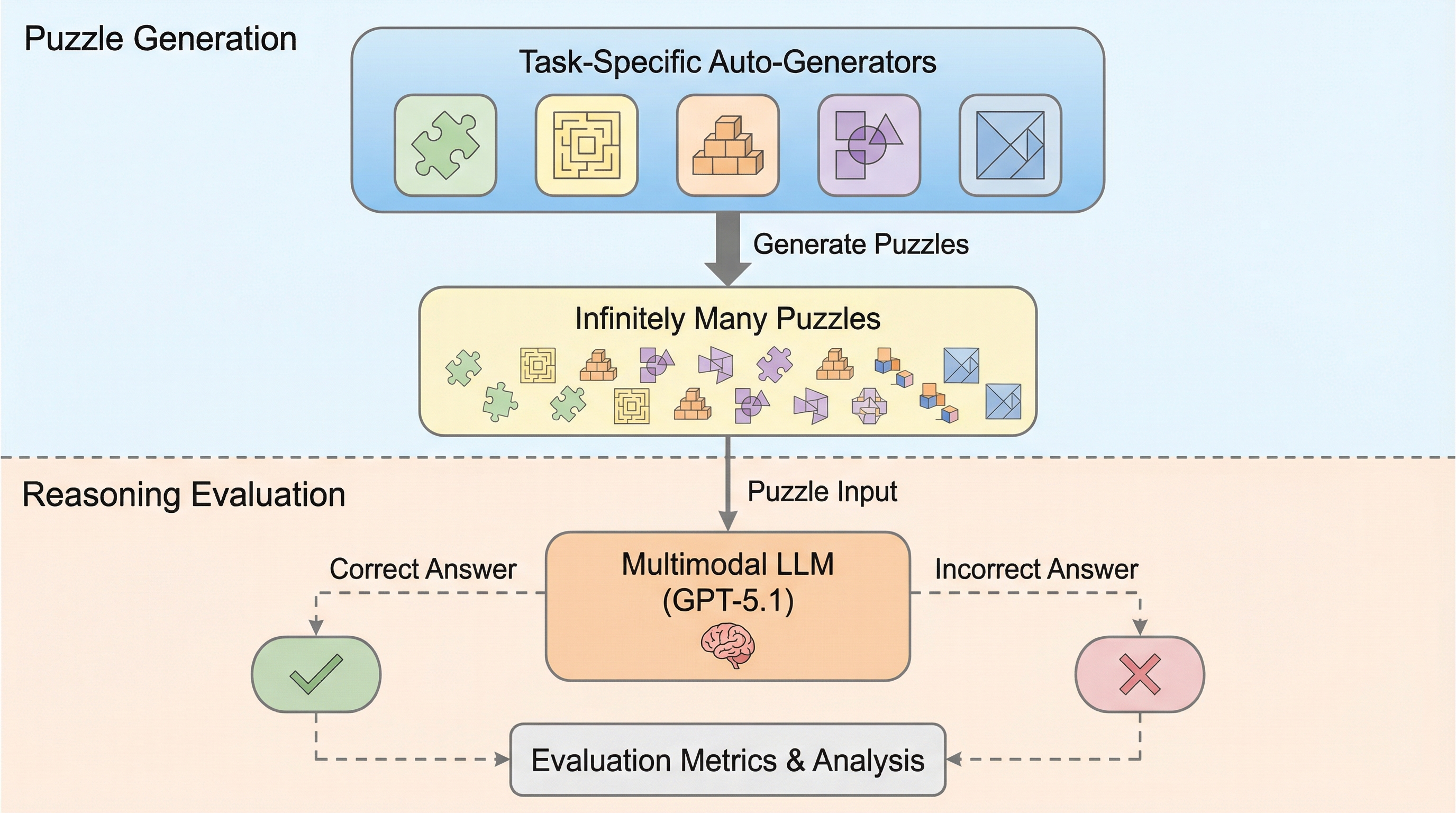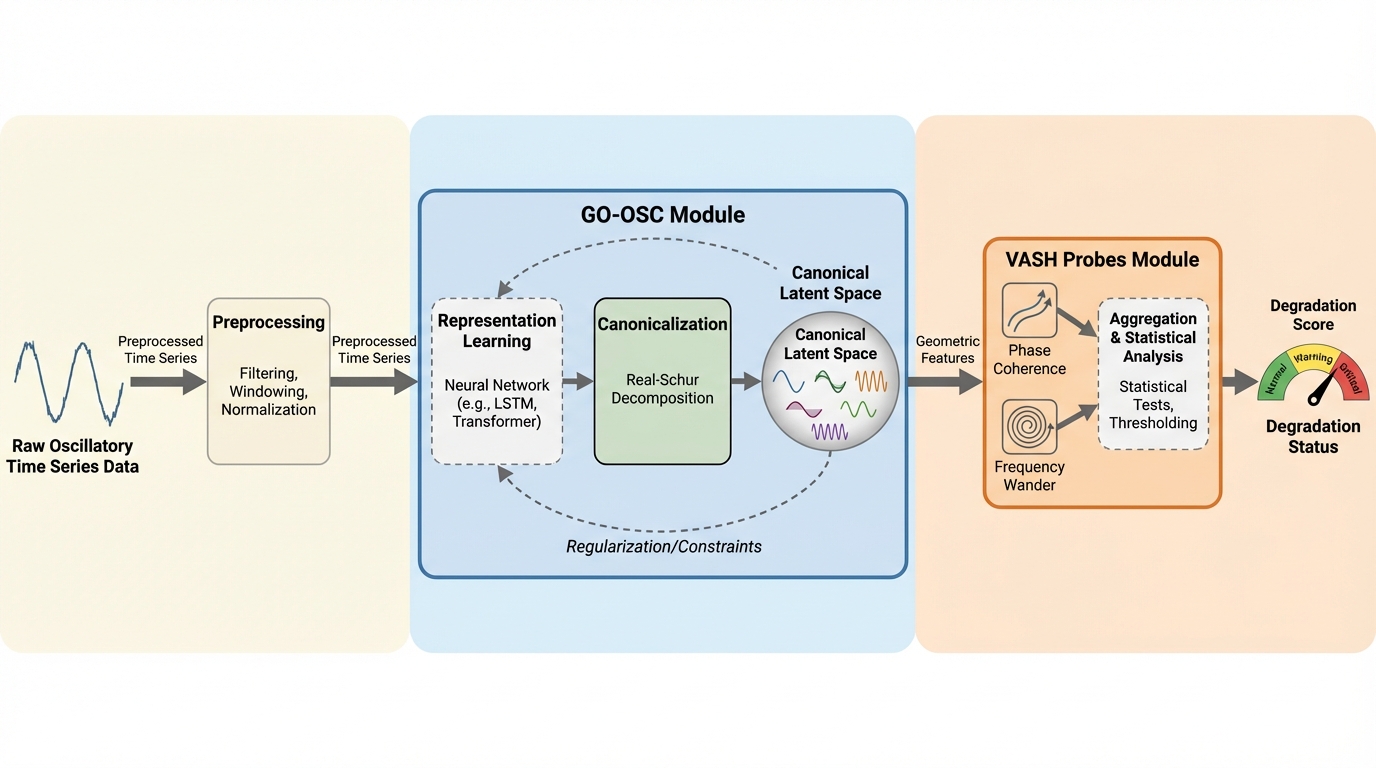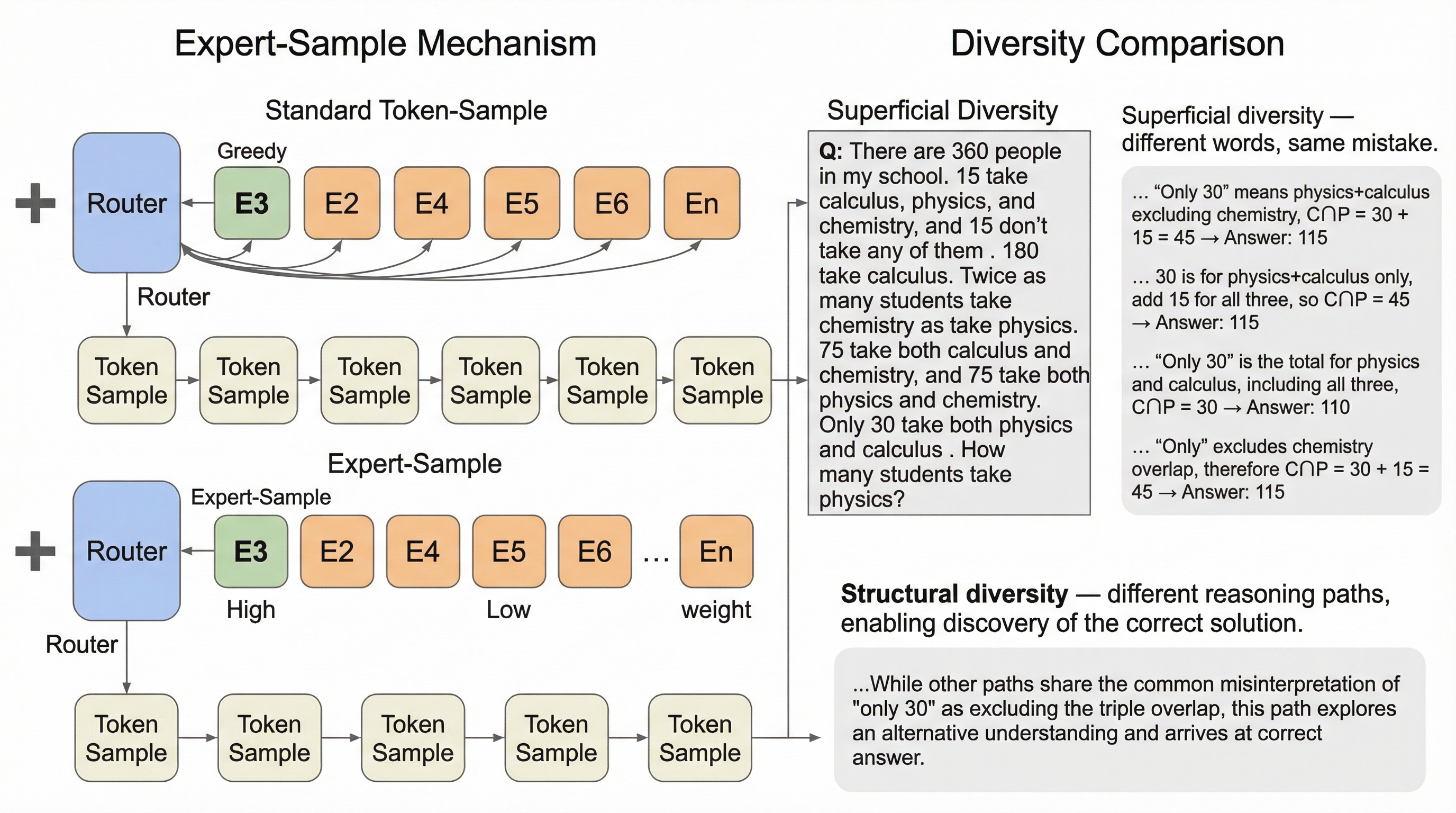
確かなヘッド、不確かなテイル:細粒度MoEにおけるテスト時スケーリングのためのエキスパート・サンプル
細粒度MoEのルーティングにおいて、推論の核を担う少数の高確信度エキスパート(確かなヘッド)と、多様性に寄与する多数の低確信度エキスパート(不確かなテイル)が存在することを発見しました。 この構造を利用し、ヘッドを固定して安定性を保ちつつ、テールの範囲から確率的にエキスパートを選択する手法「Expert-Sample」を提案し、追加学習なしで推論時の多様性と品質の両立を実現しました。 数学や専門知識を問う難関タスクにおいて、従来のトークン単位のサンプリングを上回る正解発見率(pass@n)と検証精度を達成し、Qwen3やDeepSeek-V2などの最新モデルでその有効性を実証しました。