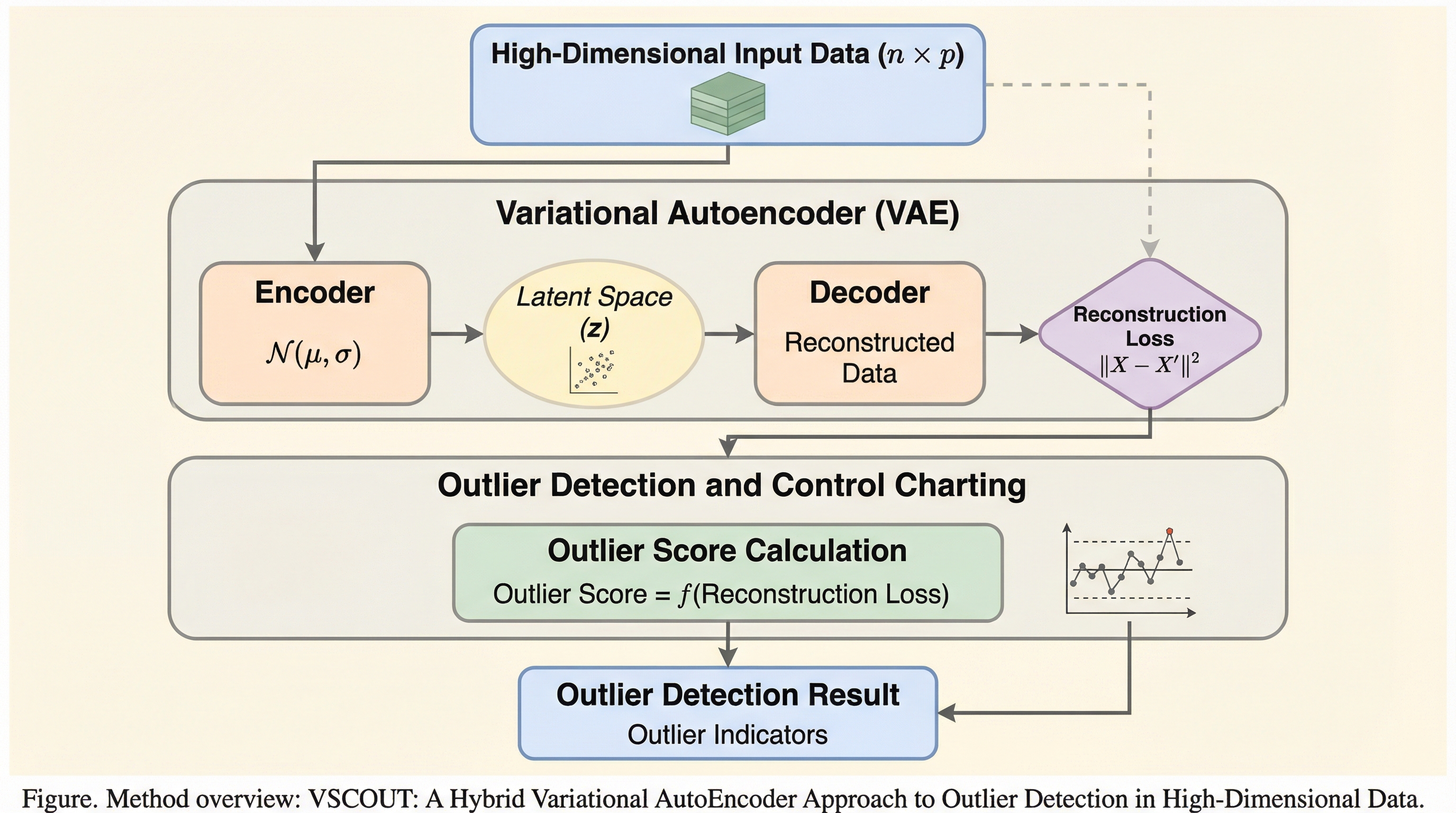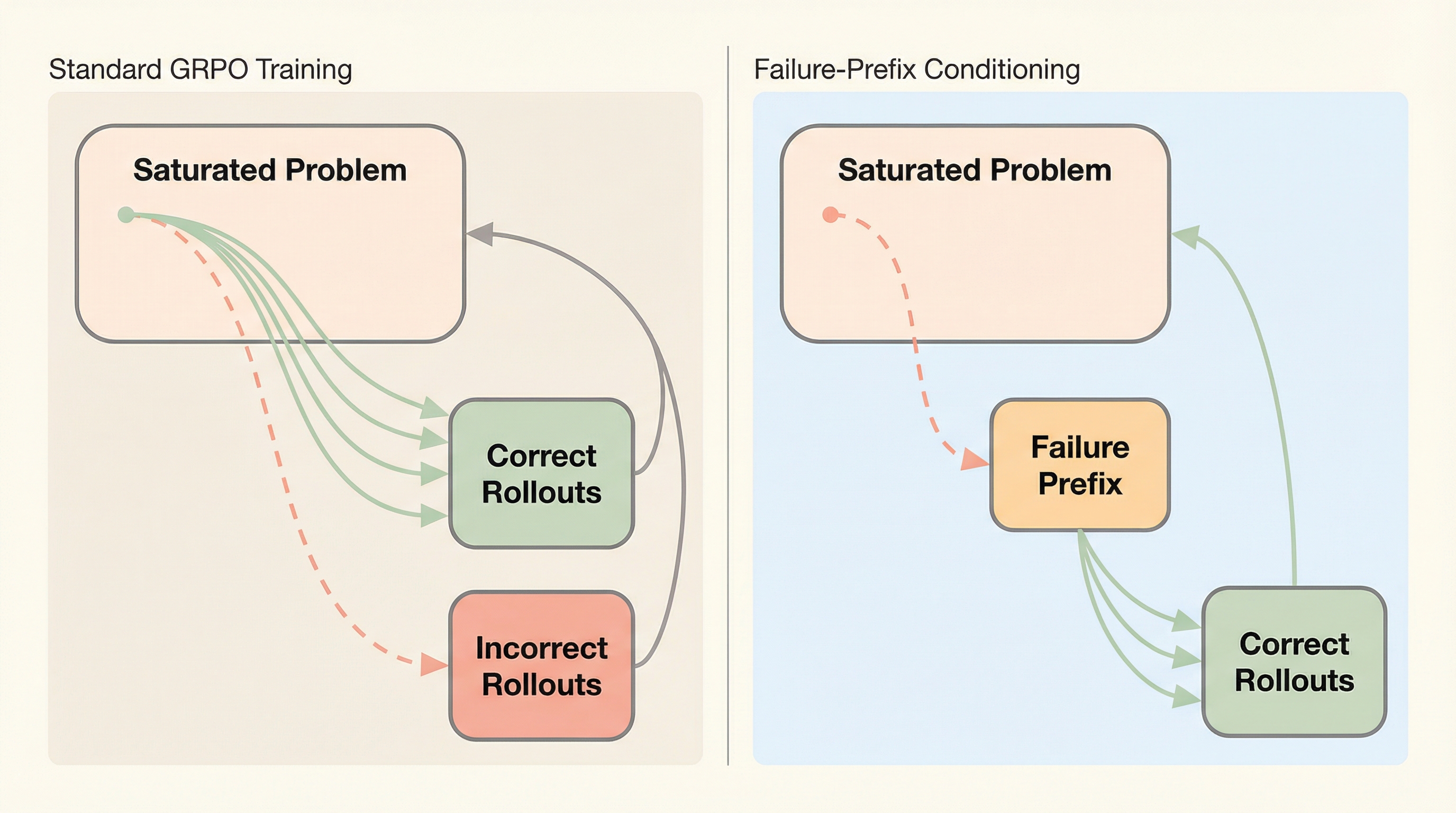
失敗プレフィックス条件付けによる飽和問題での推論モデルの学習
検証可能な報酬を用いた強化学習(RLVR)において、モデルが問題をほぼ完璧に解けるようになる「飽和状態」では学習信号が消失し、性能向上が停滞するという課題がある。 本研究は、稀に発生する誤った推論の断片(失敗プレフィックス)を問題文に付与して学習を開始させる「失敗プレフィックス条件付け」を提案し、意図的に失敗しやすい状態から探索させることで学習信号を回復させる。 実験の結果、飽和した問題のみを用いても中難易度の問題で学習した場合と同等の性能向上を達成し、推論の堅牢性が向上するとともに、トークン効率を維持したまま反復的な学習によってさらなる改善が可能であることを示した。