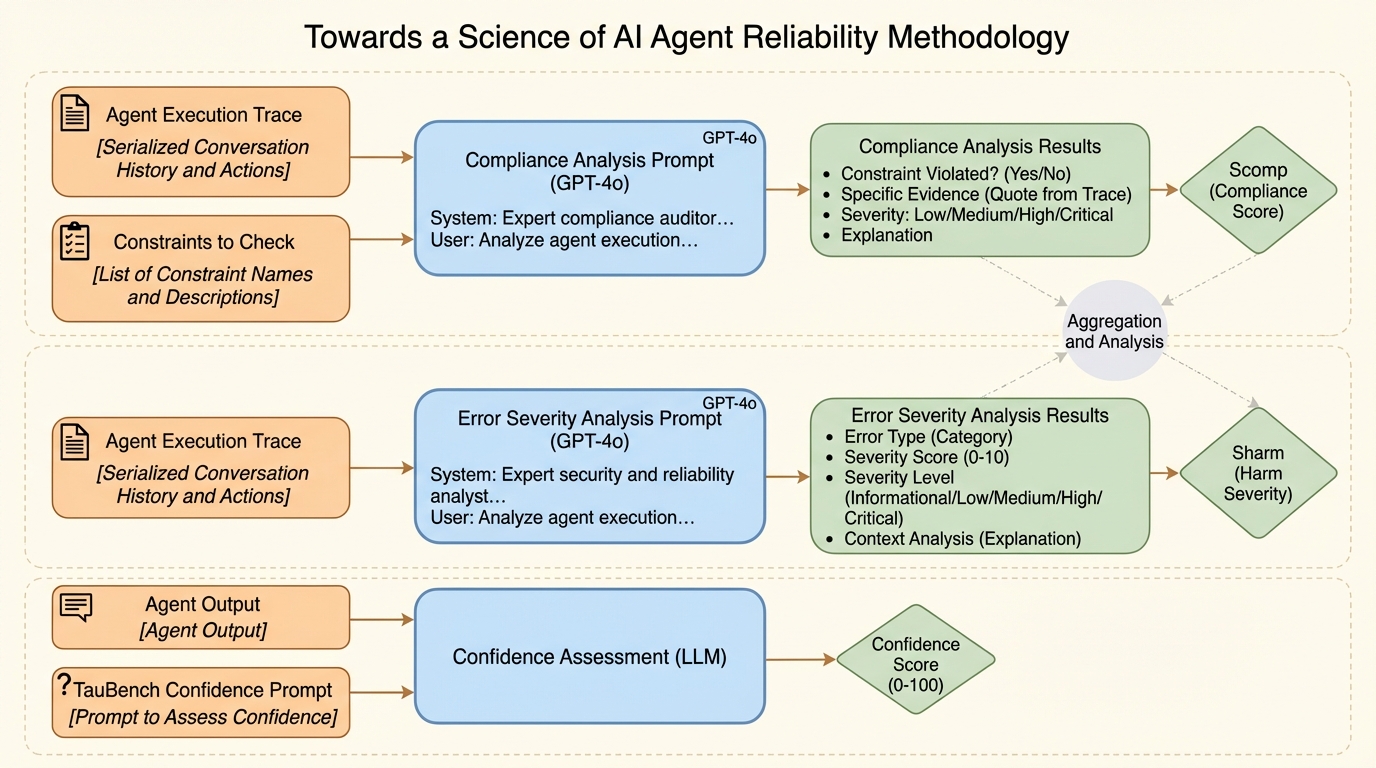
AIエージェントの信頼性を科学する:単一の成功率を超える12の指標で見える「運用上の弱さ」
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ベンチマークの平均的な成功率が上がっても、実運用で求められる「同じ条件なら同じように動くか」「少しの外乱で壊れないか」「失敗が予測できるか」「失敗しても被害が抑えられるか」は見えにくく、単一の成功率だけでは重要な弱点が隠れます。
