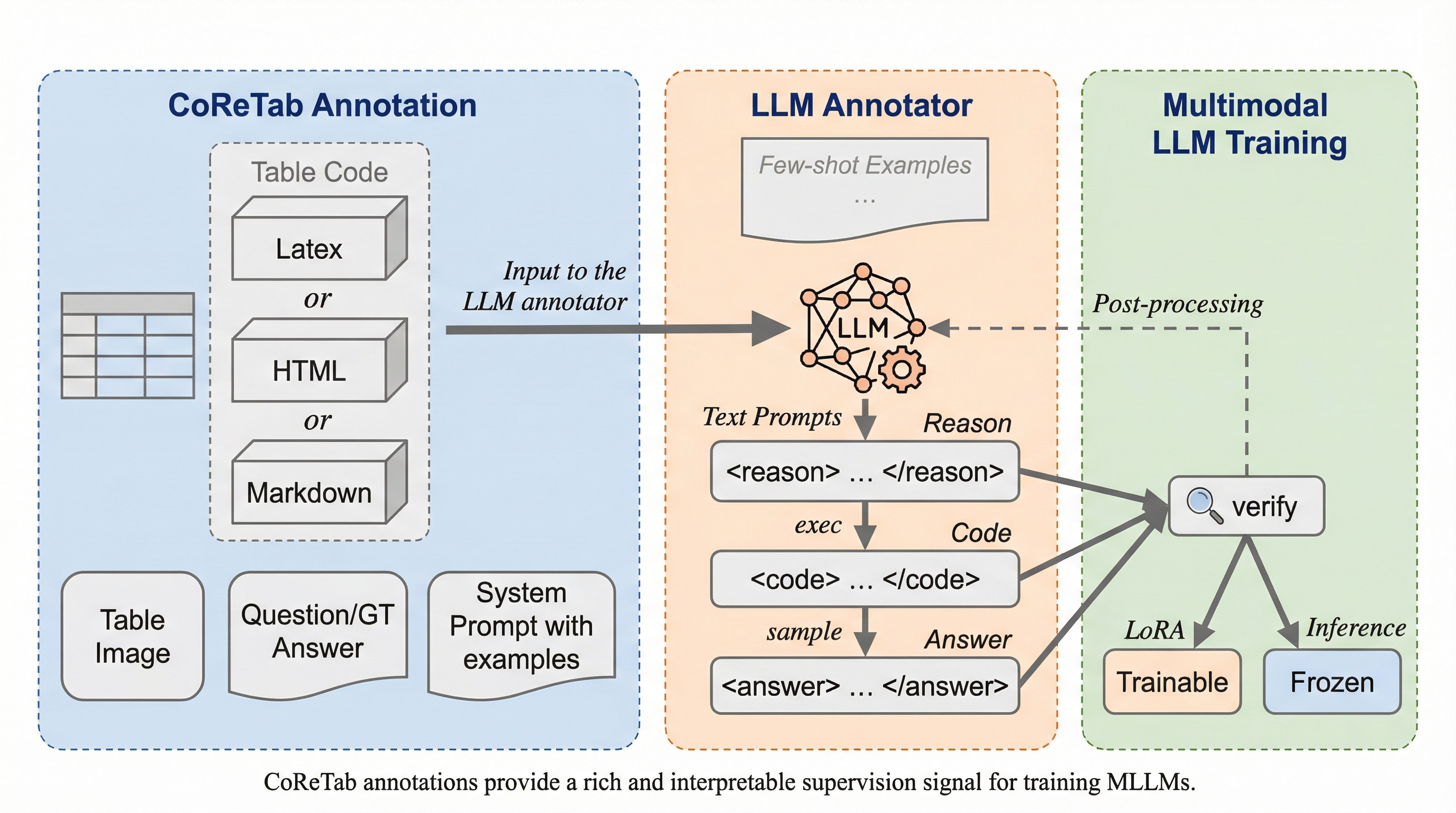
CoReTab:コード駆動型推論によるマルチモーダル表理解の向上
従来のマルチモーダル表理解データセットは短答形式が主流であり、多段階の推論過程を学習できないため、モデルの回答精度が低く、最終的な答えに至るまでのプロセスが不透明であるという課題が存在していました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
従来のマルチモーダル表理解データセットは短答形式が主流であり、多段階の推論過程を学習できないため、モデルの回答精度が低く、最終的な答えに至るまでのプロセスが不透明であるという課題が存在していました。
