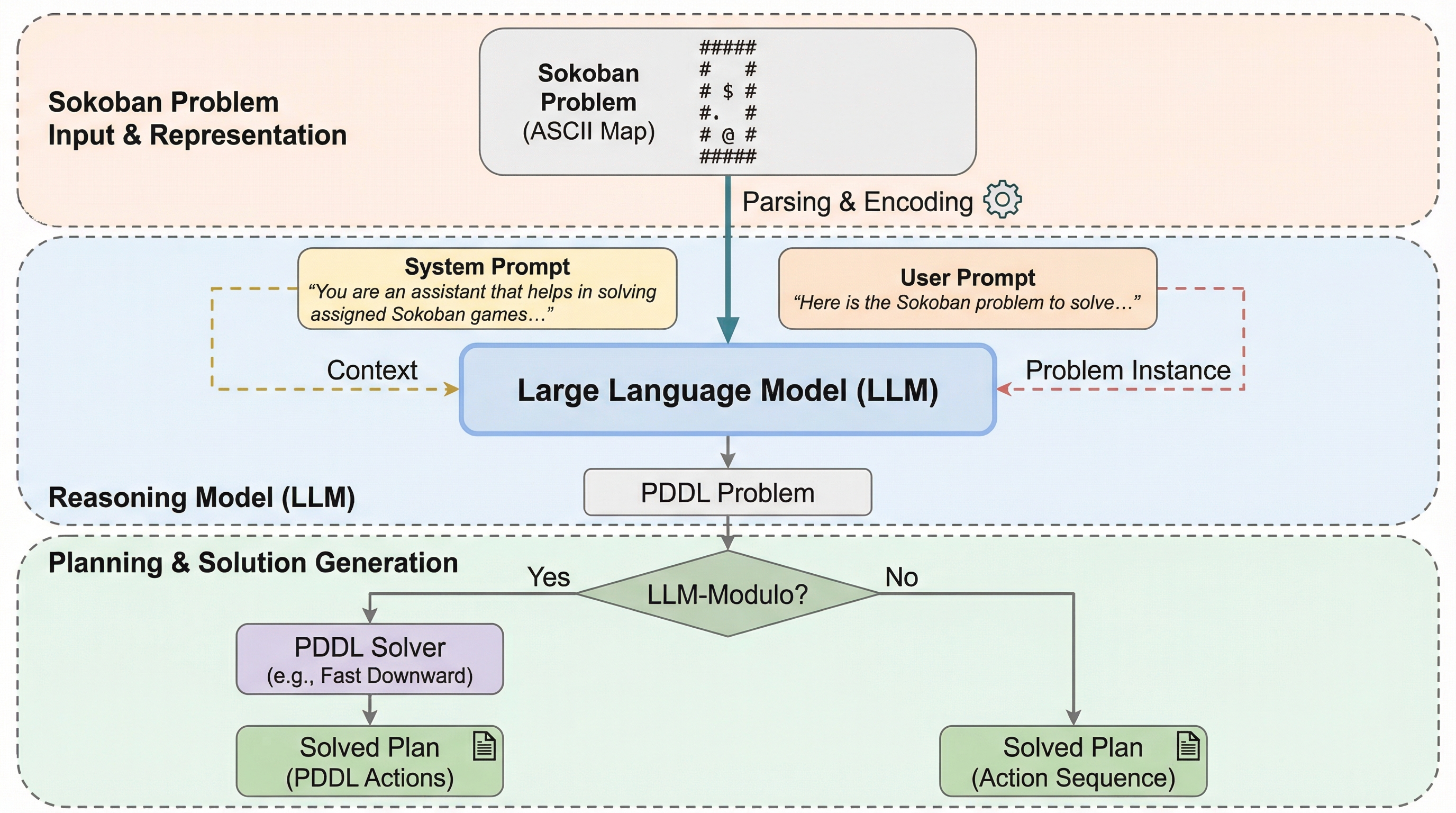
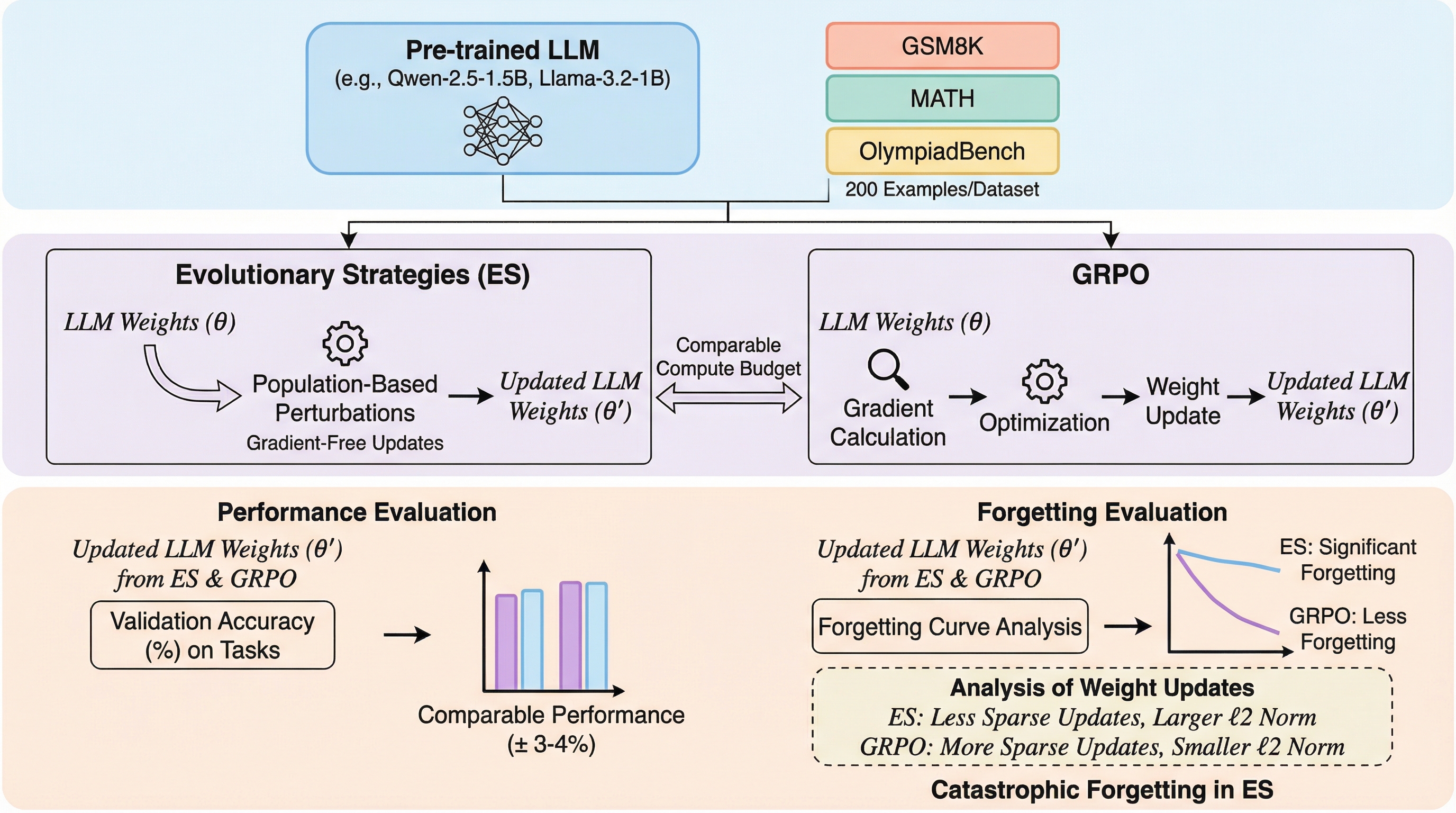
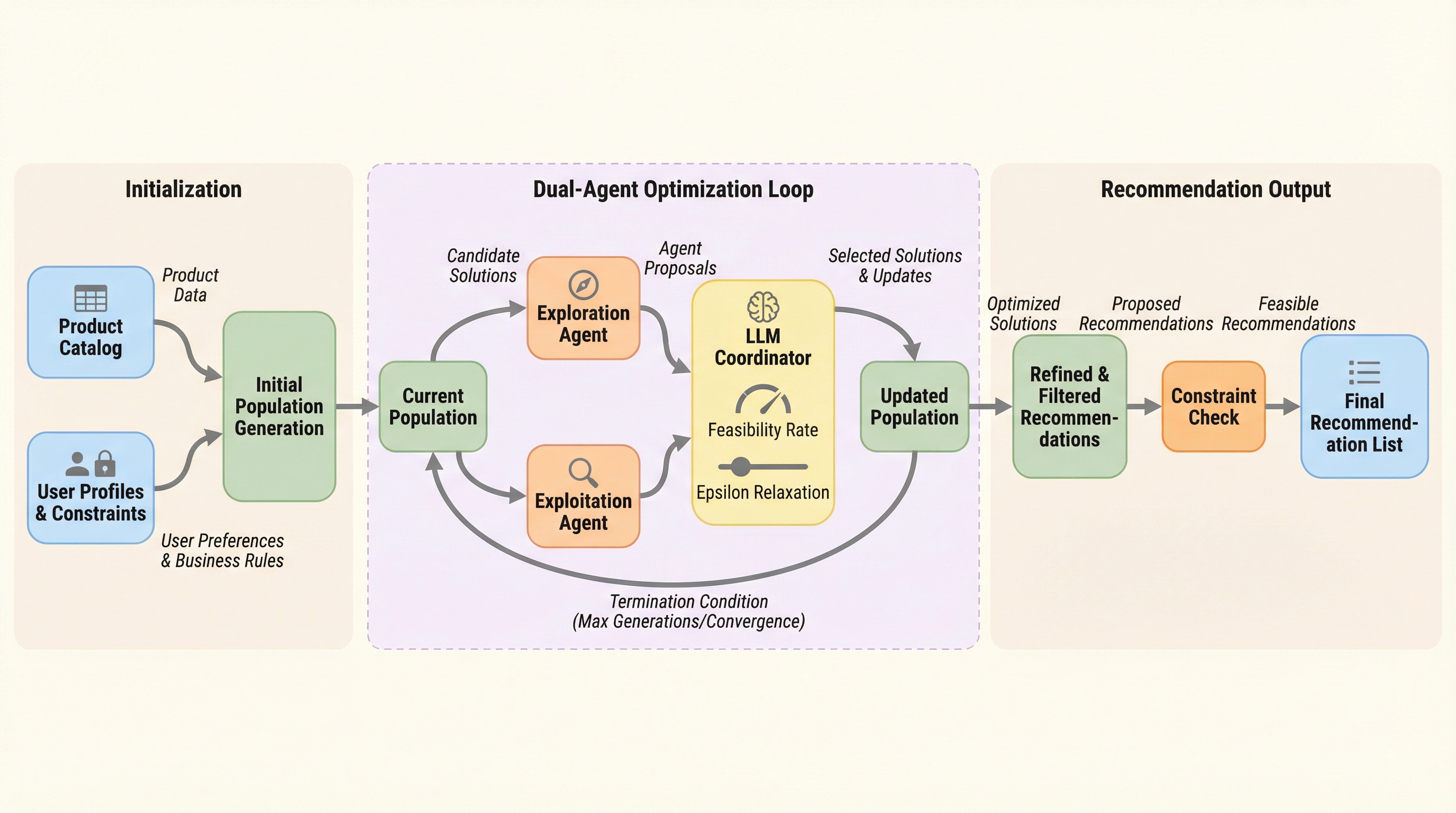
