心の目は、AIの推論を強くするのか――MentisOculiが暴く「メンタルイメージ推論」の限界
AIに「途中の図」を描かせれば、難しい推論はもっと解けるようになる? ところが最先端モデルほど、絵を挟んでも強くならない場面がある。むしろ、図を入れたことで“別の失敗”が増えてしまう可能性すら見えてくる。 この記事では、MentisOculiが何を測り、どこでつまずきが起きるのかを追いかける。
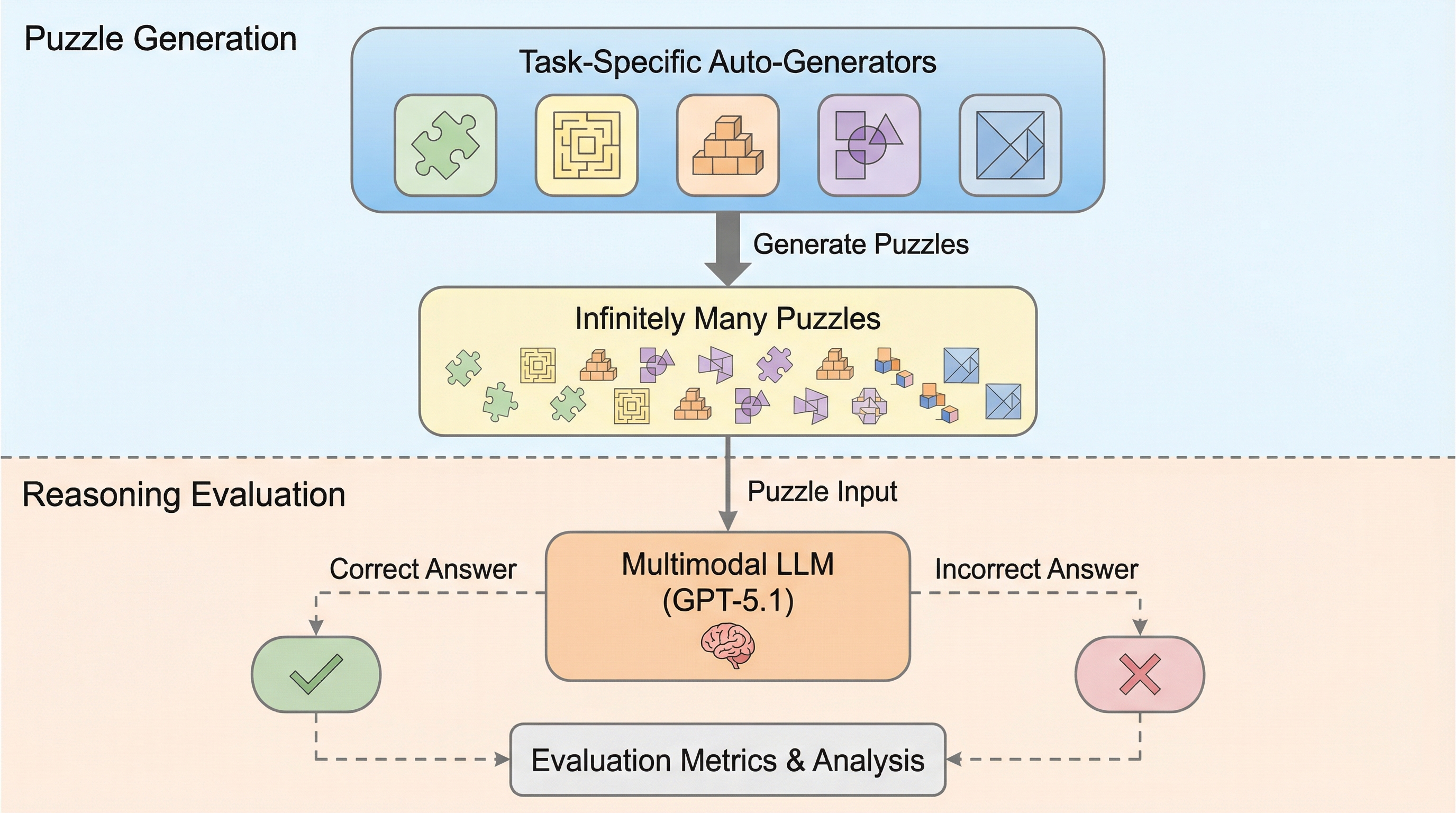
論文図解
TL;DR(結論)
- 提案の中心は、MentisOculi(MENTISOCULI)というベンチマークです。
- 狙いは、モデルが「目的に沿って、視覚表現を作り、保ち、何度も操作する」能力を包括的に調べることにあります。
- MentisOculiの課題は、「視覚的な解法が自然に成立する」タイプに寄せられています。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLMs)は、長いあいだ「画像は入力、言語が推論の舞台」という形になりがちでした。画像が入っていても、推論の“手順”そのものはテキストで進み、視覚は受け身の情報源になりやすい、という構図です。 しかし最近は、テキストと画像などを自然に織り交ぜて生成できる統合マルチモーダルモデル(UMMs)へと移行しつつあります。この移行は、単に出力が増えたというより、「推論の途中に視覚を差し込める」余地を現実的にした、という意味で大きい。
核心:何を提案したのか
提案の中心は、MentisOculi(MENTISOCULI)というベンチマークです。狙いは、モデルが「目的に沿って、視覚表現を作り、保ち、何度も操作する」能力を包括的に調べることにあります。 ここで問われるのは、単発でそれっぽい図を出せるかどうかだけではありません。多段の途中で表現を更新し、その更新が次の判断を支え、さらに次の更新につながる――という連鎖が成立するかが焦点になります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related