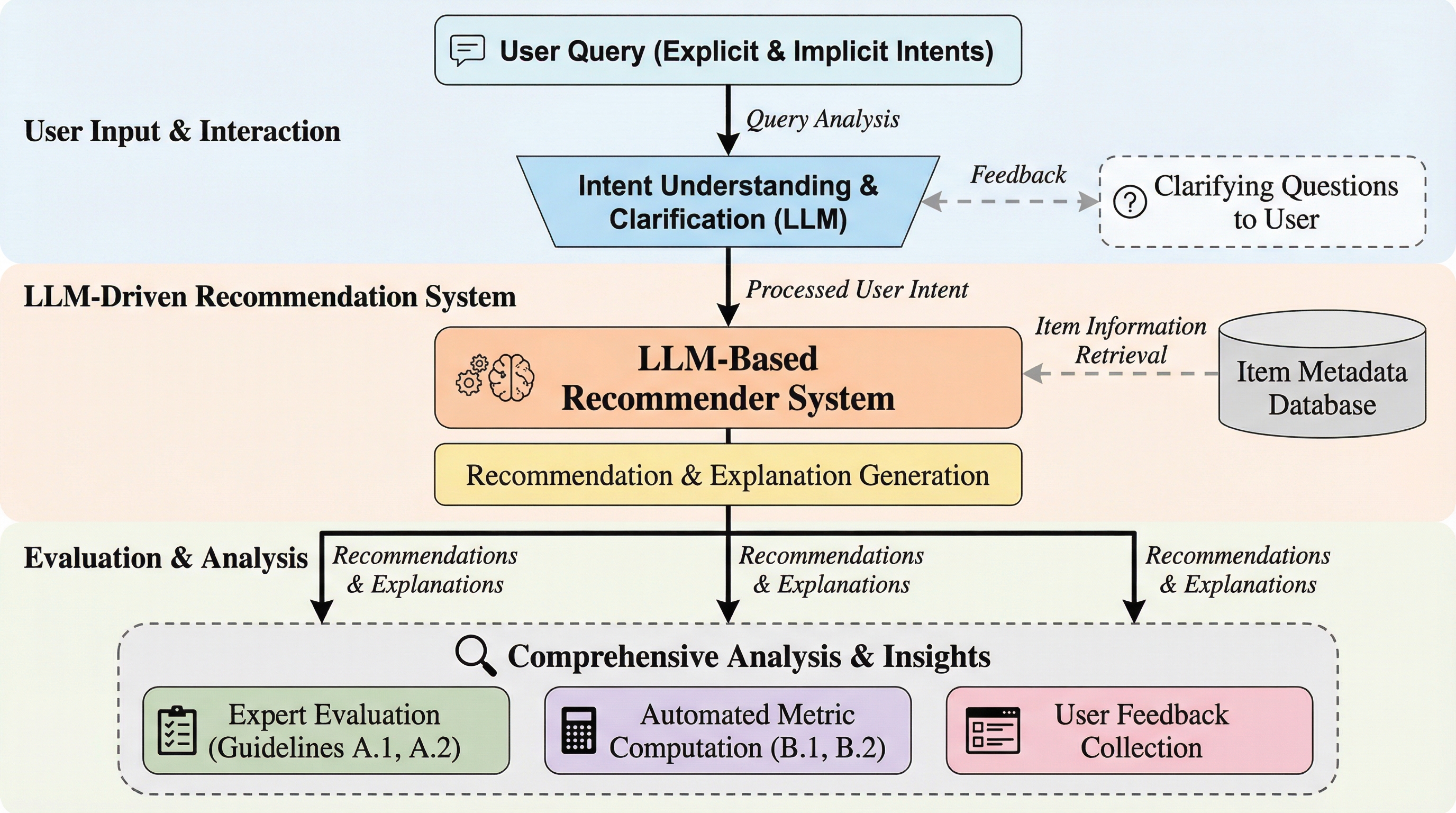
大規模言語モデル(LLM)を搭載した推薦システムは、自然言語による対話や詳細な説明生成といった革新的な能力を持つが、従来の的中率やNDCGといった正確性重視の指標では、その人間中心の価値を十分に評価できないという課題がある。
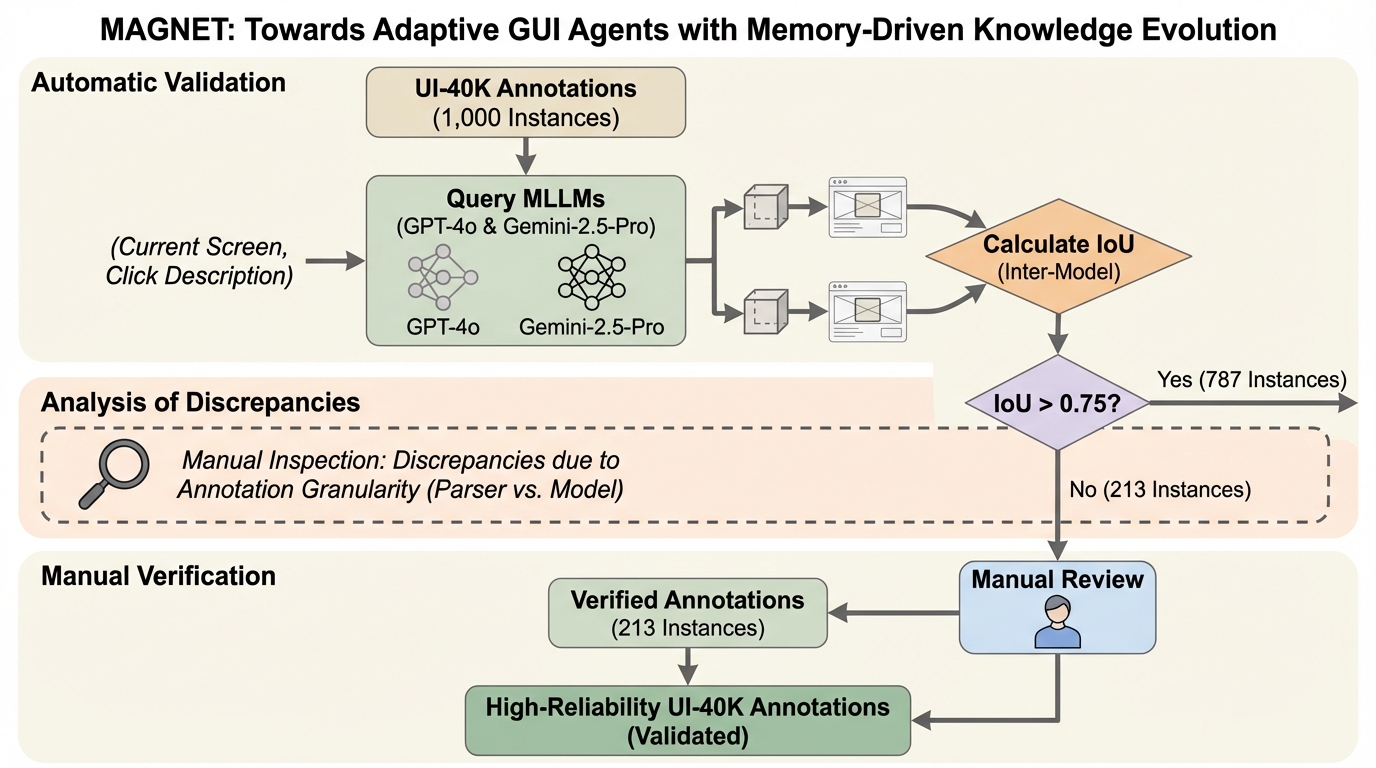
モバイルアプリの頻繁な更新で起きる「外観ドリフト」と「ワークフロードリフト」に対し、機能的な意味やタスク意図の不変性に注目し、視覚的特徴を機能へ結びつける「定常メモリ」と、操作手順を抽象化して保持する「手続きメモリ」の二層構造を導入しています。 / 成功した実行軌跡から知識を自動抽出して更新する動的進化メカニズムを備え、エビングハウスの忘却曲線に着想を得たランク付けで、有用な知識を優先保持しながらアプリ進化への適応を継続できるようにしています。 / AndroidWorld などのオンライン環境と複数のオフラインベンチマークで既存のメモリ拡張型エージェントを上回り、未知アプリや未知ドメインへの移行時にも性能低下を抑えられることを示しています。
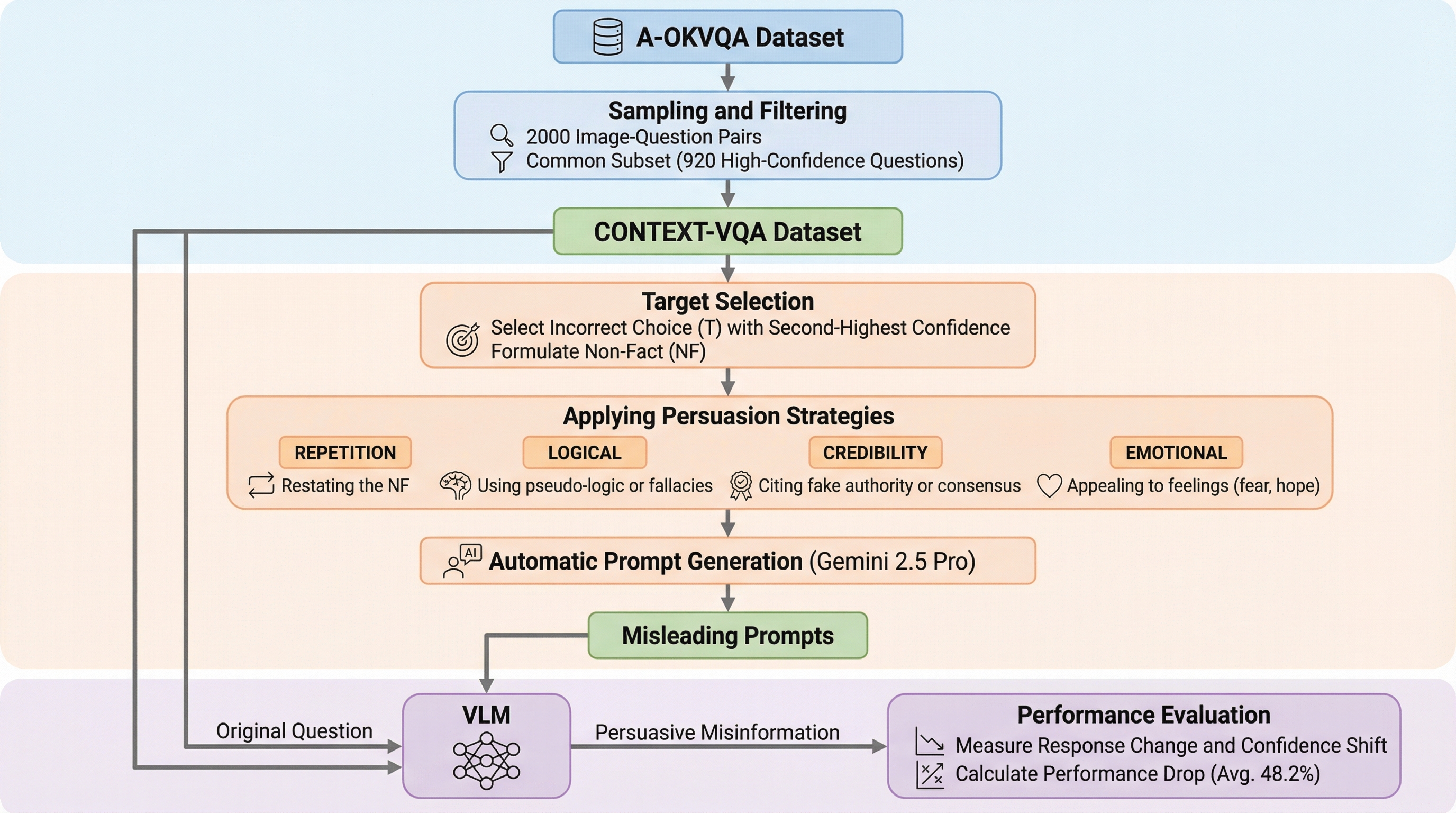
視覚と言語を統合して処理するモデル(VLM)が、画像の内容と真っ向から矛盾する誤ったテキスト情報に対してどの程度の耐性を持っているかを調査するため、新しいデータセットであるCONTEXT-VQAを構築しました。