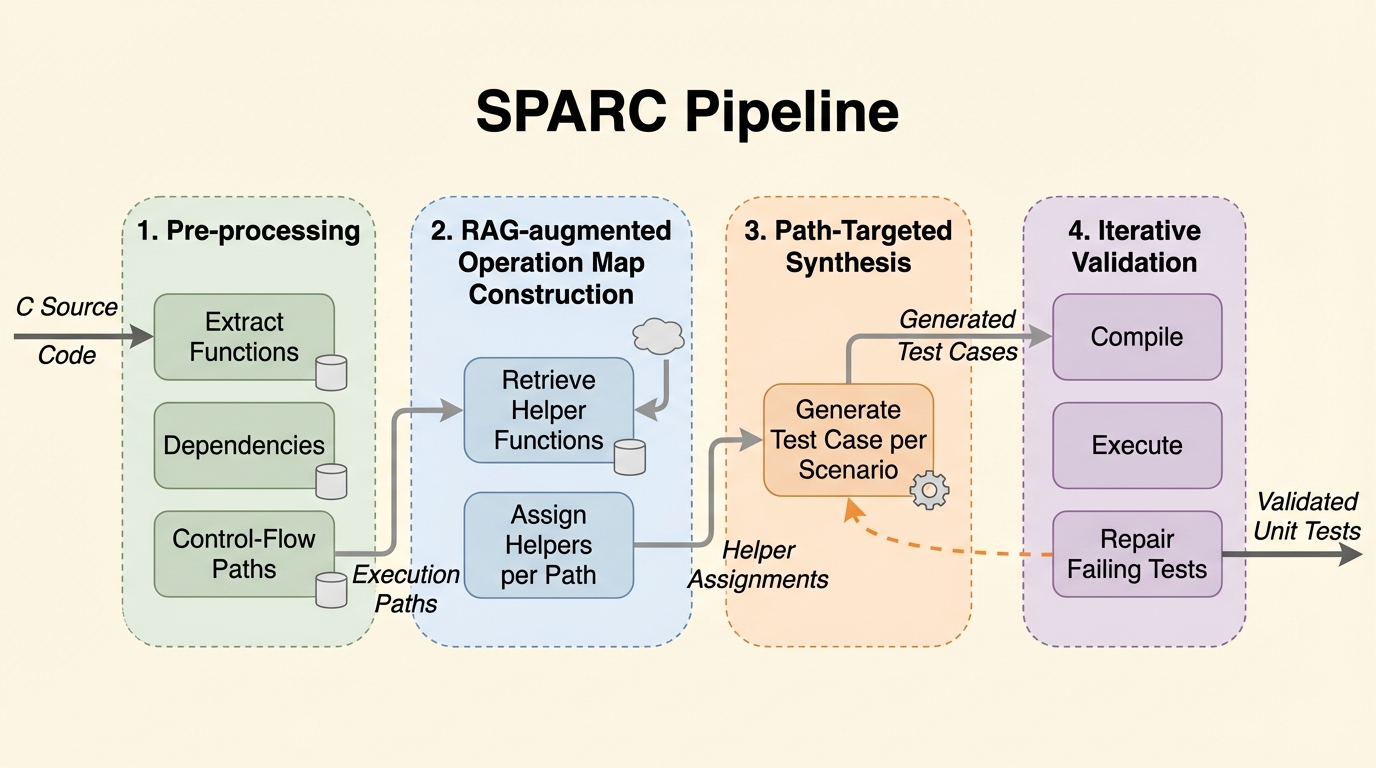
Cではポインタ演算や手動メモリ管理の制約が強く、LLMに意図だけを渡してテストを書かせると、正常系に偏ったり依存関係を捏造したりして、コンパイル不能や意味の薄いアサーションになりやすいです。 / SPARCは制御フローグラフから実行パスごとのシナリオを抽出し、検証済みヘルパーに基づく操作マップで呼び出し先を制限したうえで、パス単位のテスト生成とコンパイル・実行フィードバックによる反復修復を行います。 / 59件の対象で単純なプロンプト生成より行・分岐カバレッジとミューテーションスコアが向上し、複雑な対象