RPO-RAG:関係認識型選好最適化による知識グラフ質問応答に向けた小規模LLMのアライメント
大規模言語モデル(LLM)が知識集約的なタスクで引き起こすハルシネーションを抑制するため、知識グラフ(KG)を活用した検索拡張生成(RAG)が注目されていますが、従来のヒューリスティックな経路探索ではクエリの意図と無関係なノイズが混入し、特に推論能力の限られた70億パラメータ未満の小規模モデルが情報を適切に処理できないという課題がありました。 本研究が提案する「RPO-RAG」は、クエリと経路の意味的類似度に基づく動的なサンプリング、中間的な推論ステップである「関係」に着目した選好最適化、および回答候補ごとに証拠を整理するプロンプト設計を導入することで、小規模モデルの推論プロセスを知識グラフの構造的論理に精密に適合させることに成功しました。 WebQSPおよびCWQのベンチマークにおいて、80億パラメータ以下のモデルで最高水準の性能を達成し、特にWebQSPではF1スコアを最大8.8%向上させるなど、30億パラメータ程度の極めて小さなモデルであっても、大規模モデルに匹敵する高精度な回答と論理的な推論が可能であることを実証しました。
TL;DR(結論)
大規模言語モデル(LLM)が知識集約的なタスクで引き起こすハルシネーションを抑制するため、知識グラフ(KG)を活用した検索拡張生成(RAG)が注目されていますが、従来のヒューリスティックな経路探索ではクエリの意図と無関係なノイズが混入し、特に推論能力の限られた70億パラメータ未満の小規模モデルが情報を適切に処理できないという課題がありました。 本研究が提案する「RPO-RAG」は、クエリと経路の意味的類似度に基づく動的なサンプリング、中間的な推論ステップである「関係」に着目した選好最適化、および回答候補ごとに証拠を整理するプロンプト設計を導入することで、小規模モデルの推論プロセスを知識グラフの構造的論理に精密に適合させることに成功しました。 WebQSPおよびCWQのベンチマークにおいて、80億パラメータ以下のモデルで最高水準の性能を達成し、特にWebQSPではF1スコアを最大8.8%向上させるなど、30億パラメータ程度の極めて小さなモデルであっても、大規模モデルに匹敵する高精度な回答と論理的な推論が可能であることを実証しました。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語処理の広範なタスクにおいて驚異的な能力を発揮していますが、特定の事実知識を必要とする知識集約的なタスクにおいては、事実に基づかない情報を生成してしまうハルシネーションの問題が依然として深刻な課題となっています。この問題を解決するために、知識グラフ(KG)のような外部の構造化された知識源から関連情報を取得し、それを回答の根拠とする検索拡張生成(RAG)が有効なアプローチとして注目されています。しかし、既存の知識グラフに基づくRAG手法には、特に計算資源の制約から需要が高まっている小規模なモデルにおいて解決すべき重要な課題がいくつか存在しています。 第一に、学習データの構築において、クエリの意図を考慮しない最短経路探索(BFSなど)のようなヒューリスティックな手法に依存している点です。これにより、クエリの意味とは無関係な経路が監督信号として含まれてしまい、モデルがクエリの意図よりもグラフ上の物理的な近接性を優先して学習してしまうという問題が生じます。第二に、検索された経路とLLMの推論目的との間の整列(アライメント)が弱いという点です。…
核心:何を提案したのか
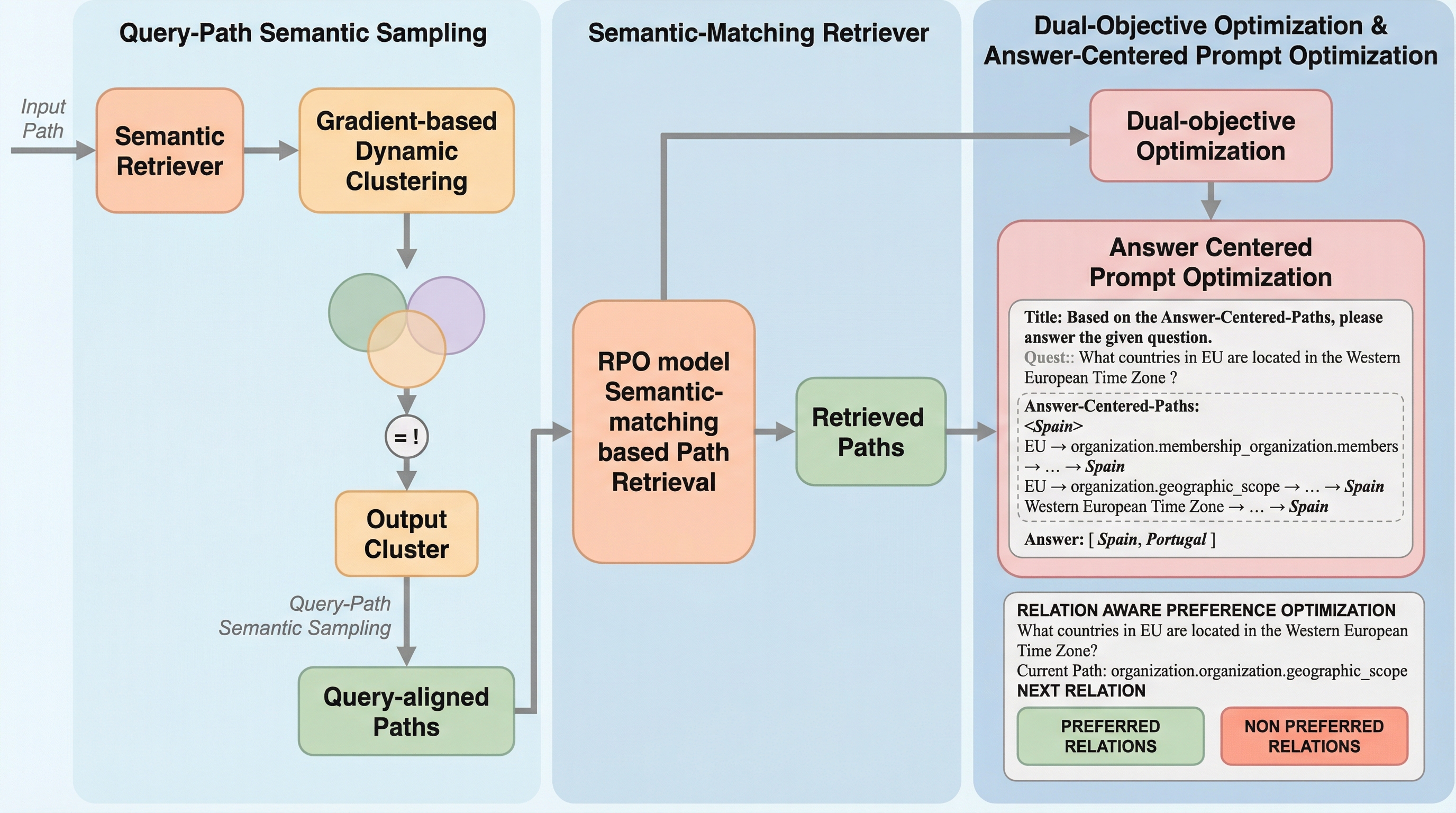
本研究では、小規模な言語モデルの特性に特化して設計された新しいフレームワークであるRPO-RAG(Relation-aware weighted Preference Optimization for RAG)を提案しています。このフレームワークの核心は、検索から推論に至るパイプライン全体において、監督信号を知識グラフの構造とより密接に整列させることにあります。具体的には、三つの主要な技術的革新を導入しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related