「教科書的な解答」を「学べる推論」に変える:DAILという発想
難問で、LLMはどうやって“学ぶための手がかり”を手に入れるべきなのでしょうか? 正解が出ないなら強化学習は止まり、模範解答を真似ても逆に崩れる──ここが意外な落とし穴です。 この記事では、専門家の解答を“学習可能な推論”へ変換して使うDAILの狙いと仕組みを、論文の範囲で追います。
論文図解
TL;DR(結論)
- 正解が出ないなら強化学習は止まり、模範解答を真似ても逆に崩れる──ここが意外な落とし穴です。
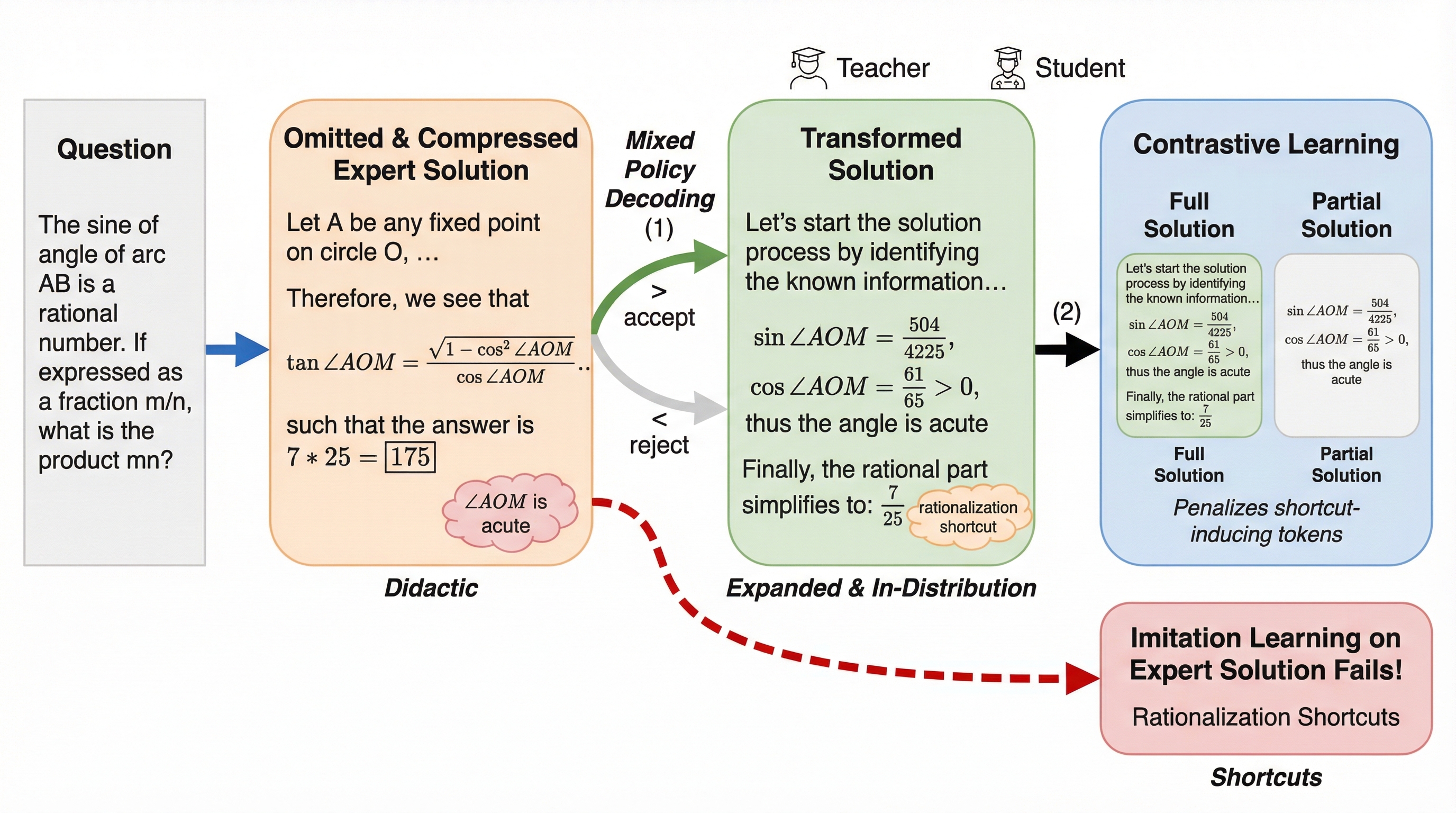
- 論文が提案するのは Distribution Aligned Imitation Learning(DAIL) という2段階の方法です。
- 狙いは一言でいえば、「専門家の解答」をそのまま真似るのではなく、まず“モデルが学べる形”に作り替えてから学ぶこと。
なぜこの問題か
大規模言語モデルの推論能力を伸ばす定番ルートは、ざっくり2つに寄っています。 1つは、モデルがたまたま正解をサンプルできることを前提に、それを強化するやり方。もう1つは、より強いモデルの助けを借りるやり方です。どちらも「正しい軌跡」や「正しい判断」を、何らかの形で手に入れられることが出発点になります。
核心:何を提案したのか
論文が提案するのは Distribution Aligned Imitation Learning(DAIL) という2段階の方法です。 狙いは一言でいえば、「専門家の解答」をそのまま真似るのではなく、まず“モデルが学べる形”に作り替えてから学ぶこと。ここでの主役は「解答」そのものよりも、解答へ至るプロセスを、モデル側の学習都合に合わせて再設計する手続きです。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related