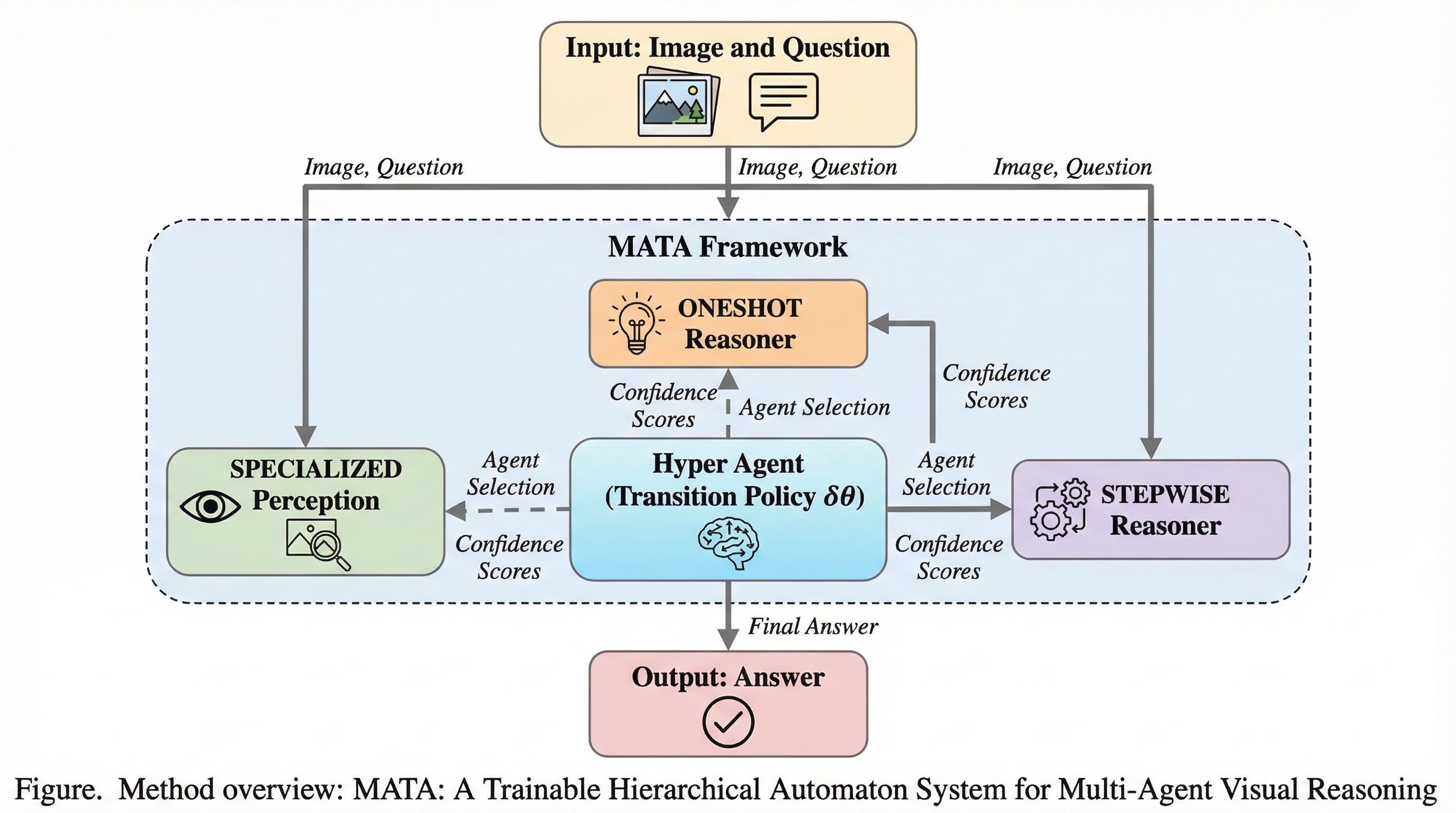
視覚言語モデルは高い知覚能力を持つ一方で、複雑な推論における「幻覚」やプロセスの不透明さが課題となっており、本研究ではこれを解決するために推論過程を有限状態オートマトンとしてモデル化しました。 提案手法である「MATA」は、学習可能なハイパーエージェントが複数の専門エージェントを動的に切り替える階層構造を採用し、共有メモリを介してエージェント間の高度な協調と競争を実現することで、推論の透明性と精度を両立させています。 9万件の遷移軌跡から構築されたデータセットを用いて微調整された大規模言語モデルを制御塔とすることで、複数の視覚推論ベンチマークにおいて従来手法を凌駕する最高水準の性能を達成し、複雑なタスクにおける新たな基準を提示しました。
本研究は、自己注意機構を持つトランスフォーマーが訓練を通じてトークン間の意味的関連性を獲得するプロセスを、勾配の主要項近似という手法を用いて理論的に解明した。重み行列は「バイグラム」「トークン互換性」「文脈」という3つの基底関数の単純な合成として閉形式で表現可能であり、これがモデルの内部構造を決定づけていることを明らかにした。実世界のデータを用いた検証により、この理論的な重みの特徴付けが実際の大規模言語モデルの挙動や学習された重みと密接に一致することが確認され、ブラックボックスとされるモデルの機械論的な基礎を提示した。
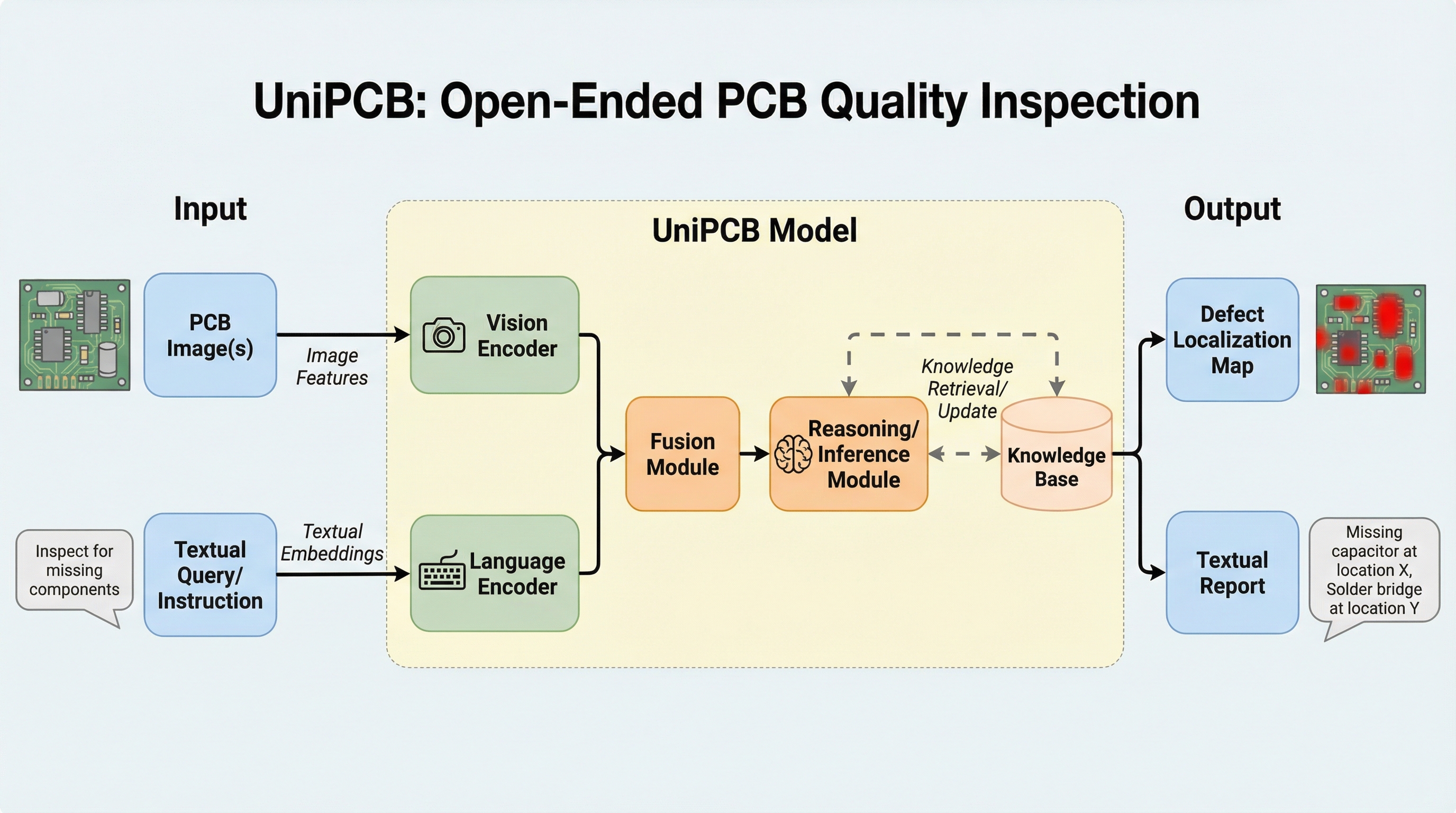
UniPCBは、プリント基板(PCB)の品質検査を目的とした世界初の統一的な視覚言語ベンチマークであり、6,000枚以上の画像と23,000件を超える高品質な多対話形式の質問回答ペアを提供することで、複雑な工業検査におけるマルチモーダルモデルの性能を厳密に評価する。
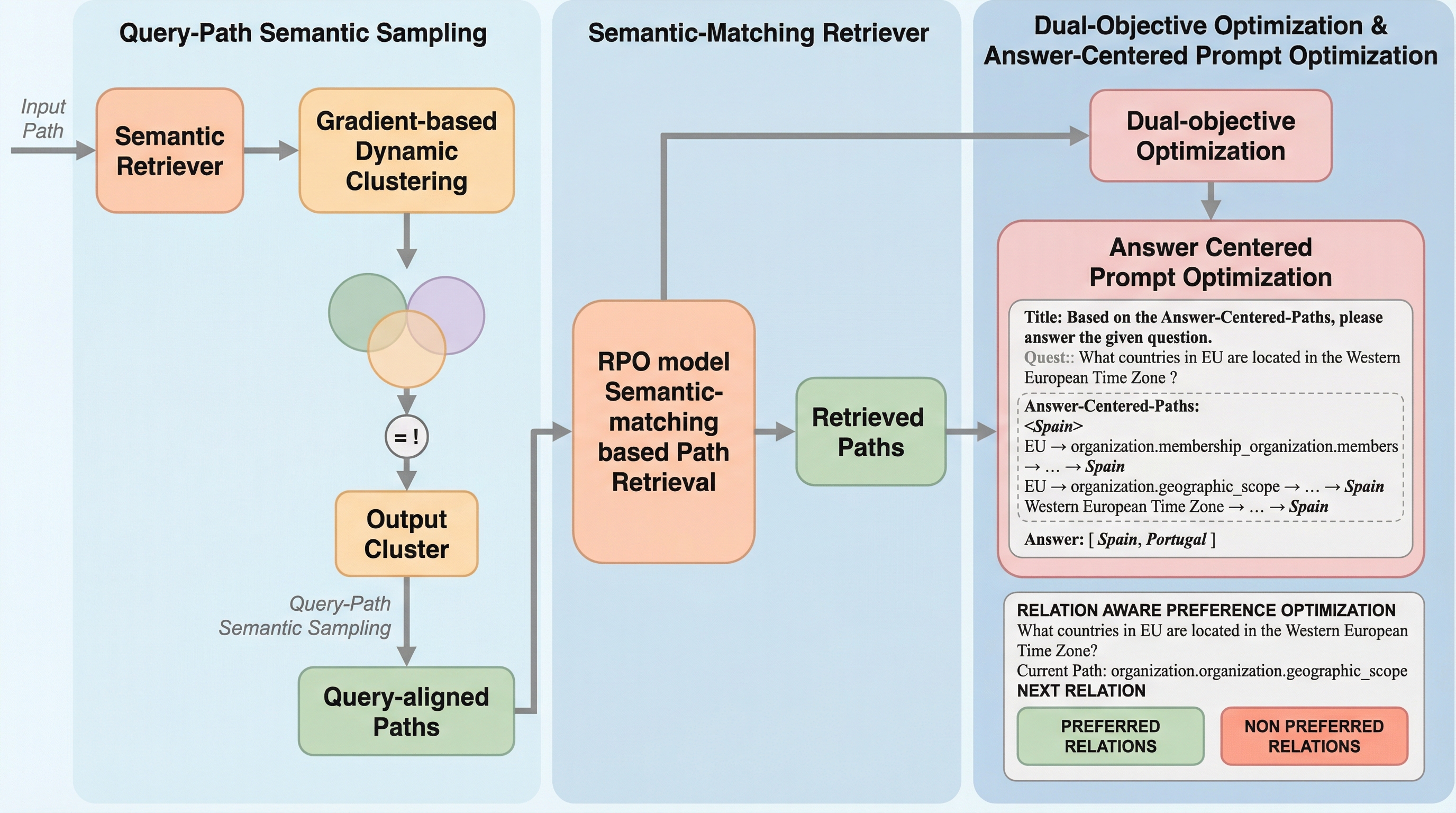
大規模言語モデル(LLM)が知識集約的なタスクで引き起こすハルシネーションを抑制するため、知識グラフ(KG)を活用した検索拡張生成(RAG)が注目されていますが、従来のヒューリスティックな経路探索ではクエリの意図と無関係なノイズが混入し、特に推論能力の限られた70億パラメータ未満の小規模モデルが情報を適切に処理できないという課題がありました。 