ではKLEEに匹敵または上回り、修復後にテストの大半が残って可読性と保守性の評価も高まりました。
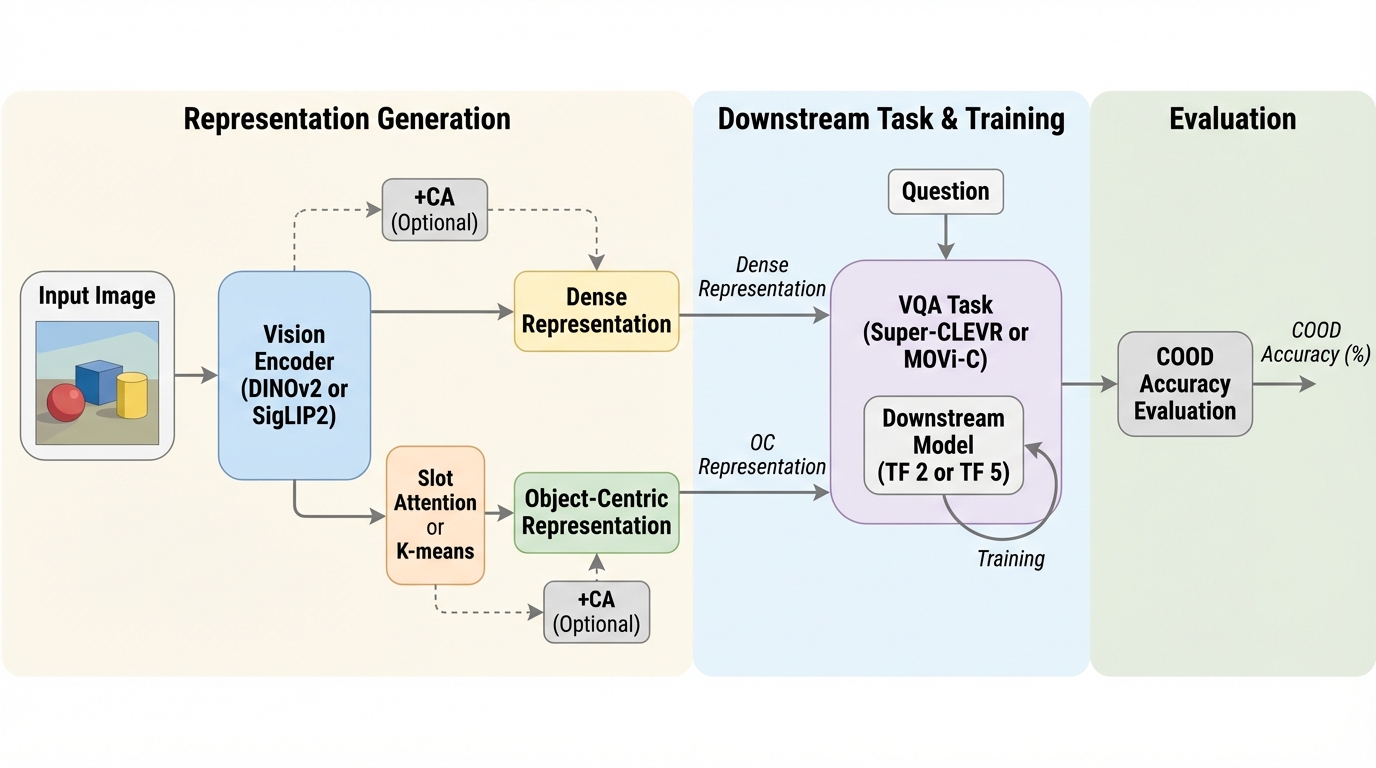
見慣れた属性を材料に「未学習の組み合わせ」を扱う合成的一般化では、物体中心(OC)表現がとくに難しい条件で優位になりやすく、データ量・多様性・下流計算量のいずれかが制約されると強みが出やすいです。
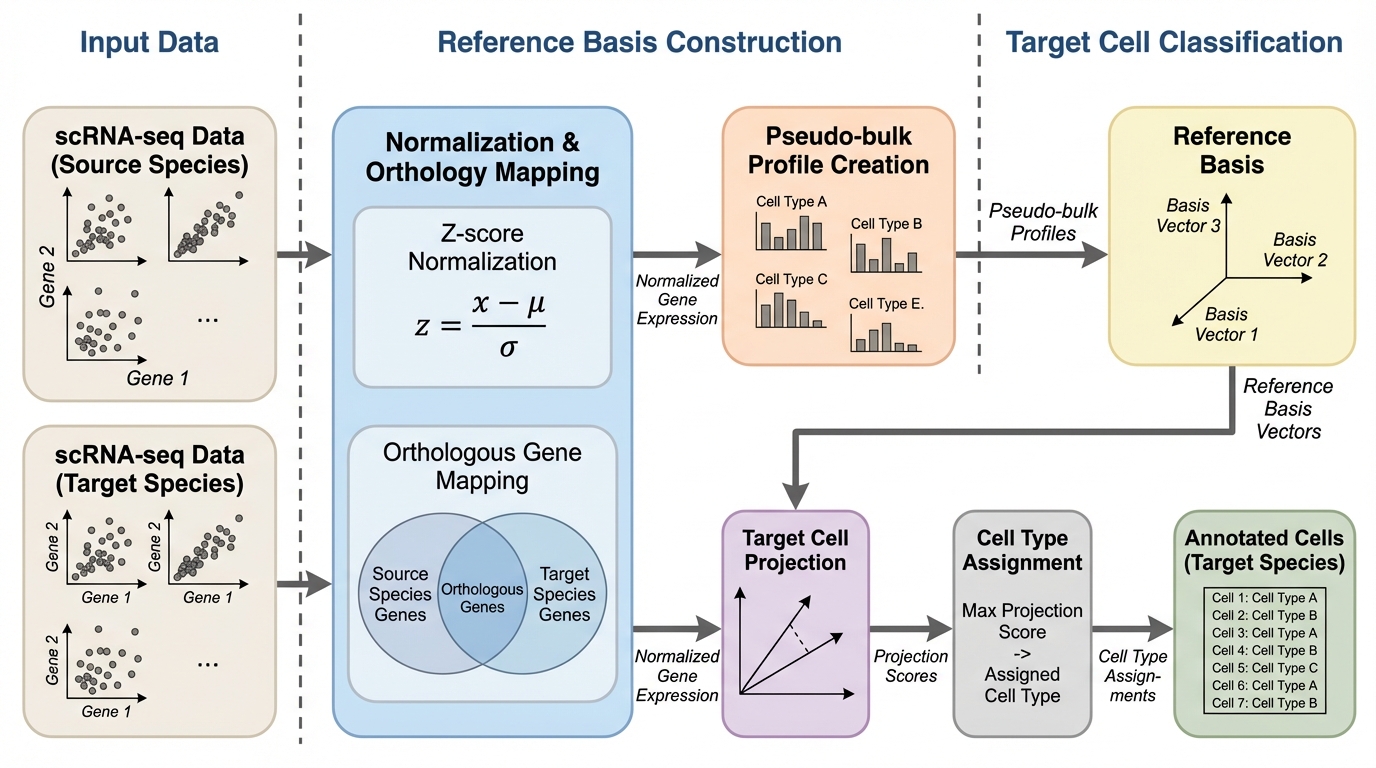
単一細胞RNAシーケンスの代表的な下流ベンチマークでは、大規模な基盤モデルの埋め込みを使わなくても、細胞内正規化と線形手法を中心にした単純で解釈可能な表現で最先端級、またはそれに近い性能に到達できると示しています。
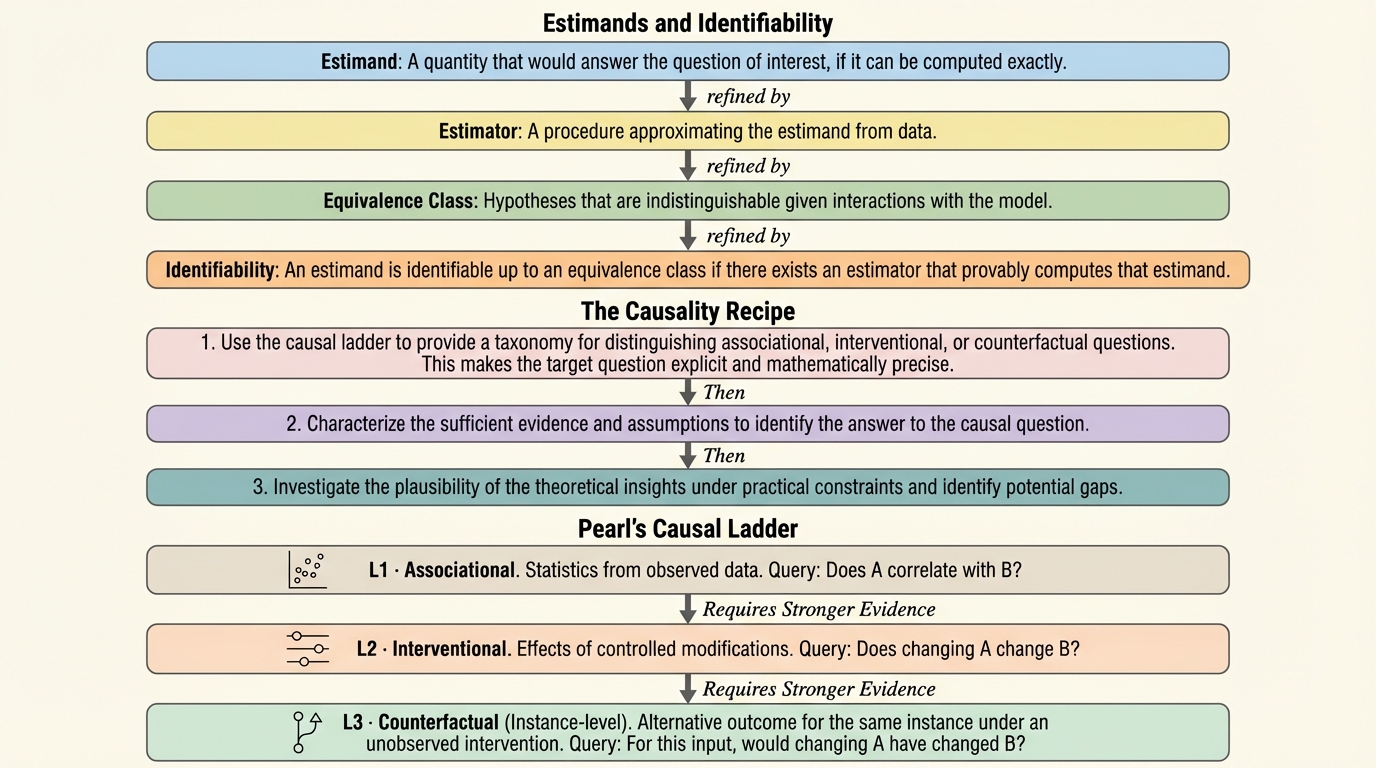
大規模言語モデルの解釈可能性研究は有益な道具立てを増やしてきましたが、観測や介入で得た証拠の範囲を越えて因果的・反事実的に語ると、別条件で再現せず一般化しない落とし穴が残ります。 / 因果推論の語彙を使って、相関・介入効果・反事実という問いの段を区別し、狙う量(推定したい量)と許す介入の範囲、証拠から区別できない説明のまとまり(同値類)を明示して、主張と評価の対応を固定します。 / 反事実の主張は制御された監督がないと大部分が検証しにくく、因果表現学習は「活性から何が、どの仮定の下で復元可能か」を整理するため、実務で方法選択と評価設計を診断的に進める含意があります。
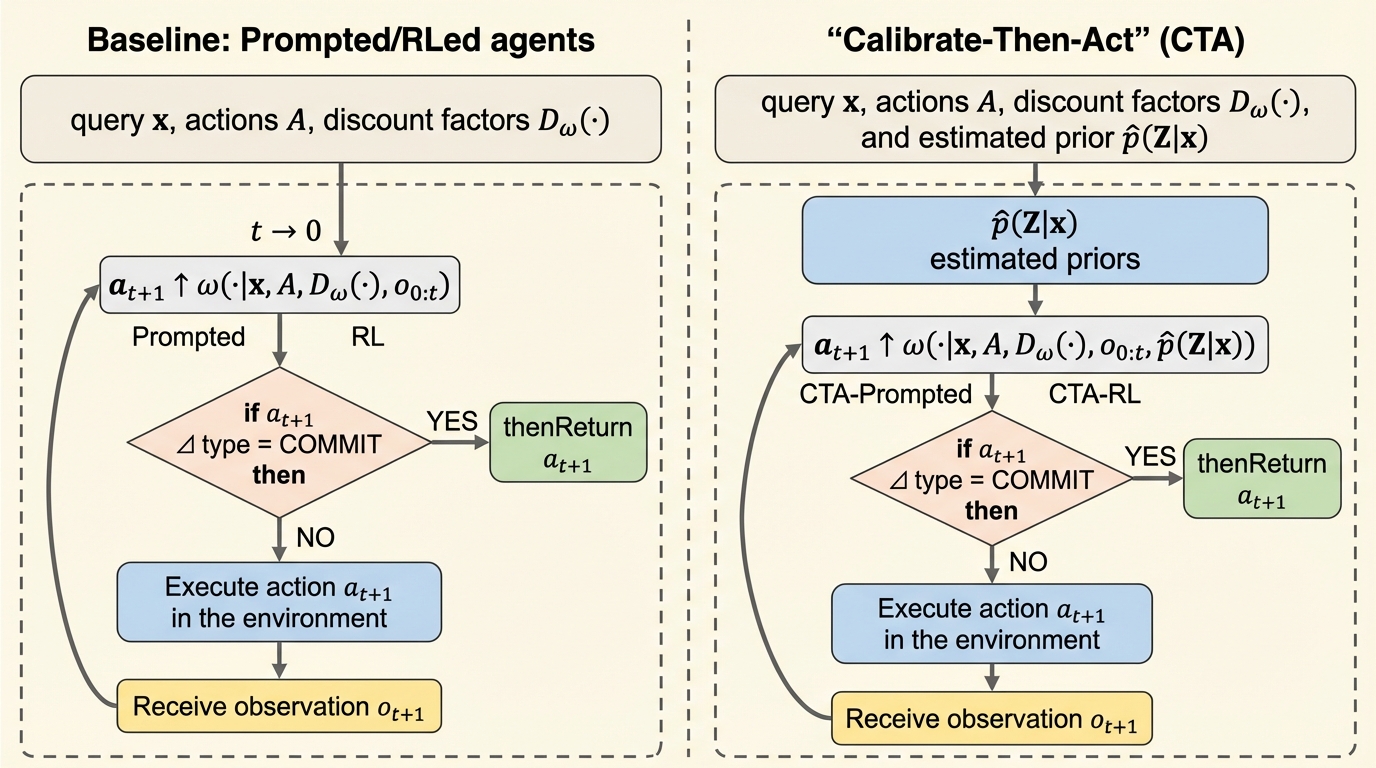
単発回答で終わらないタスクでは、追加で調べるほど時間や手間のコストが増える一方、早く確定すると誤りのリスクが残るため、探索を続けるか確定するかの判断を「不確実性とコストの釣り合い」として扱うことが重要です。
