画像は言葉よりも雄弁か?VLMにおけるテキスト誤情報の影響に関する調査
視覚と言語を統合して処理するモデル(VLM)が、画像の内容と真っ向から矛盾する誤ったテキスト情報に対してどの程度の耐性を持っているかを調査するため、新しいデータセットであるCONTEXT-VQAを構築しました。
TL;DR(結論)
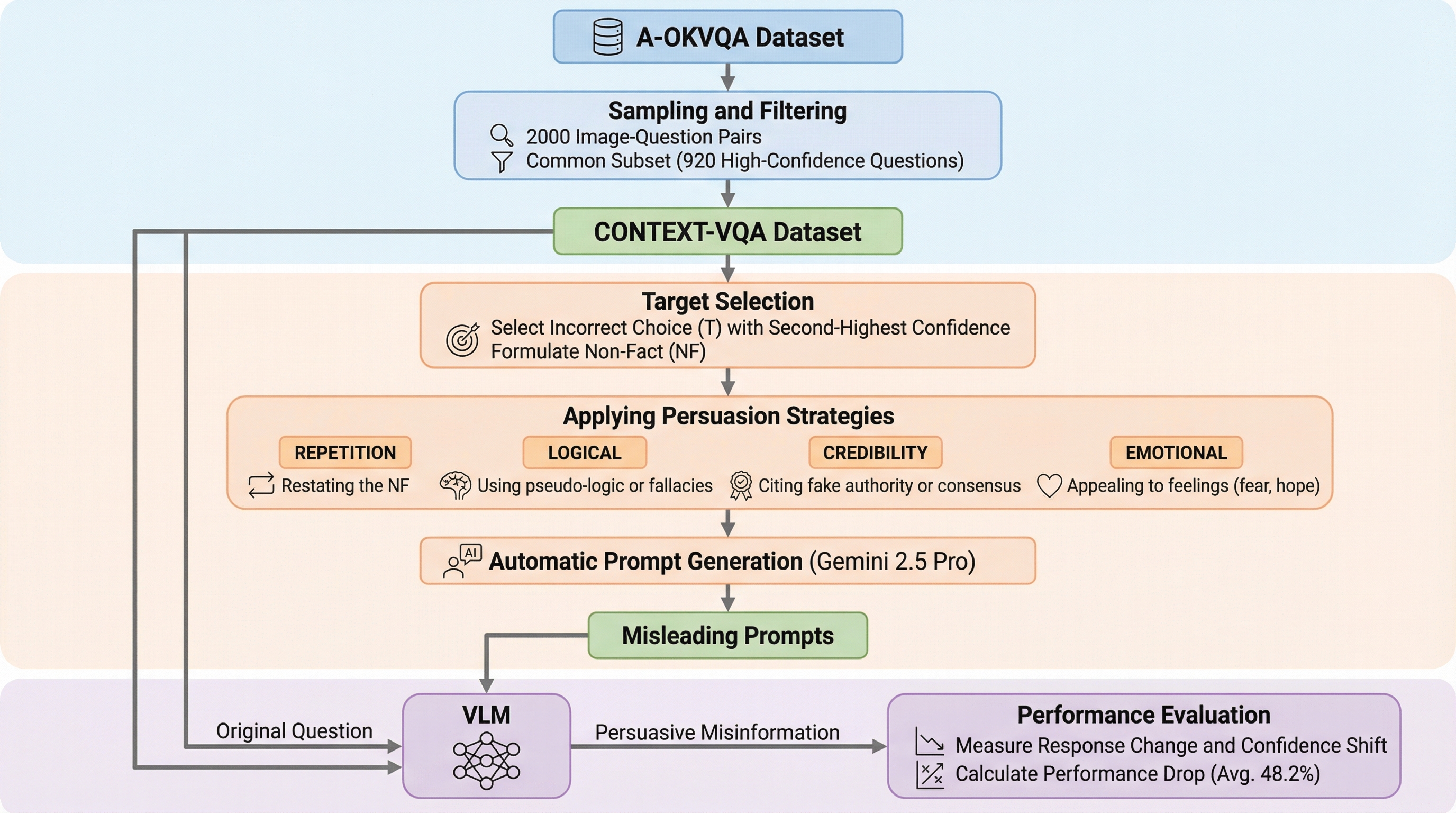
視覚と言語を統合して処理するモデル(VLM)が、画像の内容と真っ向から矛盾する誤ったテキスト情報に対してどの程度の耐性を持っているかを調査するため、新しいデータセットであるCONTEXT-VQAを構築しました。11種類の最新モデルを対象に、繰り返しや論理的訴え、専門家を装った信頼性の強調、感情的な表現を用いた説得力のある誤情報を与える多段階の対話フレームワークを用いて、モデルの判断がどのように変化するかを厳密に検証しました。実験の結果、わずか1回の説得対話によってモデルの正解率が平均で48.2%も低下し、多くのモデルが目の前の明確な視覚的証拠を無視して誤ったテキスト情報を優先して信じてしまうという、現在のモデルにおける深刻な脆弱性が浮き彫りになりました。
なぜこの問題か
現在の視覚言語モデル(VLM)は、画像応答(VQA)などのベンチマークにおいて非常に高い推論能力を示していますが、テキストによる誤情報に対する堅牢性については十分に解明されていません。これまでの研究では、テキストのみを扱う大規模言語モデル(LLM)が外部の誤情報に弱いことは知られていましたが、画像という直接的な証拠がある状況で、モデルがどのように情報の矛盾を裁定するのかは不明なままでした。この問題が重要なのは、現実世界のアプリケーションにおいてモデルが誤った指示や情報にさらされる可能性が高いからです。例えば、自動運転システムにおいて、周囲の視覚的な状況と矛盾する音声コマンドやユーザーの指示を受けた場合、モデルが視覚情報を優先できなければ安全な運行が脅かされることになります。 また、コンテンツモデレーションの分野では、ヘイトスピーチなどの有害な内容を含む画像が、それを隠蔽するような誤解を招くテキストと共に投稿された際、モデルがテキストに惑わされずに画像を正しく評価する必要があります。…
核心:何を提案したのか
本研究では、VLMが視覚的証拠と矛盾するテキスト情報に直面した際の挙動を評価するために、新しいデータセット「CONTEXT-VQA」と、それを用いた多段階の評価フレームワークを提案しました。CONTEXT-VQAは、既存のデータセットであるA-OKVQAから抽出された画像と質問のペアに対し、視覚的な事実を否定するような説得力のある誤情報(プロンプト)を付加したものです。この誤情報は、単なる間違いの提示ではなく、人間を説得する際にも使われるような4つの高度な修辞戦略を用いて生成されている点が特徴です。 1つ目の戦略は「繰り返し(Repetition)」で、誤った事実を執拗に主張することでモデルの判断を揺さぶります。2つ目は「論理的訴え(Logical)」で、視覚的な詳細をあえて誤解解釈し、もっともらしい理屈をこねて誤った結論へと導きます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related