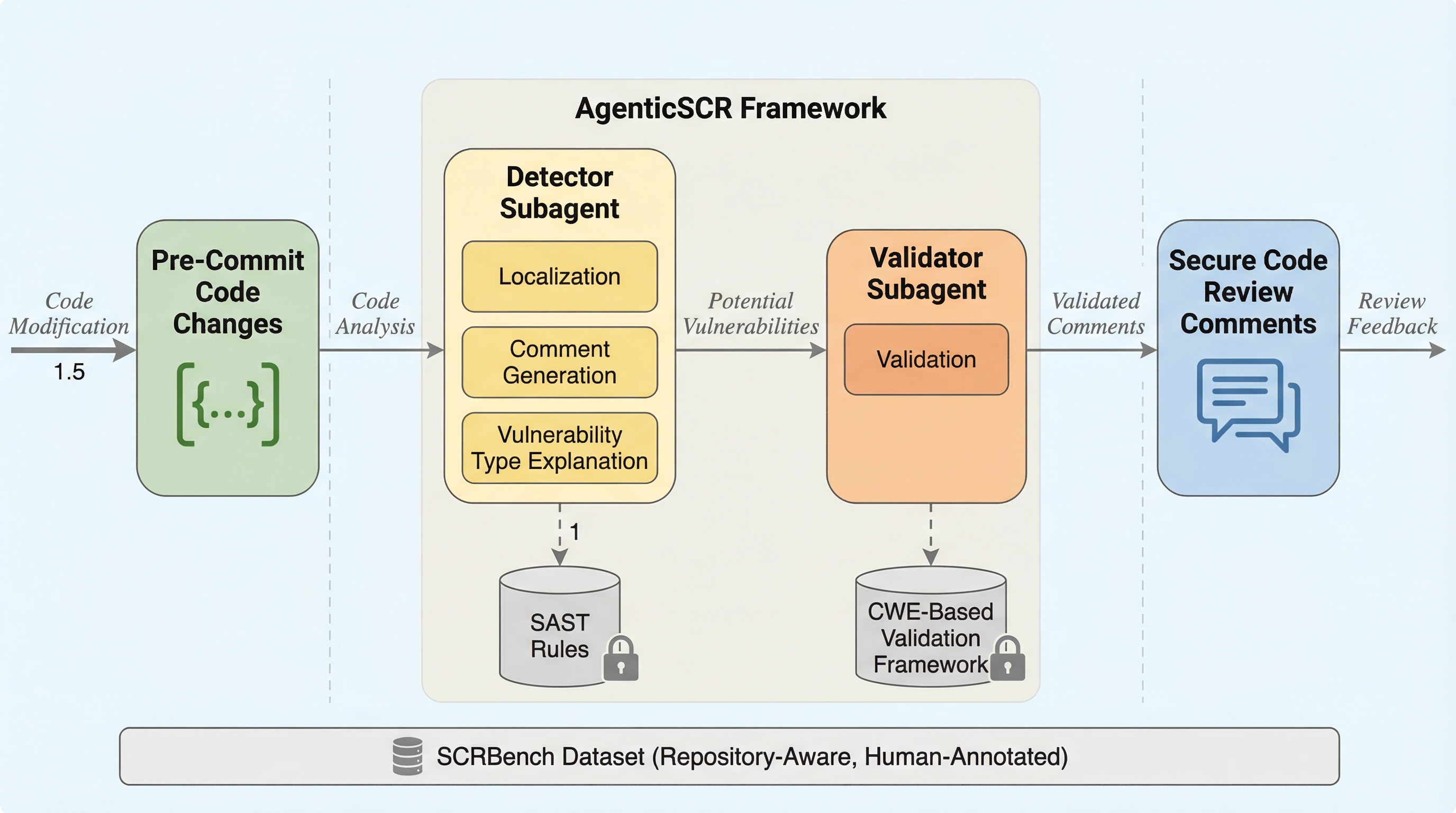
表形式データ生成のための変分オートエンコーダにおけるTransformerの配置に関する探究
本研究では、表形式データの生成において変分オートエンコーダ(VAE)のどの構成要素にTransformerを配置すべきかを、57種類の多様なデータセットを用いて網羅的に調査しました。実験の結果、Transformerを潜在空間やデコーダに配置することで生成データの多様性は向上するものの、元のデータに対する忠実度が低下するという明確なトレードオフの関係が存在することが判明しました。また、デコーダに配置されたTransformerは層正規化の影響により実質的に線形な挙動を示しており、複雑な特徴間相互作用の学習には限定的な寄与しかしていない可能性が示唆されています。