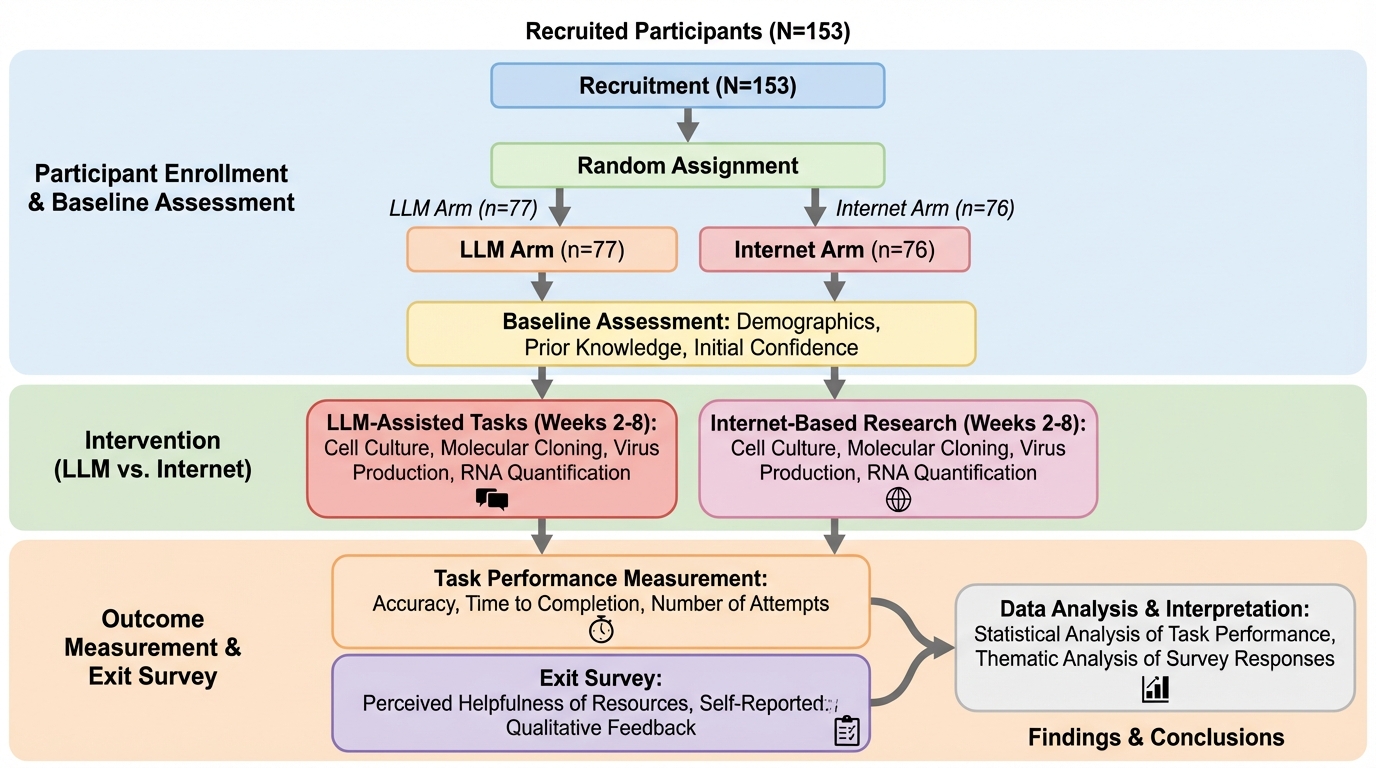
2025年中頃の大規模言語モデルを使える条件でも、初心者が「ウイルスのリバースジェネティクス」を模した一連の中核タスク(細胞培養・分子クローニング・ウイルス産生)を最後まで完了する割合は、インターネットのみの条件と統計的に有意な差が出ませんでした。
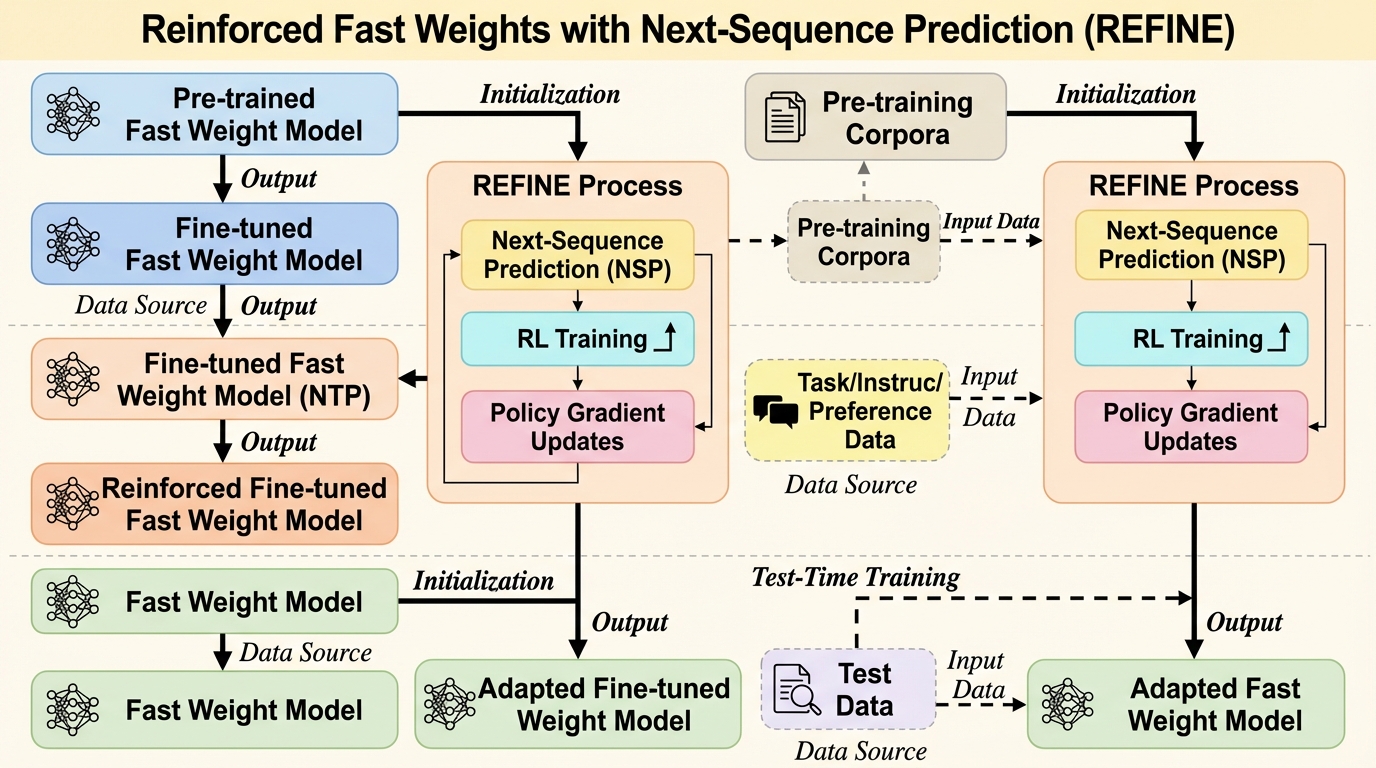
Fast weightアーキテクチャは文脈長に対して一定のメモリ負荷で推論しやすい一方、次トークン予測だけの学習では接頭辞の後に続く複数トークンの意味的一貫性を直接は最適化できず、長距離依存を取りこぼしやすいと指摘されています。