本研究が提案する「RPO-RAG」は、クエリと経路の意味的類似度に基づく動的なサンプリング、中間的な推論ステップである「関係」に着目した選好最適化、および回答候補ごとに証拠を整理するプロンプト設計を導入することで、小規模モデルの推論プロセスを知識グラフの構造的論理に精密に適合させることに成功しました。 WebQSPおよびCWQのベンチマークにおいて、80億パラメータ以下のモデルで最高水準の性能を達成し、特にWebQSPではF1スコアを最大8.8%向上させるなど、30億パラメータ程度の極めて小さなモデルであっても、大規模モデルに匹敵する高精度な回答と論理的な推論が可能であることを実証しました。
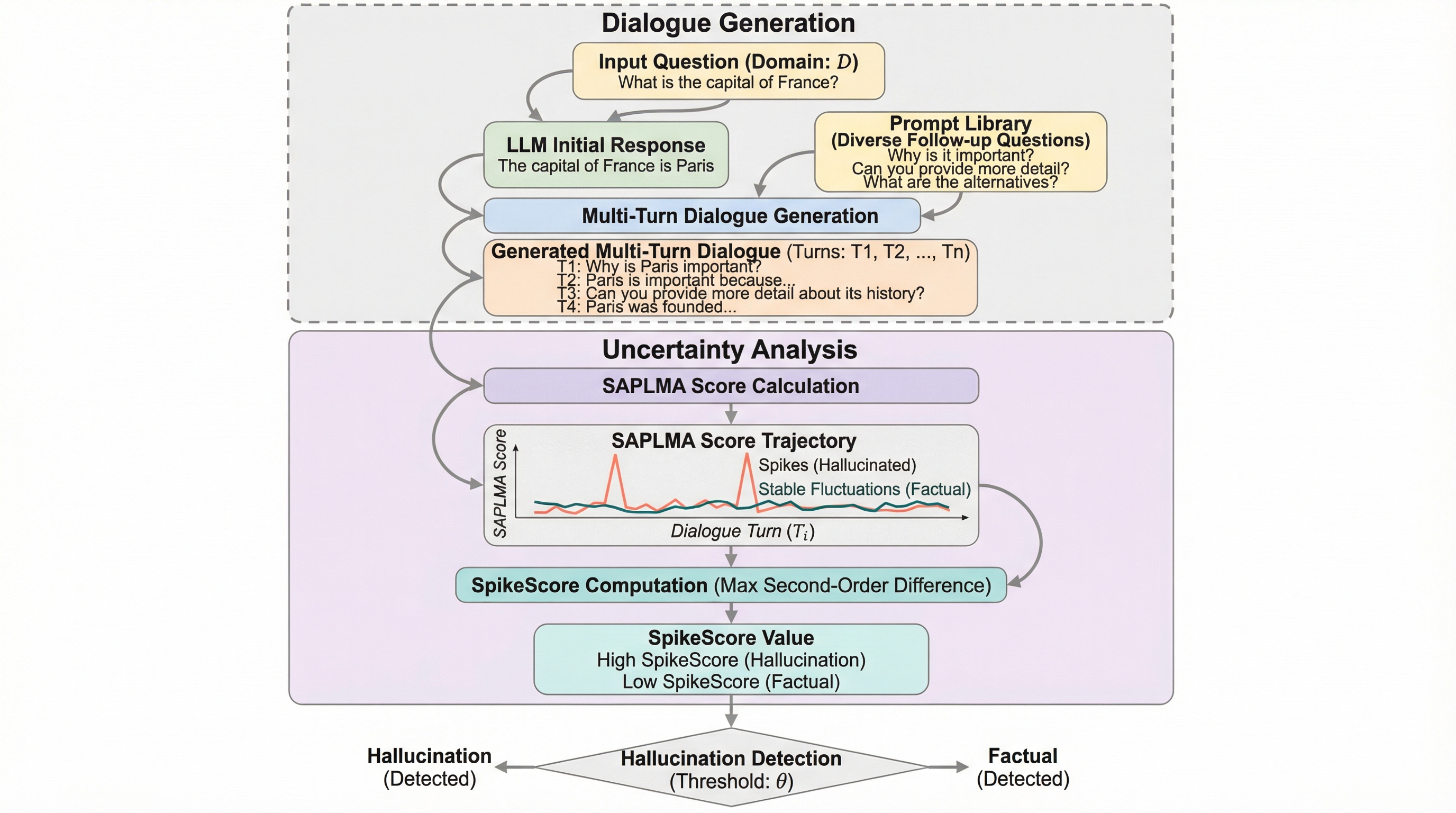
大規模言語モデル(LLM)のハルシネーション検知において、訓練データと異なる領域で精度が低下する「クロスドメイン汎用性」の欠如を解決するため、単一ドメインの学習のみで多様な未知の領域に対応できる汎用的検知(GHD)の枠組みを確立しました。
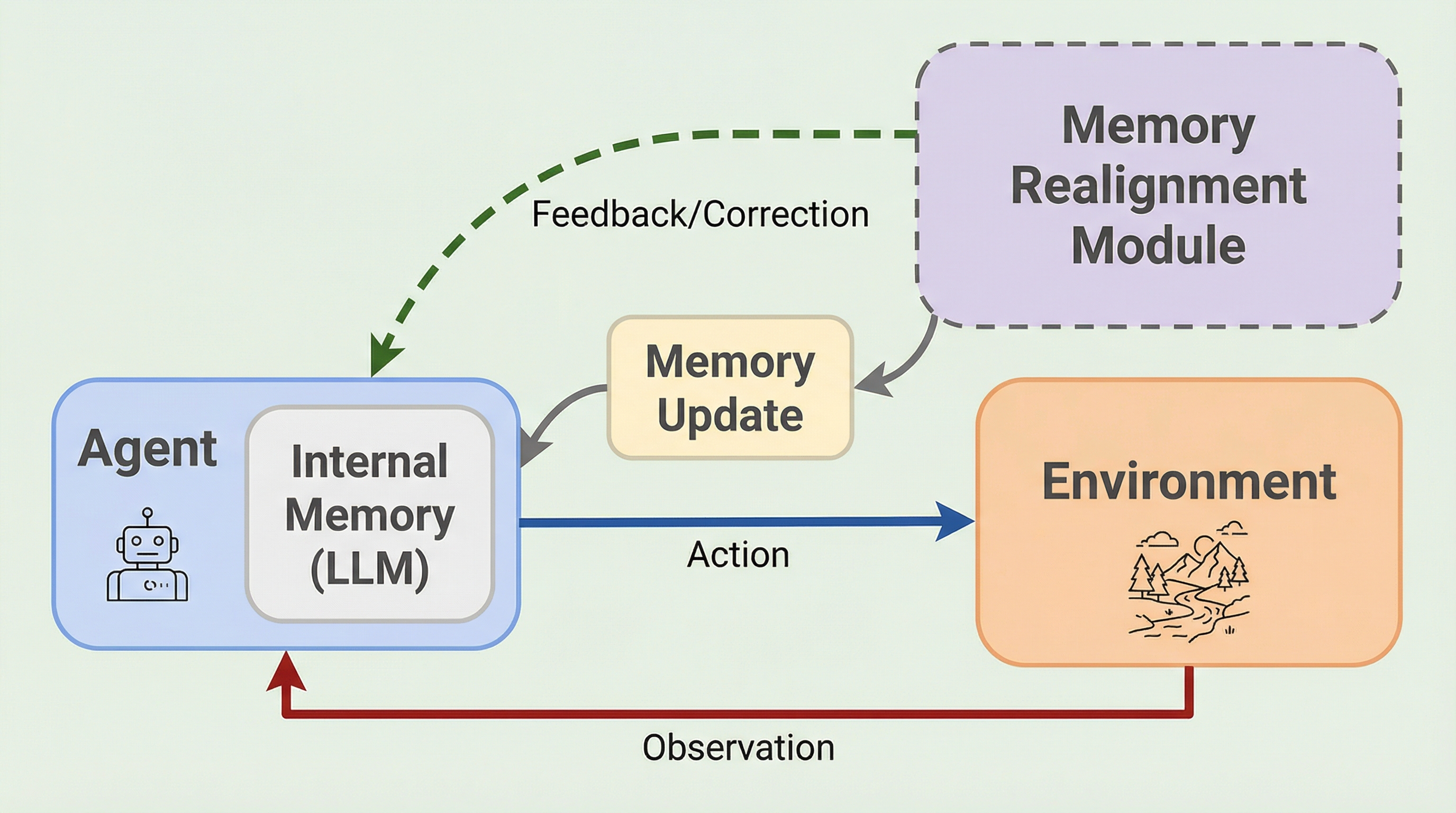
大規模言語モデル(LLM)を用いたエージェントが、外部の正解ラベルやモデル自身の内省能力に過度に依存することなく、環境の変化に合わせて記憶を自律的に更新するための新しいフレームワーク「GLOVE」を提案する。