CoReTab:コード駆動型推論によるマルチモーダル表理解の向上
従来のマルチモーダル表理解データセットは短答形式が主流であり、多段階の推論過程を学習できないため、モデルの回答精度が低く、最終的な答えに至るまでのプロセスが不透明であるという課題が存在していました。
TL;DR(結論)
従来のマルチモーダル表理解データセットは短答形式が主流であり、多段階の推論過程を学習できないため、モデルの回答精度が低く、最終的な答えに至るまでのプロセスが不透明であるという課題が存在していました。本研究では、自然言語による多段階の推論と実行可能なPythonコードを密接に連携させることで、スケーラブルかつ解釈可能で、自動的な検証が可能なアノテーションを生成する新しいフレームワークであるCoReTabを提案しました。このフレームワークを活用して構築された115K件の検証済みデータセットを用いて学習した結果、従来のベースラインと比較して表構造の理解で+25.6%という顕著な性能向上を達成し、推論の正確性と透明性を大幅に高めることに成功しました。
なぜこの問題か
表は、金融、科学、政府機関など、多様な実務領域において構造化された情報を整理し伝達するための主要な媒体として機能しています。現実の場面では、表はスライドやPDF、スプレッドシート内のスクリーンショットとして埋め込まれていることが多く、本質的に視覚的なオブジェクトとして存在しています。テキストのみを扱う大規模言語モデル(LLM)は、テキスト抽出時に空間的なレイアウトが損なわれたり不整合が生じたりするため、このような入力には適していません。また、OCR(光学文字認識)を実行した後にHTMLやLaTeXなどの複雑なテキスト表現に頼るよりも、表の画像を直接操作する方が自然で効率的です。先行研究では、OCRとLLMを組み合わせたパイプラインであっても、表画像の理解においてはマルチモーダル大規模言語モデル(MLLM)に大幅に劣ることが示されています。 しかし、現在のMLLMの性能は、教師データの制約によって制限されています。人間によるアノテーションは正確ではあるものの、コストが極めて高く、大規模なデータセット作成には向かないという欠点があります。…
核心:何を提案したのか
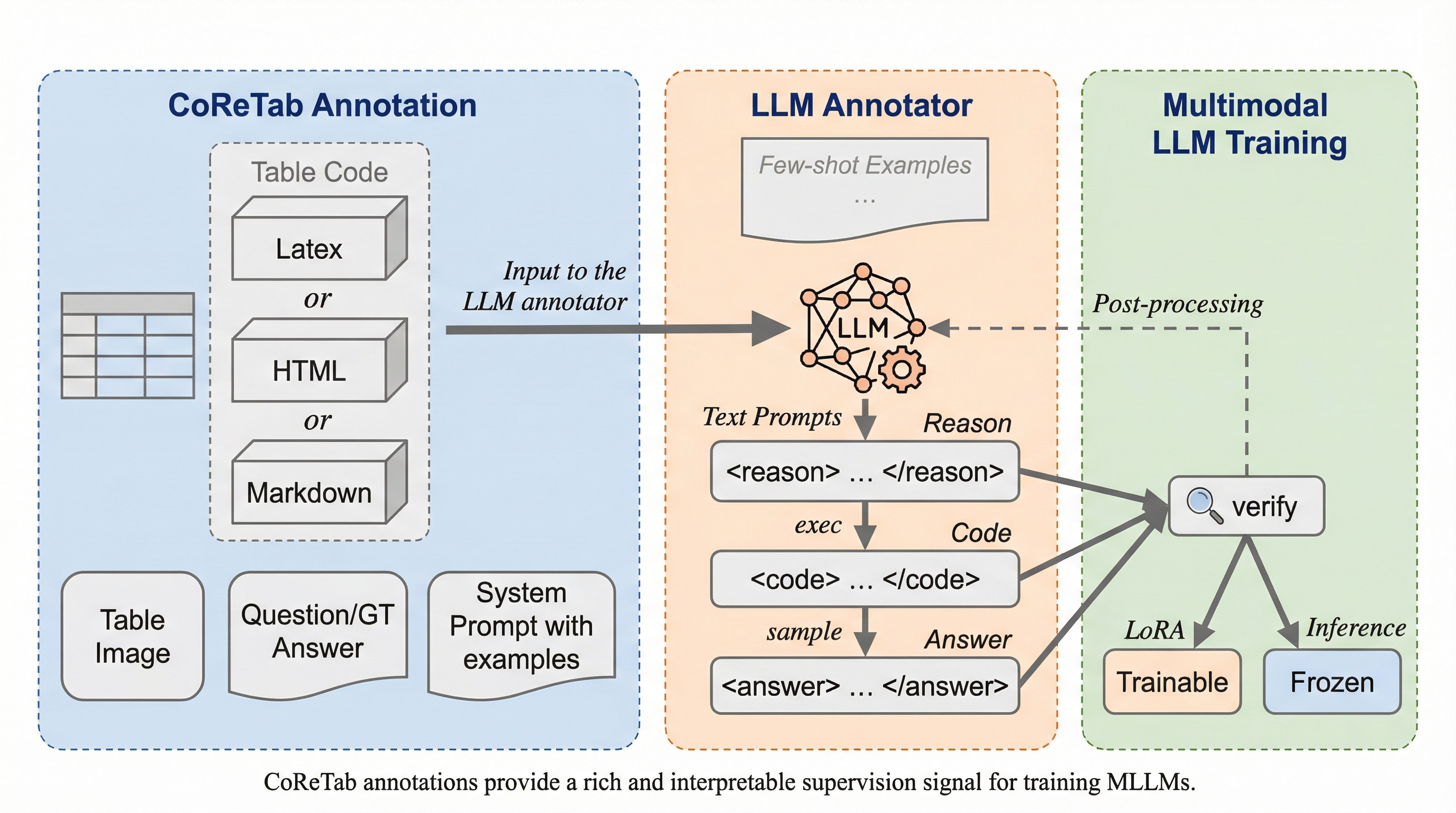
本研究では、マルチモーダルな表理解のためのコード駆動型推論フレームワークであるCoReTabを提案しました。このフレームワークの核心は、自然言語による多段階の推論ステップと、実行可能なPythonコードを密接に結合させる点にあります。これにより、推論の正しさをコードの実行結果を通じて自動的に検証することが可能となりました。具体的には、Qwen3 32B-3Aなどの強力なLLMアノテーターに対し、表のコード(HTML、LaTeX、Markdown)、質問、および正解の短答を入力として与え、多段階の推論過程とそれに対応するPythonコードを含む新しいアノテーションを生成させます。生成されたコードを実行し、その出力が元の正解と一致する場合のみをデータセットとして採用することで、高品質な教師データを確保しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related