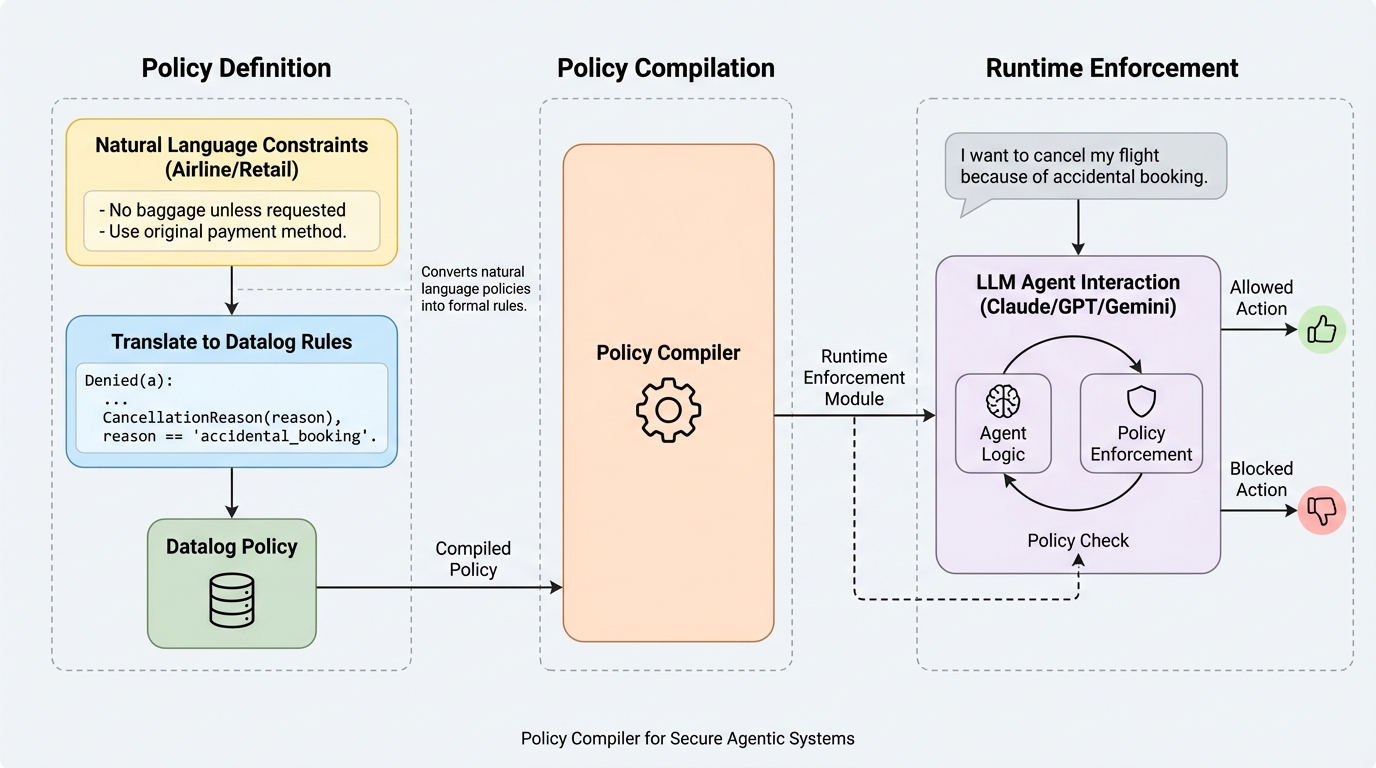
エージェント型 LLM を業務に入れると、承認フロー、データアクセス制限、顧客対応規程などの複雑なポリシーを守らせる必要がありますが、プロンプトに規則を書くだけでは強制力がありません。 / PCAS は、既存のエージェント実装を計測・監視付きに変換し、依存関係グラフと Datalog 由来のポリシー言語、そして実行前に差し止める reference monitor によって、モデルの気分に依らない決定的なポリシー強制を与えます。 / 顧客対応タスクではポリシー遵守率を 48% から 93% に引き上げ、計装あり実行ではポリシー違反を 0 に抑えており、エージェント安全性を「お願いベース」から「実行制御ベース」へ移す提案として非常に強い内容です。
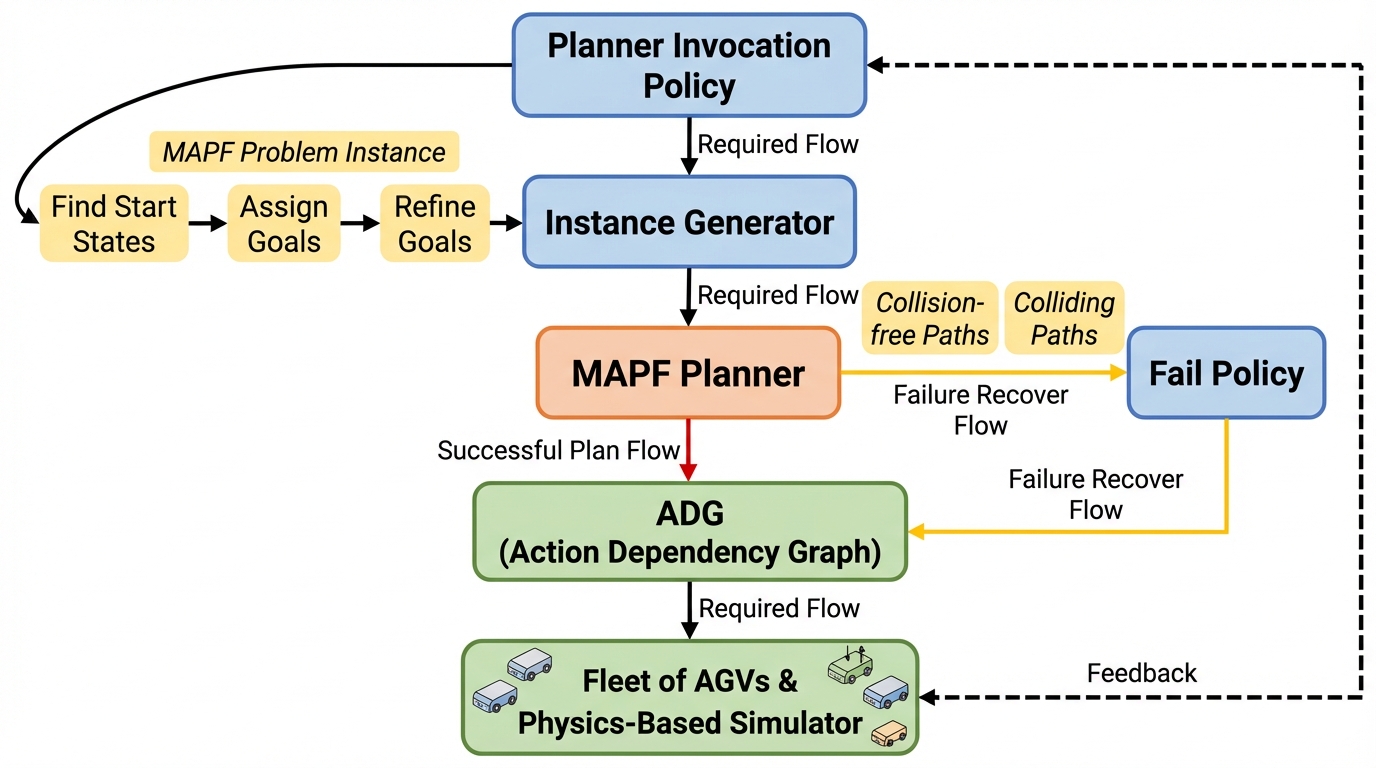
LSMARTは、中央集権の生涯型フリート管理システムでAGV群を動かす状況を対象に、任意の多エージェント経路探索を現実的な実行条件(運動学、通信遅延、実行時間のばらつき)込みで評価できるオープンソースの試験基盤です。