Fast Weightモデルを「次トークン」から「次シーケンス」へ拡張して鍛えるREFINE:強化学習による長文脈モデリング改善
Fast weightアーキテクチャは文脈長に対して一定のメモリ負荷で推論しやすい一方、次トークン予測だけの学習では接頭辞の後に続く複数トークンの意味的一貫性を直接は最適化できず、長距離依存を取りこぼしやすいと指摘されています。
TL;DR(結論)
- Fast weightアーキテクチャは文脈長に対して一定のメモリ負荷で推論しやすい一方、次トークン予測だけの学習では接頭辞の後に続く複数トークンの意味的一貫性を直接は最適化できず、長距離依存を取りこぼしやすいと指摘されています。
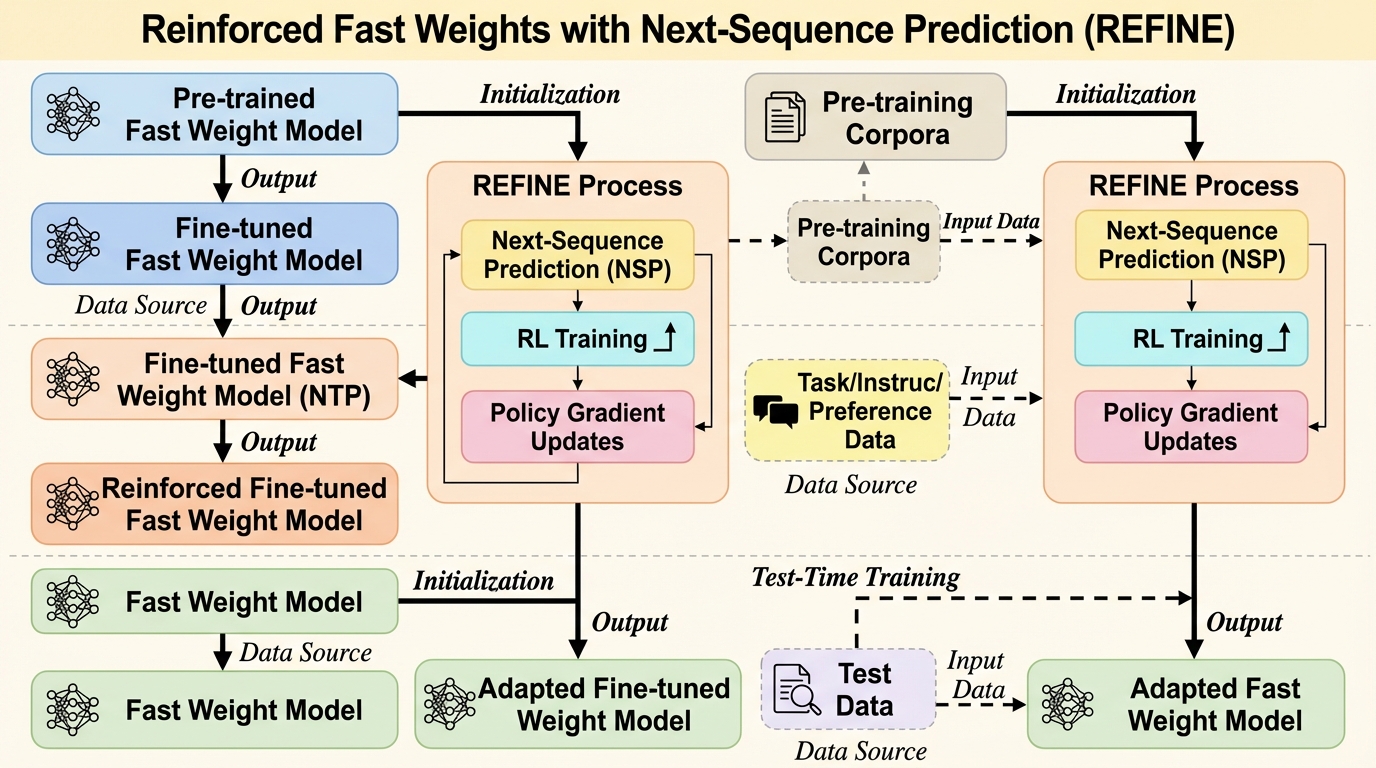
- REFINEは、次シーケンス予測を強化学習として扱い、不確実性が高い位置をエントロピーで選んで複数トークンのロールアウトを作り、隠れ状態の類似度などから自己教師ありの系列報酬を与え、GRPOで方策更新する枠組みです。
- LaCT-760MとDeltaNet-1.3Bに対して、needle-in-a-haystack型検索、長文脈の質問応答、LongBenchのタスク群で、次トークン予測の教師あり微調整より良い成績が一貫して示され、学習段階(mid-training、post-training、test-time training)をまたいで適用できる点も含意として示されています。
なぜこの問題か
長文脈モデリングは、長い文書の理解、many-shotの文脈内学習、コード生成などで重要性が増しており、数千トークン規模の文脈から情報を取り出して保持し、必要なタイミングで再利用する能力が求められています。注意機構に基づくTransformerはこれらの課題で強い性能を示す一方、文脈長に対して計算量とメモリが二乗で増える点が、学習と推論の両方で根本的な制約になります。そこで、グローバルな注意の代わりに固定サイズのメモリを用い、トークン処理に合わせてそのメモリを動的に更新するFast weightアーキテクチャが、長文脈に対する代替として注目されています。論文が強調している利点は、文脈長に依存しない一定のメモリ負荷で推論できる点です。 一方で本研究は、「アーキテクチャだけを変えても、学習目的が次トークン予測(NTP)のままでは潜在能力が十分に引き出されない」と問題設定を置いています。NTPは各位置で次の1トークンを当てる損失であり、同じ内部状態(Fast weightsやメモリ状態)に依存する“その先の複数トークン”の品質を直接には評価しません。…
核心:何を提案したのか
著者らの提案の中心は、学習目標を次トークン予測から次シーケンス予測(NSP)へ拡張し、接頭辞に続く複数トークンの列として意味的に整合した継続を促すことです。NSPは、Fast weightsに保存された情報が「次の1トークン」だけでなく「複数ステップ先の継続」にも有効かどうかを学習信号に反映しやすくする意図があります。しかし、NSPを通常の交差エントロピーで素直に最適化しようとすると、あらゆる接頭辞位置で複数トークン生成が必要になり、長文脈では計算的に重くなります。加えて、参照列と完全一致しない言い換えのような妥当な継続も強く罰してしまい、列の品質を適切に捉えにくい点が課題として挙げられています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related